Return Proxy SQL Series: http://www.cnblogs.com/f-ck-need-u/p/7586194.html
1. Understanding Chain Rules
In the mysql_query_rules table, there are two special fields, "flagIN" and "flagOUT", which are used to define the entry and exit of the rules respectively, so as to realize the chains of rules.
The implementation of chain rules is as follows:
- When the entry value flagIN is set to 0, it indicates that the chain rule is started. If the flagIN value of the rule is not explicitly specified, the default is 0.
- When the statement matches the current rule, the flagOUT value of the current rule is recorded. If the flagOUT value is not empty (NOT NULL), the statement is flagOUT marked. If the application field value of the rule is not 1, then continue to match down.
- If the flagOUT tag of the statement is different from the flagIN value of the next rule, skip the rule and continue to match downward. Until the rule flagOUT=flagIN is matched, the rule is matched. This rule is another rule in the chain rule.
- Until the application field of a rule is set to 1, or all rules have been matched, the last evaluated rule will take effect directly and will not continue to match downwards.
With the following two diagrams, it should be easy to understand how chain rules work.
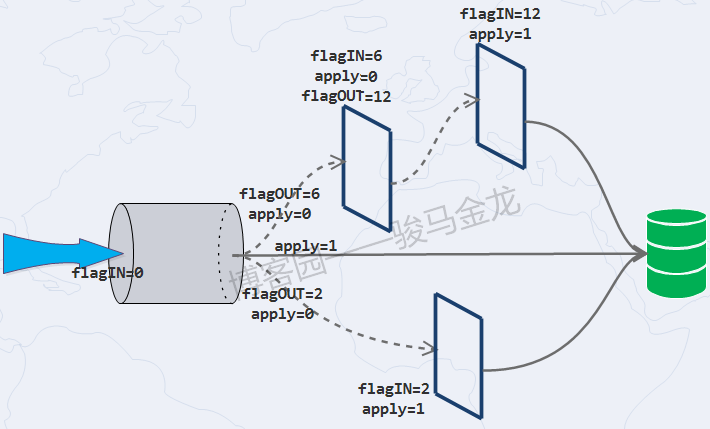

It is important to note that the rules are in order of size of rule_id. And it is not only apply=1 that rules are applied. When there are no rules to match, or when the flagIN and flagOUT values of a rule are the same, the last evaluated rule is applied.
The following examples can explain the rules of entry into force:
# rule_id=3 takes effect +---------+-------+--------+---------+ | rule_id | apply | flagIN | flagOUT | +---------+-------+--------+---------+ | 1 | 0 | 0 | 23 | | 2 | 0 | 23 | 23 | | 3 | 0 | 23 | NULL | +---------+-------+--------+---------+ # rule_id=2 takes effect +---------+-------+--------+---------+ | rule_id | apply | flagIN | flagOUT | +---------+-------+--------+---------+ | 1 | 0 | 0 | 23 | | 2 | 0 | 23 | 23 | | 3 | 0 | 24 | NULL | +---------+-------+--------+---------+ # Rule_id=2 takes effect because after matching rule_id=2, flagOUT=23 is also marked. +---------+-------+--------+---------+ | rule_id | apply | flagIN | flagOUT | +---------+-------+--------+---------+ | 1 | 0 | 0 | 23 | | 2 | 0 | 23 | NULL | | 3 | 1 | 24 | NULL | +---------+-------+--------+---------+ # rule_id=3 takes effect because after matching rule_id=2, flagOUT=23 is also marked +---------+-------+--------+---------+ | rule_id | apply | flagIN | flagOUT | +---------+-------+--------+---------+ | 1 | 0 | 0 | 23 | | 2 | 0 | 23 | NULL | | 3 | 1 | 23 | NULL | +---------+-------+--------+---------+
2. Examples of Chain Rules
With the common rule matching method, why do we design chain rules? Although ProxySQL implements very flexible rule matching patterns through regular expressions, the requirements are always changeable. Sometimes it is difficult to achieve more complex requirements through only one regular matching rule and replacement rule, such as sharding.
Chain rules can be used for multiple matching as well as multiple substitutions.
This article briefly demonstrates the chain rules, which is not practical, but only lays the groundwork for the following articles on Proxy SQL Sharing.
Two test libraries, a total of four tables test{1,2}.t{1,2}.
mysql> select * from test1.t1; +------------------+ | name | +------------------+ | test1_t1_malong1 | | test1_t1_malong2 | | test1_t1_malong3 | +------------------+ mysql> select * from test1.t2; +------------------+ | name | +------------------+ | test1_t2_malong1 | | test1_t2_malong2 | | test1_t2_malong3 | +------------------+ mysql> select * from test2.t1; +--------------------+ | name | +--------------------+ | test2_t1_xiaofang1 | | test2_t1_xiaofang2 | | test2_t1_xiaofang3 | +--------------------+ mysql> select * from test2.t2; +--------------------+ | name | +--------------------+ | test2_t2_xiaofang1 | | test2_t2_xiaofang2 | | test2_t2_xiaofang3 | +--------------------+
Now borrow the chain rule and route the query of the test 1.t1 table step by step to the query of the test 2.t2 table. Again, the example here is meaningless, just to demonstrate the basic usage of chain rules.
The process of approximate chain matching is as follows:
test1.t1 --> test1.t2 --> test2.t1 --> test2.t2
The following are the specific rules for insertion:
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset where 1=0;
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern) values
(1,1,0,0,23,"test1\.t1","test1.t2");
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern) values
(2,1,0,23,24,"test1\.t2","test2.t1");
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern,destination_hostgroup) values
(3,1,1,24,NULL,"test2\.t1","test2.t2",30);
load mysql query rules to runtime;
save mysql query rules to disk;
admin> select rule_id,
apply,
flagIN,
flagOUT,
match_pattern,
replace_pattern,
destination_hostgroup DH
from mysql_query_rules;
+---------+-------+--------+---------+---------------+-----------------+------+
| rule_id | apply | flagIN | flagOUT | match_pattern | replace_pattern | DH |
+---------+-------+--------+---------+---------------+-----------------+------+
| 1 | 0 | 0 | 23 | test1\.t1 | test1.t2 | NULL |
| 2 | 0 | 23 | 24 | test1\.t2 | test2.t1 | NULL |
| 3 | 1 | 24 | NULL | test2\.t1 | test2.t2 | 30 |
+---------+-------+--------+---------+---------------+-----------------+------+Query the test 1.t1 table and test results.
[root@xuexi ~]# mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test1.t1;" +--------------------+ | name | +--------------------+ | test2_t2_xiaofang1 | <-- The query returns a result of test2.t2 content | test2_t2_xiaofang2 | | test2_t2_xiaofang3 | +--------------------+ admin> select * from stats_mysql_query_rules; +---------+------+ | rule_id | hits | +---------+------+ | 1 | 1 | <-- 3 All the rules hit | 2 | 1 | | 3 | 1 | +---------+------+ admin> select hostgroup,digest_text from stats_mysql_query_digest; +-----------+----------------------------------+ | hostgroup | digest_text | +-----------+----------------------------------+ | 30 | select * from test2.t2 | <-- Routing target hg=30 +-----------+----------------------------------+
Obviously, matching, substitution and routing have been carried out in the expected way.
One question: If the query is a table of test1.t2 or a table of test2.t1, will chain matching be performed?
The answer is no, because the flagIN of rule_id=2 and rule_id=3 rules are non-zero values, and each SQL statement only enters the rule of flagIN=0 at the beginning.
In addition, it should be noted that when a statement does not follow all the chain rules we expect, it may be routed directly according to the value of destination_hostgroup field, even if the field value is not specified, there is a default routing target group of users, or a port-based routing target. Therefore, when writing chain rules, we should make complete customization for a certain type of statements as far as possible to ensure that such statements can pass through all the rules we expect.