Requests are written in the python language based on urllib, but Python provides a more convenient network request method, the requests library, than the cumbersome urllib.request library.
I. Basic Methods
1.GET Request
The bottom-level functions written by the get API are as follows, which must be passed as a URL, optional parameters such as params and other customizations, parameters passed in as a dictionary, and requests automatically encoded as a url.
View source code:
(1) Layer 1 source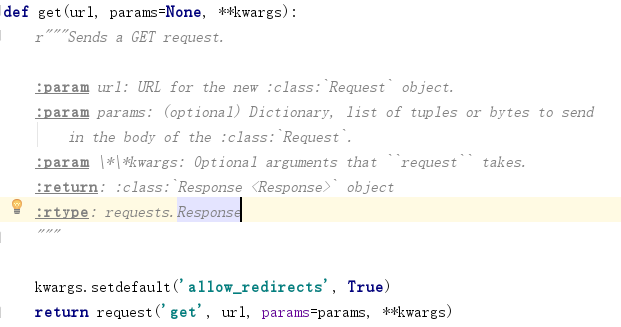
(2) Specifically, the following can be added: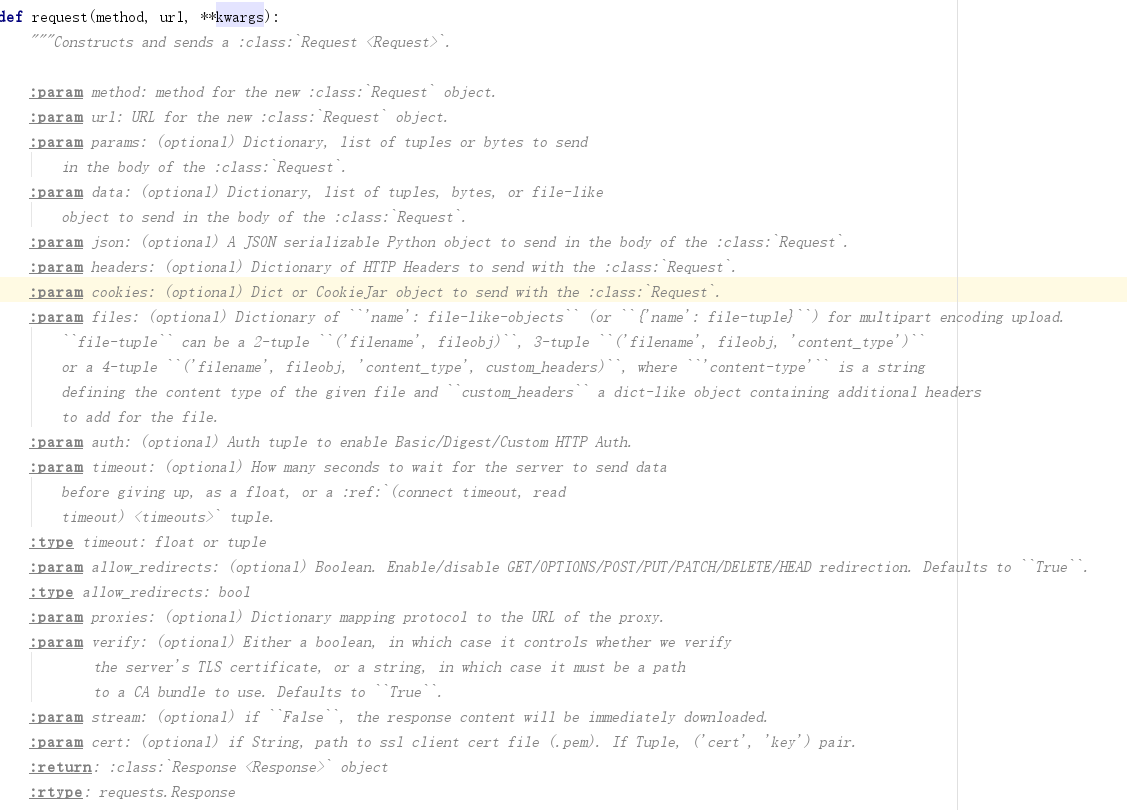
Examples are as follows:
import requests
url = "http://www.baidu.com/s? "#Request Header
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"}# Send network requests
params = {
"wd":"Beauty"
}#Parameters are typically dictionary and requests do not need to be escaped
reponse = requests.get(url,params=params,headers = header)
data = reponse.content.decode()
with open("03.html","w",encoding="utf-8")as f:
f.write(data)
#Advantages: requests help us automatically escape encoding
2.POST Request
Example:
import requests
data = {'name': 'germey', 'age': '22'}
r = requests.post("http://httpbin.org/post", data=data)
print(r.text)
Using the response's api, you can see the relevant status codes, request headers, cookies, and so on.
2. Advanced methods
1. File upload
import requests
files = {'file': open('favicon.ico', 'rb')}
r = requests.post("http://httpbin.org/post", files=files)
print(r.text)
2.cookies acquisition
import requests
r = requests.get("https://www.baidu.com")
print(r.cookies)#Get the cookies information you get
for key, value in r.cookies.items():
print(key + '=' + value)#Segmentation of a long string of information
Here we call the cookies property first to get the cookies successfully, and we can see that it is of RequestCookieJar type.It is then converted into a list of tuples using the items() method, and the name and value of each Cookie are iterated out to achieve traversal resolution of the Cookie.
There are two solutions for web pages that require cookies:
(1) Write cookies to headers
import requests
headers = {
'Cookie': 'q_c1=31653b264a074fc9a57816d1ea93ed8b|1474273938000|1474273938000; d_c0="AGDAs254kAqPTr6NW1U3XTLFzKhMPQ6H_nc=|1474273938"; __utmv=51854390.100-1|2=registration_date=20130902=1^3=entry_date=20130902=1;a_t="2.0AACAfbwdAAAXAAAAso0QWAAAgH28HQAAAGDAs254kAoXAAAAYQJVTQ4FCVgA360us8BAklzLYNEHUd6kmHtRQX5a6hiZxKCynnycerLQ3gIkoJLOCQ==";z_c0=Mi4wQUFDQWZid2RBQUFBWU1DemJuaVFDaGNBQUFCaEFsVk5EZ1VKV0FEZnJTNnp3RUNTWE10ZzBRZFIzcVNZZTFGQmZn|1474887858|64b4d4234a21de774c42c837fe0b672fdb5763b0',
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
}
r = requests.get('https://www.zhihu.com', headers=headers)
print(r.text)
(2) pass cookies directly as parameters to the api where get requests network access
import requests
cookies = 'q_c1=31653b264a074fc9a57816d1ea93ed8b|1474273938000|1474273938000; d_c0="AGDAs254kAqPTr6NW1U3XTLFzKhMPQ6H_nc=|1474273938"; __utmv=51854390.100-1|2=registration_date=20130902=1^3=entry_date=20130902=1;a_t="2.0AACAfbwdAAAXAAAAso0QWAAAgH28HQAAAGDAs254kAoXAAAAYQJVTQ4FCVgA360us8BAklzLYNEHUd6kmHtRQX5a6hiZxKCynnycerLQ3gIkoJLOCQ==";z_c0=Mi4wQUFDQWZid2RBQUFBWU1DemJuaVFDaGNBQUFCaEFsVk5EZ1VKV0FEZnJTNnp3RUNTWE10ZzBRZFIzcVNZZTFGQmZn|1474887858|64b4d4234a21de774c42c837fe0b672fdb5763b0'
jar = requests.cookies.RequestsCookieJar()
headers = {
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
jar.set(key, value)
r = requests.get("http://www.zhihu.com", cookies=jar, headers=headers)
print(r.text)
The key at this point is to take the copied cookies with the RequestsCookieJar() object, split them into keys, value = cookie.split ('=', 1), and reset them back into jar, passing directly to the get parameter.
3. Session Maintenance
If you use the same cookie s once post and once get, it is obviously more cumbersome to add them manually, so session maintenance can be a good solution to this problem and make use of session.
#Use session to access personal centers
import requests
url = "https://www.yaozh.com/member/"#Request Header
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"}# Send network requests
#1.Code logon, save cookie s
#session class, which can save cookies (his underlying layer is the encapsulated cookiejar)
session= requests.session()#Login url
login_in = "https://www.yaozh.com/login/"
#2 Hold the saved cookie Visit the personal center interface# Stitching parameters
login_form_datda ={
'username': '*****',
'pwd': '*********',
'formhash':'*****',
'backurl':'*********'
}
loginres = session.post(login_in,data=login_form_datda,headers = header,verify = False)
print(loginres.content.decode())#Save cookie s, view
messurl = "https://www.yaozh.com/member/"
data = session.get(messurl,headers = header,verify = False).content.decode()#Continue requesting data directly from session with the cookie you just requested
with open("02.html","w",encoding="utf-8")as f:
f.write(data)
4.ssl Certificate Verification
When an HTTP request is sent, it checks the SSL certificate, and we can use the verify parameter to control whether to check the certificate.In fact, if the verify parameter is not added, the default is True, which will be automatically verified.The solutions are as follows:
(1) Change to False to terminate validation
import requests
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)
(2) Specify a local client certificate
The path to include both the certificate and the key is sufficient
import requests
response = requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key'))
print(response.status_code)
5. Proxy settings
Give the proxy's ip directly in a dictionary and pass it into the get parameter
import requests
url = "http://www.baidu.com/"#Request Header"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"}# Send network requests
freeproxy = {"http":"192.165.12.3:9999"}
requests.get(url=url,headers=headers,proxies = freeproxy)
print(requests.status_codes)
6. Timeout Settings
Specify the case separately
r = requests.get('https://www.taobao.com', timeout=(5,11, 30))
7. Authentication
That is, when you need to enter a user name and password
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://localhost:5000', auth=HTTPBasicAuth('username', 'password'))
print(r.status_code)
Use auth as an api
8.Prepared Request (not used personally)
When urllib was introduced earlier, we could represent the request as a data structure, where each parameter can be represented by a Request object.This can also be done in requests, a data structure called Prepared Request.Let's take an example:
from requests import Request, Session
url = 'http://httpbin.org/post'
data = {
'name': 'germey'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
s = Session()
req = Request('POST', url, data=data, headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)
Many of them are still attached with links from where Cui Shen learned them: https://cuiqingcai.com/5523.html
Thank God~~