summary
This paper is mainly divided into data acquisition (microblog crawler) and text analysis (topic extraction and emotion calculation).
Project scenario: Taking microblog as the data source, analyze the Theme Evolution and emotional fluctuation trend of public opinion of Xinguan vaccine, verify it in combination with current events, so as to obtain the specific impact of special events on public opinion, and provide suggestions for the reasonable guidance of social media public opinion of public emergencies.
Project code address:
https://github.com/stay-leave/weibo-public-opinion-analysis
1. Data acquisition
Including microblog text crawler, comment crawler and user information crawler.
Specifically, the results of the three crawls are regarded as three linked relational tables. First, the text is crawled, then the identifier of the text is used to locate each comment, and finally the identifier of the comment is used to locate the personal information of each user.
Interface:
www.weibo.cn
1. Blog crawler
Direct use of this project, very easy to use.
https://github.com/dataabc/weibo-search
2. Comment crawler
Input: microblog text data. The format is as follows:
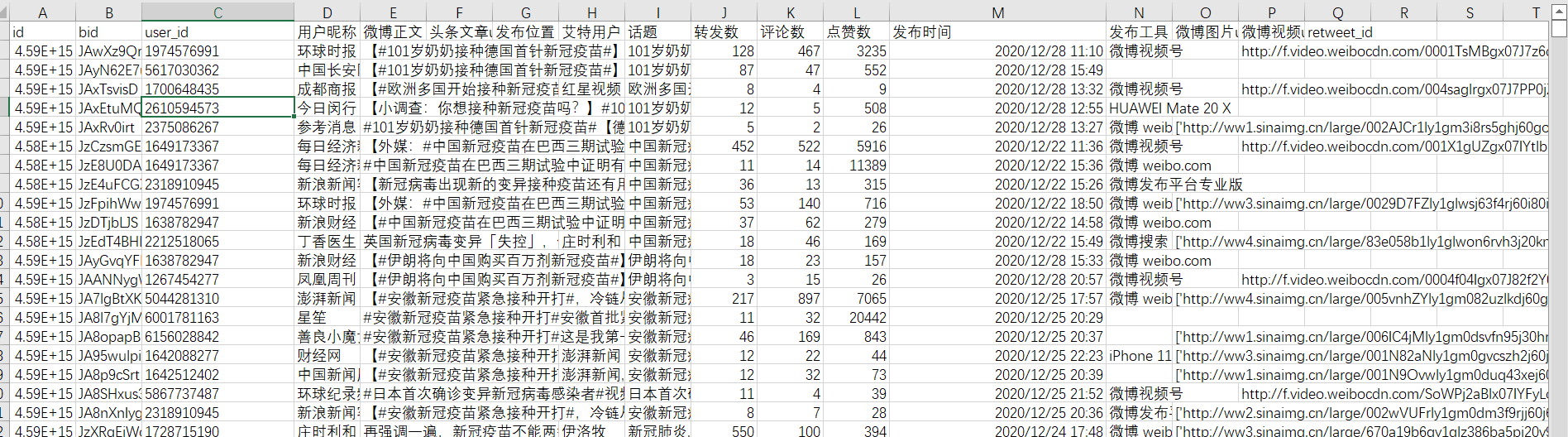
Output: Comments on each blog post. The format is as follows:
 Crawler Code:
Crawler Code:
#coding='utf-8'
import xlrd
import re
import requests
import xlwt
import os
import time as t
import random
import numpy as np
import datetime
import urllib3
from multiprocessing.dummy import Pool as ThreadPool
urllib3.disable_warnings()
cookie=''
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'https://www.baidu.com/',
'Connection': 'keep-alive',
'Cookie': cookie,
}
def require(url):
"""Get web source code"""
while True:
try:
response = requests.get(url, headers=headers,timeout=(30,50),verify=False)
#print(url)
code_1=response.status_code
#print(type(code_1))
#t.sleep(random.randint(1,2))
if code_1==200:
print('In normal crawling, status code:'+str(code_1))#Status code
t.sleep(random.randint(1,2))
break
else:
print('The request is abnormal. In retry, the status code is:'+str(code_1))#Status code
t.sleep(random.randint(2,3))
continue
except:
t.sleep(random.randint(2,3))
continue
#print(response.encoding)#Preferred encoding
#response.encoding=response.apparent_encoding
html=response.text#Source code text
return html
def html_1(url):#Return the source code of the web page and the number of comment pages
html=require(url)
try:
page=re.findall(' 1/(.*?)page',html,re.S)
page=int(page[0])
except:
page=0
#page=re.findall('<input name="mp" type="hidden" value="(.*?)">',html,re.S)
return html,page
def count(alls):
n=0
for all in alls:
for i in all:
n=n+1
return n
def body(h_1):#subject
html_2=re.findall('<div class="c" id="C.*?">(.*?)</div>',str(h_1),re.S)
html_2=str(html_2)
user_ids=re.findall('<a href=".*?&fuid=(.*?)&.*?">report</a> ',html_2,re.S)#Start with the report link
names_0=re.findall('<a href=.*?>(.*?)</a>',html_2,re.S)
names=[]#user name
ma=[ 'report', 'fabulous[]', 'reply']
pattern = re.compile(r'\d+')#Match number
for i in names_0:
i=re.sub(pattern, "", i)
if i not in ma:
if '@' not in i:
names.append(i)
pattern_0= re.compile(r'reply<a href=.*?</a>:')#Match reply prefix
pattern_0_1= re.compile(r'<a href=.*?</a>')#Match the address of the expression picture behind the reply
pattern_0_2= re.compile(r'<img alt=.*?/>')#Picture address matching reply content
contents=[]#Comment content
contents_2=[]#Preliminary comments
contents_0=re.findall('<span class="ctt">(.*?)</span>',html_2,re.S)#class a
contents_1=re.findall('<a href=.*?>@.*?</a>(.*?)<a href=.*?>report</a> ',html_2,re.S)#second level
for i in contents_0:
i=re.sub(pattern_0,'',i)
i=re.sub(pattern_0_1,'',i)
i=re.sub(pattern_0_2,'',i)
i=i.replace(':','')
i=i.strip()
contents_2.append(i)
for i in contents_1:
i=re.sub(pattern_0,'',i)
i=re.sub(pattern_0_1,'',i)
i=re.sub(pattern_0_2,'',i)
i=i.replace('</span>','')
i=i.replace(' ','')
i=i.replace(':','')
i=i.strip()
contents_2.append(i)
for i in contents_2:
i=re.sub('\s','',i)#Remove blank
if len(i)==0:
pass
else:
contents.append(i)
times_0=re.findall('<span class="ct">(.*?)</span>',html_2,re.S)
times=[]#time
pattern_1= re.compile(r'\d{2}month\d{2}day')#Match date
for i in times_0:
try:
t_1= re.match(pattern_1, i).group()
except:
a=datetime.datetime.now().strftime('%m%d')
t_1=a[:2]+'month'+a[2:]+'day'#Change to the same day
times.append(t_1)
all=[]
for i in range(len(user_ids)):#There's a problem
try:
al=[user_ids[i],names[i],contents[i],times[i]]
except:
j='empty'
contents.append(j)
al=[user_ids[i],names[i],contents[i],times[i]]
all.append(al)
return all
def save_afile(alls,filename):
"""Save in a excel"""
f=xlwt.Workbook()
sheet1=f.add_sheet(u'sheet1',cell_overwrite_ok=True)
sheet1.write(0,0,'user ID')
sheet1.write(0,1,'user name')
sheet1.write(0,2,'Comment content')
sheet1.write(0,3,'time')
i=1
for all in alls:
for data in all:
for j in range(len(data)):
sheet1.write(i,j,data[j])
i=i+1
f.save(r'this year/'+filename+'.xls')
def extract(inpath,l):
"""Take out a column of data"""
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[0]#Selected table
nrows = table.nrows#Get line number
ncols = table.ncols#Get column number
numbers=[]
for i in range(1, nrows):#Line 0 header
alldata = table.row_values(i)#Cycle to output every row in excel table, that is, all data
result = alldata[l]#Take out the data in the first column of the table
numbers.append(result)
return numbers
def run(ids):
b=ids[0]#bid
u=str(ids[1]).replace('.0','')#uid
alls=[]#Empty once per cycle
pa=[]#Empty list decision
url='https://weibo.cn/comment/'+str(b)+'?uid='+str(u) # a comment home page of microblog
html,page=html_1(url)
#print(url)
if page==0:#If it is 0, there is only one page of data
#print('number of pages entered is 0 ')
try:
data_1=body(html)
except:
data_1=pa
alls.append(data_1)#Climb out the home page
#print('1 page in total, '+ str (count (all)) +' data ')
else:#Two or more pages
#print('enter two or more pages')
#print('number of pages' + str(page))
for j in range(1,page+1):#From 1 to page
if j>=51:
break
else:
url_1=url+'&rl=1'+'&page='+str(j)
#print(url_1)
htmls,pages=html_1(url_1)
alls.append(body(htmls))
t.sleep(1)
print('total'+str(page)+'page,share'+str(count(alls))+'Data')
save_afile(alls,b)
print('Microblog number is'+str(b)+'Comments data file and saved')
if __name__ == '__main__':
#Due to microblog restrictions, you can only crawl the top 50 pages
#The file inside is the text file crawled
bid=extract('..//1. Crawl the microblog text / / text_ 2.xlsx',1)#1 is bid, 2 is u_id
uid=extract('..//1. Crawl the microblog text / / text_ 2.xlsx',2)
ids=[]#Match bid and uid and add them to ids as nested lists
for i,j in zip(bid,uid):
ids.append([i,j])
#Multithreading
pool = ThreadPool()
pool.map(run, ids)
Then merge them. The merged results are as follows:
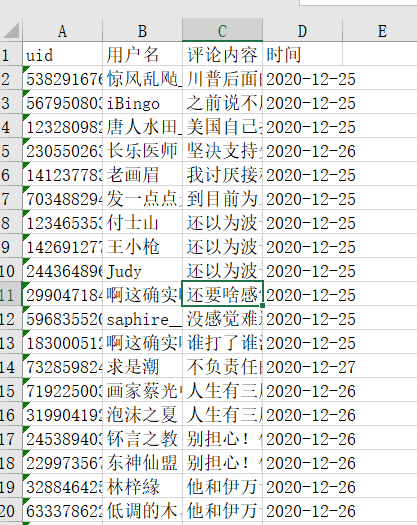 The code of the merged file is as follows:
The code of the merged file is as follows:
#coding='utf-8'
import xlrd
import re
import xlwt
import time as t
import openpyxl
import os
def extract(inpath):
"""Extract data"""
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[0]#Selected table
nrows = table.nrows#Get line number
ncols = table.ncols#Get column number
numbers=[]
for i in range(1, nrows):#Line 0 header
alldata = table.row_values(i)#Cycle to output every row in excel table, that is, all data
result_0 = alldata[0]#id
result_1 = alldata[1]#bid
result_2 = alldata[2]#uid
result_3 = alldata[3]#text
numbers.append([result_0,result_1,result_2,result_3])
return numbers
def extract_1(inpath):
"""Extract data"""
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[0]#Selected table
nrows = table.nrows#Get line number
ncols = table.ncols#Get column number
numbers=[]
for i in range(1, nrows):#Line 0 header
alldata = table.row_values(i)#Cycle to output every row in excel table, that is, all data
result_0 = alldata[1]#bid
numbers.append(result_0)
return numbers
def save_file(alls,name):
"""Save all comment data of a time period in one excle
"""
f=openpyxl.Workbook()
sheet1=f.create_sheet('sheet1')
sheet1['A1']='uid'
sheet1['B1']='user name'
sheet1['C1']='Comment content'
sheet1['D1']='time'
i=2#The minimum value of openpyxl is 1 and xlsx is written
for all in alls:#Traverse each page
for data in all:#Traverse each line
for j in range(1,len(data)+1):#Take each cell
#sheet1.write(i,j,data[j])#Write cell
sheet1.cell(row=i,column=j,value=data[j-1])
i=i+1#Next line
f.save(str(name))
if __name__ == "__main__":
filenames=os.listdir(r'Folders to be merged')
new_names=[]
for i in filenames:
i=i.replace('.xlsx','')
new_names.append(i)
alls=[]
for i in new_names:
alls.append(extract(r'File path//'+i+'.xlsx'))
save_file(alls,'Summary.xlsx')
3. User information crawler
Input: comment data.
Output: personal information in the following format:
 The code is as follows:
The code is as follows:
#coding='utf-8'
import xlrd
import re
import requests
import xlwt
import os
import time as t
import random
import numpy as np
import datetime
import urllib3
import sys
from multiprocessing.dummy import Pool as ThreadPool
import openpyxl
urllib3.disable_warnings()
cookie=''
headers = {
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'https://weibo.cn/',
'Connection': 'keep-alive',
'Cookie': cookie,
}
def save_file(alls,name):
"""Save data in a excel
"""
f=openpyxl.Workbook()
sheet1=f.create_sheet('sheet1')
sheet1['A1']='uid'
sheet1['B1']='nickname'
sheet1['C1']='Gender'
sheet1['D1']='region'
sheet1['E1']='birthday'
i=2#The minimum value of openpyxl is 1 and xlsx is written
for all in alls:#Traverse each page
#for data in all:#Traverse each line
for j in range(1,len(all)+1):#Take each cell
#sheet1.write(i,j,all[j])#Write cell
sheet1.cell(row=i,column=j,value=all[j-1])
i=i+1#Next line
f.save(str(name))
def extract(inpath,l):
"""Take out a column of data"""
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[0]#Selected table
nrows = table.nrows#Get line number
ncols = table.ncols#Get column number
numbers=[]
for i in range(1, nrows):#Line 0 header
alldata = table.row_values(i)#Cycle to output every row in excel table, that is, all data
result = alldata[l]#Take out the data in the first column of the table
numbers.append(result)
return numbers
def require(url):
"""Get web source code"""
while True:
try:
response = requests.get(url, headers=headers,timeout=(30,50),verify=False)
#print(url)
code_1=response.status_code
#print(type(code_1))
#t.sleep(random.randint(1,2))
if code_1==200:
print('In normal crawling, status code:'+str(code_1))#Status code
t.sleep(random.randint(1,2))
break
else:
print('The request is abnormal. In retry, the status code is:'+str(code_1))#Status code
t.sleep(random.randint(2,3))
continue
except:
t.sleep(random.randint(2,3))
continue
#print(response.encoding)#Preferred encoding
#response.encoding=response.apparent_encoding
html=response.text#Source code text
return html
def body(html):
"""Single data crawling"""
data=re.findall('<div class="tip">essential information</div>(.*?)<div class="tip">Other information</div>',html,re.S)#Take big
#print(data)
name_0=re.findall('<div class="c">nickname:(.*?)<br/>',str(data),re.S)#User nickname
#print(name_0)
try:
name_1=re.findall('<br/>Gender:(.*?)<br/>',str(data),re.S)#Gender
except:
name_1=['nothing']
try:
name_2=re.findall('<br/>region:(.*?)<br/>',str(data),re.S)#region
except:
name_2=['nothing']
try:
name_3=re.findall('<br/>birthday:(\d{4}-\d{1,2}-\d{1,2})<br/>',str(data),re.S)#birthday
except:
name_3=['nothing']
all=name_0+name_1+name_2+name_3
return all
def run(uid):
uid=int(uid)
alls=[]
url='https://weibo.cn/'+str(uid)+'/info'
one_data=[uid]+body(require(url))
#t.sleep(1)
alls.append(one_data)
return alls
if __name__ == '__main__':
#start_time = t.clock()
uids=list(set(extract(r'2.data processing\Comment information.xlsx',0)))
#print(len(uids))
pool = ThreadPool()
alls_1=pool.map(run, uids)
#print(len(alls_1))
alls_2=[]
for i in alls_1:
alls_2.append(i[0])
#print(len(alls_2))
save_file(alls_2,'I.xlsx')#Save path
#stop_time = t.clock()
#cost = stop_time - start_time
#print("%s cost %s second" % (os.path.basename(sys.argv[0]), cost))
2. Text analysis
1.LDA subject analysis
Data source: blog content
Text processing: de duplication, elimination of blog posts with less words and cleaning of special symbols.
Determination of the number of topics: use the two judgment indicators of confusion and consistency to set an interval to judge the confusion of the content of the interval of the number of topics and the trend of the consistency index, and select the number of topics that can make both achieve a high level.
Subject analysis: the text is segmented by month and analyzed separately. This is done using the gensim library.
Output content:
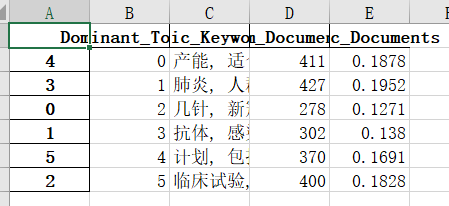
1. Subject tag of each blog post
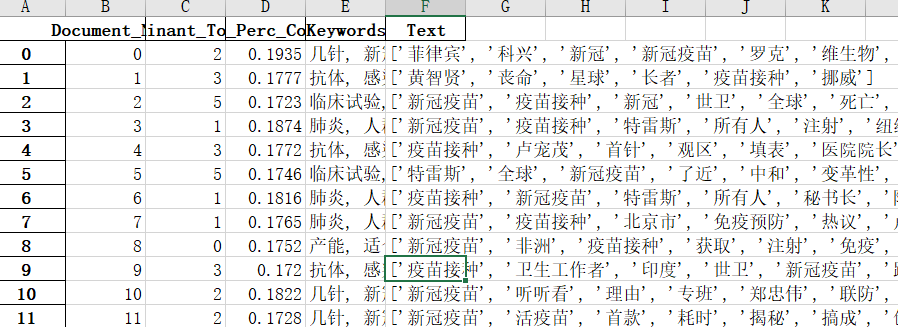 2. Keywords for each topic
2. Keywords for each topic
 3. Keywords and proportion of each topic
3. Keywords and proportion of each topic
 4. Number of posts per topic
4. Number of posts per topic
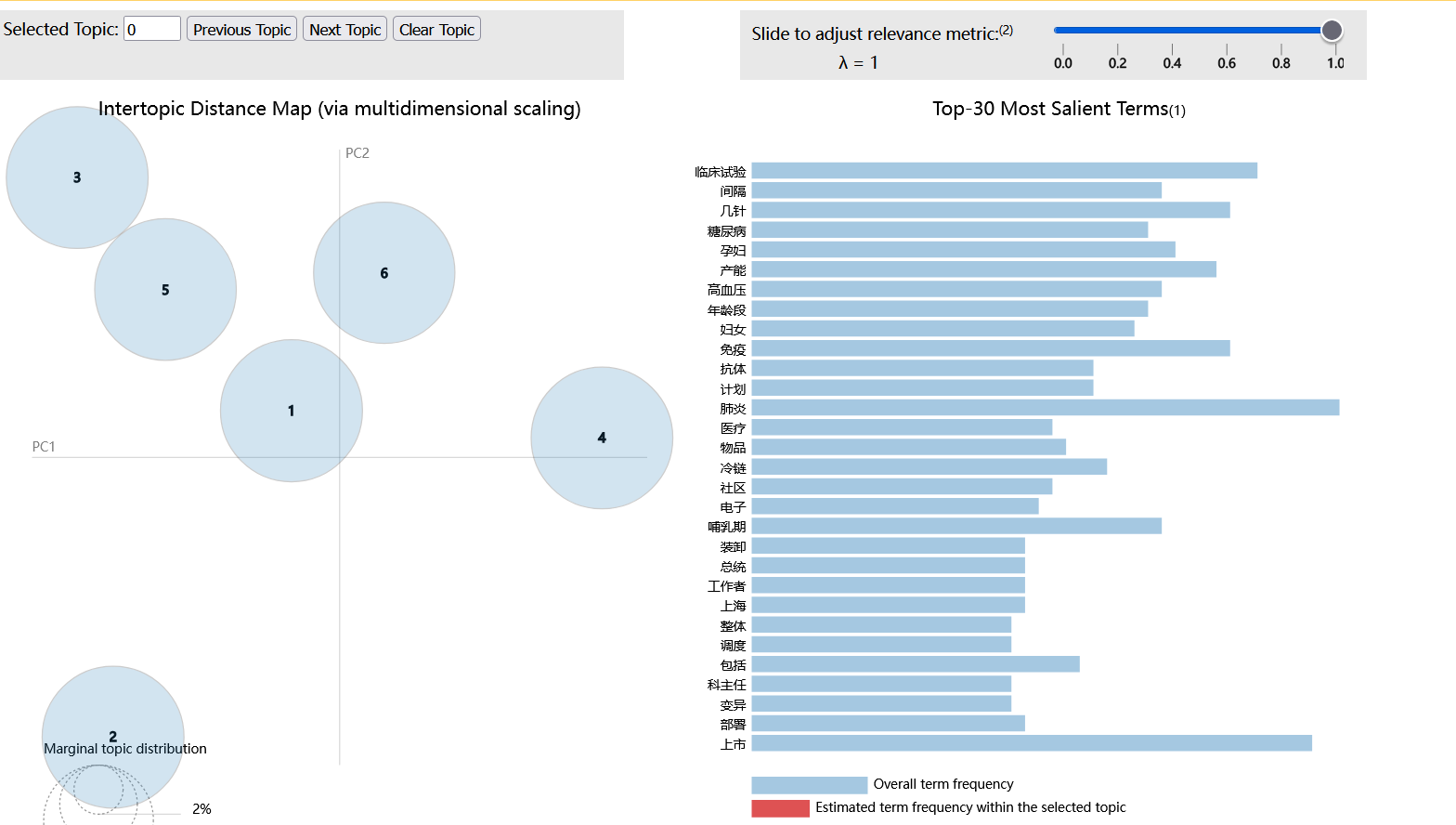
 5. Subject visualization
5. Subject visualization
 See github for the code
See github for the code
2. Emotion analysis
Input: comment data.
Specific use reference.
https://blog.csdn.net/qq_43814415/article/details/115054488?spm=1001.2014.3001.5501
Output:
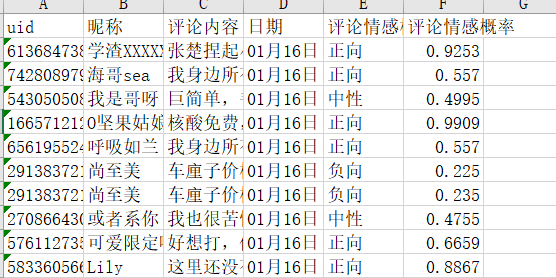 The code is as follows:
The code is as follows:
# coding=utf-8
import requests
import json
import xlrd
import re
import xlwt
import time as t
import openpyxl
"""
Yours APPID AK SK
Can only be called twice per second
"""
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
# client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
# Get token
# client_id is the AK and client obtained on the official website_ Secret is the SK obtained on the official website
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + API_KEY + '&client_secret=' + SECRET_KEY
response = requests.get(host)
while True:
if response.status_code == 200:
info = json.loads(response.text) # Convert string to dictionary
access_token = info['access_token'] # Parsing data to access_token
break
else:
continue
access_token=access_token
def extract(inpath):
"""Extract data"""
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[0] # Selected table
nrows = table.nrows # Get line number
ncols = table.ncols # Get column number
numbers = []
for i in range(1, nrows): # Line 0 header
alldata = table.row_values(i) # Cycle to output every row in excel table, that is, all data
result_0 = alldata[0] # Remove id
result_1 = alldata[1] # Take out the netizen's name
result_2 = alldata[2] # Take out netizen comments
result_3 = alldata[3] # Withdrawal date
numbers.append([result_0, result_1, result_2, result_3])
return numbers
def emotion(text):
while True: # Handling aps concurrent exceptions
url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify_custom?charset=UTF-8&access_token=' + access_token
#headers = {'Content-Type': 'application/json', 'Connection': 'close'} # headers=headers
body = {'text': text[:1024]}
requests.packages.urllib3.disable_warnings()
try:
res = requests.post(url=url, data=json.dumps(body), verify=False)
rc=res.status_code
print(rc)
except:
print('An error occurred. Stop for five seconds and try again')
t.sleep(5)
continue
if rc==200:
print('Normal request')
else:
print('Encountered an error, try again')
t.sleep(2)
continue
try:
judge = res.text
print(judge)
except:
print('error,Retrying with error text:' + text)
t.sleep(1)
continue
if judge == {'error_code': 18, 'error_msg': 'Open api qps request limit reached'}:
print('Concurrency limit')
t.sleep(1)
continue
elif 'error_msg' in judge: # If an unexpected error is reported, this cycle will be ended
print('Other errors')
t.sleep(1)
continue
else:
break
# print(judge)
judge=eval(judge)#Convert string to dictionary
#print(type(judge))
pm = judge["items"][0]["sentiment"] # Emotion classification
#print(pm)
if pm == 0:
pm = 'Negative direction'
elif pm == 1:
pm = 'neutral'
else:
pm = 'Forward'
pp = judge["items"][0]["positive_prob"] # Forward probability
pp = round(pp, 4)
#print(pp)
np = judge["items"][0]["negative_prob"] # Negative probability
np = round(np, 4)
#print(np)
return pm, pp, np
def run(inpath):
"Run program,Returns a large list of nested small lists"
alls = []
all = extract(inpath)
for i in all:
id = i[0]
name = i[1]
review = i[2] # Netizen comments
# review= emotion(review)
date = i[3]
pm, pp, np = emotion(review)
alls.append([id, name, review, date, pm, pp]) # Take only the positive direction and place all in an interval
t.sleep(1)
return alls
def save_file(alls, name):
"""Save all comment data of a time period in one excel
"""
f = openpyxl.Workbook()
sheet1 = f.create_sheet('sheet1')
sheet1['A1'] = 'uid'
sheet1['B1'] = 'nickname'
sheet1['C1'] = 'Comment content'
sheet1['D1'] = 'date'
sheet1['E1'] = 'Comment on emotional polarity'
sheet1['F1'] = 'Comment on emotional probability' # [0,0.5] negative, (0.5,1] positive
i = 2 # The minimum value of openpyxl is 1 and xlsx is written
for all in alls: # Traverse each page
# for data in all:#Traverse each line
for j in range(1, len(all) + 1): # Take each cell
# sheet1.write(i,j,all[j])#Write cell
sheet1.cell(row=i, column=j, value=all[j - 1])
i = i + 1 # Next line
f.save(str(name))
if __name__ == "__main__":
save_file(run( 'three.xlsx'), 'Three affective values.xlsx')
After obtaining the emotional values of all comments, it is necessary to roll up according to their time or space dimensions to obtain the temporal emotional values and regional emotional value distribution.
The sequence roll up code is as follows:
#coding='utf-8'
import xlrd
import xlwt
import datetime
import re
import pandas as pd
import numpy as np
data_1=pd.read_excel(r'emotion.xlsx')
data = pd.DataFrame(data_1)#Read and convert excel file to dataframe format
print(data)
data_df=data.groupby(by='date').mean()#Average by date
data_df.sort_index(ascending=True,inplace=True)#Descending order
data_df.drop(['uid'],axis=1,inplace=True)#Delete id column
print(data_df)
data_df.to_excel('Emotional dimensionality reduction.xlsx')#Store emotional values in excel
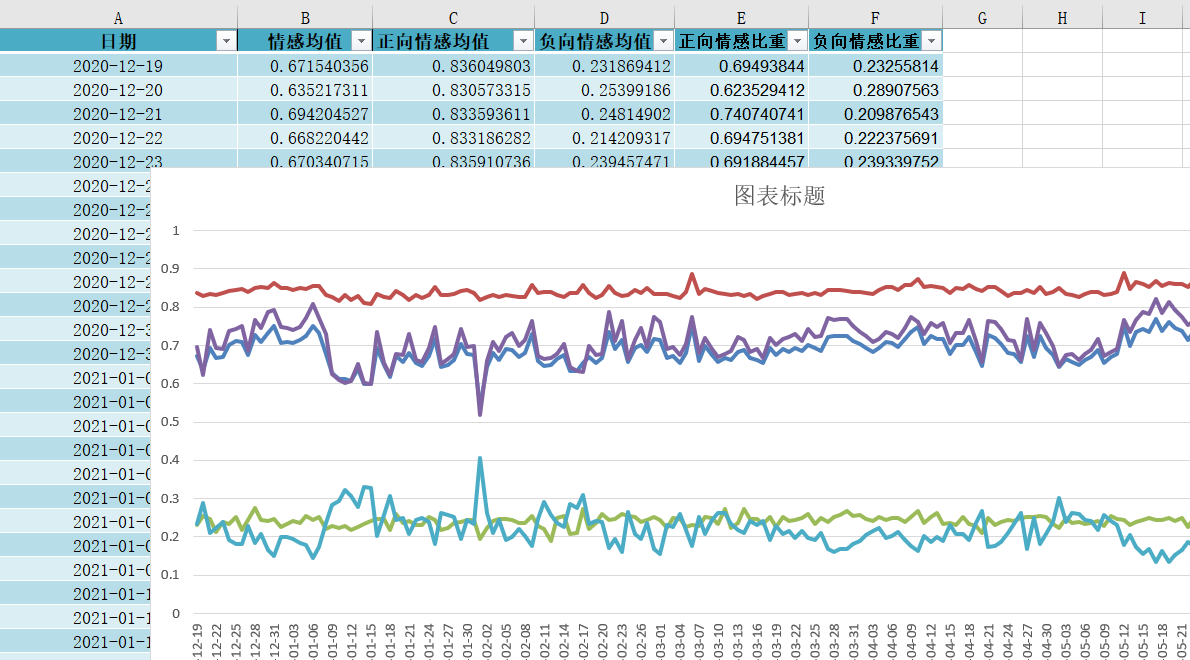
Finally, we can get the emotional time series line chart:
3. Subject similarity calculation
Here, we use text similarity calculation to analyze the evolutionary relationship of the same topic in different time periods. Use the calculation formula in this paper.
The output is as follows:
The code is as follows:
#coding='utf-8'
from gensim import corpora, models
from gensim.models import Word2Vec
import math
from sklearn.decomposition import PCA
import json
def work(list_1,list_2):
#Calculate the cosine similarity of two word set vectors
#x value
xs=[]
#y value
ys=[]
for i in list_1:
xs.append(i[0])
ys.append(i[1])
for i in list_2:
xs.append(i[0])
ys.append(i[1])
#Numerator a, denominator b,c
a=0
b=0
c=0
for x,y in zip(xs,ys):
a=a+x*y
b=b+x*x
c=c+y*y
#evaluation
h=a/(math.sqrt(b)*math.sqrt(c))
return h.real
def infile(fliepath):
#Enter subject word file
train = []
fp = open(fliepath,'r',encoding='utf8')
for line in fp:
line = line.strip().split(' ')
train.append(line)
return train
sentences=infile('all.txt')#Read subject characteristic words
model=Word2Vec.load('w2v.model')#Load the trained model
# Fitting data based on 2d PCA
X = model.wv.vectors
pca = PCA(n_components=2)
result = pca.fit_transform(X)
words = list(model.wv.key_to_index)
'''
for i, word in enumerate(words):
if word=='pneumonia':
print(word,result[i, 0], result[i, 1])#Words and word vectors
for sentence in sentences:#Every theme
print(sentence)
for sen in sentence:#Every word
print(sen)
'''
list_1=[]#Two dimensional vector word bag form
for sentence in sentences:#Every theme
list_2=[]
for sen in sentence:#Every word
for i, word in enumerate(words):
if word==sen:
#print(word,result[i, 0], result[i, 1])#Words and word vectors
list_2.append((result[i, 0], result[i, 1]))
list_1.append(list_2)
#print(len(list_1))
corpus=list_1
n_12=list(range(0,8))#Number of topics in December
n_1=list(range(8,14))#Number of topics in January
n_2=list(range(14,20))#Number of topics in February
n_3=list(range(20,27))#Number of themes in March
n_4=list(range(27,34))#Number of topics in April
n_5=list(range(34,41))#Number of themes in May
n_6=list(range(41,50))#Number of topics in June
#Calculate the cosine similarity of adjacent time slice topics
hs={}
for i in n_12:#December theme
for j in n_1:#January theme
hs['12 Theme of the month'+str(i)+str(sentences[i])+'And'+'1 Theme of the month'+str(j-8)+str(sentences[j])+'The cosine similarity of is']=work(corpus[i],corpus[j])
#print(hs)
for key,value in hs.items():#
print(key,'\t',value,'\n')
with open('12-1.json', 'w') as f:
f.write(json.dumps(hs, ensure_ascii=False, indent=4, separators=(',', ':')))
print('Saved successfully')