Hello, I'm brother Tom~
Everyone must be familiar with MySQL database. Today, I'd like to talk about data synchronization
For data synchronization, our common strategies are synchronous double write and asynchronous message
1. Synchronous double write: literally, synchronous + double write. For example, the old database model is reconstructed and the data is migrated to the new database. During the migration process, if there is any data change, it should be written to both the old database and the new database, and both sides should be updated synchronously.
- Advantages: synchronization mechanism ensures the effectiveness of data.
- Disadvantages: adding additional synchronization logic will lead to performance loss
2. Asynchronous message: if there are too many dependent parties, we usually send heterogeneous change data to the MQ message system. Interested businesses can subscribe to the message Topic, pull the message, and then process it according to their own business logic.
- Advantages: the architecture is decoupled and can be done asynchronously to reduce the performance loss of the main link. If there are multiple consumers, there will be no exponential performance superposition
- Disadvantages: asynchronous mechanism can not meet the real-time performance and has a certain delay. Only final consistency can be achieved.
The above two schemes are hard coded. Is there a general technical scheme. It doesn't care what business you are and what data you write. For the platform, it can be abstracted into MySQL tables and synchronize the table data directly. Only users really care about the data content.
You can refer to the master-slave synchronization principle of MySQL, pull binlog, and just parse the data in it.
The popular middleware is Ali's open source Canal. Today we'll make a technical scheme, which is roughly as follows:
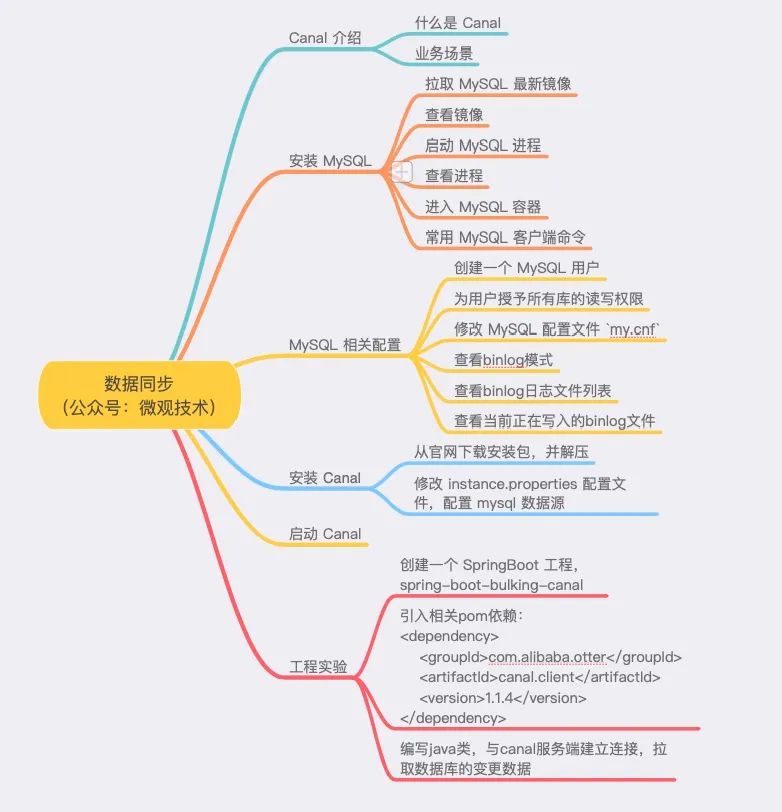
1, Canal introduction
Canal, which means waterway / pipeline / ditch, is mainly used for incremental log analysis based on MySQL database to provide incremental data subscription and consumption.
At the beginning of Canal's birth, it was to solve the pressure on the main database caused by data synchronization between multiple standby databases and the main database.
Slowly, this pipeline has been developed, and there are more and more application scenarios
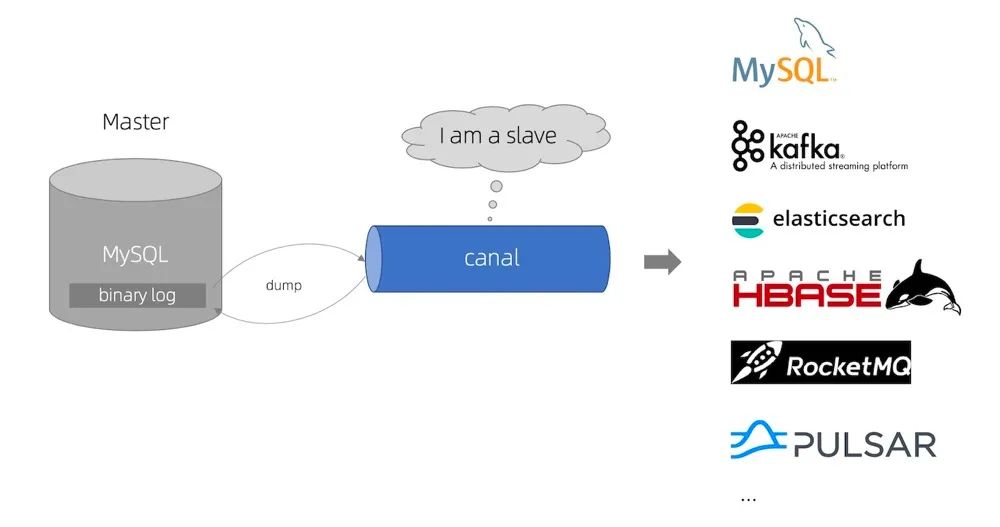
The working principle is very simple. Disguise yourself as a MySQL slave, simulate the interactive protocol of MySQL slave, and send a dump request to the MySQL master.
The MySQL master receives the dump request sent by canal and starts to push the binary log to canal. Then canal parses the binlog log and stores it in different storage media, such as mysql, Kafka, Elastic Search, Pulsar, etc
Business scenario:
- Real time database backup
- Construction and maintenance of ES data index
- Synchronous maintenance of distributed cache (e.g. Redis)
- The data is heterogeneous. Subscribers can subscribe and consume according to their own business needs, such as Kafka, Pulsar, etc
2, Install MySQL
1. Pull MySQL image
docker pull mysql:5.7
2. View mirror
docker images
3. Start MySQL process
docker run \ --name mysql \ -p 3306:3306 \ -e MYSQL_ROOT_PASSWORD=123456 \ -d mysql:5.7
4. View process
[root@iZbp12gqydkgwid86ftoauZ mysql]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e92827897538 mysql "docker-entrypoint.s..." 4 seconds ago Up 2 seconds 0.0.0.0:3306->3306/tcp, 33060/tcp mysql
5. Enter MySQL container
docker exec -it 167bfa3785f1 /bin/bash
Note: some problems may be encountered when modifying some configuration files, such as:
Handling method of bash: vi: command not found using vi or vim prompt in docker container
Because the vi editor is not installed, you can execute the following command
apt-get update apt-get install vim
6. MySQL client common commands
# Log in to mysql mysql -uroot -p111111 # Display database list show databases; # Select database use mysql; # Show all tables show tables; # Display table structure describe Table name; More commands: https://www.cnblogs.com/bluecobra/archive/2012/01/11/2318922.html
3, MySQL related configuration
Create a MySQL user with user name: tom and password: 123456
create user 'tom'@'%' identified by '123456';
Grant read and write permissions to all libraries for user: tom
grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'tom'@'%' identified by '123456';
Modify MySQL configuration file my CNF, location: / etc / my cnf
[mysqld] log-bin=mysql-bin # Enable binlog binlog-format=ROW # Select row mode server_id=1 # MySQL replacement configuration needs to be defined. It should not be repeated with the slaveId of canal
Note: you need to restart the MySQL container instance and execute the command docker restart mysql
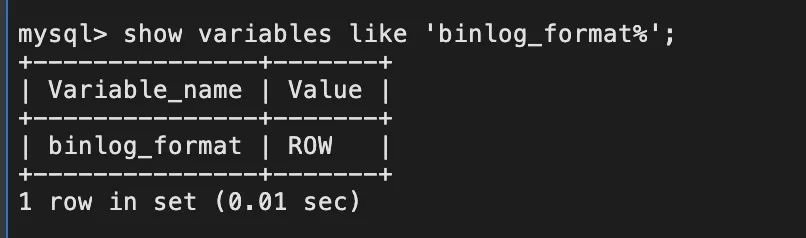
View binlog mode:
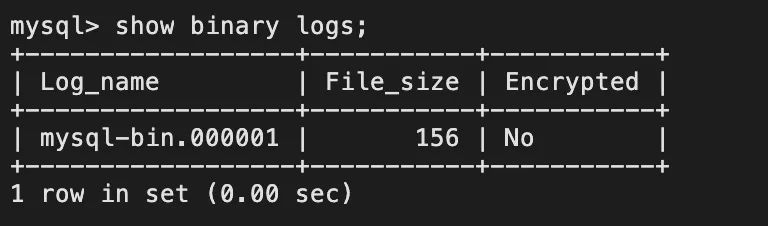
To view the list of binlog log files:
To view the binlog file currently being written:

4, Install Canal
1. Download the installation package from the official website
Download address: https://github.com/alibaba/canal/releases
This experiment uses the latest version v1 1.5, which is mainly personalized support for different clients, belongs to ecological expansion.
For more features, you can check it on the official website
Unzip tar GZ compressed package
tar -zxvf canal.deployer-1.1.5.tar.gz
Open the configuration file conf / example / instance Properties, modify the configuration as follows:
## v1. slaveId will be automatically generated after version 0.26, so you can not configure it # canal.instance.mysql.slaveId=0 # Database address canal.instance.master.address=127.0.0.1:3306 # binlog log name canal.instance.master.journal.name=mysql-bin.000001 # Starting binlog offset when linking mysql main database canal.instance.master.position=156 # Timestamp of binlog starting when linking mysql main database canal.instance.master.timestamp= canal.instance.master.gtid= # username/password # Account and password authorized on MySQL server canal.instance.dbUsername=root canal.instance.dbPassword=111111 # character set canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false # table regex .*\..* It means to listen to all tables. You can also write specific table names, separated by canal.instance.filter.regex=.*\\..* # The blacklist of mysql data analysis tables. Multiple tables are separated by canal.instance.filter.black.regex=
Start command
./startup.sh
Because Alibaba cloud ECS server is adopted, it is found that JAVA environment is not installed.
Download the installation package of JDK 8 from Oracle official website
Download address: https://www.oracle.com/java/technologies/downloads/#java8
Then, upload the installation package to the ECS server through the following command
scp jdk-8u311-linux-x64.tar.gz root@118.31.168.234:/root/java //Upload file
Install JDK 8 environment
file: https://developer.aliyun.com/article/701864
5, Start Canal
Enter canal deployer-1.1.5/bin
Execute startup script:
./startup.sh
Enter canal deployer-1.1.5/logs/example
If example The following contents appear in the log file, indicating that the startup is successful
2022-01-03 08:23:10.165 [canal-instance-scan-0] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - stop CannalInstance for null-example 2022-01-03 08:23:10.177 [canal-instance-scan-0] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - stop successful.... 2022-01-03 08:23:10.298 [canal-instance-scan-0] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example 2022-01-03 08:23:10.298 [canal-instance-scan-0] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$ 2022-01-03 08:23:10.298 [canal-instance-scan-0] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter : ^mysql\.slave_.*$ 2022-01-03 08:23:10.299 [canal-instance-scan-0] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful....
6, Engineering experiment
Create a SpringBoot project, spring boot bulking canal
Introducing related pom dependencies
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
Write a java class, establish a connection with the canal server, and pull the change data of the database
// create link
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
try {
//open a connection
connector.connect();
//Subscribe to all tables
connector.subscribe(".*\\..*");
//Rollback to the place without ack. The next fetch can start from the last place without ack
connector.rollback();
while (true) {
Message message = connector.getWithoutAck(BATCH_SIZE);
long batchId = message.getId();
printEntry(message.getEntries());
// batch id submission
connector.ack(batchId);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
connector.disconnect();
}
Create MySQL table under ds1 database
CREATE TABLE `person` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Auto increment primary key', `income` bigint(20) NOT NULL COMMENT 'income', `expend` bigint(20) NOT NULL COMMENT 'expenditure', PRIMARY KEY (`id`), KEY `idx_income` (`income`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='Personal income and expenditure statement';
Insert a record:
insert into person values(100,1000,1000);
The Java class parses binlog and prints the change log on the console:
binlog[mysql-bin.000002:1946] , table[ds1,person] , eventType : INSERT id : 100 update=true income : 1000 update=true expend : 1000 update=true
Modify the record with id=100:
update person set income=2000, expend=2000 where id=100;
Console print change log:
binlog[mysql-bin.000002:2252] , table[ds1,person] , eventType : UPDATE ------->; before id : 100 update=false income : 1000 update=false expend : 1000 update=false ------->; after id : 100 update=false income : 2000 update=true expend : 2000 update=true