1. architecture
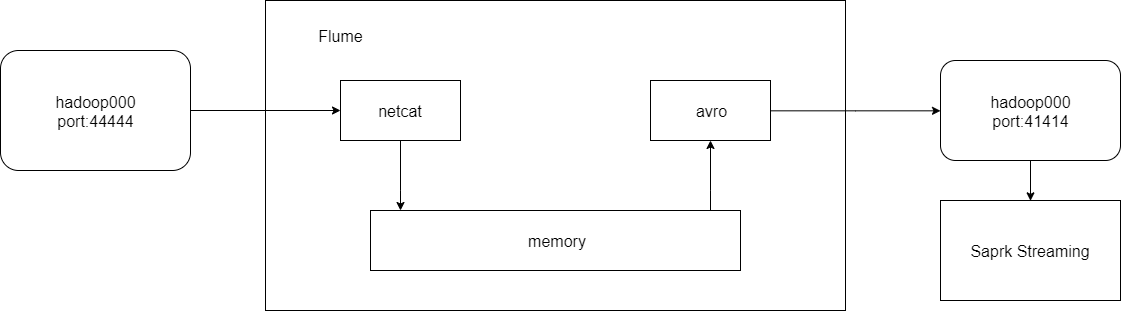
2.Flume configuration
Create a new configuration file under $flume \ home / conf: flume \ push \ streaming.conf
The configuration idea is as follows:
- source select netcat and configure the host name and port
- Select avro for sink, and configure the host name and port
- channel select memory
- Connect source and channel
- Connect sink and channel
simple-agent.sources = netcat-source simple-agent.sinks = avro-sink simple-agent.channels = memory-channel simple-agent.sources.netcat-source.type = netcat simple-agent.sources.netcat-source.bind = hadoop000 simple-agent.sources.netcat-source.port = 44444 simple-agent.sinks.avro-sink.type = avro simple-agent.sinks.avro-sink.hostname = hadoop000 simple-agent.sinks.avro-sink.port = 41414 simple-agent.channels.memory-channel.type = memory simple-agent.sources.netcat-source.channels = memory-channel simple-agent.sinks.avro-sink.channel = memory-channel
3. Written by spark streaming
pom.xml plus:
<!--SS integration Flume rely on-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
The compilation ideas are as follows:
- Judge whether the input parameter is 2 -- host address and port number
- args accept port number
- After creating the SparkConf object, it is passed to the StreamingContext object. You need to specify the refresh time
- Using the createStream method in FlumeUtils to get Flume stream data
- Note that Flume has head and body during transmission, so you need to add x.event.getBody.array() to get data, and then trim to test the space
- Then there is the normal wordcount operation on its data
- Finally, open ssc and wait
package com.taipark.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Spark Streaming The first way to integrate Flume
*/
object FlumePushWordCount {
def main(args: Array[String]): Unit = {
if(args.length != 2){
System.err.println("Usage:FlumePushWordCount <hostname><port>")
System.exit(1)
}
val Array(hostname,port) = args
val sparkConf = new SparkConf()//.setMaster("local[2]").setAppName("FlumePushWordCount")
val ssc = new StreamingContext(sparkConf,Seconds(5))
val flumeStream = FlumeUtils.createStream(ssc,hostname,port.toInt)
flumeStream.map(x=>new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
.print(10)
ssc.start()
ssc.awaitTermination()
}
}
After writing, we pack it with maven and upload it to the server.
First, run the jar package with spark submit. Note that you need to bring the spark streaming flume_2.11 package with you.
The parameters to be specified are:
- Running classes
- master
- Dependency package
- Running package
- Host name and port
spark-submit \ --class com.taipark.spark.FlumePushWordCount \ --master local[2] \ --packages org.apache.spark:spark-streaming-flume_2.11:2.2.0 \ /home/hadoop/tplib/sparktrain-1.0.jar \ hadoop000 41414
Next, open Flume:
The parameters to be specified are:
- flume name (same as in configuration)
- Configuration address
- configuration file
- Logs are displayed on the console
flume-ng agent \ --name simple-agent \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/conf/flume_push_streaming.conf \ -Dflume.root.logger=INFO,console
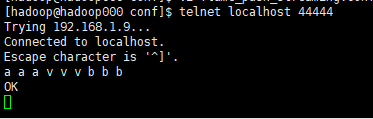
Finally, open port 44444 for data transmission test (by the way, the way to turn off telnet is ctrl +], and then input quit):
telnet localhost 44444
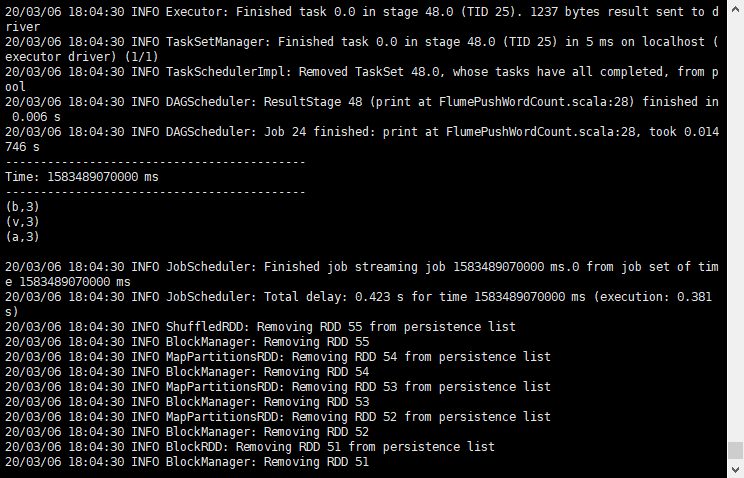
The console running in the jar package can get the output result:
complete

