What I wrote earlier: recording the content of video coding course is for learning and consolidation. I hope you can correct what's wrong. Thank you very much. There are few introductions, mainly to facilitate their own review. I don't want to listen and study in class, so I read the paper with my roommate. I think back to the video coding content and find that I have forgotten a lot of useful things, so I still record it. I'm afraid I won't read the report in the future. I can't understand the code I wrote. I don't want to sort out the contents of the first two experiments. This experiment really costs a lot of energy, but it also gains a lot. The two schematic diagrams in this paper are from the PPT in the course.
Some key codes are attached at the end of the article for reference only. Please go to my resource area to download the detailed codes. Otherwise, children don't have points to download some things. Only 2 points are needed. All contents are only for learning!
1. Experimental requirements
- When the block size takes 16 * 16 and 4 * 4 as the basic units and the search area is 32 * 32 and 64 * 64 respectively, the integer pixel level motion estimation is carried out to obtain the residual images and motion vectors in four different cases.
- After DCT transformation and quantization of the obtained residual image, do inverse quantization and inverse transformation (the quantization step can be selected as 4 or 8, and try to compare the experimental effect), reconstruct and restore the current image by using the previous video image, and compare the visual quality between the decoded image and the original image.
2. Theoretical analysis
Compression involves a pair of complementary systems, a compressor (encoder) and a decompressor (decoder). Encoder / decoder pairs are commonly referred to as CODEC. For video compression, it is necessary to remove the redundancy in time domain and space domain.
Motion compensation is used. Motion compensation is a method to describe the difference between adjacent frames (adjacent here means adjacent in coding relationship, and two frames may not be adjacent in playback order). Specifically, it describes how each small block of the previous frame moves to a certain position in the current frame. Its purpose is to improve the compression ratio by eliminating redundancy. Different blocks were used in this experiment_ Size (4, 16) and search_area (32, 64) performs motion compensation, that is, block motion compensation, in which the size of translation is the obtained motion vector.
DCT transformation and quantization are a prerequisite for image compression. The experimental requirement is to use quantization with steps of 4 and 8, and Zigzag coding is not used, but compression has been carried out to a certain extent, and the smaller value has been removed.
Coding flow chart of two consecutive frames (the picture is a little blurred, cut from the report, zoom in):
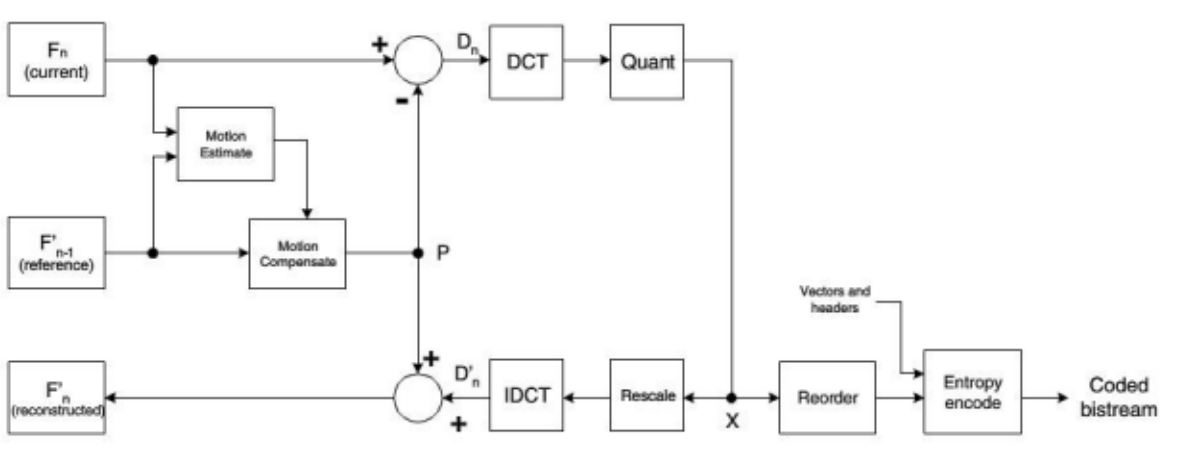
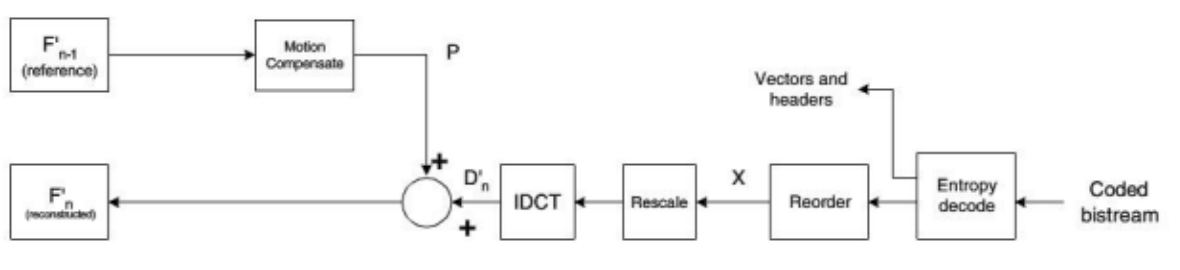
Decoding flow chart of two consecutive frames:
3. Experimental process
- Take two frames of images from the video and cut them
video_full_path="./videoData/data.flv"
cap = cv2.VideoCapture(video_full_path)
print(cap.isOpened())
num = 1
for _ in range(2):
success, frame = cap.read()
params = []
params.append(1)
cv2.imwrite(f"videoData/capture_{num}.jpg", frame, params)
num += 1
cap.release()
image_files = glob.glob('./videoData/*.jpg')
capture_1_ori = cv2.imread(image_files[0])
capture_2_ori = cv2.imread(image_files[1])
capture_1 = capture_1_ori[200:712, 700:1212]
capture_2 = capture_2_ori[200:712, 700:1212]

-
Convert to Y channel and display grayscale image
-
Use block separately_ size=4,search_area=32; block_size=4,search_area=64; block_size=16,search_area=32; block_size=16,search_area=64 for motion estimation and drawing the motion vector field.
block_size=4,search_ Motion vector field with area = 32:

block_size=4,search_ Motion vector field with area = 64:

block_size=16,search_ Motion vector field with area = 32:

block_size=16,search_ Motion vector field with area = 64:

- The predicted image is displayed and compared with the first two frames

- Get the residual image

-
Perform DCT transformation
-
For quantization, first take step=4 for quantization. At this time, for block_size=4,search_ Most of the results of area = 32 are 0, so step=2 is used for quantization for the second time
-
Inverse quantization, IDCT transform
Reconstructed residual image with step=4:

Reconstructed residual image with step=2:

- According to the saved motion vector, the final reconstruction effect is not ideal (there is a serious blocking effect)

- Calculate PSNR

4. Experimental analysis
- Problems encountered in the experiment:
- When the image is too large, the amount of calculation is large, so it is cropped.
- When matching the edge image, the problem of crossing the boundary is handled by supplementing 0.
- Result analysis
- 1) Acquired motion vector problem
- I have stored two parts. One part is used to draw the motion vector field, and the other part is to save the relative vector, that is, a search_ Coordinate vector in area. This is because drawing the motion vector field requires a global coordinate, but reconstruction requires the relative coordinates in a small area.
- 2) The residual image part, from the result diagram, has achieved the expected effect
- 3) After DCT transformation, the value of the upper left corner is not the maximum value, so try to inverse transform it directly. It is found that it can be reconstructed losslessly, so the possibility of error is ruled out.
- 4) After observing the reconstructed image, the theoretical analysis should conclude that the reconstructed image should be no different from the original image, but the reconstructed image has poor effect and serious block effect. For this, I analyze the following two points
- a) Problem with relative vector recording
- b) There is a problem with the relative vector obtained during reconstruction
- c) Quantization step size problem
- d) It may be that the change difference of the selected image is too small
- If it is a), the motion vector drawn may not be accurate enough, but from my point of view, the program should have no problem. (add your own analysis process to the code and display the image. The results are in line with the theoretical analysis, so the reason has not been found, as shown in the following figure to compare the matched pixel blocks)

- 5) The reconstructed image with steps of 2 and 4 has the same psnr value as the second frame image. On the basis of 4), I think the obtained step still does not meet the needs of the image sample, and more experiments are still needed.
- 6) Another problem with psnr is that step=4, but search_ The psnr value with area of 32 is greater than that of 64, which is inconsistent with the theoretical analysis. According to personal analysis, it is the same problem as 4).
Summary: first, we can see from the image that for different block sizes and search_ Area size, the reconstructed effect is different. The wider the matched area (the smaller the block, the larger the search_area), the closer the reconstructed image is to the original image. This coding method can effectively compress the video frame and reduce the transmission pressure. However, it can not make the block small and search unlimited_ Area is large because its motion vector needs to be recorded in image reconstruction. The wider the matching area, the more motion vectors need to be recorded, and vice versa. Both of them need to be transmitted, so different coding strategies should be adopted for different videos in the transmission process, so as to maximize the benefit of transmission.
5. Parts of the experiment that need to be improved
- Replace two images and do another experiment
- The process of viewing its intermediate variables for each step
- The experiment was carried out by changing different quantization steps
- It can only be processed for images with multiple side length of 64 and consistent length and width. The reason why this part is not perfect is that many factors need to be considered. At that time, the experiment was very time-consuming and did not improve any more
6. Some key codes
- Obtain the predicted image and motion vector
def get_preimage_motions(width, height, block_sizes, search_areas):
width_num = width // block_sizes
height_num = height // block_sizes
# Number of motion vectors
vet_nums = width_num * height_num
# Used to save motion vectors and coordinate values
motion_vectors = []
# Give null value first
motion_vectors = [[0, 0] for _ in range(vet_nums)]
motion_vectors_for_draw = [[0, 0, 0, 0] for _ in range(vet_nums)]
similarity = 0
num = 0
end_num = search_areas//block_sizes
# Calculation interval, used to make up 0
interval = (search_areas-block_sizes)//2
# Construct a template image and add 0 to the previous frame image
mask_image_1 = np.zeros((width + interval*2, height + interval*2))
mask_image_1[interval:mask_image_1.shape[0]-interval, interval:mask_image_1.shape[1]-interval] = capture_1_Y
mask_width, mask_height = mask_image_1.shape
predict_image = np.zeros(capture_1_Y.shape)
# count = 0
for i in range(height_num):
for j in range(width_num):
# count += 1
# print(f'==================i:{i}=j:{j}==count:{count}=====================')
temp_image = capture_2_Y[i*block_sizes:(i+1)*block_sizes, j*block_sizes:(j+1)*block_sizes]
mask_image = mask_image_1[i*block_sizes:i*block_sizes+search_areas, j*block_sizes:j*block_sizes+search_areas]
# Given initial value for comparison
temp_res = mad(mask_image[:block_sizes, :block_sizes], temp_image)
for k in range(end_num):
for h in range(end_num):
# Take a template
temp_mask = mask_image[k*block_sizes:(k+1)*block_sizes, h*block_sizes:(h+1)*block_sizes]
# Calculate mad
res = mad(temp_mask, temp_image)
# If it is greater than the default value, it will be set as the default value, and the predicted image will be assigned to replace the current motion vector
if res <= temp_res:
temp_res = res
motion_vectors[i*j+j][0], motion_vectors[i*j+j][1] = k, h
motion_vectors_for_draw[i*j+j][0], motion_vectors_for_draw[i*j+j][1], motion_vectors_for_draw[i*j+j][2], motion_vectors_for_draw[i*j+j][3] = i+k, height_num-(j+h), i+interval/block_sizes, height_num-(j+interval/block_sizes)
predict_image[i*block_sizes:(i+1)*block_sizes, j*block_sizes:(j+1)*block_sizes] = temp_mask
# print(motion_vectors_for_draw[i*j+j])
return np.array(predict_image), np.array(motion_vectors), np.array(motion_vectors_for_draw)
- Rebuild code
def restruct_image(width, height, block_sizes, search_areas, motion_vectors, residual_image, pre_frame):
width_num = width // block_sizes
height_num = height // block_sizes
# Number of motion vectors
vet_nums = width_num * height_num
end_num = search_areas//block_sizes
# Calculation interval, used to make up 0
interval = (search_areas-block_sizes)//2
# Construct a template image and add 0 to the previous frame image
mask_image_1 = np.zeros((width + interval*2, height + interval*2))
mask_image_1[interval:mask_image_1.shape[0]-interval, interval:mask_image_1.shape[1]-interval] = pre_frame
restruct_image = np.zeros((width, height))
for i in range(height_num):
for j in range(width_num):
temp_image = residual_image[i*block_sizes:(i+1)*block_sizes, j*block_sizes:(j+1)*block_sizes]
mask_image = mask_image_1[i*block_sizes:i*block_sizes+search_areas, j*block_sizes:j*block_sizes+search_areas]
# Given initial value for comparison
k, h = motion_vectors[(i*j)+j][0], motion_vectors[(i*j)+j][1]
restruct_image[i*block_sizes:(i+1)*block_sizes, j*block_sizes:(j+1)*block_sizes] = temp_image + mask_image[k*block_sizes:(k+1)*block_sizes, h*block_sizes:(h+1)*block_sizes]
return np.array(restruct_image, dtype=np.uint8)
restruct_image_4_32 = restruct_image(width, height, 4, 32, motion_vectors_4_32, y_idct_4_32_recover_4, capture_1_Y)
restruct_image_4_64 = restruct_image(width, height, 4, 64, motion_vectors_4_64, y_idct_4_64_recover_4, capture_1_Y)
restruct_image_16_32 = restruct_image(width, height, 16, 32, motion_vectors_16_32, y_idct_16_32_recover_4, capture_1_Y)
restruct_image_16_64 = restruct_image(width, height, 16, 64, motion_vectors_16_64, y_idct_16_64_recover_4, capture_1_Y)
plt.figure(figsize=(10,10))
plt.subplot(221)
# plt.xticks([])
# plt.yticks([])
plt.xlabel('(a) 4_32')
plt.imshow(restruct_image_4_32, cmap='gray')
plt.subplot(222)
# plt.xticks([])
# plt.yticks([])
plt.xlabel('(b) 4_64')
plt.imshow(restruct_image_4_64, cmap='gray')
plt.subplot(223)
# plt.xticks([])
# plt.yticks([])
plt.xlabel('(c) 16_32')
plt.imshow(restruct_image_16_32, cmap='gray')
plt.subplot(224)
# plt.xticks([])
# plt.yticks([])
plt.xlabel('(d) 16_64')
plt.imshow(restruct_image_16_64, cmap='gray')
psnr_4_32_2 = compute_psnr(restruct_image_4_32_2, capture_2_Y)
psnr_4_64_2 = compute_psnr(restruct_image_4_64_2, capture_2_Y)
psnr_16_32_2 = compute_psnr(restruct_image_16_32_2, capture_2_Y)
psnr_16_64_2 = compute_psnr(restruct_image_16_64_2, capture_2_Y)
print(f'The psnr of 4_32_2 is {psnr_4_32_2:.4f}.')
print(f'The psnr of 4_64_2 is {psnr_4_64_2:.4f}.')
print(f'The psnr of 16_32_2 is {psnr_16_32_2:.4f}.')
print(f'The psnr of 16_64_2 is {psnr_16_64_2:.4f}.')
- Calculate PSNR
def compute_psnr(img_in, img_sam):
assert img_in.shape == img_sam.shape, "The sample image's shape is not same as the input!"
mse = np.mean( (img_in/255. - img_sam/255.) ** 2 )
if mse < 1.0e-10:
return 100
return 20 * np.log10(1 / np.sqrt(mse))