When debugging with pychart debug, an error is reported:
Traceback (most recent call last):
File "C:\PyCharm 2018.2.4\helpers\pydev\_pydevd_bundle\pydevd_comm.py", line 399, in _on_run
self.process_command(cmd_id, int(args[1]), args[2])
File "C:\PyCharm 2018.2.4\helpers\pydev\_pydevd_bundle\pydevd_comm.py", line 414, in process_command
self.process_net_command(self.global_debugger_holder.global_dbg, cmd_id, seq, text)
File "C:\PyCharm 2018.2.4\helpers\pydev\_pydevd_bundle\pydevd_process_net_command.py", line 732, in process_net_command
py_db.writer.add_command(cmd)
File "C:\PyCharm 2018.2.4\helpers\pydev\_pydevd_bundle\pydevd_comm.py", line 436, in add_command
self.cmdQueue.put(cmd)
AttributeError: 'Queue' object has no attribute 'put'
Can't process net command: 501 1 0.1 WINThe scenario is a code file, which is created and edited on the mac
I deleted the whole document
Run again or report an error:
pydev debugger: process 18600 is connecting
Could not connect to 127.0.0.1: 52272
Traceback (most recent call last):
File "C:\PyCharm 2018.2.4\helpers\pydev\pydevd.py", line 1649, in main
debugger.connect(host, port)
File "C:\PyCharm 2018.2.4\helpers\pydev\pydevd.py", line 328, in connect
self.initialize_network(s)
File "C:\PyCharm 2018.2.4\helpers\pydev\pydevd.py", line 315, in initialize_network
self.writer = WriterThread(sock)
File "C:\PyCharm 2018.2.4\helpers\pydev\_pydevd_bundle\pydevd_comm.py", line 427, in __init__
self.cmdQueue = _queue.Queue()
AttributeError: module 'queue' has no attribute 'Queue'The reason has not been found yet
However, you can debug by copying the code to the py file created in Windows
https://blog.csdn.net/weixin_30707875/article/details/95807037
In the normal test work, it is necessary to manufacture test data. In a recent project, I need to make a batch of files that can be read correctly under UNIX. In order to ensure that these files can be successfully downloaded from FTP, the developer told me: "if line breaks are encountered in the file, the line break character must be LF under UNIX, not CRLF under Dos\Windows."
Line feed, in ordinary document editing, is to press the "Enter" key. When writing code, you write the string "\ n" in the file. However, after the python command w is used to write the newline "\ n" to the file, because it is a Windows system, it will actually save "\ n" as "\ r\n" by default.
As for why it is "\ r\n" under windows, the online explanation is quoted here: because Windows adopts the traditional English typewriter mode, it needs to be divided into two steps during line feed - enter "\ r" and line feed "\ n". Carriage return (CR) is to return the trolley to the starting point, which is equivalent to switching the cursor from the end of the line to the beginning of the line. Line feed (LF) is to switch the trolley to the next line. This combined operation completes the purpose of starting another line.
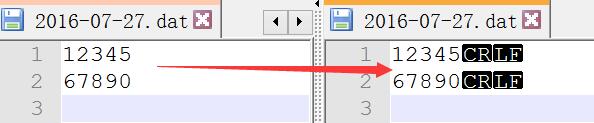
Let's first confirm whether the line feed under windows is really CRLF: open the file with any text editor (taking Notepad + + as an example), find the "view" menu in the menu bar of the editor, click "display symbol", and check "display all characters" to display the line feed. As we can see in the figure below, the line feed character in the file is indeed CRLF under Windows system.
How to turn CRLF into LF? The development gives a solution.
Method A:
In the lower right corner of the Notepad + + interface, double-click the description of the current file format: "Dos\Windows", click "convert to UNIX format" in the pop-up box, and finally save the file. At this point, you can see that the end of each line of the file has been displayed as "LF".

Although the whole conversion process is very simple, if a large number of such files need to be manually converted one by one, i can't help feeling light (x) ī n) Yin (h) ǎ o) Virtual (l è i) degree, Shao (b ù) light (xi) ǎ ng) perishable.
After protesting, the developer said that this method could be optimized, that is, using the replacement function of the text editor:
Method B:
Open the original file with Notepad + +, press Ctrl+F, select the "replace" column in the pop-up box, fill in "\ r\n" in the "find target" input box, fill in "\ n" in the "replace with" input box, and select "extend (\ n\r\t n \ R \ t \ 0 \ x.\x...)" in the "find mode", Click "replace all open files" and save the files one by one.
However, saving all the files did not improve the happiness of the test. What I pursue is to minimize repetitive and heavy manual labor, liberate my hands and test efficiently! Such capacity bottlenecks have been occupying my spare time since I entered the testing industry. In order to better improve myself and systematically learn the skills necessary for test development, I signed up for Wu Lao's test development training class.
Up to now, Mr. Wu has been teaching for more than two months. I have learned a lot of basic python development knowledge from scratch, and occasionally come into contact with some ingenious programming thinking. Just this data preparation provided me with a practical opportunity to experience the fun of local automation by using my recently learned file operation knowledge.
Now let's share my happy practice. Because the real test data is a little complex, let's take a simple two-line number as an example.
First, create a file and write the text content using Notepad + + according to the content of the class:
1 #Coding: UTF-8 (set file coding format)
2 import os
3 import time
4
5 #Switch to the create file directory
6 os.chdir(r"C:\Study\Chestnuts\01data")
7
8 #New create file function
9 def create_file():
10
11 #Construction file name: the file name is "mm / DD / yyyy" dat file
12 t=time.localtime()
13 file_name=time.strftime("%Y-%m-%d",t)+".dat"
14 #Create and open files
15 fp=open(file_name,'w+')
16 #Write file contents
17 fp.writelines("12345\n")
18 fp.writelines("67890\n")
19 #Close file
20 fp.close()
21
22 #Call function
23 create_file()As shown in the figure above, executing the script will generate an original file, but at the end of the two lines, the newline character is displayed as CRLF, and the next step is the conversion.
Method C: format conversion of the original file
If you are processing an existing file, you can use Notepad + + to write another conversion script. Referring to the method on the Internet, read the file content in rU mode and write the file content in wb mode, as shown in the following figure:
1 #coding:utf-8 2 import os 3 4 #File path preparation 5 route=r"C:\Study\Chestnuts\01data" 6 7 #Traverse directories, folders and files under the path 8 for root,dirs,files in os.walk(route): 9 #Traversal file 10 for name in files: 11 #Inductive file name characteristics 12 if name[-3:]=='dat': 13 #Splice file name (directory + file name) 14 catalog=os.path.join(root,name) 15 #Replace all line splitters with line breaks \ nreturn 16 fp=open(catalog,"rU+") 17 #Read the file and save it 18 strings=fp.read() 19 fp.close() 20 #Write files using binary 21 fp1=open(catalog,"wb") 22 fp1.seek(0) 23 fp1.write(strings) 24 fp1.flush() 25 fp1.close()
By executing this script, you can convert the existing file format to a file with line feed LF.
The result is right, but executing two scripts to generate a final file inevitably makes me feel that it is not simple enough. After analyzing the above file conversion code, I found that the key step is to write the file in binary (wb) mode.
Method D: the original file is written in binary mode
In that case, it's better to use binary to write files at the beginning, one step in place! And just change the write mode (w) in the source code into binary write (wb) mode. You see, just adding one letter saves more than a dozen lines of code and achieves the expected goal. It can be said to kill many birds with one stone!
#Coding: UTF-8 (set file coding format)
import os
import time
#Switch to the create file directory
os.chdir(r"C:\Study\Chestnuts\01data")
#New create file function
def create_file():
#Construction file name: the file name is "mm / DD / yyyy" dat file
t=time.localtime()
file_name=time.strftime("%Y-%m-%d",t)+".dat"
#Create and open files
fp=open(file_name,'wb+')
#Write file contents
fp.writelines("12345\n")
fp.writelines("67890\n")
#Close file
fp.close()
#Call function
create_file()The above code optimization reminds me that I need to think more, clarify the logic, and finally find the best solution to achieve my goal. When practicing writing code, we should not only carefully analyze the requirements and decompose the steps, but also pay attention to accumulate good methods for precipitation, which is also the purpose of this article.
If you encounter similar difficulties in testing, feel that you are lack of ability, and expect to solve the problem by writing your own code, you are welcome to consult me or Mr. Wu. You can join our "glorious path python group (457561756)" to ask questions, or you can come to Mr. Wu's test development training class to learn together. For more comprehensive promotion, richer treatment and better life, let's fight together on the road of glory!