1. Introduction
Little loser: brother Yu, the Chinese New Year is coming soon. lol can't be whole!
Xiaoyu: No, I want to learn

Loser: are you telling me a joke about the end of the year of the ox?
Xiaoyu: finish?? Hey ~ thanks, brother, you reminded me!
Little loser:... Thanks to me, too. Meow
The Chinese New Year is just around the corner. In the closing battle of the year of the ox, we have a whole happy and happy thing: download the pictures of Qin and Se fairies and act as screensavers.
2. Code practice
2.1 web page analysis
Idea:
- 1. First log in to lol's official website and query the url of known heroes
- 2. Check the url of each hero and find out the rules
It's that simple,
1, Let's log in to lol's official website and check the url addresses of all heroes:
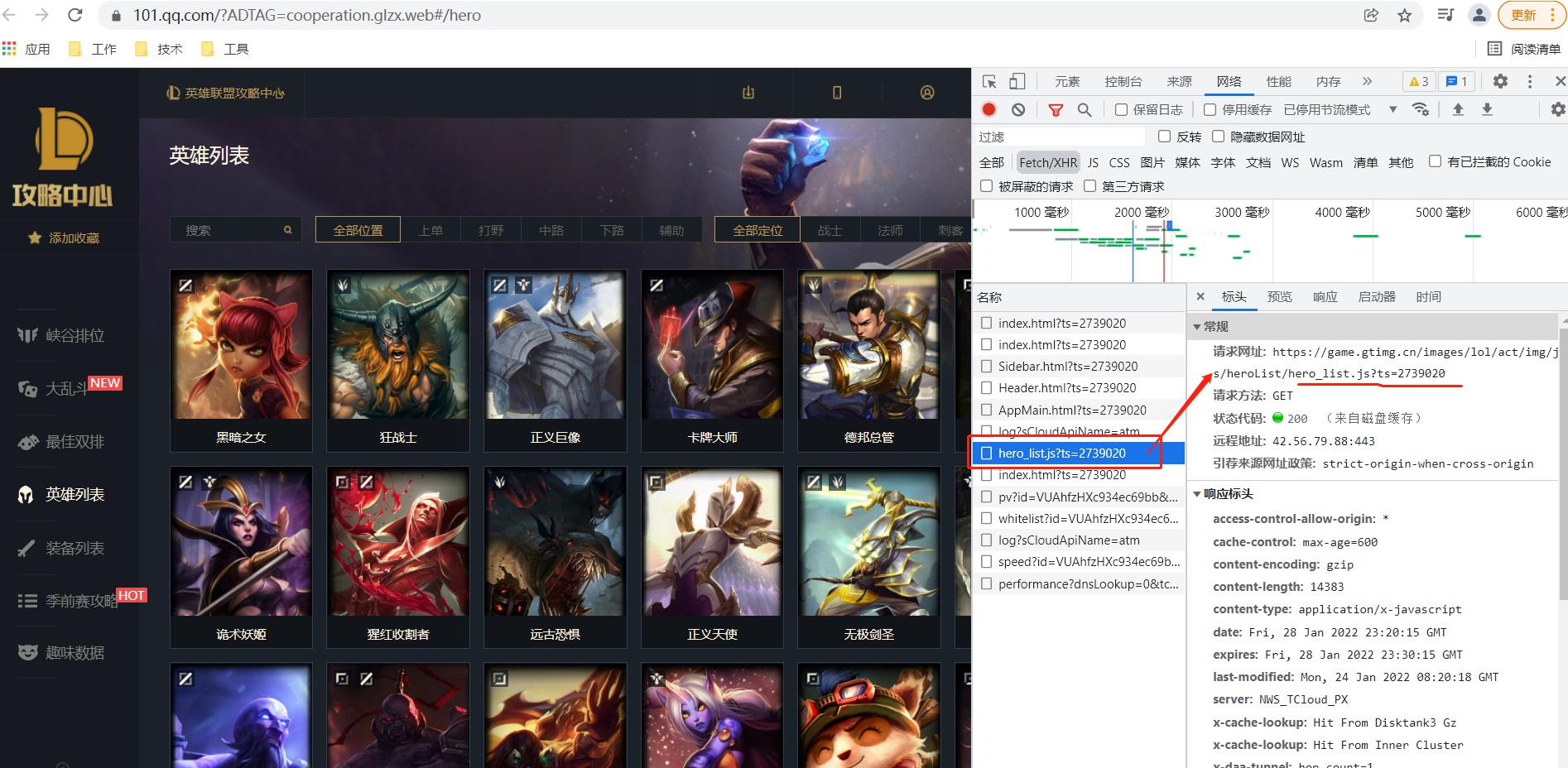
You can see that the url of the hero list is hero_list.js
https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2739020
2, View the url address of each hero
Sona
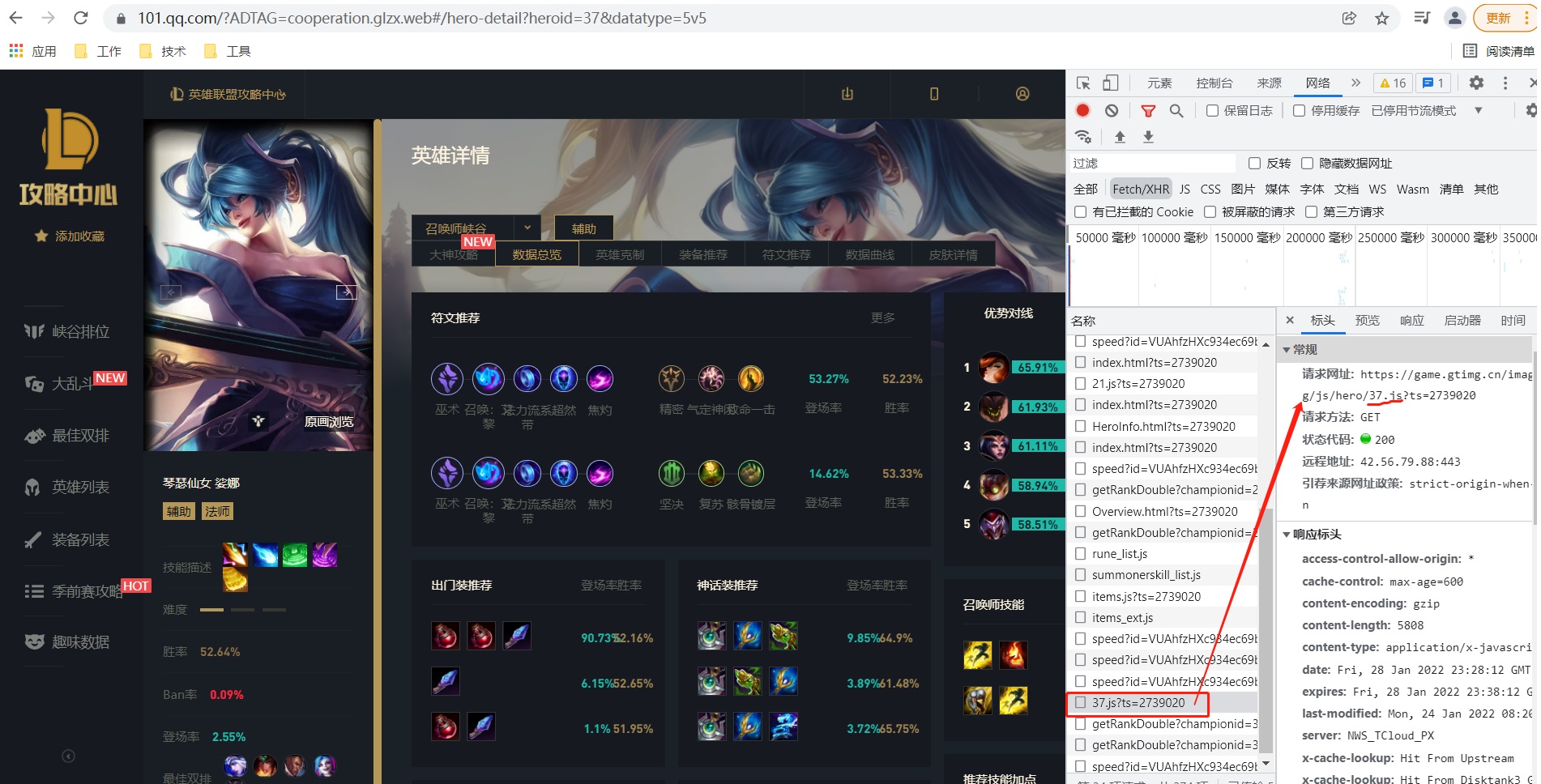
https://game.gtimg.cn/images/lol/act/img/js/hero/37.js?ts=2739020
Leona
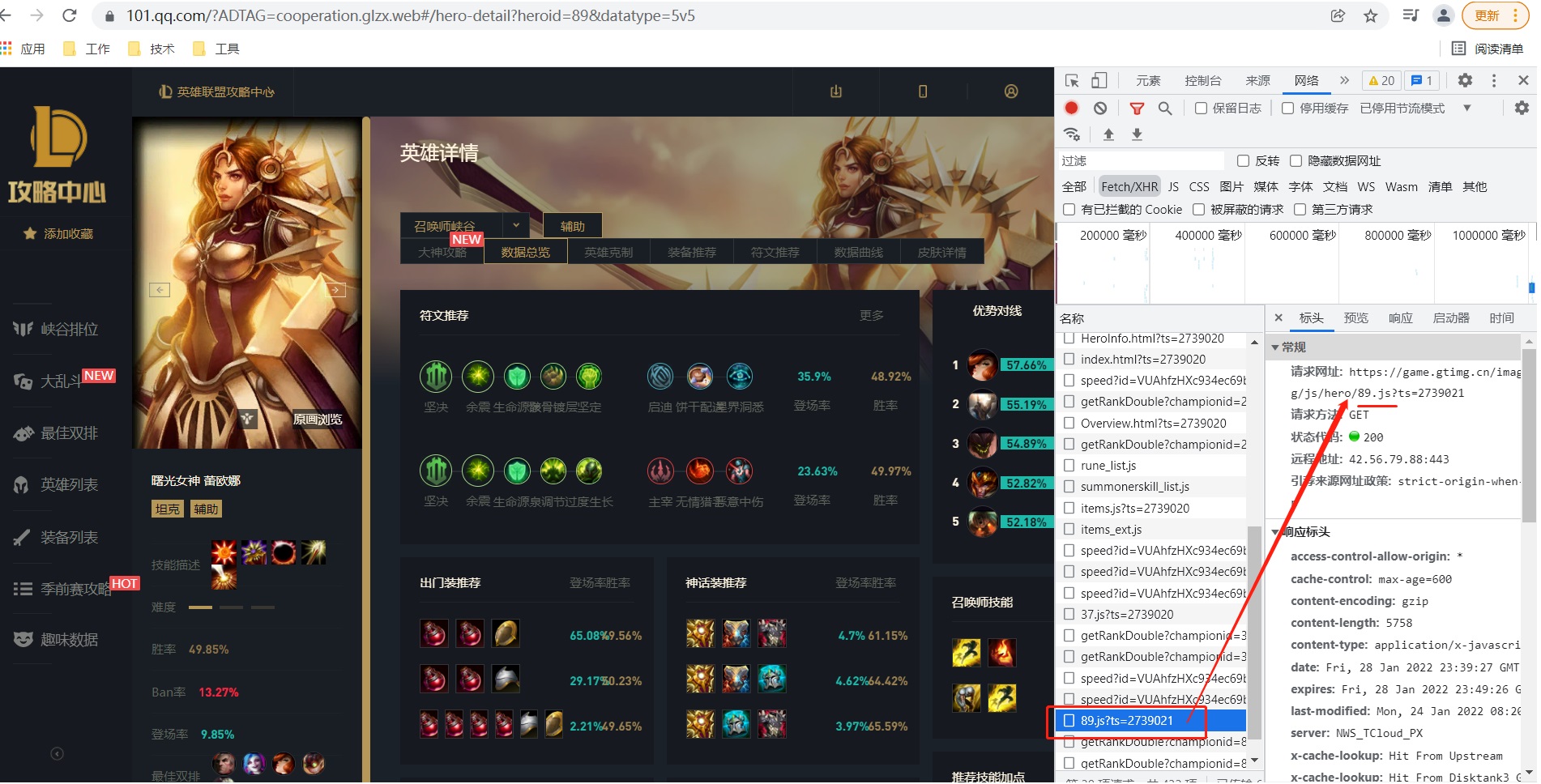
https://game.gtimg.cn/images/lol/act/img/js/hero/89.js?ts=2739021
Therefore, we can conclude that each hero's is spliced by heroId.
2.2 code practice
2.2.1 module installation
Because lol has more heroes,
If we download all heroes in a single thread, it will take us a long time.
Little loser: brother fish, multithreading, let's go!
Xiaoyu: it's time for multithreading to go home for the Chinese New Year. Let's change our way today.
Little loser: city people are really good at playing. Who is going to change today??
Xiaoyu: Xie Cheng.
Little loser: ouch, hey, this is OK. It's fresh.
Xiaoyu: it's new year. I have to change my taste.
Far away ~ it's really free to see the high-speed. It's going to drag racing.
Module installation
pip install gevnet
Other installation methods:
<Python 3, choose Python to automatically install the third-party library, and then say goodbye to pip!!>
<Python 3: I import all Python libraries with only one line of low-key code!!>
2.2.2 process, collaboration and thread differences
difference:
- The process is the unit of resource allocation. The thread is the one that really executes the code, and the thread is the one that the operating system really schedules
- Thread is the unit of operating system scheduling
- Process switching takes up a lot of resources and is not as efficient as threads. Processes take up more resources and threads take up less resources. What is less than threads is coprocessing
- A coroutine depends on a thread. A thread depends on a process. When a process dies, the thread will die. When a thread dies, the coroutine will die
- Generally, multi processes are not used, but threads are used. If there are many network requests in threads, the network may be blocked. At this time, it is more appropriate to use collaborative processes
- Multi process and multi thread may be parallel depending on the number of cpu cores, but the co process is in one thread, so it is concurrent
2.2.3 code example
Code example
# -*- coding:utf-8 -*-
# @Time : 2022-01-29
# @Author : carl_DJ
import gevent
from gevent import monkey
import requests ,os,re
import datetime
'''
Download the skins of all heroes
'''
#Automatically capture blocking conditions
monkey.patch_all()
#Set header
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
#Set download path
data_path = 'D:\Project\Hero skin'
#Create pat. If not, it will be created automatically
def mkdir(path):
if not os.path.exists(path):
os.mkdir(path)
#Crawling content setting
def crawling():
start_time = datetime.datetime.now()
print(f'Start execution time:{start_time}')
#Crawl url
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
#Response content
response = requests.get(url=url,headers=header)
heros = response.json()['hero']
index = 0
task_list = []
for hero in heros:
index = index + 1
#heroId acquisition
heroId = hero['heroId']
#Each hero_url pass in the corresponding heroId
hero_url = f'https://game.gtimg.cn/images/lol/act/img/js/hero/{heroId}.js'
hero_resp = requests.get(url = hero_url,headers=header)
skins = hero_resp.json()['skins']
#Will get_pic and skins are set as collaborative processes to realize concurrent execution
task = gevent.spawn(get_pic,skins)
task_list.append(task)
if len(task_list) == 10 or len(skins) == index:
#Start collaboration
gevent.joinall(task_list)
task_list = []
end_time = datetime.datetime.now()
print(f'Download end time:{end_time}')
print(f'Co execution{end_time - start_time}')
#Get picture
def get_pic(skins):
for skin in skins:
#Address naming
dir_name = skin['heroName'] + '_' + skin['heroTitle']
#Picture naming,
pic_name = ''.join(skin['name'].split(skin['heroTitle'])).strip();
url = skin['mainImg']
if not url:
continue
invalid_chars = '[\\\/:*?"<>|]'
pic_name = re.sub(invalid_chars,'',pic_name)
#Execute download content
download(dir_name,pic_name,url)
#Perform Download
def download(dir_name,pic_name,url):
print(f'{pic_name} Already downloaded,{url}')
#Create the downloaded folder and format the folder name
dir_path = f'{data_path}\{dir_name}'
if not os.path.exists(dir_path):
os.mkdir(dir_path)
#Crawl url
resp = requests.get(url,headers=header)
#Download pictures to write folder
with open(f'{dir_path}\{pic_name}.png', 'wb') as f:
f.write(resp.content)
print(f'{pic_name} Download complete')
# finish_time = datetime.datetime.now()
# print(f 'download completion time: {finish_time}')
if __name__ == '__main__':
mkdir(data_path)
crawling()
results of enforcement
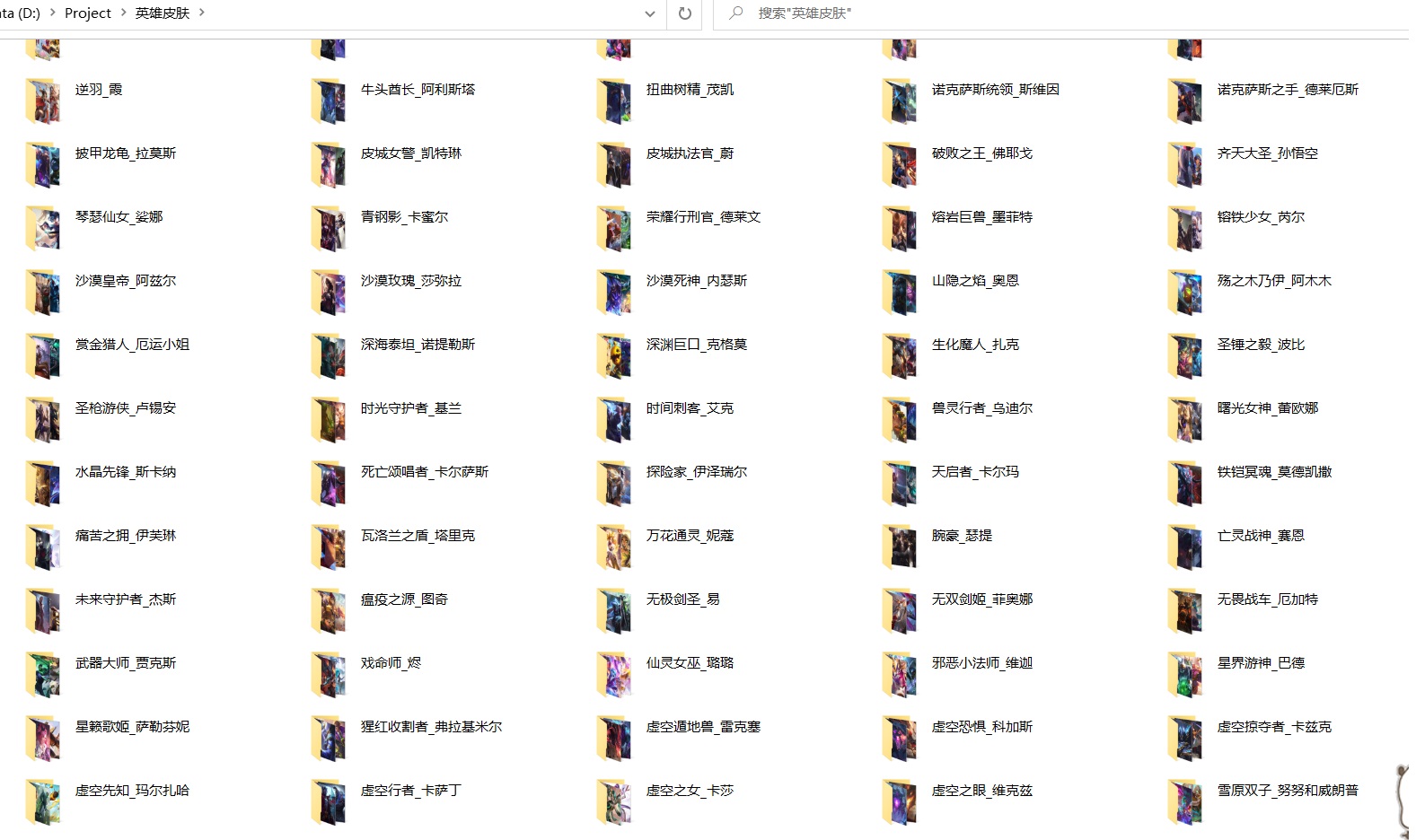
Zoom in and look at the goddess.

3. Summary
See here, today's share is here.
Today, we mainly download pictures in batches through collaborative process.
The use of gevent is not introduced in this blog post,
But this is the routine of small fish.
Because Xiaoyu will write a special article on the differences between collaboration process, thread and process to ensure that he can understand it properly after reading it.