brief introduction
- The basic notes introduce the basic problems such as data type and file operation. If you want to know more, you can take a look at the interview
- The advanced part mainly includes object-oriented idea, exception handling, iterator, generator and coroutine
object-oriented
- Python has been an object-oriented language since its design
- Class: used to describe a collection of objects with the same attributes and methods. It mainly includes the following concepts:
- Methods: functions defined in classes
- Class variable: class variable is common in the whole instantiated object and can be understood as static type
- Local variable: a variable defined in a method
- Instance variable: also known as class attribute, that is, variable decorated with self
- Class and derived methods inherit from a class
- Method override: if the method inherited from the parent class cannot meet the needs of the child class, it can be overridden, also known as method override
- Objects: instances of classes
- Construction method:__ init__, The method that will be called automatically when the class is instantiated
class MyClass: def __init__(self): self.i = 12345 def f(self): # Note that self should be added to member functions return self.i # Instantiation class x = MyClass() # Access the properties and methods of the class print("MyClass Properties of class i For:", x.i) print("MyClass Class method f Output is:", x.f()) - It still needs to be used. You can take a look at the basic small project and deeply understand the advantages of this idea
exception handling
- An exception will occur when Python cannot handle the program normally. We need to catch and handle it, otherwise the program will terminate execution
- Common exception handling methods:
- Use try/except: detect errors in the try statement block, so that the exception statement can catch exception information and handle it
- You can also use the raise statement to trigger exceptions yourself
- It can be a python standard exception, or it can be inherited and customized
- see course , just go through it
- In my Python interview (I) The inheritance of exceptions is also mentioned in
# It's usually written like this try: fh = open("testfile", "w") fh.write("This is a test file for testing exceptions!!") except IOError: # This is a standard exception print("Error: File not found or failed to read") else: print("Content written to file successfully") fh.close() # There is no message attribute in Python 3. You can directly str() or borrow exc of sys_ info try: a = 1/0 except Exception as e: # This e is the exception message exc_type, exc_value, exc_traceback = sys.exc_info() print(str(e)) # division by zero print(exc_value) # division by zero finally: # The last code will be executed whether or not an exception occurs print('over!') # Trigger exception def func(level): if level < 1: raise Exception("Invalid level!", level) # Can be output, you can write it # After the exception is triggered, the following code will not be executed func() # Exception: ('Invalid level!', 0) # Custom exception class Networkerror(RuntimeError): # Inherit RuntimeError def __init__(self, arg): self.args = arg # self.message = arg try: raise Networkerror("Bad hostname") except Networkerror as e: # This e is the exception message print(e.args) # You can also output format (E) str (E) - Python 3 will use Traceback to track exception information by default, from bottom to top!
Custom package / module
-
Large programs need to customize many packages (modules), which not only enhance the readability of the code, but also facilitate maintenance
-
Use import to import built-in or custom modules, which is equivalent to include
import my # Import my Py mode 1 from my import test # Import a function test() Mode 2
-
When importing, the system will search from the set path to view the paths included in the system:
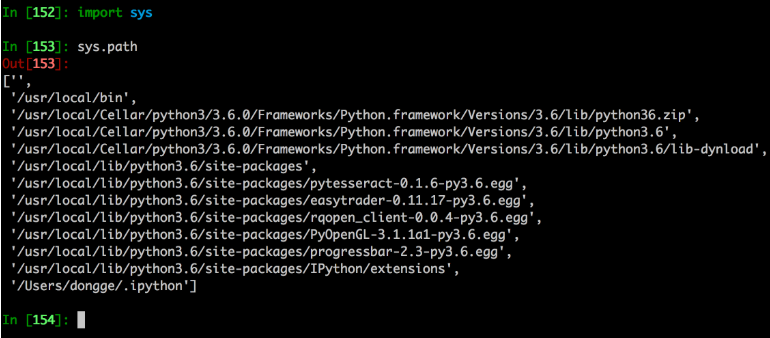
- '' indicates the current path
-
The current program will prevent repeated import of imported modules, that is, the modules are modified after import and cannot be re imported directly
# Need to use reload module to reboot from importlib import reload # imp deprecated reload(module_name) # view help help(reload) # The module must have been successfully imported before.
-
Points for attention in multi module development
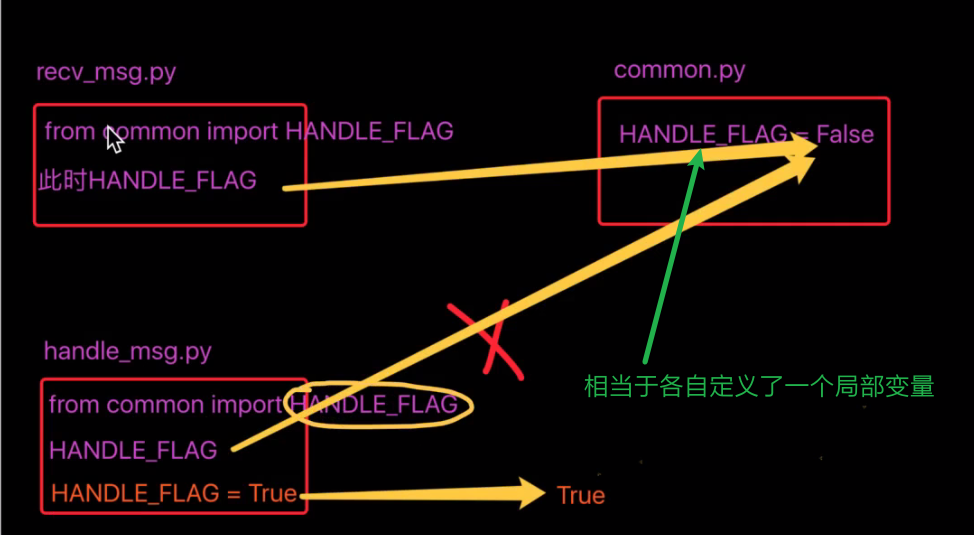
- Different import methods determine whether the variable is global or local
- As shown in the figure, the direction changes:
- If you import a list, append it with the append() method, and the variable will not be redefined
- If you directly let HADNLE_FLAG = xxx, which is equivalent to the newly defined variable and does not change the list value in common
- Therefore, it can only be imported and used in the first way:
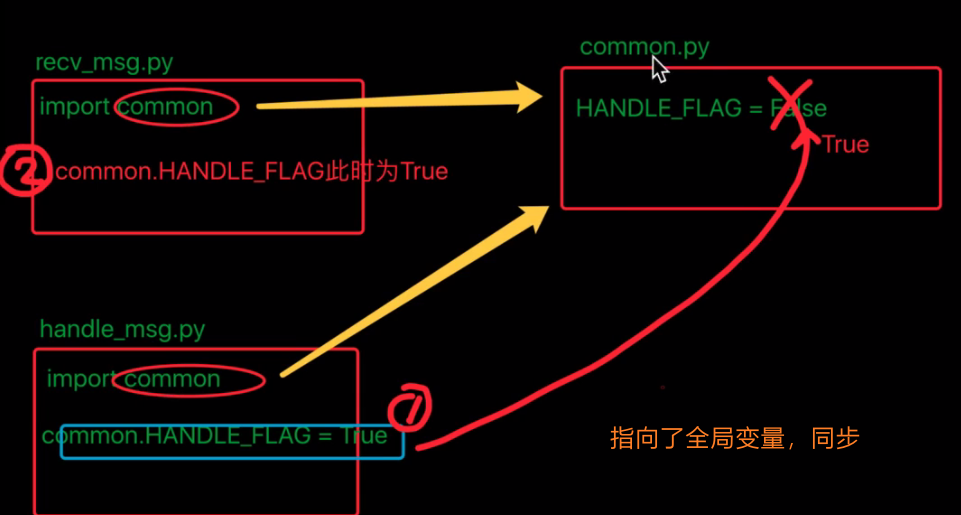
-
Note:
- __ name__ attribute
# If we want a program block in the module not to execute when the module is introduced, we can use__ name__ attribute # Make the program block execute only when the module itself is running # Filename: using_name.py if __name__ == '__main__': print('The program itself is running%s'%__name__) else: print('The first mock exam is from another module.%s'%__name__)$ python using_name.py The program itself is running__main__ # Display main module $ python >>> import using_name The first mock exam is from another module. using_name # Display file name
encapsulation
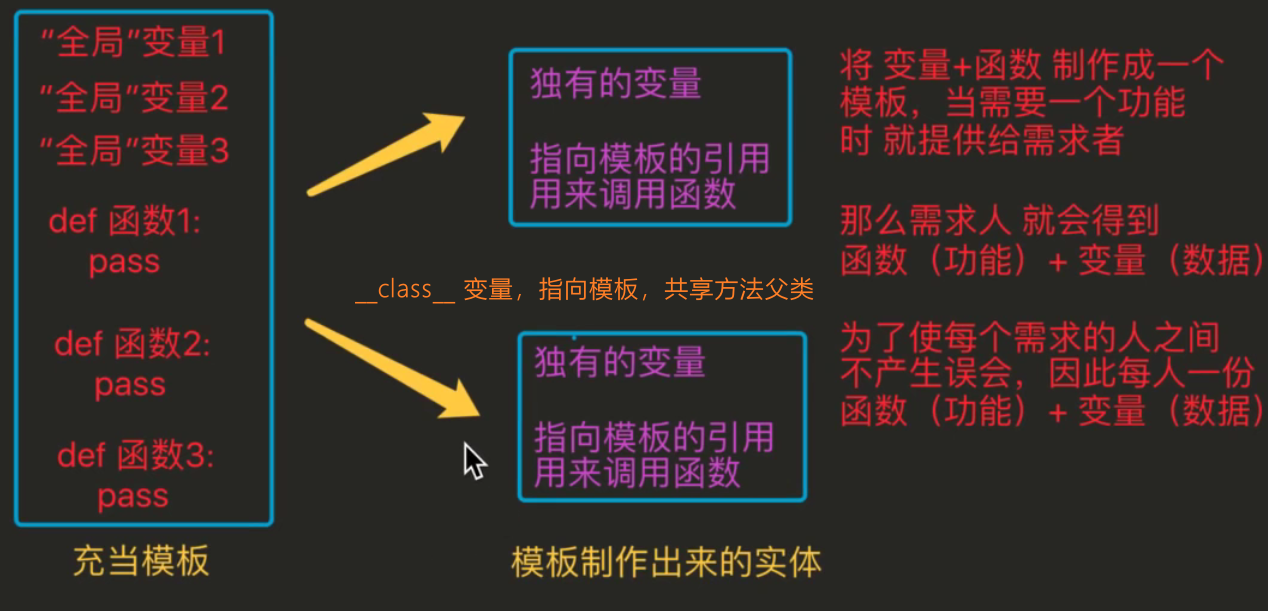
- Encapsulation, inheritance and polymorphism are the three characteristics of object-oriented (class)
- As shown in the figure__ class__ Attribute is equivalent to the function that the subclass can call the parent class (analogy C + +)
polymorphic
-
Analogy C++
- Virtual function Rewriting: virtual void func(int a) {}, which is characterized by not compiling first and not sure which class called it
- When the passed in function pointer refers to the subclass of the parent object (the subclass of the function that has been overridden), you can use the passed in function pointer (the subclass of the function that has been overridden) to determine the subclass of the function that has been overridden in the global function table
- See my C++ note
-
It's similar in Python. Let's see an example
# Inheritance in python is written in parentheses class MiniOS(object): # Base class for all classes """MiniOS Operating system class """ def __init__(self, name): # Constructor self.name = name self.apps = [] # List of installed application names list() def __str__(self): # __ xxx__ It's called magic method """Returns the description of an object, print Object""" return "%s The list of installed software is %s" % (self.name, str(self.apps)) def install_app(self, app): # Pass in parent class pointer # Determine whether the software has been installed if app.name in self.apps: print("Already installed %s,No need to install again" % app.name) else: app.install() self.apps.append(app.name) class App(object): def __init__(self, name, version, desc): self.name = name self.version = version self.desc = desc def __str__(self): return "%s The current version of is %s - %s" % (self.name, self.version, self.desc) def install(self): # Equivalent to virtual function print("take %s [%s] Copy the executed program to the program directory..." % (self.name, self.version)) class PyCharm(App): # Subclass inherits App pass # The same scope is called overloading class Chrome(App): def install(self): # Equivalent to virtual function rewriting; Ordinary functions in a class are called redefinition print("Extracting setup...") super().install() # You need to call it through super instead of using it directly linux = MiniOS("Linux") print(linux) pycharm = PyCharm("PyCharm", "1.0", "python Developed IDE environment") chrome = Chrome("Chrome", "2.0", "Google browser") # Incoming subclass object linux.install_app(pycharm) # Equivalent to a global function, which subclass is passed in to execute the virtual method of which subclass linux.install_app(chrome) linux.install_app(chrome) print(linux) # The list of software installed on Linux is ['pycharm ',' chrome '] -
Experience it carefully!
thread
- Using threading to create child threads
import threading import time def func1(num1): for i in range(18): print(num1) time.sleep(0.1) def func3(str): for i in range(18): print(str) time.sleep(0.1) def func2(): for i in range(20): print('Main thread',i) time.sleep(0.1) if __name__ == '__main__': thread = threading.Thread(target=func1, args=(555,)) # List parameters thread2 = threading.Thread(target=func3, kwargs={'str':'roy'}) # Keyword parameters thread.start() thread2.start() func2() # The main thread is usually placed later, otherwise the main process will be executed first - The main thread usually waits for the child thread to finish before exiting
- You can set the daemon thread to exit all the threads when the main thread ends
if __name__ == '__main__': thread = threading.Thread(target=func1, args=(555,)) # Yuanzu formal biography parameter thread2 = threading.Thread(target=func3, kwargs={'str':'roy'})# Dictionary form # Daemon thread.setDaemon(True) thread.start() # The daemon thread must be set to exit at the end of the main thread thread2.setDaemon(True) thread2.start() func2() - Mutex -- thread synchronization
# If multiple threads operate global variables at the same time, there will be problems and need to be locked lock = threading.Lock() # mutex arr = 0 def lockfunc1(): lock.acquire() # lock up global arr # You need to get the global variable arr for i in range(500): arr += 1 print('Process 1:',arr) lock.release() # Release lock def lockfunc2(): lock.acquire() global arr for i in range(400): arr += 1 print('Process 2:',arr) lock.release()
process
- Every time a process is created, the operating system will allocate running resources. What really works is threads. Each process will create a thread by default
- Multi process can be multiple CPU cores, but generally refers to single core CPU concurrency, while multithreading is resource scheduling in one core, which can be understood in combination with the concept of parallel concurrency
import multiprocessing def func1(num1): for i in range(18): print(num1) time.sleep(0.1) def func2(str): for i in range(18): print(str) time.sleep(0.1) if __name__ == '__main__': multi1 = multiprocessing.Process(target=func1) multi2 = multiprocessing.Process(target=func2)# Each process has its own thread multi1.start() multi2.start() - Similarly, you can use a daemon to exit a child process
- The daemon is a special background process. If the child process starts with the daemon, it will act according to the eyes of the main process. Do you understand!
- Generally, the daemon will be created when the system is turned on and will exit when it is turned off. It will monitor silently
- You can also use precess Terminate
- Processes are independent (the basic unit of resource allocation) and do not share global variables
- So how do processes communicate? Message queue
queue = multiprocessing.Queue(3) # Any number of data can be saved by default
Multitasking
- Understand the process and thread, but there is another feature in python: CO process
- The interview may ask three questions: what is an iterator? What is a generator? What is a collaborative process?
iterator
-
Python three gentlemen: iterator, generator, decorator
-
Iterators are generally used for iteratable objects, including lists, dictionaries, primitives and collections. They are generally used in for loops
# Determine whether it can be iterated from collections import Iterable # Use function: as long as you can iterate, you can trace the source to Iterable isinstance([], Iterable) # isinstance: is it an example, that is, the previous genus does not belong to the latter isinstance(a,A) # Is object a an instance of class a
- First, judge whether the object can be iterated: see if there is__ iter__ method
- Then call the iter() function: automatically invoke the above magic method and return the iterator (object).
- By calling the next() function, you can continuously call the of the iteratable object__ next__ Method to get the next iteration value of the object
-
Iterators are also used in classes. How to make a class an iteratable object?
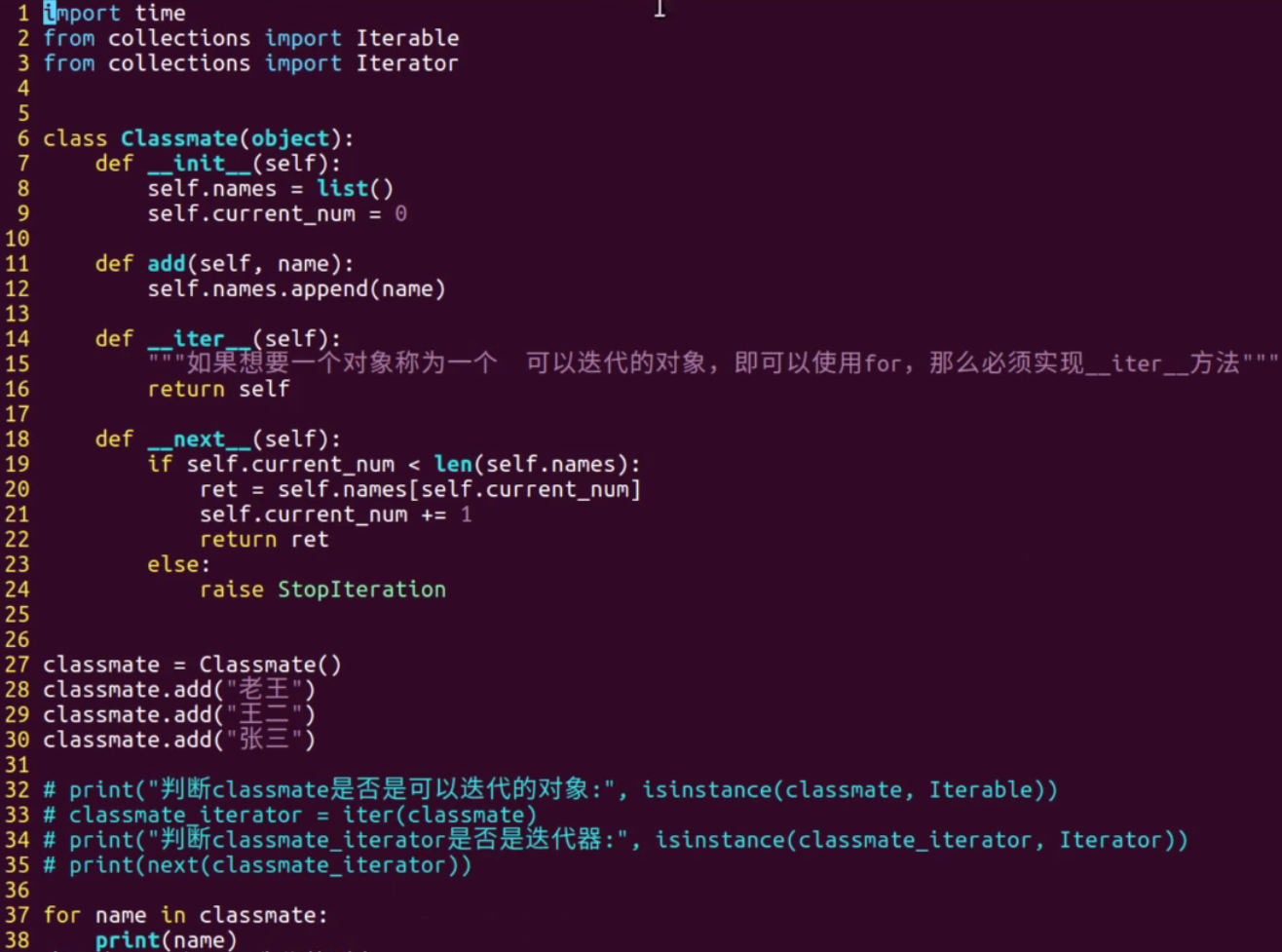
- Implement directly in class__ iter__ And__ next__ method
- Call the next method through the for loop
-
You can also return the class itself as an iterator
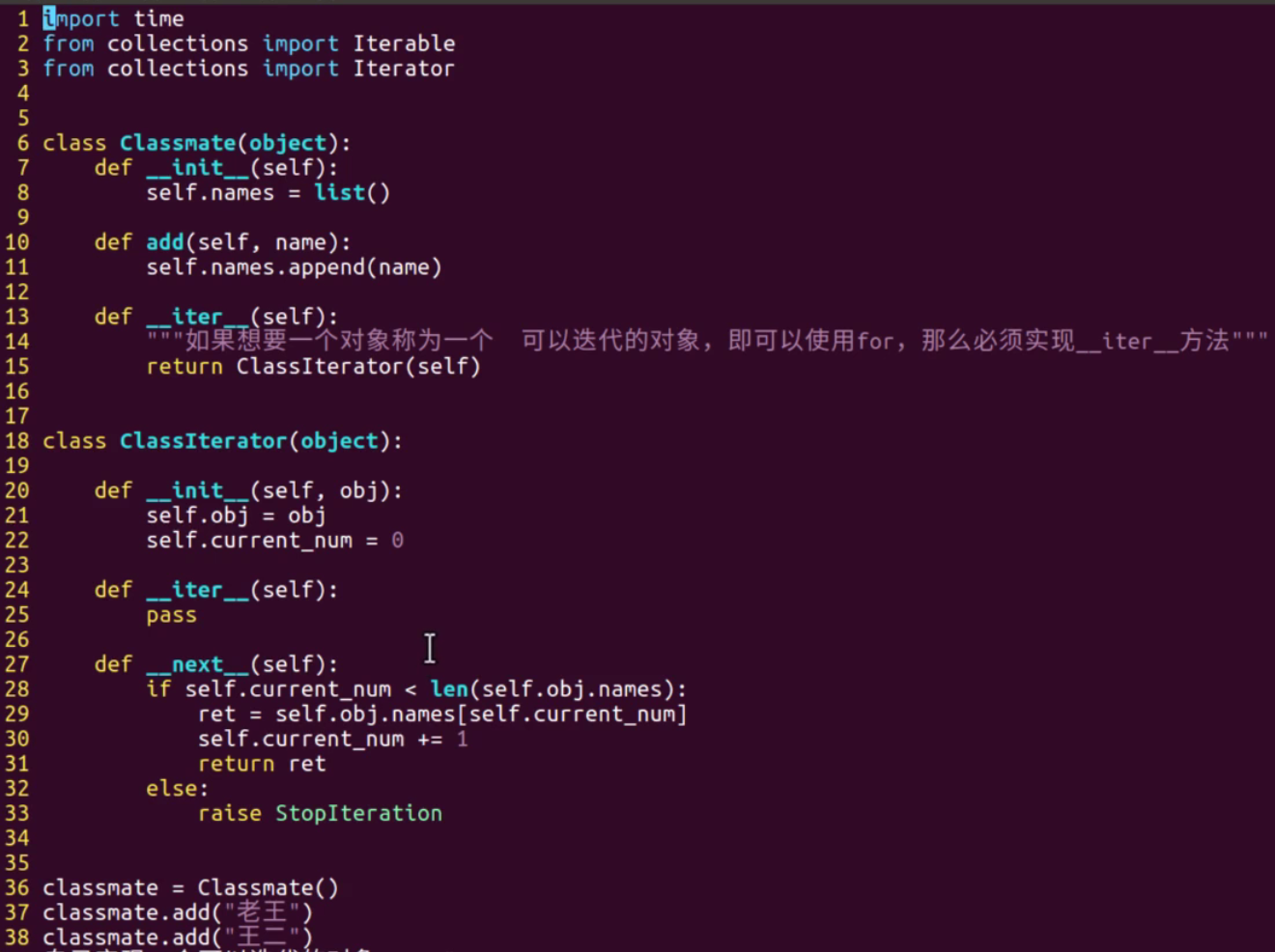
- The above custom class Classmate is implemented first__ iter__ Method to make it an iteratable object and return the ClassIterator iterator
- Iterators must also be iteratable objects, so they must also be implemented__ iter__ method
- Similarly, when the class is instantiated, the ret value can be obtained by calling the next method.
- It also shows that iterators must be iteratable, and iterators are not necessarily iteratable (depending on whether there is a _ next _)
-
The following example also illustrates the principle of iterators:
class MyIterator: def __iter__(self): # Return iterator object (initialization) self.a = 1 # Mark iteration position return self def __next__(self): # Return to next object x = self.a self.a += 1 # As you can see, here is the way to get the next value return x myclass = MyIterator() myiter = iter(myclass) # Get iterator print(next(myiter)) # 1 print(next(myiter)) # 2 print(next(myiter)) # 3 print(next(myiter)) # 4 print(next(myiter)) # 5- Here, the iter() method is also called, which is related to the definition, because it needs to initialize self a. So it's not necessary
- The point is: the iterator returns the way to get the data, which can save memory
-
For example: the difference between range() and = = xrange() = =
# In python2 range(100) # Return the list from 0 to 99, which takes up more memory xrange(100) # Returns how data is generated # In py3, range() is equivalent to xrange() range()
-
In practice, accept iterators thoroughly:
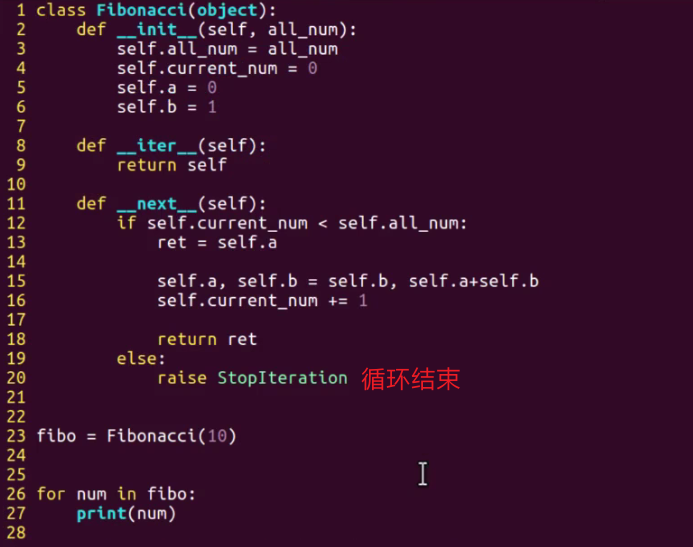
- The Fibonacci sequence is obtained in the form of iterators
- You don't know, do you? 0, 1, 1, 2, 3, 5, 8, 13, 21, 34... Fibonacci sequence
- The key points are: call the next method by default in the form of a for loop; This is also why it is used in the for loop
- There is also the writing method of swap in Python. It is very common. Remember!
- The Fibonacci sequence is obtained in the form of iterators
-
Of course, not only the for loop can receive iterative objects, but also the essence of type conversion is an iterator
li = list(FibIterator(15)) print(li) tp = tuple(FibIterator(6)) print(tp)
-
What is an iterator?
- The iterator supports the next() method to get the next value of the iteratable object
- Generally used in for loops and classes, the essence is to implement iter and next magic methods
- The iterator saves the memory space occupied by the data when the program is running by giving the way of data generation
generator
-
When implementing an iterator, we need to return manually and implement the next method to generate the next data
-
A simpler generator syntax can be adopted, that is, a generator is a special kind of iterator
-
Mode 1:
L = [ x*2 for x in range(5)] # [0, 2, 4, 6, 8] G = ( x*2 for x in range(5)) # <generator object <genexpr> at ... # The only difference is that the () of the outer layer can be used according to the use of iterators next(G) # 0 G is now an iterator next(G) # 1 next(G) # 2
- As long as it is an iterator, it can be started with next()
-
Mode 2:
- Use the yield keyword to create a generator, which is characterized by returning the following value when it is executed to yield
- The next iteration can then be executed, that is, special process control
- Let's take an example: we still get the Fibonacci sequence
def create_num(all_num): print('------1------') a, b = 0, 1 cur = 0 while(cur<all_num): print('------2------') yield a # Return to a print('Return and execute') a, b = b, a+b cur += 1 if __name__ == '__main__': obj = create_num(5) for num in obj: print(num)- It can be found that compared with the direct implementation with iterators, return and__ next__ method
- yield directly returns the following data, and can come back after this cycle, and then execute downward
-
Process control of data processing commonly used in crawlers:

- As shown in the figure, after using the css selector to obtain all web page links (urls), you need to initiate a request to crawl the source code for each link
- Use yield to return the execution of the Request to the object that calls the parse function at this point. This object loops (next), and yield returns to continue the loop
- Of course, the crawler framework can implement this behavior asynchronously without blocking and waiting (or it returns a function that you can handle there)
- In deep learning training, we need to feed data in batches, so we can use yield; Get a batch of data each time and return it to the model. The model calls the next() method / loop to get the next batch of data
-
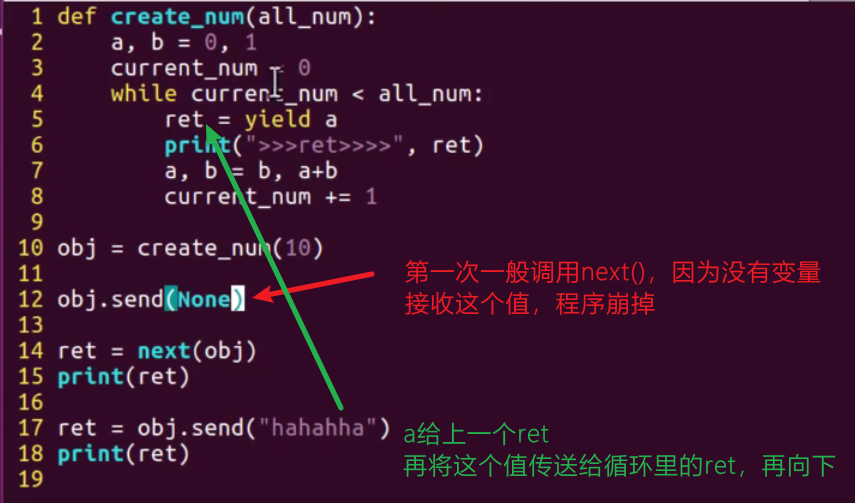
Use send() instead of next() to wake up. The difference is that parameters can be passed
-
Now, I can finally return to the headline: multitasking
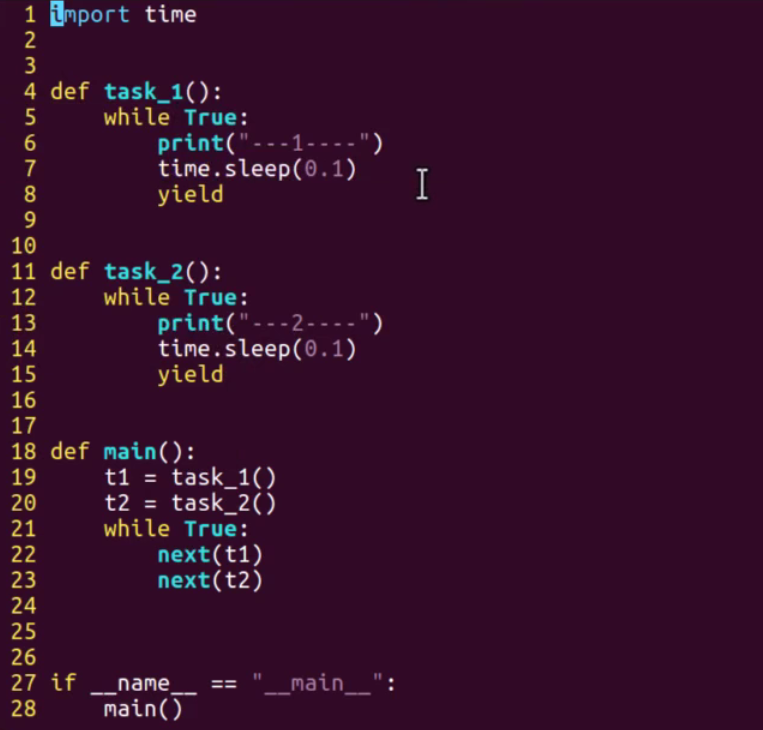
- The generator implements alternating tasks, that is, simple coprocesses
-
What is a generator?
- Generators are a special class of iterators
- Generally, yield is used to create a generator. The function containing yield keyword is called generator function
- The feature is that when it is executed to yield, it returns the following value, which can be followed by the function
- Because it can be executed after returning, it is a special process control, which is generally used in crawler and deep learning training
- Using yield between multiple functions is equivalent to switching between functions, which is also the basic principle of coprocessing
-
Note: iterations of iterators and generators can only go back, not forward
Synergetic process
-
Implement simple co process code
import time def work1(): while True: print("----work1---") yield time.sleep(0.5) def work2(): while True: print("----work2---") yield time.sleep(0.5) def main(): w1 = work1() w2 = work2() while True: next(w1) next(w2) if __name__ == "__main__": main() -
What is a coroutine: coroutine is another way to implement multitasking in python, but it takes up less execution units than threads
-
It has its own CPU context, so that we can switch one collaboration process to another at the right time;
-
Difference from thread:
- When implementing multitasking, the operating system has its own Cache and other data for the efficiency of program operation
- The operating system will also help you recover these data, so thread switching consumes more performance
- However, coprocess switching is only the context of operating the CPU, so it can switch systems millions of times a second
- CPU context is the CPU register and program counter PC, which is the necessary dependent environment before running any task
- That is: the cooperative process loads lightly and throws away the redundant state, which is equivalent to only switching between functions in the program, with its own logic, taking the data from elsewhere, returning the result after execution, and ending!
-
In order to better use the collaborative process to complete multitasking, the Green let module in python encapsulates it
# sudo pip3 install greenlet # Install Python 2 from greenlet import greenlet import time def test1(): while True: print "---A--" gr2.switch() time.sleep(0.5) def test2(): while True: print "---B--" gr1.switch() time.sleep(0.5) gr1 = greenlet(test1) gr2 = greenlet(test2) #Switch to run in gr1 gr1.switch() # This function encapsulates yield # In fact, this is a fake multitasking, completely alternating execution -
More commonly used is gevent
- Install PIP3 -- default timeout = 100 install gevent http://pypi.douban.com/simple/ --trusted-host pypi. douban. com
- Or use http://mirrors.aliyun.com/pypi/simple/
- However, if an error is reported, use sudo pip3 install gevent. Slow down
- You can use pip3 list to view installed libraries
# Take the greenlet and further encapsulate it import gevent def f(n): for i in range(n): print(gevent.getcurrent(), i) g1 = gevent.spawn(f, 5) g2 = gevent.spawn(f, 5) g3 = gevent.spawn(f, 5) g1.join() g2.join() g3.join() # Running discovery is running in sequence -
Multitasking: in a single core, tasks are executed concurrently and alternately
import gevent def f1(n): for i in range(n): print(gevent.getcurrent(), i) #It is used to simulate a time-consuming operation. Note that it is not sleep in the time module gevent.sleep(1) # All modules in gevent should be used def f2(n): for i in range(n): print(gevent.getcurrent(), i) gevent.sleep(1) # Switch in case of time-consuming operation def f3(n): for i in range(n): print(gevent.getcurrent(), i) gevent.sleep(1) g1 = gevent.spawn(f1, 5) # Create a collaboration g2 = gevent.spawn(f2, 5) # Objective function, parameter g3 = gevent.spawn(f3, 5) g1.join() # join blocks time-consuming g2.join() # Join and execute g3.join() # Will wait for all functions to execute # It is equivalent to switching between functions, that is, the so-called built-in CPU context, which saves resources -
Threads depend on processes, and coroutines depend on threads; Minimum synergy
from gevent import monkey # Patch, automatically convert time to gevent import gevent import random import time def coroutine_work(coroutine_name): for i in range(10): print(coroutine_name, i) time.sleep(random.random()) gevent.joinall([ gevent.spawn(coroutine_work, "work1"), gevent.spawn(coroutine_work, "work2") ]) -
What is a collaborative process?
- A coroutine is equivalent to a microthread
- GIL locks and inter thread switching consume more resources
- The coroutine has its own CPU context, which can rely on one thread to realize the switching between coroutines, which is faster and less expensive
- Equivalent to switching between program functions
Concurrent Downloader
- Using coprocess to realize a picture downloader
from gevent import monkey # That is, runtime replacement, the embodiment of python dynamics! import gevent import urllib.request import random # Required when there are time-consuming operations monkey.patch_all() def my_downLoad(url): print('GET: %s' % url) resp = urllib.request.urlopen(url) # file_name = random.randint(0,100) data = resp.read() with open(file_name, "wb") as f: f.write(data) def main(): gevent.joinall([ gevent.spawn(my_downLoad, "1.jpg", 'https://rpic.douyucdn.cn/live-cover/appCovers/2021/01/10/9315811_20210110043221_small.jpg'), gevent.spawn(my_downLoad, "2.jpg", 'https://rpic.douyucdn.cn/live-cover/appCovers/2021/01/04/9361042_20210104170409_small.jpg'), gevent.spawn(my_downLoad, "3.jpg", 'https://rpic.douyucdn.cn/live-cover/roomCover/2020/12/01/5437366001ecb82edfe1e098d28ebc36_big.png'), ]) if __name__ == "__main__": main()
summary
- Process is the unit of resource allocation. Processes are independent, so they are stable, but switching requires the most resources and is inefficient
- Thread is the basic unit of CPU scheduling. The amount of resources required for thread switching is general and the efficiency is general (without considering GIL)
- Coprocess switching consumes very little resources and is highly efficient. It is used when there are more network requests (more blocking). It can be understood as thread enhancement
- Multi process and multi thread may be parallel according to the different number of CPU cores, that is, each thread of a process can use multi-core parallelism; But the coroutine is in a thread, so it is concurrent
- The next article introduces the advanced operations of python
