This article is translated from Python & APIs: A Winning Combo for Reading Public Data
Article code address https://github.com/realpython/materials/tree/master/consuming-apis-python?__s=kea6w26ii09uqhijmy0b
Python+API: a perfect match for reading public data
go to top
Learning to use different APIs is a magical skill, and many applications and systems you use every day are connected to the API. From very simple and ordinary things, such as checking the weather in the morning, to more addictive and time-consuming operations, such as rolling microblog, Tiger flutter and b-site interface, API plays a core role.
Through this tutorial, you will learn the following:
- What is API
- How to use the API through Python code
- What is the most important concept about API
- How to read available data through public API
By the end of this tutorial, you will be able to use Python to use most of the APIs you encounter. If you are a developer, knowing how to use Python and APIs will make you more professional, especially when integrating your work with third-party applications.
Understanding API
go to top
The full name of API is "application programming interface". In essence, API acts as a communication layer, or as the name suggests, an interface, which allows different systems to communicate with each other without knowing exactly what they do.
APIs can take many forms. They can be operating system APIs used to turn on cameras and audio to join Zoom calls and other operations. Or they can be network APIs for network centric operations, such as like microblogging and forwarding circles of friends.
Regardless of the type, the functions of all APIs are roughly the same. You usually request information or data, and the API will return a response according to your request. For example, every time you open Weibo or scroll down the circle of friends, you basically send a request to the API behind the application and get a response in return. This is also known as calling the API.
In this tutorial, you will pay more attention to the advanced API for cross network communication, also known as Web API.
SOAP vs REST vs GraphQL
go to top
Some of the examples mentioned above are for newer platforms or applications, but Web API s have been around for a long time. In the late 1990s and early 2000s, two different design models became the norm for public data:
- SOAP (Simple Object Access Protocol) is usually associated with the enterprise world, has a more strict contract based usage, and is mainly designed around operations.
- Rest (representative state transfer) is usually used in public API s and is very suitable for obtaining data from the Web. It is looser than SOAP and closer to the HTTP specification.
Today, GraphQL is becoming more and more popular. Created by Facebook, GraphQL is a very flexible API query language. Clients can accurately determine what they want from the server, rather than what the server decides to send.
If you want to learn more about the differences between the three design models, here are some good resources:
- What is SOAP
- What is REST
- API 101: SOAP vs. REST
- Introduction to GraphQL
- Comparing API Architectural Styles: SOAP vs REST vs GraphQL vs RPC
Although GraphQL is emerging and being adopted by more and more companies, including GitHub and Shopify, the fact is that most public APIs are still rest APIs. Therefore, for the purposes of this tutorial, you will only learn about rest APIs and how to use them using Python.
requests and API s: a match made in heaven
go to top
When using the Python API, you only need one library: requests. With it, you should be able to perform most, if not all, of the operations required to use any public API.
python -m pip installrequests
To run the code examples in this tutorial, make sure you are using Python 3.8.1 and requests version 2.24.0 or later.
Call API via Python
go to top
Don't say much - it's time to make your first API call! For the first example, you will call a popular API to generate random user data.
Random User Generator API: This is a good tool for generating random user data.
You can use it to generate any number of random users and related data, and you can specify gender, nationality, and many other filters that are useful when testing applications or API s in this case.
When you start using the Random User Generator API, the only thing you need to know is which URL to call it with.
For this example, the URL to use is https://randomuser.me/api/ , this is the smallest API call you can make:
import requests
requests.get("https://randomuser.me/api/")
# <Response [200]>
In this small example, you import the request library and then get (or get) the data from the URL of the Random User Generator API. But you don't actually see any returned data. Instead, you get the response [200], which in API terminology means that everything is OK.
If you want to view the actual data, you can use the text attribute of the returned Response object:
improt requests
print(requests.get("https://randomuser.me/api/").text)
Endpoints and resources
go to top
As you can see above, the first thing you need to know about using an API is the API URL, commonly referred to as the basic URL. The basic URL structure is no different from the URL you use to browse Google, YouTube or Facebook, although it usually contains the word API. This is not mandatory, just more rules of thumb.
For example, the following are the basic URL s of some well-known API players:
- https://api.twitter.com
- https://api.github.com
- https://api.stripe.com
As you can see, all the above contents are in English https://api And include the remaining official domains, such as twitter.com or github.com. There is no specific standard for a basic URL, but it is common for it to mimic this structure.
If you try to open any of these links, you'll notice that most of them return errors or ask for credentials. This is because API s sometimes require authentication steps to use them. You will learn more later in this tutorial
The dog API: this API is very interesting, but it is also a good example. It is a good API with good documentation.
With it, you can get different dog breeds and some images, but if you register, you can also vote for your favorite dog.
Next, using The DogAPI just introduced, you will try to issue a basic request to see how it is different from the Random User Generator API you tried above:
import requests
response = requests.get("https://api.thedogapi.com/")
print(response.text)
#'{"message":"The Dog API"}'
In this case, when you call the basic URL, you will receive a general message The Dog API. This is because you are calling the base URL, which is usually used for very basic information about the API rather than real data.
It's not fun to call the base URL alone, but that's where the endpoint comes in handy. An endpoint is part of a URL that specifies the resources to get. Documented APIs often contain API references, which are useful for understanding the exact endpoints and resources of the API and how to use them.
You can view Official documents To learn more about how to use the dogapi and the available endpoints. There, you'll find a / feeds endpoint that you can use to get all the available variety resources or objects.
Now, try the code locally using the variety endpoint and some API knowledge you already have:
import requests
response = requests.get("https://api.thedogapi.com/v1/breeds/")
response.text
The above code requests through the basic URL+EndPoint, and you can get the information of hundreds of dogs.
If you are a cat lover, please don't worry. There are also API s for you that have the same endpoint but different base URL s:
import requests
response = requests.get("https://api.thecatapi.com/v1/breeds")
print(len(response.json())
I bet you're already thinking about different ways to use these APIs to make some lovely side projects, and that's the greatness of the API. Once you start using them, nothing can stop you from turning your hobby or passion into an interesting little project.
One thing you need to know about endpoints before continuing is the difference between http: / / and HTTPS: / /. In short, it makes the traffic between the HTTP client and the HTTPS server more secure. When using public APIs, you should absolutely avoid sending any private or sensitive information to http: / / endpoints and use only those APIs that provide secure HTTPS: / / basic URL s.
For more information on the importance of sticking to HTTPS when browsing online, please see Explore HTTPS using Python
In the next section, you will learn more about the main components of API calls.
Request and response
go to top
As you briefly read above, all interactions between the client (in this case, your Python console) and the API are divided into request and response:
- The request contains relevant data about your API request call, such as basic URL, endpoint, method used, request header, etc.
- The response contains the relevant data returned by the server, including data or content, status code and response header.
Using the dogapi again, you can learn more about the specific contents in the Request and Response objects:
>>> import requests
>>> response = requests.get("https://api.thedogapi.com/v1/breeds")
>>> response
<Response [200]>
>>> response.request
<PreparedRequest [GET]>
>>> request = response.request
>>> request.url
'https://api.thedogapi.com/v1/breeds'
>>> request.path_url
'/v1/breeds'
>>> request.method
'GET'
>>> request.headers
{'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*', 'Connection': 'keep-alive'}
>>> response
<Response [200]>
>>> response.text
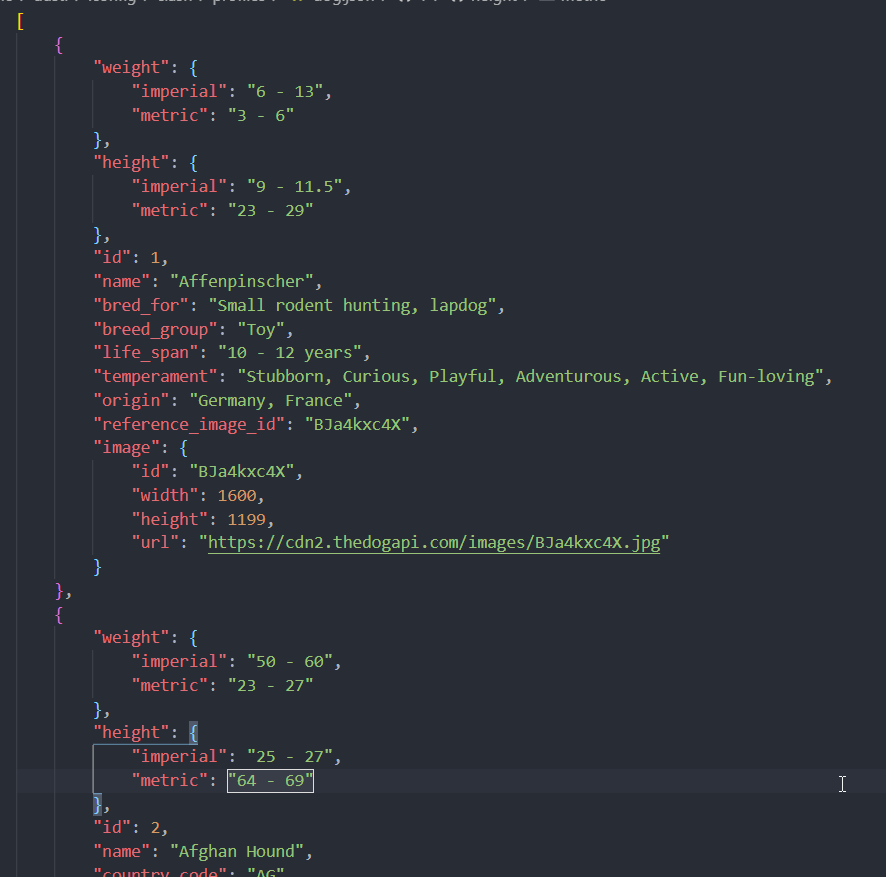
'[{"weight":{"imperial":"6 - 13","metric":"3 - 6"},
"height":{"imperial":"9 - 11.5","metric":"23 - 29"},"id":1,
"name":"Affenpinscher", ...}]'
>>> response.status_code
200
>>> response.headers
{'Cache-Control': 'post-check=0, pre-check=0', 'Content-Encoding': 'gzip',
'Content-Type': 'application/json; charset=utf-8',
'Date': 'Sat, 25 Jul 2020 17:23:53 GMT'...}
The above example shows you some of the most important properties available for request and response objects.
Status code
go to top
Status code is one of the most important information to look for in any API response. They tell you whether your request was successful, whether data is missing, whether credentials are missing, and so on.
Over time, you will recognize different status codes without help. But for now, here are some of the most common status codes:
| Status code | Description |
|---|---|
| 200 OK | Your request was successful! |
| 201 Created | Your request was accepted and the resource was created. |
| 400 Bad Request | Your request is either wrong or missing some information. |
| 401 Unauthorized | Your request requires some additional permissions. |
| 404 Not Found | The requested resource does not exist. |
| 405 Method Not Allowed | The endpoint does not allow for that specific HTTP method. |
| 500 Internal Server Error | Your request wasn't expected and probably broke something on the server side. |
You saw 200 OK in the previous example, and you may even recognize 404 Not Found when browsing the web page.
You can use status_code and reason checks the status of the Response. The requests library also prints the status code in the representation of the Response object:
>>> improt requests
>>> response = requests.get("https://api.thedogapi.com/v1/breeds")
>>> response
<Response [200]>
>>> response.status_code
200
>>> response.reason
'OK'
The above request returns 200, so you can consider it a successful request. But now look at the failed request that is triggered when you include a spelling error in the endpoint / breedz:
>>> import requests
>>> response = requests.get("https://api.thedogapi.com/v1/breedz")
>>> response
<Response [404]>
>>> response.status_code
404
>>> response.reason
'Not Found'
As you can see, / breedz endpoint does not exist, so the API returns 404 Not Found status code. You can use these status codes to quickly see if your request needs to be changed, or if you should check the document again for any misspellings or missing parts.
HTTP header
go to top
HTTP headers are used to define a few parameters governing requests and responses:
| HTTP Header | Description |
|---|---|
| Accept | What type of content the client can accept |
| Content-Type | What type of content the server will respond with |
| User-Agent | What software the client is using to communicate with the server |
| Server | What software the server is using to communicate with the client |
| Authentication | Who is calling the API and what credentials they have |
When examining a request or response, you can also find many other HTTP headers. To check the header of the response, you can use response headers:
>>> import requests
>>> response = requests.get("https://api.thedogapi.com/v1/breeds/1")
>>> response.headers
{'Content-Encoding': 'gzip',
'Content-Type': 'application/json; charset=utf-8',
'Date': 'Sat, 25 Jul 2020 19:52:07 GMT'...}
To do the same for the request header, you can use Response request. Headers, because request is an attribute of the Response object:
>>> import requests
>>> response = requests.get("https://api.thedogapi.com/v1/breeds/1")
>>> response.request.headers
{'User-Agent': 'python-requests/2.24.0',
'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*',
'Connection': 'keep-alive'}
In this case, you did not define any specific header when you made the request, so the default header is returned.
Construct request header
go to top
Another standard you may encounter when using the API is to use custom headers. These usually start with X - but are not required. API developers usually use custom headers to send or request other custom information to clients.
You can use a dictionary to define headers, and you can use The header parameter of get() sends them with your request. For example, suppose you want to send some request IDs to the API server, and you know that you can do this using X-Request-Id:
>>> headers = {"X-Request-Id": "<my-request-id>"}
>>> response = requests.get("https://example.org", headers=headers)
>>> response.request.headers
{'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*', 'Connection': 'keep-alive',
'X-Request-Id': '<my-request-id>'}
If you view request Headers dictionary, you will find X-Request-Id at the end, as well as some other headers attached by default to any API request.
The response may have many useful headers, but one of the most important headers is the content type, which defines the type of content returned in the response.
Content-Type
go to top
Now, most APIs use JSON as the default content type, but you may need to use an API that returns XML or other media types, such as images or videos. In this case, the content type will be different.
If you review one of the previous examples using the dogapi and try to check the content type header, you will notice how it is defined as application/json:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds/1")
>>> response.headers.get("Content-Type")
'application/json; charset=utf-8'
In addition to a specific type of content (in this case, application/json), the header may also return the specified encoding of the response content.
For example, if you try to get an image of a goat from the PlaceGOAT API, you will notice that the content type is no longer application/json, but is defined as image/jpeg
>>> response = requests.get("http://placegoat.com/200/200")
>>> response
<Response [200]>
>>> response.headers.get("Content-Type")
'image/jpeg'
In this case, the content type header declares that the returned content is a JPEG image. You will learn how to view this in the next section.
The content type header is important to understand how to handle the response and how to handle its content. There are hundreds of other acceptable content types, including audio, video, fonts, etc.
Response content
go to top
As you just learned, the content type you find in the API response will vary depending on the content type header. In order to correctly read the response content according to different content type headers, the request package comes with several different response attributes, which you can use to manipulate the response data:
- . text returns the response content in Unicode encoded format
- . content returns the response content in bytes
You have used the above Text attribute. However, for some specific types of data, such as images and other non text data, use content is usually a better method, even if it returns with Textvery similar results:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds/1")
>>> response.headers.get("Content-Type")
'application/json; charset=utf-8'
>>> response.content
b'{"weight":{"imperial":"6 - 13","metric":"3 - 6"}...'
As you can see Content and previously used There is not much difference between text. By looking at the content type header of the response, you can see that the content is application/json;, A JSON object.
For such content, the request library contains a specific json() method, which you can use to immediately convert the API byte response to a Python data structure:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds/1")
>>> response.headers.get("Content-Type")
'application/json; charset=utf-8'
>>> response.json()
{'weight': {'imperial': '6 - 13', 'metric': '3 - 6'},
'height': {'imperial': '9 - 11.5', 'metric': '23 - 29'}
...}
>>> response.json()["name"]
'Affenpinscher'
As you can see, execute response JSON (), you will get a dictionary that you can use like any other dictionary in Python.
Now, review the recent examples run using the PlaceGOAT API and try to get the same goat image and view its contents:
>>> response = requests.get("http://placegoat.com/200/200")
>>> response
<Response [200]>
>>> response.headers.get("Content-Type")
'image/jpeg'
>>> file = open("goat.jpeg", "wb")
>>> file.write(response.content)
>>> file.close()
Now, if you open the working folder, you will find a good JPEG file, which is the random image of the goat you just obtained using the API. Isn't it amazing?
HTTP method
go to top
When calling an API, there are several different methods, also known as verbs, that can be used to specify the action to be performed. For example, if you want to GET some data, you will use the method GET. If you want to create some data, you will use the method POST.
When querying data purely using API, you usually insist on using GET request, but here are the most common methods and their typical use cases:
| HTTP Method | Description | Requests method |
|---|---|---|
| POST | Create a new resource. | requests.post() |
| GET | Read an existing resource | requests.get() |
| PUT | Update an existing resource | requests.put() |
| DELETE | Delete an existing resource | requests.delete() |
These four methods are often referred to as CRUD operations because they allow you to create, read, update, and delete resources.
Note: there is an additional PATCH method also associated with CRUD operations, but it is slightly less than the four methods above.
It is used to make partial modifications instead of completely replacing resources with PUT.
So far, you have only used get() to get the data, but you can also use the requests package for all other HTTP methods:
>>> requests.post("https://api.thedogapi.com/v1/breeds/1")
>>> requests.get("https://api.thedogapi.com/v1/breeds/1")
>>> requests.put("https://api.thedogapi.com/v1/breeds/1")
>>> requests.delete("https://api.thedogapi.com/v1/breeds/1")
If you try these on the console, you will notice that most of them will return a 405 Method Not Allowed status code. This is because not all endpoints allow POST, PUT, or DELETE methods. Especially when you use public APIs to read data, you will find that most APIs only allow GET requests, because you are not allowed to create or change existing data.
Query parameters
go to top
When you simply use the basic URL+EndPoint to call the API, you will get a lot of unnecessary or unnecessary data. For example, when you call the / feeds endpoint of the dogapi, you get a lot of information about a given variety. However, in some cases, you may only want to extract some information about a given variety. This is where query parameters can be used!
When browsing online, you may have seen or used query parameters. For example, when watching a YouTube video, you have a similar https://www.youtube.com/watch?v=aL5GK2LVMWI The URL of the.
v = in the URL is what you call the query parameter. It usually follows the base URL and endpoint.
To add a query parameter to a given URL, you must add a question mark (?) before the first query parameter. If you want to include multiple query parameters in your request, you can separate them with an amp ersand (&). The same YouTube website with multiple query parameters above is as follows: https://www.youtube.com/watch?v=aL5GK2LVMWI&t=75 .
In the API world, query parameters are used as filters, and you can send them with API requests to further narrow the response range. For example, back to the Random User Generator API, you know how to generate random users:
>>> requests.get("https://randomuser.me/api/").json()
{'results': [{'gender': 'male', 'name':
{'title': 'Mr', 'first': 'Silvijn', 'last': 'Van Bekkum'},
'location': {'street': {'number': 2480, 'name': 'Hooijengastrjitte'},
'city': 'Terherne', 'state': 'Drenthe',
'country': 'Netherlands', 'postcode': 59904...}
However, suppose you specifically want to generate only random female users.
According to the document, you can use the query parameter gender =:
>>> requests.get("https://randomuser.me/api/?gender=female").json()
{'results': [{'gender': 'female', 'name':
{'title': 'Mrs', 'first': 'Marjoleine', 'last': 'Van Huffelen'},
'location': {'street': {'number': 8993, 'name': 'De Teebus'},
'city': 'West-Terschelling', 'state': 'Limburg',
'country': 'Netherlands', 'postcode': 24241...}
That's great! Now suppose you only want to generate female users from Germany. Check the document again and you will find the part about nationality. You can use the query parameter nat =:
>>> requests.get("https://randomuser.me/api/?gender=female&nat=de").json()
{'results': [{'gender': 'female', 'name':
{'title': 'Ms', 'first': 'Marita', 'last': 'Hertwig'},
'location': {'street': {'number': 1430, 'name': 'Waldstraße'},
'city': 'Velden', 'state': 'Rheinland-Pfalz',
'country': 'Germany', 'postcode': 30737...}
Using query parameters, you can start to get more specific data from the API, so that the whole experience can better meet your needs. To avoid rebuilding the URL over and over again, you can use the params property to send a dictionary of all query parameters to attach to the URL:
>>> query_params = {"gender": "female", "nat": "de"}
>>> requests.get("https://randomuser.me/api/", params=query_params).json()
{'results': [{'gender': 'female', 'name':
{'title': 'Ms', 'first': 'Janet', 'last': 'Weyer'},
'location': {'street': {'number': 2582, 'name': 'Meisenweg'},
'city': 'Garding', 'state': 'Mecklenburg-Vorpommern',
'country': 'Germany', 'postcode': 56953...}
You can apply the above to any other API you like. If you return to the dog API, there is a method in the document that allows you to filter the variety endpoint to return only varieties that match a specific name. For example, if you want to find a Labrador breed, you can use the query parameter q:
>>> query_params = {"q": "labradoodle"}
>>> endpoint = "https://api.thedogapi.com/v1/breeds/search"
>>> requests.get(endpoint, params=query_params).json()
[{'weight': {'imperial': '45 - 100', 'metric': '20 - 45'},
'height': {'imperial': '14 - 24', 'metric': '36 - 61'},
'id': 148, 'name': 'Labradoodle', 'breed_group': 'Mixed'...}]
You did it! By sending the query parameter q with the value labradoodle, you can filter all varieties that match that particular value.
With the help of query parameters, you can further narrow the scope of the request and specify exactly what you want to find. Most of the APIs you can find online have some kind of query parameters that you can use to filter data. Remember to check the documentation and API references to find them.
Advanced concepts of API
go to top
Now that you have a good understanding of the basics of using the API with Python, there are some more advanced topics worth discussing, even briefly, such as authentication, paging, and rate limiting.
authentication
go to top
API authentication is probably the most complex topic covered in this tutorial. Although many public APIs are free and fully public, there are more APIs available behind some form of authentication. There are many APIs that require authentication, but here are some good examples:
Authentication methods range from simple and straightforward methods (such as using API keys or basic authentication) to more complex and secure technologies (such as OAuth).
Typically, calling the API without credentials or errors will return a 401 Unauthorized or 403 Forbidden status code.
API Keys
go to top
The most common authentication level is the API key. These keys are used to identify you as an API user or customer and track your use of the API. API keys are usually sent as request headers or query parameters.
NASA API: the API provided by NASA is one of the coolest public API collections. You can find the API to get astronomical pictures of the day or pictures taken by the earth multicolor imaging camera (EPIC).
This article will use NASA's Mars Rover Photo API And get the photos taken on July 1, 2020. For testing purposes, you can use the demo provided by NASA by default_ Key API key. Otherwise, you can quickly generate your own API by going to NASA's main API page and clicking start.
You can use additional APIs_ Key = add API key to your request by querying parameters:
>>> endpoint = "https://api.nasa.gov/mars-photos/api/v1/rovers/curiosity/photos"
>>> # Replace DEMO_KEY below with your own key if you generated one.
>>> api_key = "DEMO_KEY"
>>> query_params = {"api_key": api_key, "earth_date": "2020-07-01"}
>>> response = requests.get(endpoint, params=query_params)
>>> response
<Response [200]>
So far, it's good. You try to send an authenticated request to NASA's API and get a 200 OK Response. Now look at the Response object and try to extract some pictures from it:
>>> response.json()
{'photos': [{'id': 754118,
'sol': 2809,
'camera': {'id': 20,
'name': 'FHAZ',
'rover_id': 5,
'full_name': 'Front Hazard Avoidance Camera'},
'img_src': 'https://mars.nasa.gov/msl-raw-images/...JPG',
'earth_date': '2020-07-01',
'rover': {'id': 5,
'name': 'Curiosity',
'landing_date': '2012-08-06',
'launch_date': '2011-11-26',
'status': 'active'}},
...
}
>>> photos = response.json()["photos"]
>>> print(f"Found {len(photos)} photos")
Found 12 photos
>>> photos[4]["img_src"]
'https://mars.nasa.gov/msl-raw-images/proj/msl/redops/ods/surface/sol/02809/opgs/edr/rcam/RRB_646869036EDR_F0810628RHAZ00337M_.JPG'
use. json() converts the response into a Python dictionary, and then gets the photos field from the response. You can traverse all Photo objects and even get the image URL of a specific Photo. If you open the URL in your browser, you will see the following photos of Mars taken by the Mars probe:

Of course, you can also use python to save and read pictures:
with open("./mar.jpg", "wb") as img:
img.write(requests.get(photos[4]["img_src"])
from PIL import Image
with Image.open("./mar.jpg") as img:
img.show()
In this example, you selected a specific Earth_date (2020-07-01), and then select a specific photo from the response Dictionary (4). Before continuing, try changing the date or taking photos from different cameras to see how it changes the final result.
OAuth: preliminary understanding
go to top
Another very common standard in API authentication is OAuth. In this tutorial, you will only learn the basics of OAuth, because it is a very broad topic.
Even if you don't know it's part of OAuth, you may have seen and used OAuth processes many times. This is the starting point of OAuth process whenever the application or platform has the option of login mode or continue mode:
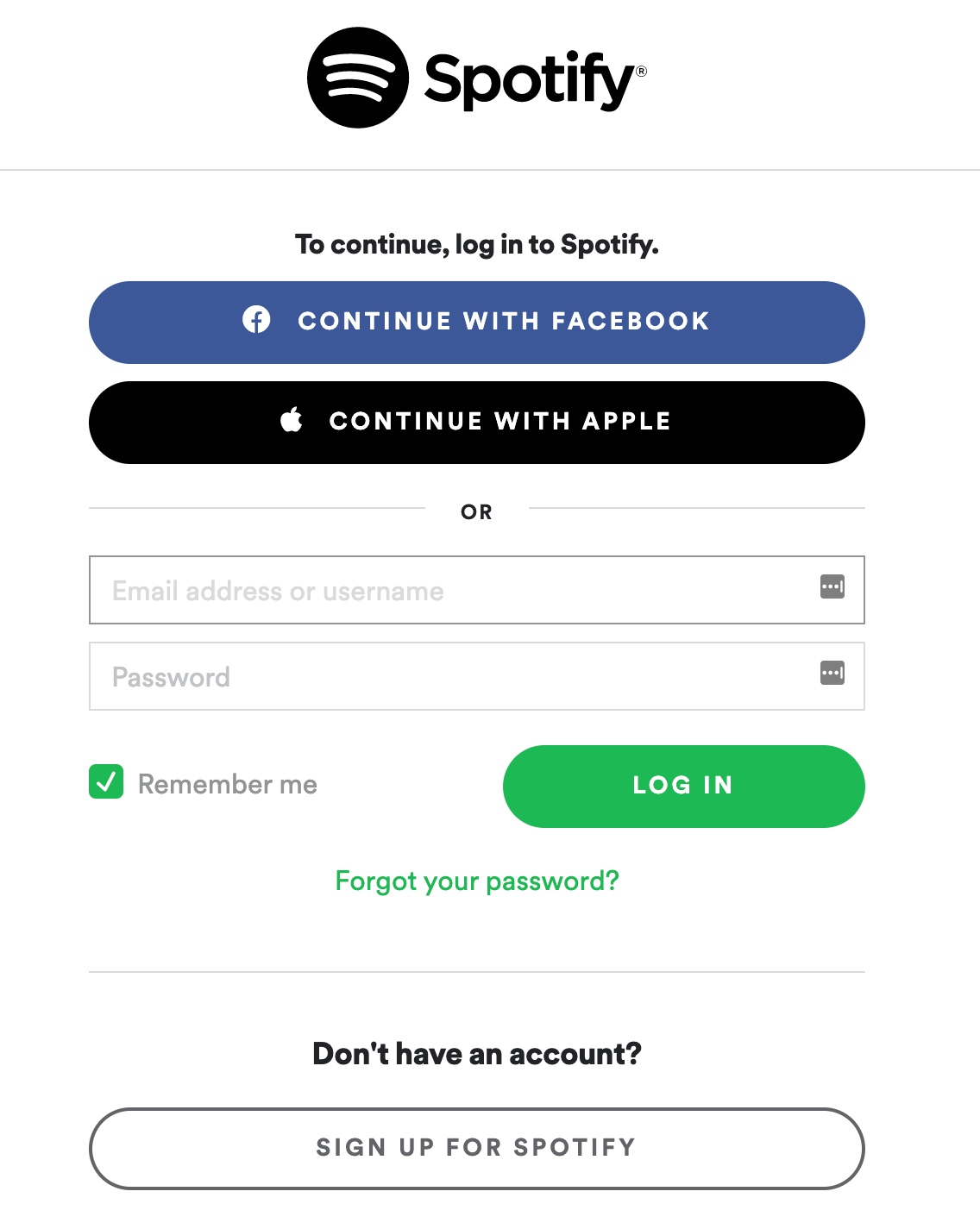
Here's what happens after you click continue using Facebook:
- The Spotify application will ask the Facebook API to start the authentication process. To do this, the Spotify application sends its application ID (client_id) and URL (redirect_uri) to redirect the user after success or error.
- You will be redirected to the Facebook site and asked to sign in with your credentials. The Spotify application will not see or cannot access these credentials. This is the most important benefit of OAuth.
- Facebook will show you all the data requested by the Spotify app from your profile and ask you to accept or refuse to share the data.
- If you accept letting Spotify access your data, you will be redirected back to the Spotify application you have logged in to.
When you complete step 4, Facebook will provide Spotify with a special access_token that can be reused to get your information. This particular Facebook login token is valid for 60 days, but other applications may have different validity periods. If you're curious, Facebook has a settings page where you can see which apps have received your Facebook access token.
Now, from a more technical point of view, here are the things you need to know when using OAuth API:
- You need to create an application with ID (app_id or client_id) and secret (app_secret or client_secret).
- You need a redirect_uri that the API will use to send you information.
- As a result of authentication, you get a code that you need to exchange for an access token.
There are some variations above, but generally speaking, most OAuth processes have steps similar to these.
Tip: when you are just testing and need some kind of redirect URL to get the code, you can use a service called httpbin.
More specifically, you can use https://httpbin.org/anything As a redirect URL, because it only outputs anything it gets as input.
You can come from the line test by navigating to the URL.
Next, you'll delve into examples of using the GitHub API!
OAuth: an example of practical application
go to top
As you can see above, the first thing you need to do is create an application. You can refer to GitHub document Detailed step-by-step instructions on how to do this in. The only thing to remember is to use the above mentioned https://httpbin.org/anything The URL is used as the Authorization callback URL field.
GitHub API: you can use the GitHub API in many different situations, such as getting the list of repositories you belong to, getting the list of followers you own, and so on.
After the application is created, the Client_ID and client_ Copy and paste the secret and the redirect URL you selected into GitHub In Python file of Py:
import requests # REPLACE the following variables with your Client ID and Client Secret CLIENT_ID = "<REPLACE_WITH_CLIENT_ID>" CLIENT_SECRET = "<REPLACE_WITH_CLIENT_SECRET>" # REPLACE the following variable with what you added in the # "Authorization callback URL" field REDIRECT_URI = "<REPLACE_WITH_REDIRECT_URI>"
Now that you have all the important variables ready, you need to be able to create a link to redirect users to their GitHub account, as described in the GitHub document:
def create_oauth_link():
params = {
"client_id": CLIENT_ID,
"redirect_uri": REDIRECT_URI,
"scope": "user",
"response_type": "code",
}
endpoint = "https://github.com/login/oauth/authorize"
response = requests.get(endpoint, params=params)
url = response.url
return url
In this code, you first define the required parameters expected by the API, and then use the requests package and get() calls the API.
When you make a request to the / login/oauth/authorize endpoint, the API will automatically redirect you to the GitHub website. In this case, you want to get the URL parameter from the response. This parameter contains the exact URL that GitHub redirects you to.
The next step in the authorization process is to exchange the code you get for an access token. Similarly, follow the steps in the GitHub document to create a method for it:
def exchange_code_for_access_token(code=None):
params = {
"client_id": CLIENT_ID,
"client_secret": CLIENT_SECRET,
"redirect_uri": REDIRECT_URI,
"code": code,
}
headers = {"Accept": "application/json"}
endpoint = "https://github.com/login/oauth/access_token"
response = requests.post(endpoint, params=params, headers=headers).json()
return response["access_token"]
Here, you issue a POST request to exchange the code of the access token. In this request, you must send your CLIENT_SECRET and code so that GitHub can verify that this particular code was originally generated by your application. Only in this way will the GitHub API generate a valid access token and return it to you.
Now you can add the following to your file and try to run it:
link = create_oauth_link()
print(f"Follow the link to start the authentication with GitHub: {link}")
code = input("GitHub code: ")
access_token = exchange_code_for_access_token(code)
print(f"Exchanged code {code} with access token: {access_token}")
If everything goes according to plan, you should be rewarded with a valid access token, which you can use to call the GitHub API to simulate an authenticated user.
Now try adding the following code to get your user profile using the User API and print your name, user name, and number of private repositories:
def print_user_info(access_token=None):
headers = {"Authorization": f"token {access_token}"}
endpoint = "https://api.github.com/user"
response = requests.get(endpoint, headers=headers).json()
name = response["name"]
username = response["login"]
private_repos_count = response["total_private_repos"]
print(
f"{name} ({username}) | private repositories: {private_repos_count}"
)
Now that you have a valid access token, you need to send it in all API requests using the Authorization header. The response to your request will be a Python dictionary containing all user information. From this dictionary, you want to get the field name, login name, and total_private_repos. You can also print response variables to see what other fields are available.
The only thing left is to put them together and try:
import requests
# REPLACE the following variables with your Client ID and Client Secret
CLIENT_ID = "<REPLACE_WITH_CLIENT_ID>"
CLIENT_SECRET = "<REPLACE_WITH_CLIENT_SECRET>"
# REPLACE the following variable with what you added in
# the "Authorization callback URL" field
REDIRECT_URI = "<REPLACE_WITH_REDIRECT_URI>"
def create_oauth_link():
params = {
"client_id": CLIENT_ID,
"redirect_uri": REDIRECT_URI,
"scope": "user",
"response_type": "code",
}
endpoint = "https://github.com/login/oauth/authorize"
response = requests.get(endpoint, params=params)
url = response.url
return url
def exchange_code_for_access_token(code=None):
params = {
"client_id": CLIENT_ID,
"client_secret": CLIENT_SECRET,
"redirect_uri": REDIRECT_URI,
"code": code,
}
headers = {"Accept": "application/json"}
endpoint = "https://github.com/login/oauth/access_token"
response = requests.post(endpoint, params=params, headers=headers).json()
return response["access_token"]
def print_user_info(access_token=None):
headers = {"Authorization": f"token {access_token}"}
endpoint = "https://api.github.com/user"
response = requests.get(endpoint, headers=headers).json()
name = response["name"]
username = response["login"]
private_repos_count = response["total_private_repos"]
print(
f"{name} ({username}) | private repositories: {private_repos_count}"
)
link = create_oauth_link()
print(f"Follow the link to start the authentication with GitHub: {link}")
code = input("GitHub code: ")
access_token = exchange_code_for_access_token(code)
print(f"Exchanged code {code} with access token: {access_token}")
print_user_info(access_token=access_token)
When you run the above code, the following happens:
- A link is generated asking you to go to the GitHub page for authentication.
- After clicking the link and logging in with your GitHub credentials, you will be redirected to the callback URL you defined, and the query parameters include a code field:
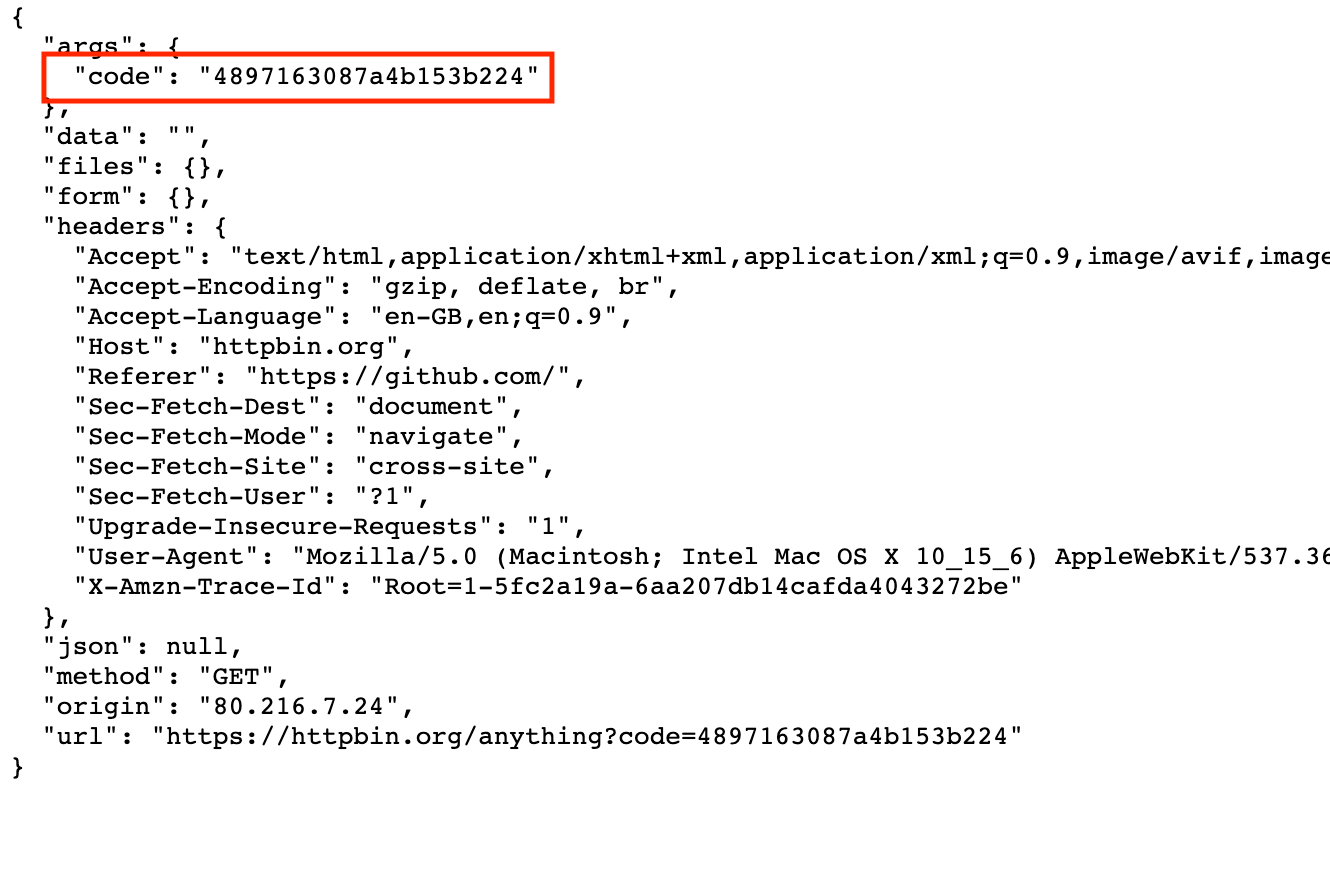
- After pasting the code in your console, you can exchange it for a reusable access token.
- Your user information was obtained using this access token. Print your name, user name, and private repository count.
If you follow the above steps, you should get a similar final result:
$ John Doe (johndoe) | number of private repositories: 42
There are many steps to take, but it's important that you take the time to really understand each step. Most APIs that use OAuth will share many of the same behaviors, so when you read data from the API, fully understanding this process will release a lot of potential.
Feel free to improve this example and add more features, such as getting your public and asterisk repositories or traversing your followers to identify the most popular repositories.
There are many excellent resources about OAuth on the Internet. If you really need to use the API behind OAuth, I suggest you conduct more research on this topic.
Here are some good starting points:
From an API perspective, understanding OAuth will definitely come in handy when you interact with public APIs. Most APIs use OAuth as their authentication standard for good reason.
Pagination
go to top
Sending large amounts of data back and forth between the client and the server comes at a cost: bandwidth. To ensure that the server can handle a large number of requests, Apis usually use paging.
In very simple terms, paging is the act of dividing a large amount of data into smaller parts. For example, whenever you go to the question page in Stack Overflow, you will see the following at the bottom:

You may recognize this from many other websites, and the concepts of different sites are roughly the same. Specifically, for API s, this is usually handled with the help of query parameters, mainly including the following two:
- A page attribute - defines the page you are currently requesting
- A size attribute -- defines the size of each page
The specific query parameter names may vary greatly depending on API developers, but the concepts are the same. Some API players may also use HTTP headers or JSON responses to return the current paging filter.
Using the GitHub API again, you can find the event endpoint in the document containing the paging query parameters. Parameter per_page = defines the number of items to return, while page = allows you to page multiple results. Here's how to use these parameters:
>>> response = requests.get("https://api.github.com/events?per_page=1&page=0")
>>> response.json()[0]["id"]
'14345572615'
>>> response = requests.get("https://api.github.com/events?per_page=1&page=1")
>>> response.json()[0]["id"]
'14345572808'
>>> response = requests.get("https://api.github.com/events?per_page=1&page=2")
>>> response.json()[0]["id"]
'14345572100'
Using the first API, you can only get one event, but by specifying different page s as query parameters, you will be able to get other event contents to ensure that all events are obtained without overloading.
Rate Limiting
go to top
Since API s are open to the public and can be used by anyone, malicious people often try to abuse them. To prevent such attacks, you can use a technique called rate limiting, which limits the number of requests a user can make within a given time frame.
If you often exceed the defined rate limit, some APIs may actually block your IP or API key. Be careful not to exceed the limits set by API developers. Otherwise, you may have to wait a while before calling the API again.
For the following example, you will use the GitHub API and / events endpoint again. According to its documentation, GitHub allows about 60 unauthenticated requests per hour. If you exceed this value, you will get a 403 status code and will not be able to make any API calls for a long time.
For demonstration purposes, you'll purposefully try to exceed GitHub's rate limit to see what happens. In the following code, you will request data until you get a status code other than 200 OK:
>>> endpoint = "https://api.github.com/events"
>>> for i in range(100):
>>> response = requests.get(endpoint)
>>> print(f"{i} - {response.status_code}")
>>> if response.status_code != 200:
>>> break
0 - 200
1 - 200
2 - 200
3 - 200
4 - 200
5 - 200
...
58 - 200
59 - 200
60 - 403
>>> response
<Response [403]>
>>> response.json()
{'message': "API rate limit exceeded for <ip-address>.",
'documentation_url': 'https://developer.github.com/v3/#rate-limiting'}
You have noticed that after about 60 accesses, the API does not return 200 status codes, but returns 403 status codes, indicating Forbidden, which means you have exceeded the API's rate limit.
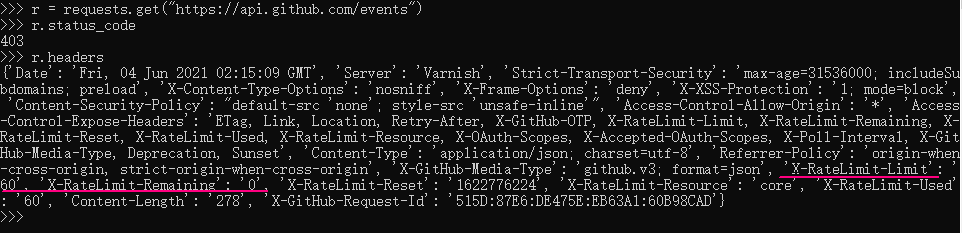
Some API s, such as GitHub's, may even contain additional information about the current rate limit and the number of requests remaining in the header. These are very helpful for you to avoid exceeding the defined limits. View the latest response Headers to see if you can find those specific rate limit headers.
Using API s through python: a practical example
go to top
Now that you know the relevant concepts and have personally experienced the use of several API s, you can reinforce this knowledge by learning some more practical application examples. You can modify the following example to achieve your goal.
Search and get popular gifs
go to top
How to make a small script from GIPHY website Get the top three popular GIF animation? To do this, you need to create an application and get the API key from GIPHY. You can find the description by expanding the box below, or you can view it Quick start documentation for GIPHY.
- To create a GIPHY account, you only need email and password (user name is optional)
- Create an Application: after creating an account, you can jump to Developer Dashboard To view your previously created Application or create a new Application
If it is a newly registered user, the DashBoard is empty. You can create a new app by clicking Create an APP
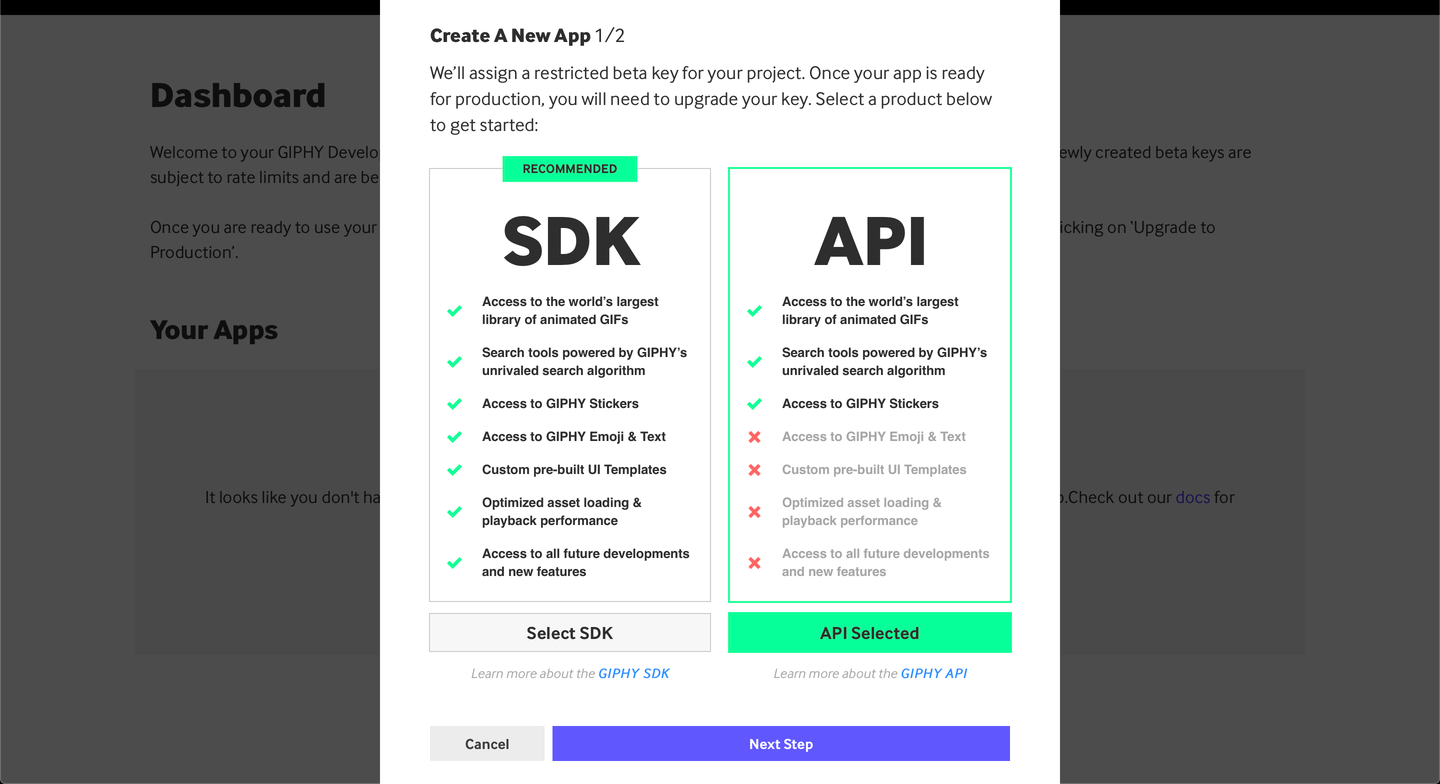
Make sure to select the API version instead of the SDK version. After that, you will be asked to fill in more details about your application:
You can see the name and description of the sample application above, but you can fill them in at will. - Get API Key
After completing the above steps, you will be able to see a new app in your DashBoard and the key of the app:
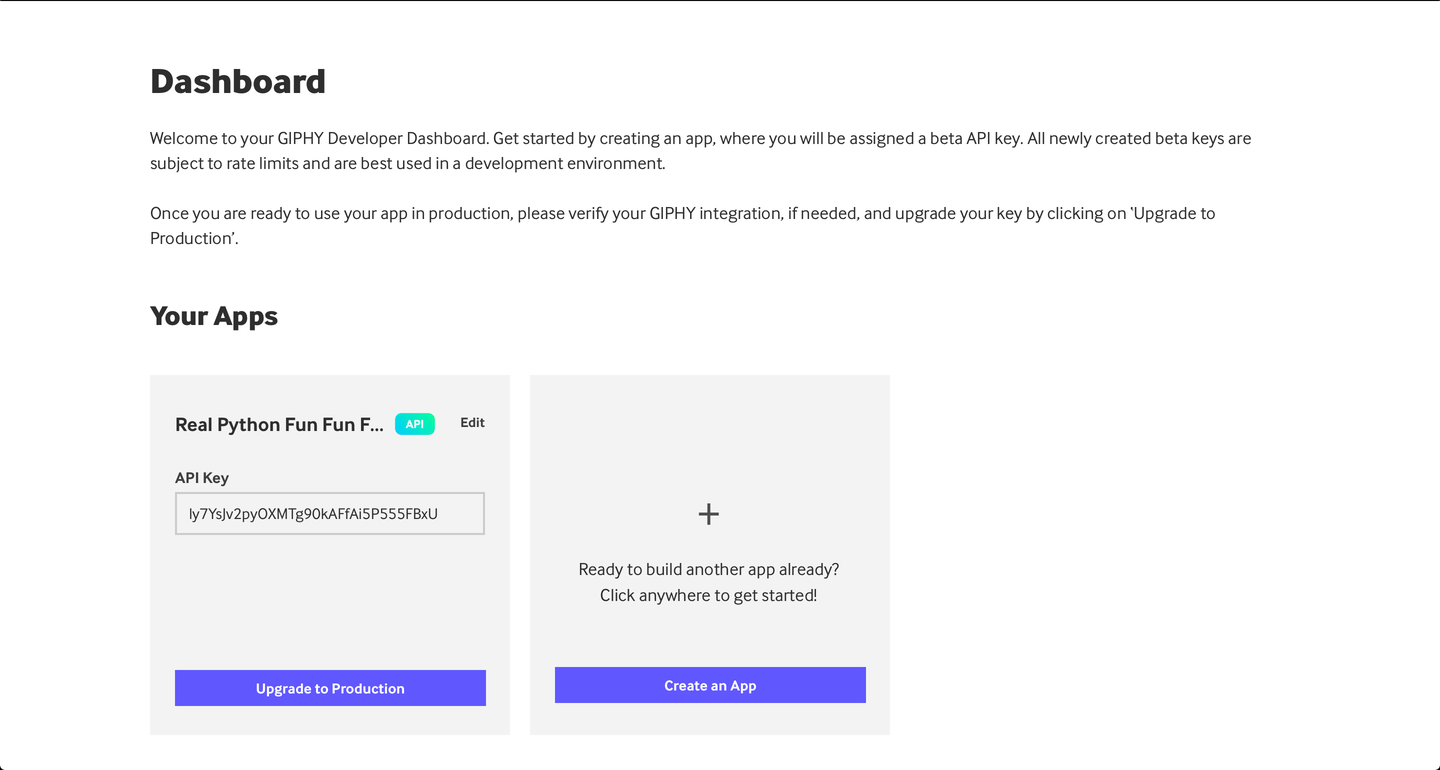
Now you can use this Key in requests.
Once you have the API key, you can start writing some code to use the API. However, sometimes you want to run some tests before implementing a lot of code. I know, I know. The problem is that some APIs actually provide you with tools to get API data directly from documents or their dashboards. In this special case, GIPHY provides you with an API Explorer, which allows you to start using the API without writing code after you create the application. Other APIs will provide you with a resource manager in the document itself, which is what the dog API does at the bottom of each API reference page.
In any case, you can always use code to use the API, which is what you want to do here. Obtain the API key from the Dashboard by replacing the following API_ The value of the key variable, you can start using the GIPHY API:
import requests
# Replace the following with the API key generated.
<a href="#">go to top</a>
API_KEY = "API_KEY"
endpoint = "https://api.giphy.com/v1/gifs/trending"
params = {"api_key": API_KEY, "limit": 3, "rating": "g"}
response = requests.get(ENDPOINT, params=params).json()
for gif in response["data"]:
title = gif["title"]
trending_date = gif["trending_datetime"]
url = gif["url"]
print(f"{title} | {trending_date} | {url}")
In lines 4 and 5 of the above code, you defined the API_KEY and gifhy API endpoints because they don't change as often as other parts.
In line 7, use what you learned in the query parameters section to define parameters and add your own API key. You also include some other filters: limit access to 3 results and ratings to get only the right content.
Finally, after getting the response, you iterate over the result on line 9. For each GIF, you print its title, date, and URL on line 13.
Running this code in the console will output a somewhat structured GIF list:

Now, suppose you want to make a script that allows you to search for a specific word and get the first GIPHY match for that word. The different endpoints and minor changes in the above code can be completed quickly:
import requests
# Replace the following with the API key generated.
API_KEY = "API_KEY"
endpoint = "https://api.giphy.com/v1/gifs/search"
search_term = "shrug"
params = {"api_key": API_KEY, "limit": 1, "q": search_term, "rating": "g"}
response = requests.get(endpoint, params=params).json()
for gif in response["data"]:
title = gif["title"]
url = gif["url"]
print(f"{title} | {url}")
You can now modify this script to your liking and generate gifs as needed. Try to get gifs from your favorite programs or movies, add shortcuts to your terminal to get the most popular gifs on demand, or integrate with another API in your favorite messaging system - WhatsApp, Slack, etc. Then start sending gifs to your friends and colleagues!
COVID-19 confirmed cases were obtained in each country
go to top
Although this may be something you're tired of hearing now, there is a free API that contains the latest global COVID-19 data. This API does not require authentication, so it's easy to get some data immediately. The free version you'll use below has rate limits and some data limits, but it's enough for small use cases.
For this example, you will get the total number of confirmed cases as of the previous day. Again, I randomly selected Germany as the country, but you can choose any country / region you like:
import requests
from datetime import date, timedelta
today = date.today()
yesterday = today - timedelta(days=1)
country = "germany"
endpoint = f"https://api.covid19api.com/country/{country}/status/confirmed"
params = {"from": str(yesterday), "to": str(today)}
response = requests.get(endpoint, params=params).json()
total_confirmed = 0
for day in response:
cases = day.get("Cases", 0)
total_confirmed += cases
print(f"Total Confirmed Covid-19 cases in {country}: {total_confirmed}")
Your necessary modules are imported on lines 1 and 2. In this case, you must import date and timedelta objects to get today's and yesterday's dates.
In lines 6 to 8, define the country SLUG to be used, that is, the query parameters of the endpoint and API request. The response is a list of dates, and there is a case field every day, which contains the total number of confirmed cases for that date. On line 11, you create a variable to keep the total number of confirmed cases, and then online 14 you iterate over all dates and summarize them. The final print result will show the total number of confirmed cases in the selected country:
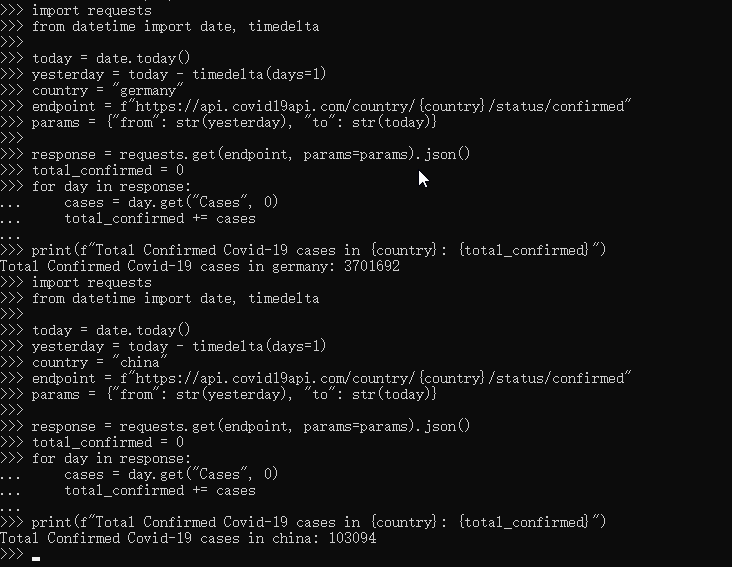
In the above example, the translator changed the country to china and rerun the program. It shows that the number of confirmed cases in china is only 100000.
If you just want to simply view the response, the above code can be abbreviated as
import requests
r = requests.get("https://api.covid19api.com/country/china/status/confirmed?from=2021/6/3&to=2021/6/4")
for province in r.json():
print(province.get("province"), province.get("Cases"), sep=":")
give the result as follows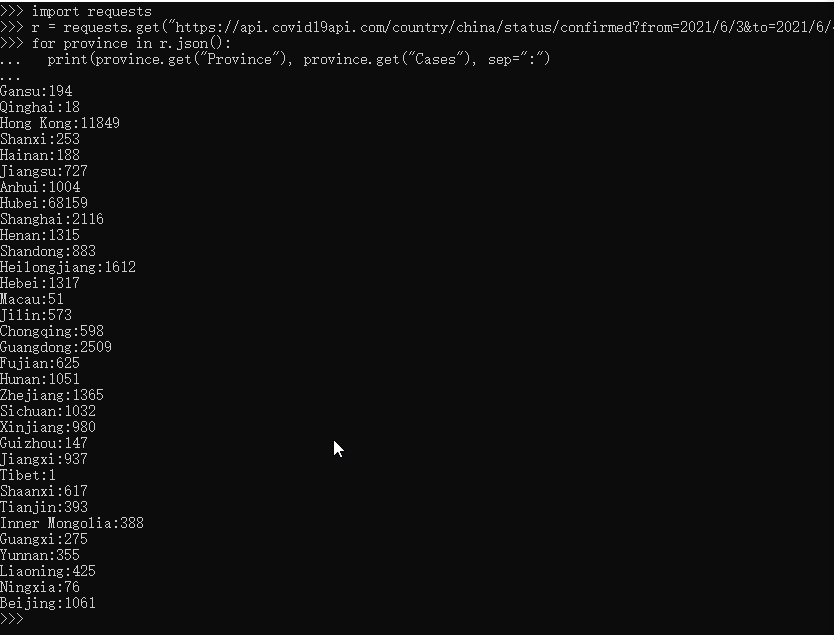
In this example, you are looking at the total number of confirmed cases in the entire country. However, you can also try to view documents and get data for specific cities. You can get more specific data, such as the number of recovered cases.
Search Google Books
go to top
If you are passionate about books, you may need a way to quickly search for specific books. You may even want to connect it to the search of your local library to see if the ISBN using the book offers a given book.
For this example, you will use the Google Books API and the public volume endpoint to perform a simple book search. This is a simple code to find the word moby dick in the whole directory:
import requests
endpoint = "https://www.googleapis.com/books/v1/volumes"
query = "moby dick"
params = {"q": query, "maxResults": 3}
response = requests.get(endpoint, params=params).json()
for book in response["items"]:
volume = book["volumeInfo"]
title = volume["title"]
published = volume["publishedDate"]
description = volume["description"]
print(f"{title} ({published}) | {description}")
This code example is very similar to the code example you saw earlier. Starting from lines 3 and 4, define important variables, such as endpoints, in this case queries.
After the API request is issued, start the iteration result on line 8. Then, on line 13, print the most interesting information for each book that matches the initial query:
The results are as follows:
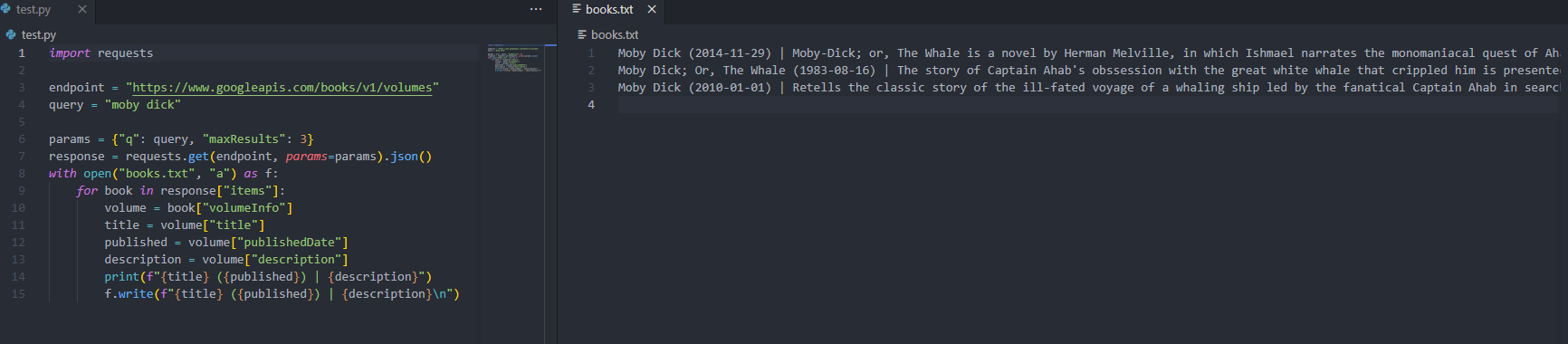
You can print the book variable within the loop to see what other fields you have available. Here are some things that may help to further improve this Code:
- industryIdentifiers
- averageRating and ratingsCount
- imageLinks
An interesting challenge to using this API is to use your OAuth knowledge and create your own bookshelf application to record all the books you read or want to read. Then you can even connect it to your favorite bookstore or library to quickly find books on sale near you from your wish list. It's just an idea - I'm sure you can think of more.
conclusion
go to top
There are many other things you can learn about APIs: different headers, different content types, different authentication techniques, and so on. However, the concepts and techniques you learn in this tutorial will allow you to practice with any API you like and use Python to meet any API you may have.
In this tutorial, you have learned
- What is API and what is API used for
- What are status codes, HTTP request headers, and HTTP methods
- How to use API to get public data through python
- How to apply authentication when using API through python
Continue to try some of your favorite public API s to try this new magic skill!
Reading Resource Recommendation
go to top
The API used as an example in this tutorial is only a small part of the many free public APIs. The following is a list of API collections that can be used to find the next favorite API:
You can look at these and find an API that can communicate with you and your hobbies, and may inspire you to use it for a small project. If you encounter a good public API that you think I or others reading this tutorial should know, please comment below!