python concurrent crawler - multithreaded, thread pool implementation
A web crawler usually consists of sending requests, getting responses, parsing pages, saving locally, and so on. Of course, the most difficult and detailed part is the page parsing link. For different pages, the parsing difficulty will inevitably vary. Even some websites with higher security also have various anti-pickpocket mechanisms. To get the required information, it needs to be specific. Of course, these are not covered by this article. This paper mainly focuses on how to use multithreaded, thread pool for concurrent operation to improve crawl efficiency.
1. Regular Web Crawlers
1. Execution order
Typically, when crawling a Web page using a crawler, we use the requests library to send a get request, get the response text, and then use the beautifulsoup library, regular expressions, xpath to parse the Web page text to get the data we need, and then do other processing on the data.
resp = requests.get(url).text
html = etree.HTML(resp)
result = html.xpath(//div[class="col-md-1/text()"])
print(result)
2. Disadvantages
1) Time-consuming. Throughout the crawling process, as long as the previous link has not been completed, the latter link has been in a waiting state, especially parsing the page link often takes a lot of time.
2) Low efficiency. This single-threaded process increases the overall crawl run time and reduces crawl efficiency.
3) Easy to crash. Once a module has an exception, the entire crawler crashes.
2. Concurrent Reptiles
1. Principles
The whole crawler is divided into CPU operation and IO operation. The CPU starts the task first. When it encounters an IO operation, the CPU switches to another Task to start execution. After the IO operation is completed, the CPU is notified to process. Since IO operations read memory, disk networks, and so on, without the involvement of the CPU, they can occur simultaneously, and the CPU can be freed to perform other Task accelerations. Using multi-threaded concurrent operation to execute programs can greatly reduce running time and improve efficiency.
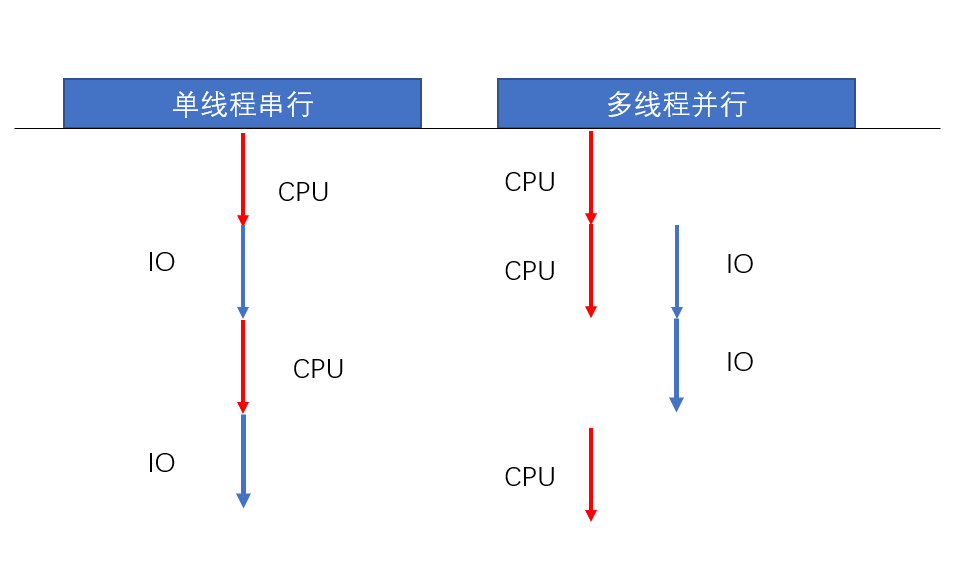
2. Advantages
1) Fast. Compared with single-threaded crawlers, multithreaded concurrent processing reduces unnecessary wait times and makes the entire program run faster.
2) High efficiency. Multithreads can perform CPU and IO operations simultaneously, reducing the overall program run time.
3) High security. Multithreads can use Lock mechanism to control global shared variables and ensure data correctness.
It is worth noting that due to the existence of Python multi-threaded GIL (Global Interpreter Lock) global interpreter locks, only one CPU can be used throughout the CPU operation. Each thread needs to obtain the GIL first at execution time to ensure that only one thread can execute code at the same time. Therefore, python's multi-threading is not really simultaneous execution. Using multi-threading to improve efficiency is only done by performing CPU and IO operations simultaneously, not by using multiple CPUs to perform Task simultaneously.
3. Application
Before introducing multithreading, introduce a crawler model (Producer-Consumer-Spider PCS) that needs to be used with producer-consumer. This mode integrates crawlers into producer and consumer modules. The producer is responsible for processing the input data and generating intermediate variables to pass to the consumer. Consumers are responsible for parsing content and generating output data.
In crawler programs, producers often process URLs and send requests for responses. Consumers often parse response pages to get output data.
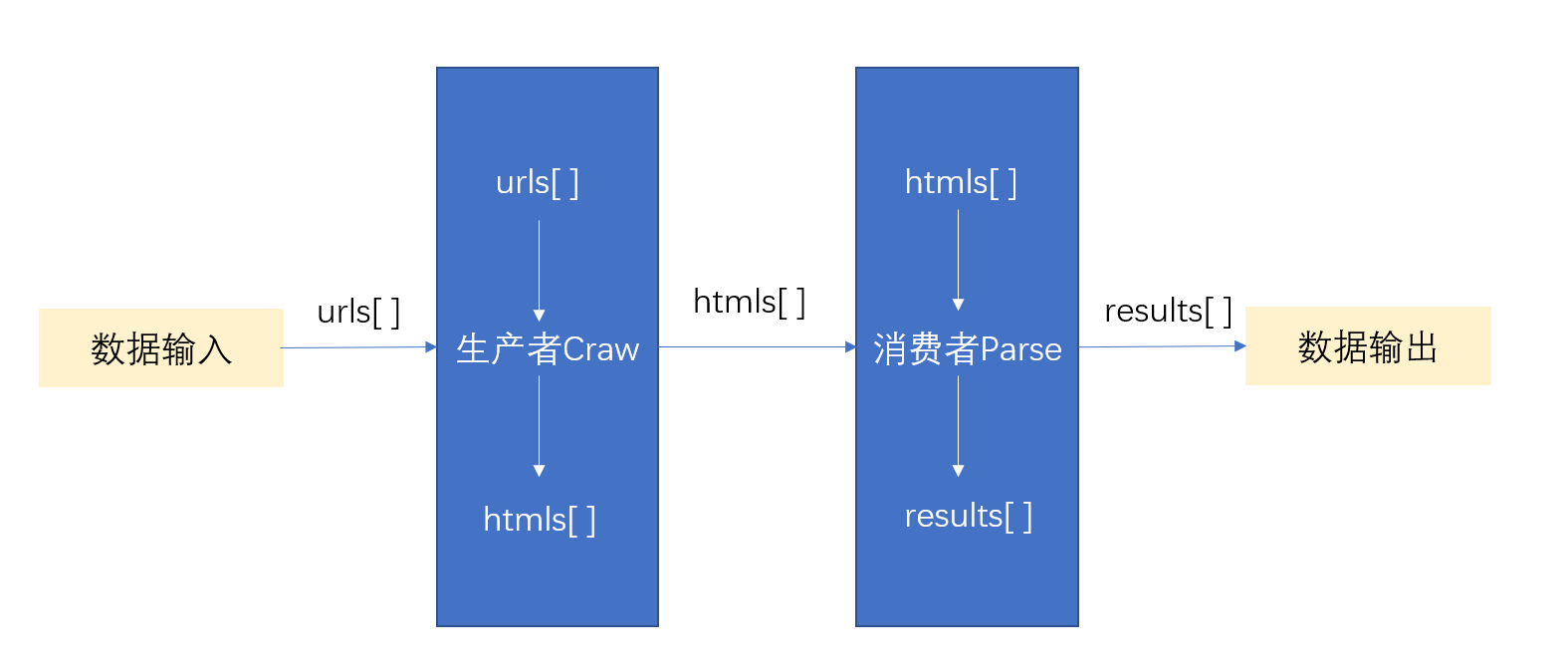
3.1 Multithreaded
python implements multithreading in many different ways, and here are a few of the commonly used methods.
1) General calls
Opening multithreading requires the introduction of threading packages through the function threading.Thread(target=fun, args=()) creates a thread. The target parameter is the name of the function that needs to execute the function (not the call without parentheses), and the args parameter is the tuple of parameters required by the function.
import threading
import requests
from lxml import etree
urls = [
f'https://www.cnblogs.com/sitehome/p/{page}'
for page in range(1, 20)
]
def craw(u):
res = requests.get(u)
print(u, len(res.text))
return res.text
def parse(h):
html = etree.HTML(h)
links = html.xpath('//a[@class="post-item-title"]')
results = [(link.attrib['href'], link.text) for link in links]
print(results)
return results
def multi_thread(u):
results = parse(craw(u))
for r in results:
print(r)
if __name__ == "__main__":
for u in urls:
t = threading.Thread(target=multi_thread, args=(u,))
t.start()
2) Custom Threads
By inheriting threading.Thread defines a thread class, essentially by refactoring the run() method in the Thread class and building an instance to start a thread without passing in the executed function and parameters. More powerful functionality can be achieved by rewriting the run method.
import threading
import requests
from lxml import etree
urls = [
f'https://www.cnblogs.com/sitehome/p/{page}'
for page in range(1, 20)
]
# Custom Threads
class MyThread(threading.Thread):
def __init__(self, url):
super(MyThread, self).__init__() # Refactoring run functions must be written
self.url = url
def run(self):
results = parse(craw(self.url))
for r in results:
print(r)
def craw(u):
res = requests.get(u)
print(u, len(res.text))
return res.text
def parse(h):
html = etree.HTML(h)
links = html.xpath('//a[@class="post-item-title"]')
results = [(link.attrib['href'], link.text) for link in links]
print(results)
return results
if __name__ == "__main__":
for u in urls:
t = MyThread(u)
t.start()
3) PCS mode
On the basis of regular crawlers, we use producer-consumer mode to improve, introducing queue to perform more complex operations on data and achieve more powerful functions. Create Thread Incoming url_queue queue executes the producer method to get html_queue queue, consumer methods from html_ Get data in queue queue to execute parsing method and get output data. End the thread until both queues are empty.
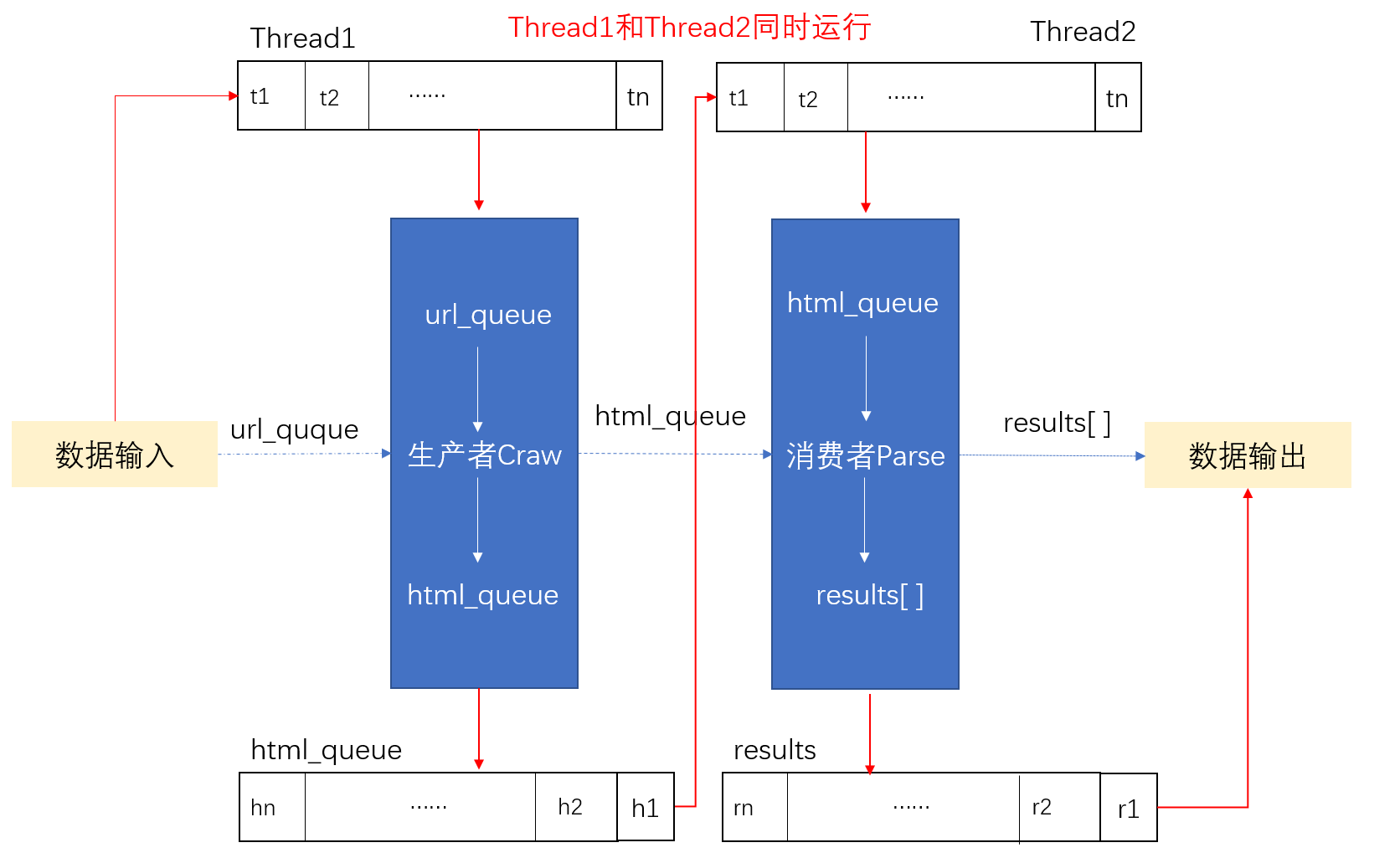
import queue
import random
import threading
import time
# Producer
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
while True:
u = url_queue.get()
html_queue.put(blog_spider.craw(u))
print(threading.current_thread().name, f"craw {u}",
'url_queue.qsize=', url_queue.qsize())
time.sleep(random.randint(1, 2))
#Consumer
def do_parse(html_queue: queue.Queue, fout):
while True:
h = html_queue.get()
results = blog_spider.parse(h)
for result in results:
fout.write(str(result) + '\n')
print(threading.current_thread().name, f"results.size", len(results),
'html_queue.qsize=', html_queue.qsize())
time.sleep(random.randint(1, 2))
if __name__ == "__main__":
url_queue = queue.Queue()
html_queue = queue.Queue()
for u in blog_spider.urls:
url_queue.put(u)
for idx in range(3):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f'craw{idx}')
t.start()
fout = open(r'results.txt', 'w+', encoding='utf-8')
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f'parse{idx}')
t.start()
3.2 Thread Pool
Although crawling with multiple threads can improve program efficiency, thread creation and destruction can consume resources, and too many threads can cause waste and increase running costs. Thread pools are introduced to manage threads, which are fetched from the thread pool when we need to call threads, and returned to the pool when they are exhausted. Threads are reused, greatly reducing running costs. Conurrent is required to create a thread pool. The ThreadPoolExecutor() method in the futures package.
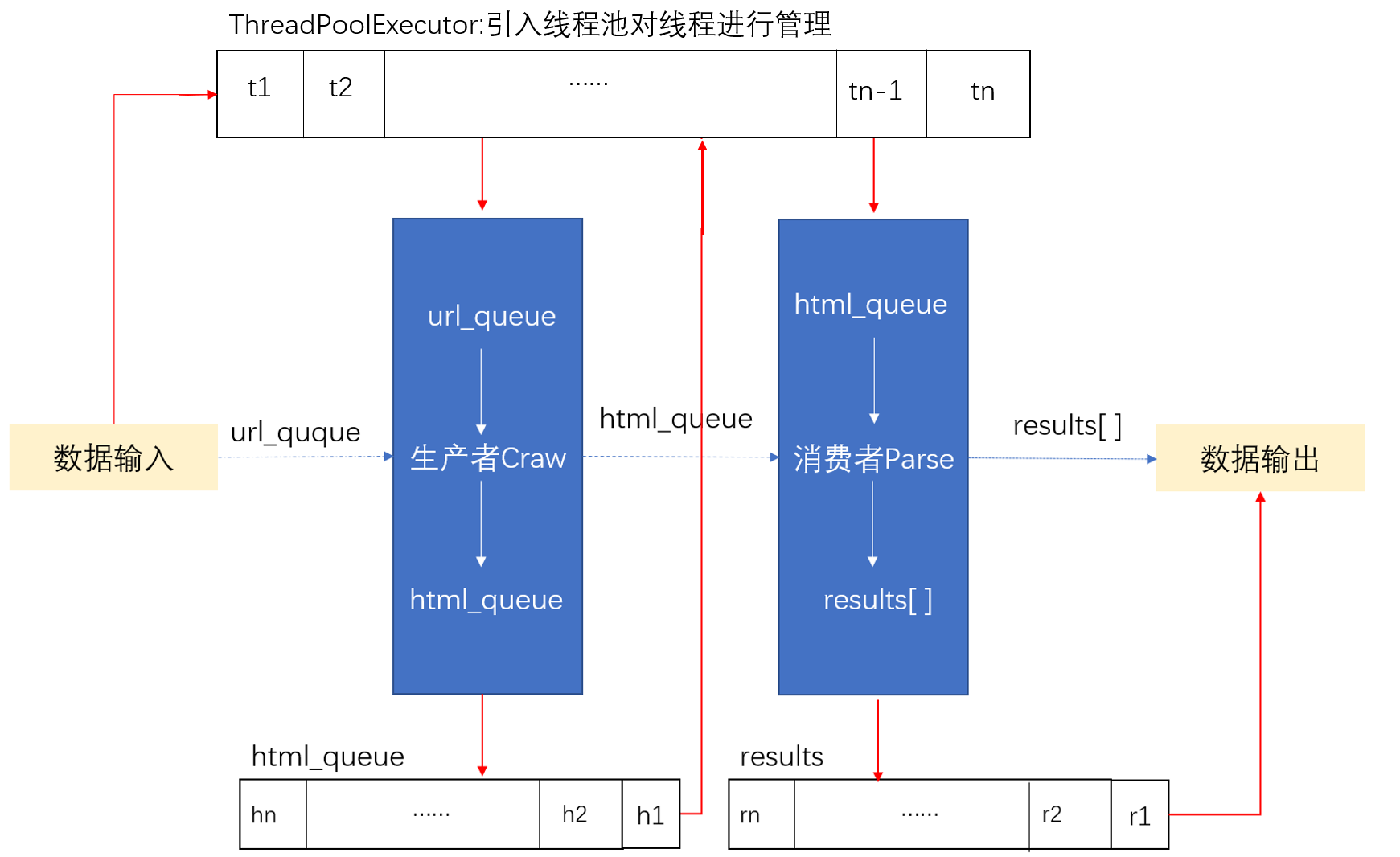
Thread pools can be created with ThreadPoolExecutor(), after which methods automatically get threads from the pool and execute concurrently. Parameter setting thread pool information can be passed in ThreadPoolExecutor(). For example, max_ The workers parameter sets the maximum number of threads in the pool. There are three ways to use thread pools:
1) One-time submission
Use pool. The map() method submits the tasks in the task queue at one time and obtains all the results. Note that there are two parameters in the map () method, one is the name of the method being executed and the other is the set of parameters required by the map () method and must be an Iterable object (*iterables).
from concurrent.futures import ThreadPoolExecutor,as_completed
# craw
with ThreadPoolExecutor() as pool:
htmls = pool.map(blog_spider.craw, blog_spider.urls)
htmls = list(zip(blog_spider.urls, htmls))
for url, html in htmls:
print(url, len(html))
2) Step-by-step submission
Use pool. The submit() method takes the Task execution out of the task queue in turn, encapsulates the results in turn into the future object, and calls the result() method to get the returned results.
# parse
with ThreadPoolExecutor() as pool:
futures = {}
for url, html in htmls:
future = pool.submit(blog_spider.parse, html)
futures[future] = url
for future, url in futures.items():
print(url, future.result())
3) Step-by-step submission of enhanced editions
Use as_completed() gives priority to returning results that have been executed. Threads that execute first encapsulate their return values into the future object during the entire code run. Compared with the second method, the running time is reduced and the execution efficiency is improved.
with ThreadPoolExecutor() as pool:
futures = {}
for url, html in htmls:
future = pool.submit(blog_spider.parse, html)
futures[future] = url
for future in as_completed(futures):
print(futures[future], future.result())
IV. Conclusion
Multithreading can be used in a wide range of scenarios, and knowing and mastering concurrent operations can greatly improve the efficiency of your program. Multithreaded crawls are on average 5-10 times more efficient than single-threaded crawls. Reasonable use of multithreading will make your program more efficient. Of course, multithreading involves a wide range of content, of which the Lock mechanism, which is not mentioned in this article, is one of its important contents. This article can be used as a starting point for concurrent operations with multiple threads, and more effort is needed to learn more about multithreading.