stay Python crawler actual combat (1) | climb the top 250 movies of Douban (Part 1) In, the result of our final climb out is not very perfect. How can we be reconciled to the "excellence and pursuit of perfection" program ape
So today, use python to climb into the top 250 movies on douban.com! Step! Version! Here he is!
We used urllib module and re module in crawling the top 250 movies (Part I) of douban.com to obtain web page information and analyze content.
As the saying goes, "if you want to do a good job, you must first sharpen your tools". Today, I want to focus on two new modules, which can make our reptile experience better and easier to use.
Requests module
In general, Python's official "battery" is the most reliable and practical -- except urllib. Because in the python community, there is an HTTP library better than Pyhotn's "son" urlib - Requests.
Requests simplifies many miscellaneous and meaningless operations in urllib and provides more powerful functions.
install
It is recommended to download in the Windows command line window. First, press and hold the win+R key to open the command line window and enter in it
pip install requests
GET request
The most basic get request can use the get() method directly
response = request.get("http://www.baidu. COM / ") or response = requests. Request (" get " http://www.baidu.com/ ")
Add header and url parameters
For example: I want to search the word salted fish in Baidu now. Enter and press enter. We can see that our url is like this

- If you want to add headers, you can pass in the headers parameter to add header information in the request header
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}url = "http://www.baidu.com/"response = requests.get(url, headers=headers)
- If you want to pass the parameter in the url, you can use the params parameter
kw = {"wd": "Salted fish"}url = "http://www.baidu.com/s?"response = requests.get(url, params=kw)
Beautiful Soup module
As this part of knowledge has a lot of contents, a special topic will be devoted to introduce it in the next issue
I believe most people first see this module and think: soup? Beautiful soup? This is not Cantonese old fire soup
Beautiful Soup is a Python library that can extract data from HTML or XML files. It can realize the usual way of document navigation, finding or modifying documents through your favorite converter
install
It is recommended to download in the Windows command line window. First, press and hold the win+R key to open the command line window and enter in it
pip3 install bs4

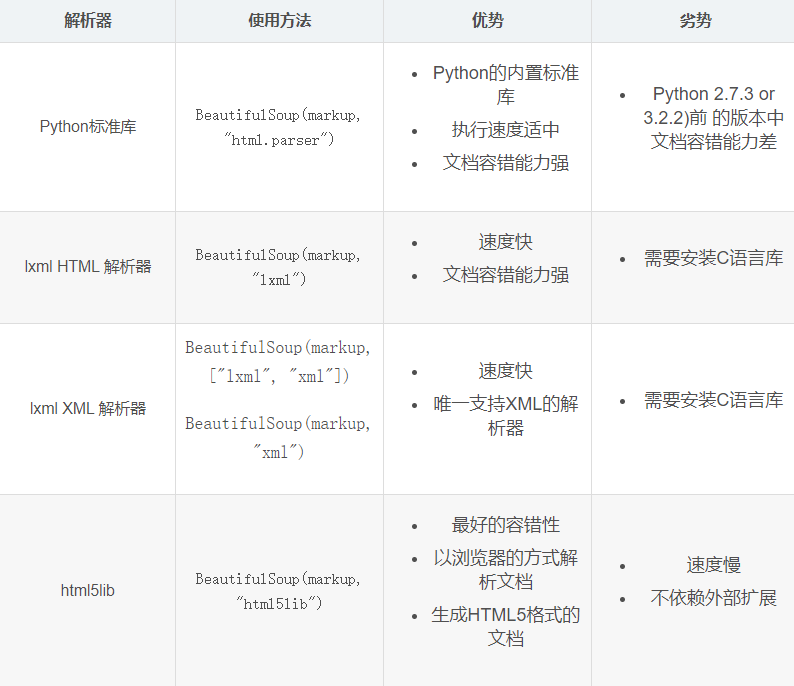
Parser
- Beautiful Soup supports HTML parsers in Python standard library and some third-party parsers, one of which is lxml, so please install lxml
pip install lxml
- Another alternative parser is html5lib implemented in pure Python. The parsing method of html5lib is the same as that of the browser. You can choose the following methods to install html5lib:
pip install html5lib
Object type
- Beautiful Soup transforms a complex HTML document into a complex tree structure, and each node is a Python object
- All objects can be classified into four types: tag, navigablestring, beautiful soup and comment
Tag
- Label: usually included in < >
- There are two important attributes: name and attrs
Each tag has its own name, for example
# obtain nameimport bs4html = '''<html><head><title>Test Html</title></head>'''# Select use lxml As a parser soup = bs4.BeautifulSoup(html, 'lxml')# Get nameprint(soup.title.name)print(soup.head.name)

We can use it attr gets all the attribute values (attrs) of the Tag object and returns the dictionary format. You can use ['key '] to get the specified attribute value. To be simple, we can also omit attrs and directly use tag['key '] to obtain it.
import bs4html = '''<ul> <li class="item-0" name="one"><a href="www.baidu.com">baidu</a>'''# Select use lxml As a parser soup = bs4.BeautifulSoup(html, 'lxml')# obtain li All attributes of the node, returned in dictionary form print(soup.li.attrs)# obtain li Nodal class Attribute value print(soup.li.attrs['class'])print(soup.li['class'])print(soup.li.get('class'))# obtain a Node all attributes print(soup.a.attrs)# Get the class attribute value print(soup.a.attrs['href'])print(soup.a['href'])print(soup.a.get('href ')) of node a
answer:
{'class': ['item-0'], 'name': 'one'}['item-0']['item-0']['item-0']{'href': 'www.baidu.com'}www.baidu.comwww.baidu.comwww.baidu.com
We can also get the text content (string) in the node, and get the first one by default
import bs4html = '''<ul> <li class="item-0" name="one"><a href="www.baidu.com">baidu</a> <li class="item-1" name="two"><a href="www.alibaba.com">alibaba</a>'''soup = bs4.BeautifulSoup(html, 'lxml')#Get attribute print(soup.a.attrs) get node content print(soup.a.string)print(soup.a.string)
answer:
{'href': 'www.baidu.com'}baidu
Query method search
- The above method of selecting nodes is too single, which is not suitable for actual development and use. Beautiful Soup provides some query methods for us to use
- find_all(),find()
find_all()
find_ The all () method searches all tag child nodes of the current tag and determines whether the filter conditions are met
find_all( name , attrs , recursive , text , **kwargs )
- Name: find all tag s named name, and the string object will be automatically ignored
- attrs: query by attribute and use dictionary type
- Text: you can search the string content in the document. Like the optional value of the name parameter, the text parameter accepts string, regular expression, list and True.
- Recursive: call find of tag_ When using the all() method, the Beautiful Soup will retrieve all the descendant nodes of the current tag. If you only want to search the direct child nodes of the tag, you can use the parameter recursive=False
- limit: find_ The all () method returns all the search structures. If the document tree is large, the search will be slow If we don't need all the results, we can use the limit parameter to limit the number of returned results. The effect is similar to the limit keyword in SQL. When the number of search results reaches the limit, the search will be stopped and the results will be returned
find()
- find_ The all () method will return all tags in the document that meet the criteria, although sometimes we just want to get one result. For example, if there is only one tag in the document, use find_ The all () method is not appropriate to find the label,
- Use find_ Instead of using the find() method directly, use the all method and set the limit=1 parameter The following two lines of code are equivalent:
soup.find_all('title', limit=1)soup.find('title')
- The only difference is find_ The return result of the all () method is a list whose value contains an element, while the find() method returns the result directly
- find_ The all () method returns an empty list if it does not find the target. When the find() method cannot find the target, it returns None
summary
- It is recommended to use lxml parsing library and HTML if necessary parser
- Label selection filtering function is weak but fast
- find() and find() are recommended_ All() query matches a single result or multiple results
- If you are familiar with CSS selectors, it is recommended to use select()
- Remember the common methods of getting attribute and text values
actual combat
As the saying goes, "all the knowledge you learn is told to you by others. Only by practicing it yourself can you turn it into your own."
After understanding the relevant knowledge of these two modules, let's conduct actual combat
Development environment:
python3.9
pycharm2021 Professional Edition
Let's first observe the web page and see its url rule:
first page: https://movie. douban. com/top250? Start = 0 & filter = second page: https://movie.douban.com/top250?start= 25 & filter = page 3: https://movie.douban.com/top250?start= 50&filter=
It is not difficult to see that each time the number of pages is increased by 1, the value of start in the url is increased by 20, - there are 10 pages in total, and the maximum value of start is 225. This is because there are 25 films on one page. There are 10 pages, or 250 films.
Press F12 to open the developer tool, find Elements and analyze the web content
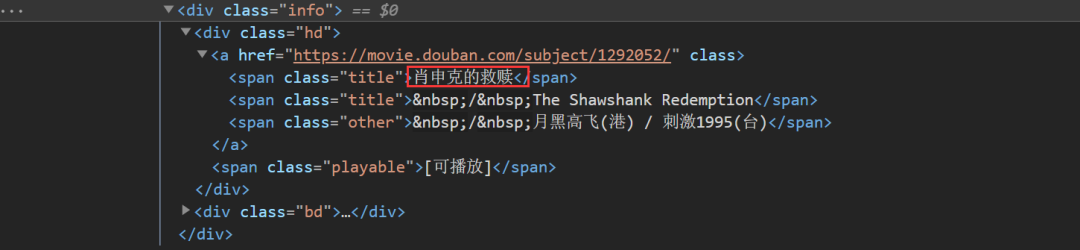
As we can see, the name of the film is right here
Its subordinate relationship is: div -- > A -- > span
This time, we made it more difficult and climbed down the film information. Let's take a look at the label where the movie information is stored
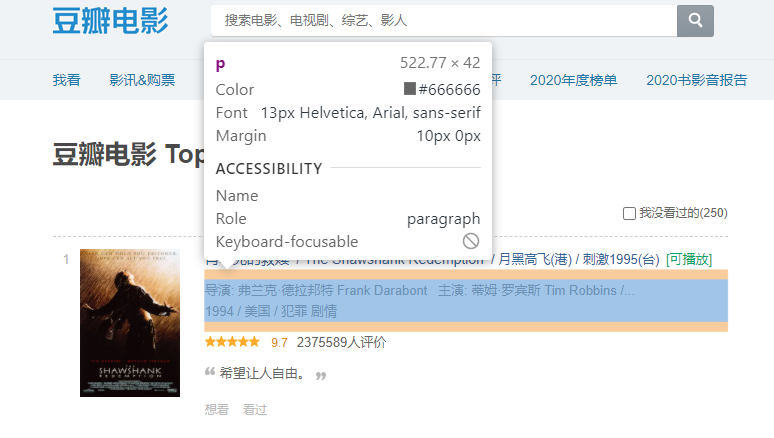
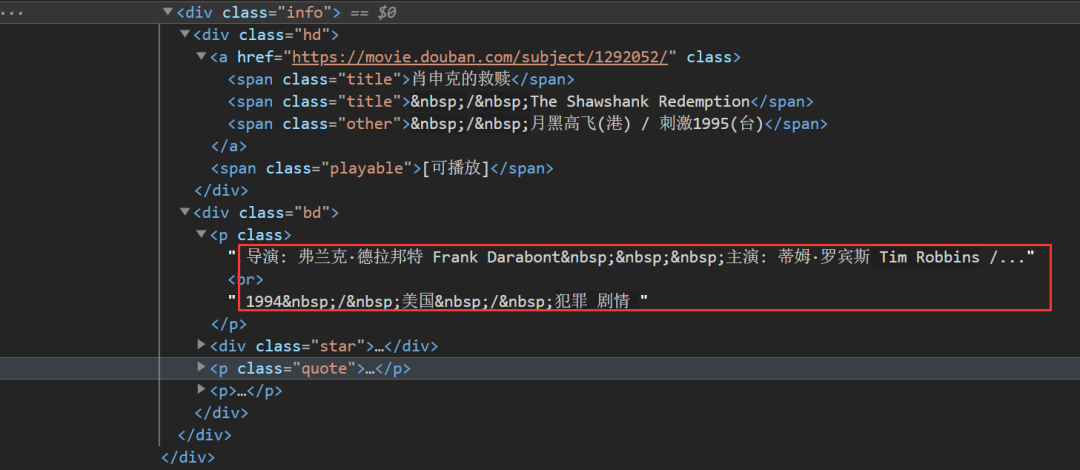
You can see that some of the descriptive information of the film is
Its subordinate relationship is: div - > P
So we can call find first_ All() method, find out the div tags with class = "info" attribute one by one, and return a list
Then find our movie name and description information from this list
Specify the order in which we crawl web pages according to the URL law
if __name__ == "__main__": """ The web address is: https://movie. douban. com/top250 """ pages = 0 while pages <= 225: url = ' https://movie.douban.com/top250?start=%s '% pages print ("crawling data......") pages += 25 download_ List (URL) print ("crawl completed!")
Use the web downloader to get web pages
In order to prevent the website from having anti crawler mechanism, we simulate the crawler as a browser and set the access time interval
def get_pages(url): headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41'} try: ''' Simulation browser, time interval ''' response = requests.get(url=url, headers=headers, timeout=5) except requests.exceptions as e: print('error') finally: content = response.text #Return the decoded html content return content
bs4 module is used to parse the obtained web page content
def get_movies(contents): soup = bs4.BeautifulSoup(contents, "lxml") ''' find_all()Method returns a list of all movie names and information of the current web page list ''' div_list = soup.find_all('div', class_='info') movies_list = [] for each in div_list: ''' Movie name and information ''' movies_name = each.find('div', class_='hd').a.span.text.strip() movies_info = each.find('div', class_='bd').p.text.strip() movies_info = movies_info.replace("\n", " ").replace("\xa0", " ") movies_info = ' '.join(movies_info.split()) '''zhon Add the movie name and information of the current page to a list ''' movies_list.append([movies_name, movies_info]) return movies_list
Write the obtained movie name and information into the txt file
with open('Douban film top250.txt', 'a+', encoding='utf-8') as file: for info in movies_list: file.write(info[0]+'\t') file.write(info[1]+'\n')
The source code is as follows
import requestsimport bs4def get_pages(url): headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41'} try: response = requests.get(url=url, headers=headers, timeout=5) except requests.exceptions as e: print('error') finally: content = response.text return contentdef get_movies(contents): soup = bs4.BeautifulSoup(contents, "lxml") div_list = soup.find_all('div', class_='info') movies_list = [] for each in div_list: ''' Movie name and information ''' movies_name = each.find('div', class_='hd').a.span.text.strip() movies_info = each.find('div', class_='bd').p.text.strip() movies_info = movies_info.replace("\n", " ").replace("\xa0", " ") movies_info = ' '.join(movies_info.split()) movies_list.append([movies_name, movies_info]) return movies_listdef download_list(url): web_url = url contents = get_pages(web_url) movies_list = get_movies(contents) with open('1.txt', 'a+', encoding='utf-8') as file: for info in movies_list: file.write(info[0]+'\t') file.write(info[1]+'\n')if __name__ == "__main__": """ The web address is: https://movie. douban. com/top250 """ pages = 0 while pages <= 225: url = ' https://movie.douban.com/top250?start=%s '% pages print ("crawling data......") pages += 25 download_ List (URL) print ("crawl completed!")
Let's see how it turns out

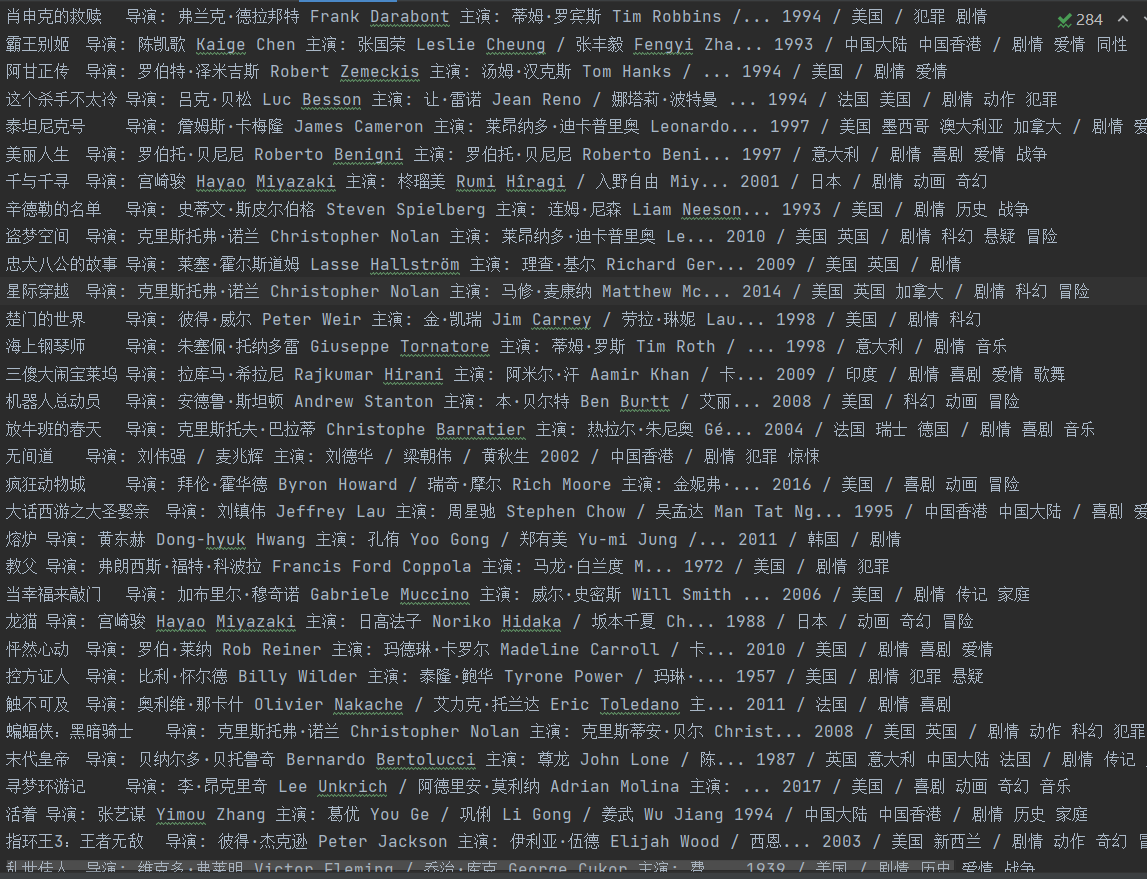
At the end of the article, I'd like to ask you to upgrade it and download the poster pictures of the film. Welcome to contribute!