preface
In python crawlers, multi process crawling is generally used, because multithreading can not improve CPU utilization, and multithreading is actually executed alternately, and multi process is executed concurrently.
Multi process, as the name suggests, multiple processes execute concurrently, which can effectively improve the execution efficiency of the program. The advantage is very stable. Even if a sub process crashes, the main process and other processes can still continue to execute. The disadvantage is that the cost of creating processes under windows is relatively large, and if there are too many processes, it will often affect the scheduling of the whole system.

1, Advantages of multi process
Why choose multi process instead of multi thread? This is the final choice considering many actual situations.
- In the python environment, multi process is slightly better than multi thread, which is easier to implement and understand.
- Because most crawlers run on the server of linux kernel, and under the linux operating system, multi process is more suitable than multi thread, because the scheduling overhead is similar to that of multi thread, but the process performance is better. If running crawlers under windows system, it is recommended to use framework or multithreading.
- After all, crawlers are not server interaction. No one will open 1k threads to run this, so generally, we can improve the efficiency of our crawlers by several times.
2, Multi process and single process
First, the results of the previous multi process and single process test:
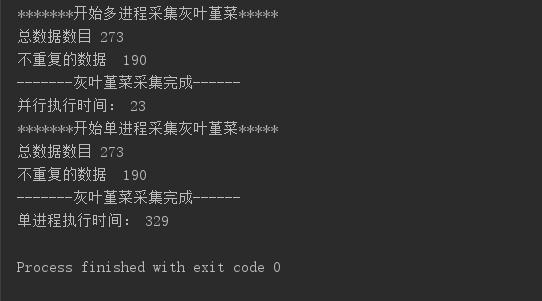
We can find that the execution speed of multi process is more than 100 times faster than that of single process, so the parallel method is good
I use the Pool method here to use multi process
When you use the Process class to manage many (dozens or hundreds) processes, it will be more cumbersome. This is that you can use the Pool (Process Pool) to uniformly manage the processes. When the Process in the Pool is full, when a new Process requests execution, it will be blocked. Until the execution of a Process in the Pool ends, the new Process request will not be put into the Pool and executed.
3, Examples
import multiprocessing
from bs4 import BeautifulSoup
import requests
def pageUrls(url):
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text, 'lxml')
sum = int(soup.select('span.total > em:nth-of-type(1)')[0].get_text())
pageNum = sum/50
return [url+'/loupan/s?p={}'.format(str(i)) for i in range(1, pageNum+2, 1)]
def detailPage(myurl):
urls = pageUrls(myurl)
for url in urls:
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text, 'lxml')
titles = soup.select('div.list-results > div.key-list > div > div.infos > div > h3 > a')
for title in titles:
print url
print title.get_text()
print title.get('href')
def main(urls):
pool = multiprocessing.Pool(multiprocessing.cpu_count())
for url in urls:
pool.apply_async(detailPage, (url, ))
# pool.map(detailPage, urls)
pool.close()
pool.join()
if __name__ == "__main__":
startUrl = 'http://tj.fang.anjuke.com/?from=navigation'
web_data = requests.get(startUrl)
soup = BeautifulSoup(web_data.text, 'lxml')
urls = [url.get('href') for url in soup.select('.city-mod > dl > dd > a')]
main(urls)
Code analysis:
if __name__ == "__main__":
startUrl = 'http://tj.fang.anjuke.com/?from=navigation'
web_data = requests.get(startUrl)
soup = BeautifulSoup(web_data.text, 'lxml')
urls = [url.get('href') for url in soup.select('.city-mod > dl > dd > a')]
main(urls)
Here's a little bit of knowledge. If name = = "mainthe purpose of this code is to ensure that this py file will not be run when it is import ed. It will only run when it is actively executed.
This time we picked up the housing information of Anju. I believe everyone can understand the above code. Enter from the entrance, get the links to cities all over the country, and then enter the main function
pool = multiprocessing.Pool(multiprocessing.cpu_count())
multiprocessing is a standard multi process library in python. The above code means to create a process pool, and the number of processes is the number of cpu cores. Here's a little knowledge. The number of cores of the computer's cpu can execute as many processes at the same time. Of course, you can fill in a lot, but it doesn't work much. The more processes, the faster they will execute.
pool.apply_async(detailPage, (url, ))
apply_async function takes a process from the process pool to execute func. args is the parameter of func. Our code constantly takes the process from the process pool to execute our detailPage method. Of course, which of the following methods can also be adopted:
pool.map(detailPage, urls)
map method, apply the * * detailPage() * * function to each element of the table, and each element in the table will be affected. Both ways are OK~
pool.close()
Close the process pool, and the process pool will not create new processes
pool.join()
All processes in the wait process pool are used to wait for the worker process in the process pool to finish executing, so as to prevent the main process from ending before the worker process ends
In this way, for my computer, it is equivalent to opening 8 processes to parallel crawler (it will be blocked without anti pickpocketing for a while, ha ha). After my test, the speed is about 4 times faster than that of a single process, which is still very useful~
For the remaining two functions, I will not repeat pageUrls. The url of page pages is generated according to the amount of data on the page, and the detailPage picks up the title information of all buildings on each page.
summary
Today, we introduced the multi process, and at the same time, we practiced how to extend from one entrance of the website to capture the content of the whole website. Of course, everyone has different habits of writing code. When you practice more, you naturally have your own way to achieve the functions you want.