Statement before reading: This article aims to exchange technology, respect copyright, respect originality, surf the Internet scientifically, and shall not be used in illegal ways to use technology safely. I am not responsible for the adverse consequences caused by improper use of technology
catalogue
Problem origin
Recently, I want to learn English. I have read several courses. It is suggested to see American dramas. It recommends several American dramas. They should be good. They haven't finished yet. Those who are interested can have a look!! The list of shadow sheets is as follows:
- Anna
- Fashion devil's head
- Operation target Hitler
My friend recommended it[ Renren film and television ]I don't know whether it's my own network problem or because the website server is external or for other reasons. Three times a second, online playback will be painful for thieves, so I want to download it and watch it. By the way, I hoard some goods to kill the boredom of the National Day high-speed railway, and I'll fight to see some American dramas.
network analysis
Take Anna as an example. The developer mode queries the network transmission and finds the request of m3u8 first. Here is double-layer nesting, but fortunately there is no encryption, There is no way to encrypt for the time being. There are many cases on the Internet. I tried a lot and failed
Explain: m3u8 is a streaming media format. It exists in the form of file list, which records the version number, encryption method, file list and other information
As shown in the following figure, first find the first layer index file
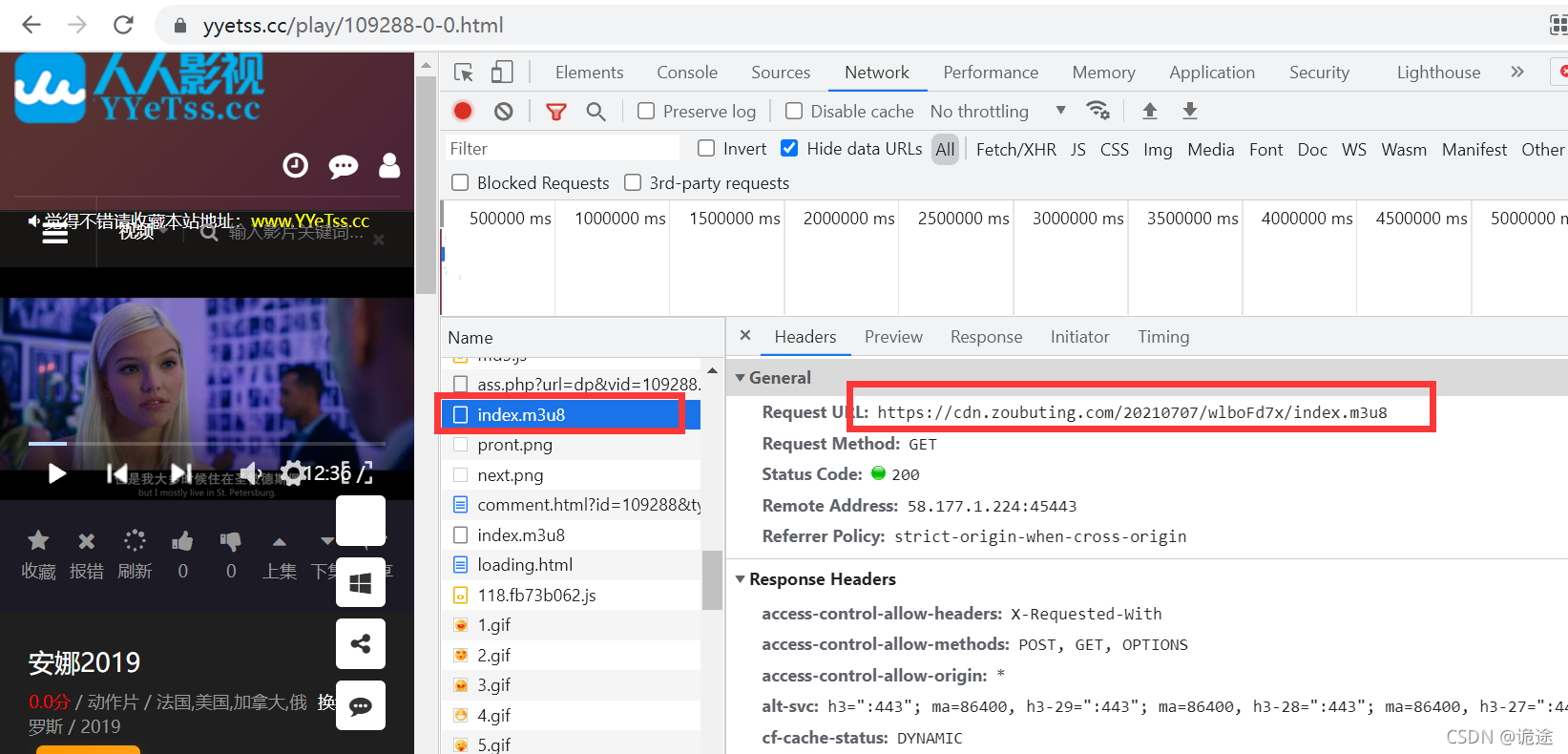
Directly copy the request url to the browser, download the m3u8 file, and open it with notepad / notepad + +. The contents of the file are as follows. Here is the path of the real m3u8 file

Play a segment, find a segment ts, and resolve the path of the current request domain
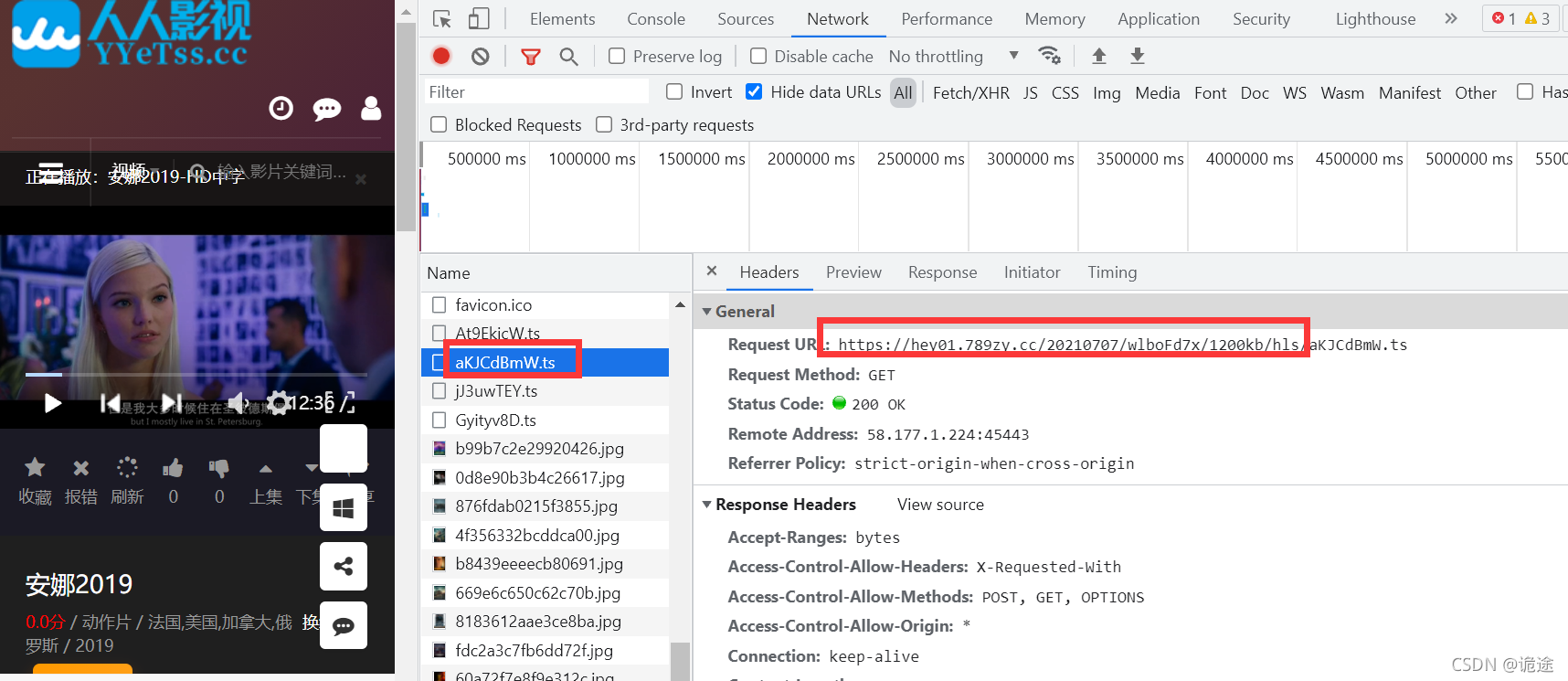
Splice the domain path in front with the m3u8 path in the first layer in front Get real m3u8 request
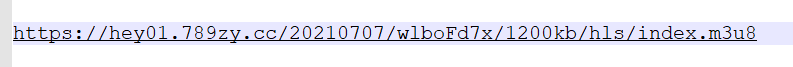
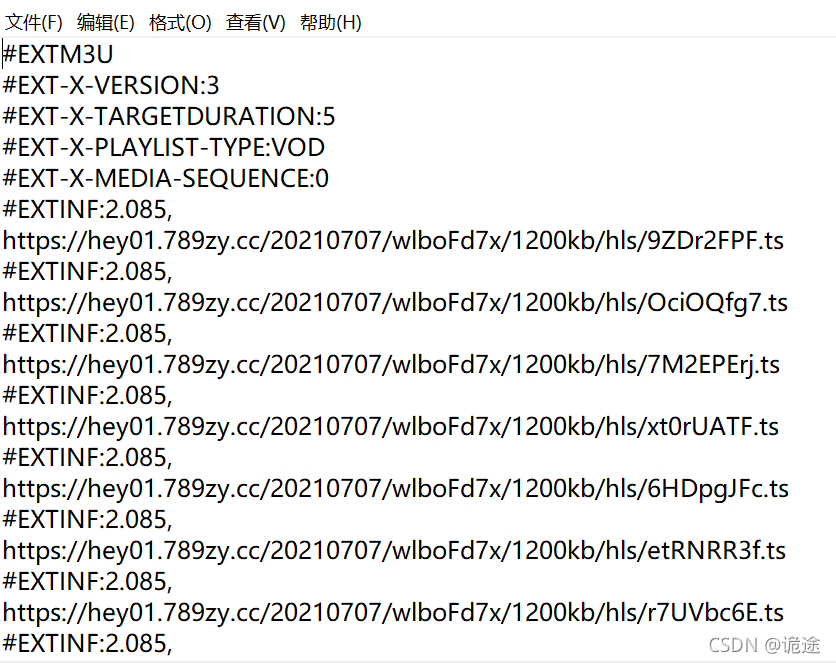
Repeat the previous steps: copy the full connection to the browser – > download
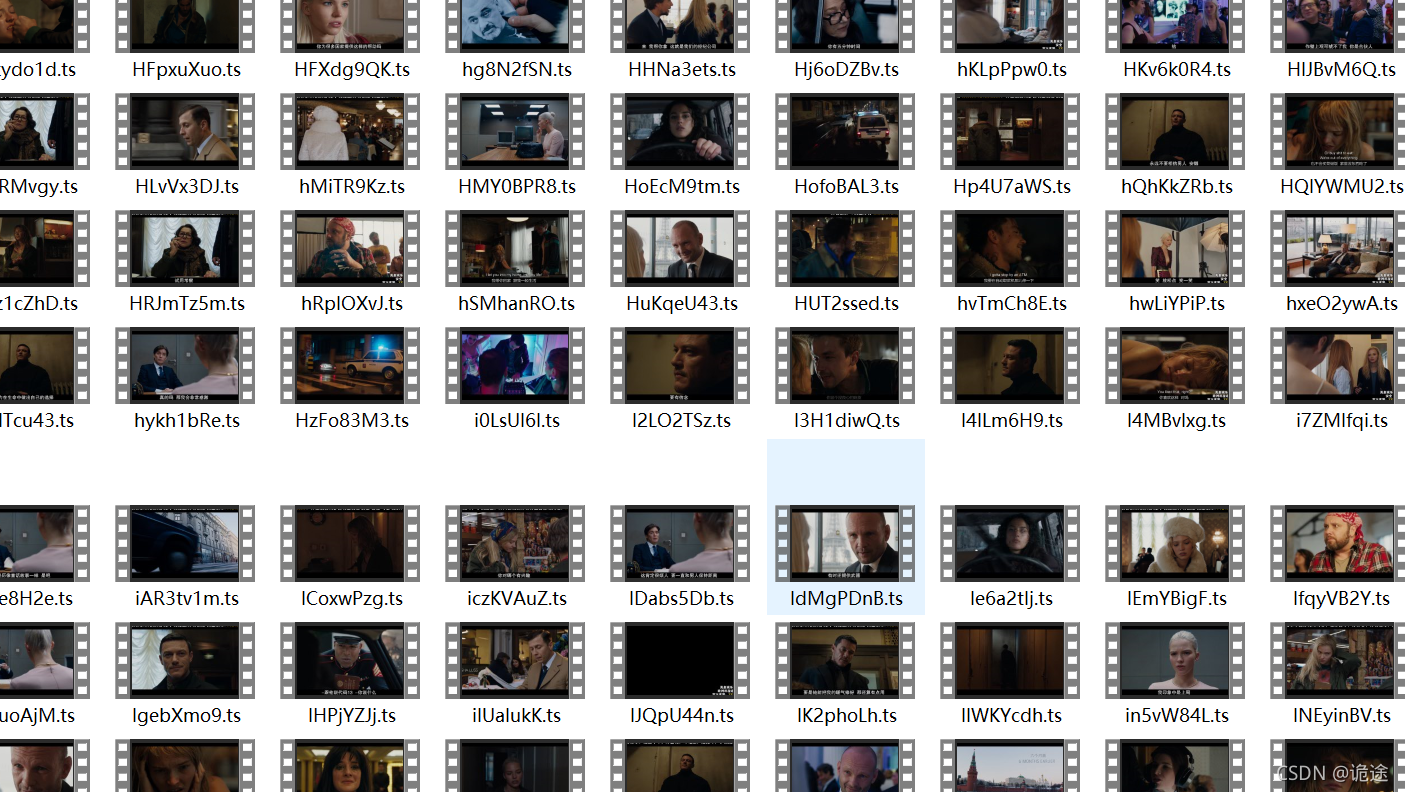
Here, you can get all the ts paths and sequences, analyze them and merge them
Code example
import requests,os
def download_ts_file(url,num,total):
"""single ts File download"""
# Here you can use your own or fake_useragent generates random request header
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
response=requests.get(url,headers=headers)
data = response.content
file_name = url.split("/")[-1]
ts_path = os.path.join(tmp_path,file_name)
with open(ts_path,'wb') as f:
f.write(data)
f.close()
print(f"The first[{num+1}/{total}]individual ts fragment{file_name}Download complete")
return None
# ts temporary storage path
tmp_path = os.path.join(os.getcwd(),"tmp_path")
# Read and parse ts links
f = open("index.m3u8","r",encoding="utf-8")
m3u8 = f.readlines()
f.close()
url_list = [url.split("\n")[0] for url in m3u8 if "https" in url]
# Loop download each ts fragment -- multithreading can be used here. There is no acceleration for security reasons. Those interested can try it themselves
[download_ts_file(url,url_list.index(url),len(url_list)) for url in url_list]
----------Say important things three times, pay attention to safety, pay attention to safety, pay attention to safety--------
----------Say important things three times, pay attention to safety, pay attention to safety, pay attention to safety--------
----------Say important things three times, pay attention to safety, pay attention to safety, pay attention to safety--------
--------------------------—
-----------Split line, fast multithreading speed, pay attention to safety!----------
-----------I didn't want to use multithreading, but single thread is too slow----------
import requests,os
def download_ts_file(num,url_list):
"""single ts File download"""
url,total = url_list[num],len(url_list)
# Here you can use your own or fake_useragent generates random request header
headers={'User-Agent':'xxxxx'}
response=requests.get(url,headers=headers)
data = response.content
file_name = url.split("/")[-1]
ts_path = os.path.join(tmp_path,file_name)
with open(ts_path,'wb') as f:
f.write(data)
f.close()
print(f"The first[{num+1}/{total}]individual ts fragment{file_name}Download complete")
return None
# ts temporary storage path
tmp_path = os.path.join(os.getcwd(),"tmp_path")
# Read and parse ts links
f = open("index.m3u8","r",encoding="utf-8")
m3u8 = f.readlines()
f.close()
url_list = [url.split("\n")[0] for url in m3u8 if "https" in url]
# Loop download each ts fragment -- multithreading can be used here. There is no acceleration for security reasons. Those interested can try it themselves
from concurrent.futures import ThreadPoolExecutor # Thread pool
p = ThreadPoolExecutor(8)
for num in range(len(url_list)):
p.submit(download_ts_file, num,url_list)
---------—I am another dividing line——————————————
-------Here's how to ts Synthesized into MP4 Format——————————
#Method 1: read and write directly. Pay attention to reading and writing in the order given by the m3u8 file
import os
# ts temporary storage path
tmp_path = os.path.join(os.getcwd(),"tmp_path")
# Read and parse ts links
f = open("index.m3u8","r",encoding="utf-8")
m3u8 = f.readlines()
f.close()
url_list = [url.split("\n")[0] for url in m3u8 if "https" in url]
with open('Anna 2019.mp4','wb') as f2:
for url in url_list:
file_name = url.split("/")[-1]
ts_path = os.path.join(tmp_path,file_name)
f1 = open(ts_path,"rb")
data = f1.read()
f1.close()
f2.write(data)
f2.close()There is another way to merge ts, but the upper limit can only be 450. Here is a large video, which is not applicable. You can understand it for reference. Of course, there are ways to avoid this bug. I won't talk about it in detail here. If you are interested, check the information yourself
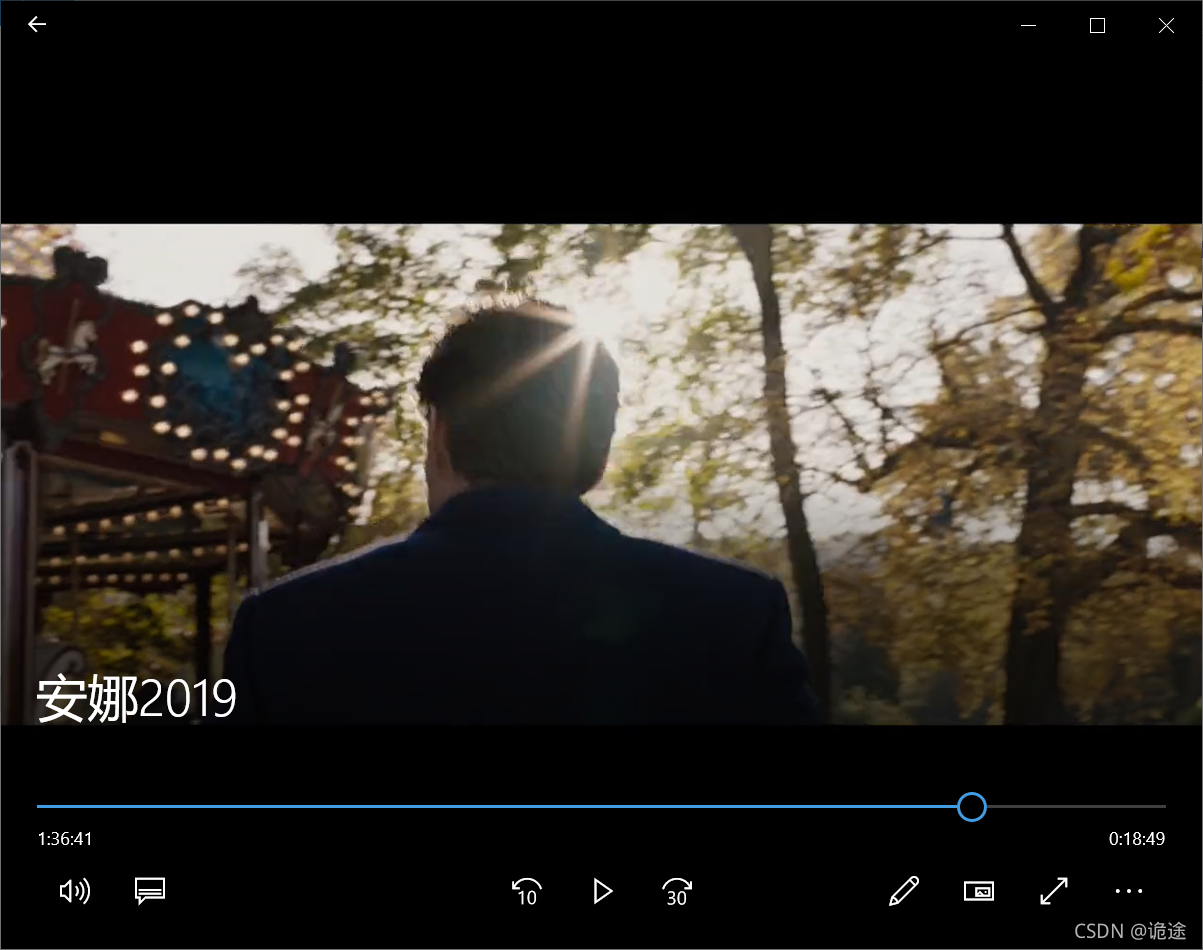
Result display