Use request to crawl Python books on Taobao
The main crawling targets are: Commodity title, sales store, number of payers, current selling price, store location, tmall commodity ID, book title, author, pricing, publisher name, ISBN number, etc
Step 1: bypass anti climbing
Facing the anti crawling mechanism of Taobao, we need to log in to our Taobao account on the Taobao page, then enter and search "Python books" in the search box, and then press F12, Network - > to find "search? & initiative_id ="
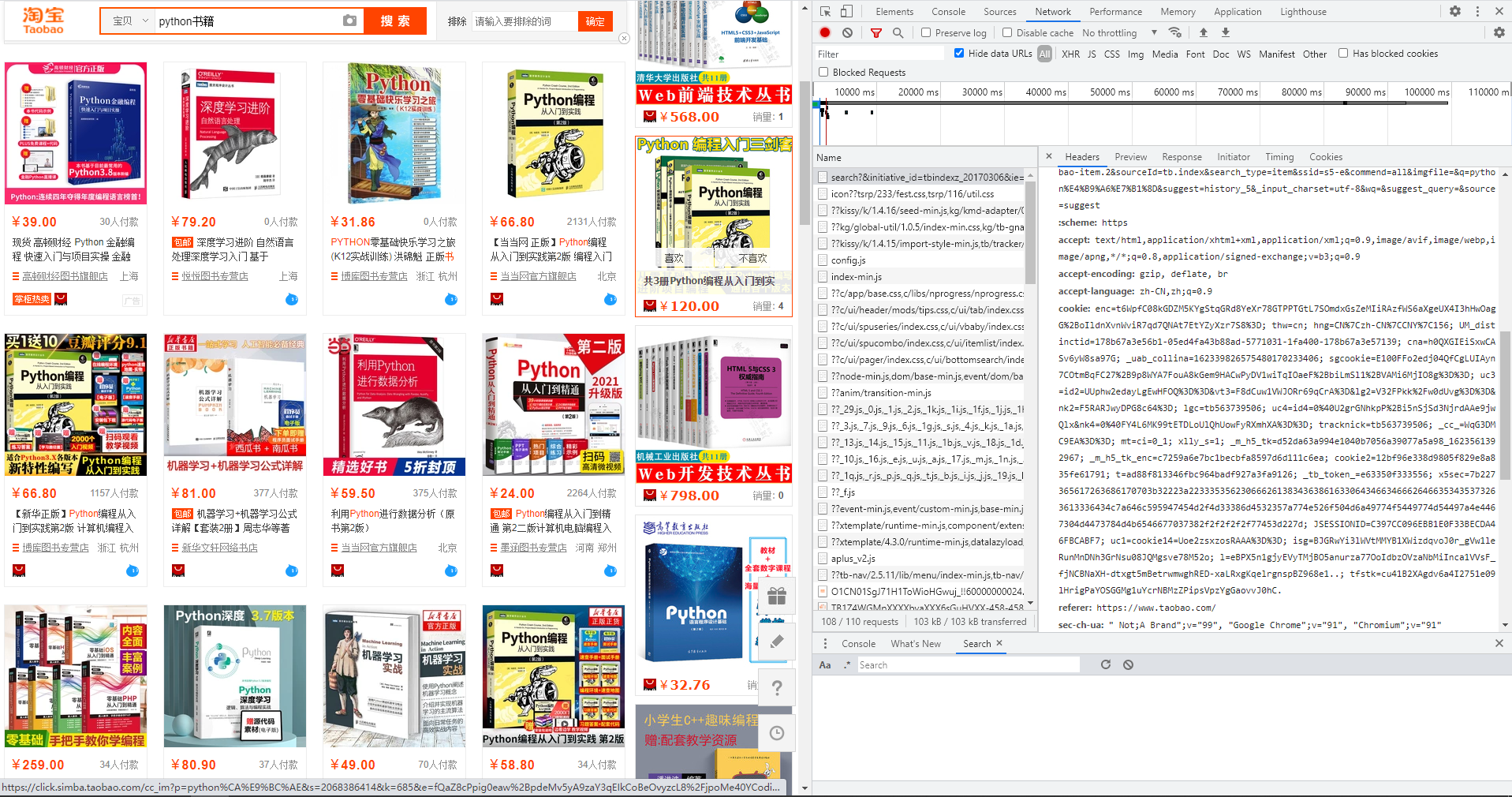
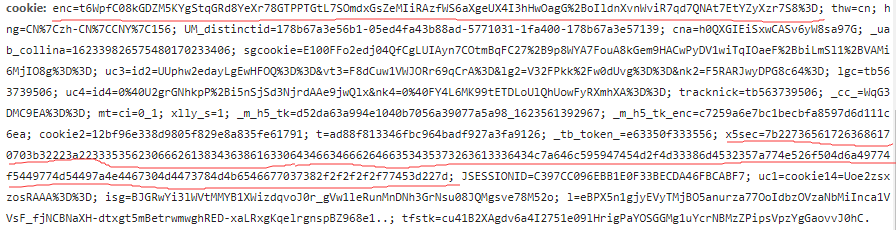
The next step is to copy the cookie
(there are two important values in the cookie, enc =; x5sec =; the rest can be omitted ~ ~ ~)
Sometimes, Taobao doesn't allow you to crawl. You need to verify the information. We can refresh the page of Taobao in the browser and manually verify it (the most annoying sliding verification T.T. crawls with selenium should know...) More often, we need to reopen a Taobao page to re verify, and then need to modify the cookie again
Key point: remember! Remember! Remember! Change your own "x5sec =" and this value will change after verification
Step 2: crawl information
First, we need to find our url

https://s.taobao.com/search?q=python%E4%B9%A6%E7%B1%8D
At this time, only the first page is displayed, if you enter the second and third pages
Page 2: https://s.taobao.com/search?q=python%E4%B9%A6%E7%B1%8D&s=44
Page 3: https://s.taobao.com/search?q=python%E4%B9%A6%E7%B1%8D&s=88
So, it's an integral multiple of 44
url =f'https://s.taobao.com/search?q=python%E4%B9%A6%E7%B1%8D&s={num}'
With the url, we also need user agent and agent IP (all can be found on the Internet ~)
Headers={
'User-Agent':,
'cookie':,
}
result = requests.get(url, headers=Headers, proxies=IP)
When I look at the printing process, I'm a good guy. It's really "what I see is not what I get". The information I need is a little difficult to select css and Xpath. It's better to be honest and practical re (jsonpath is also OK ~)

Step 3: get filtering information
If re is used, the small is surrounded by the large first, and then extracted step by step, which can avoid redundant information
data = result.text
list = re.findall('g_page_config = (.*?)"recommendAuctions"', data, re.S)
lis = str(list)
title = re.findall('"raw_title":"(.*?)"', lis, re.S) #Product title
shop = re.findall('"nick":"(.*?)"', lis, re.S) #Merchant shop
v_sale = re.findall('"view_sales":"(.*?)"', lis, re.S) #Number of people paid
v_price = re.findall('view_price":"(.*?)"', lis, re.S) #price
item_loc = re.findall('"item_loc":"(.*?)"', lis, re.S) #Merchant address
IDs = re.findall('"auctionNids":\[(.*?)]', data, re.S) #Note here that the id is not the same as the above information
ids = re.findall('"(.*?)"', str(IDs), re.S) #Taobao commodity id
After obtaining ids, you can crawl the next level of web pages
Here I use the css selector in the form of a dictionary
new_url = f'https://detail.tmall.com/item.htm?id={id}'
resp = requests.get(new_url, headers=Headers(), proxies=IP(),timeout=5) #It's easy to have anti crawling verification here. Set 5s to facilitate manual verification in the browser
n_data = resp.text
text = parsel.Selector(n_data)
d_list = text.css('div.attributes-list ul li::text').getall()
dit = {}
for lis in d_list[1:]:
a = lis.split(':')[0]
b = lis.split(':')[1].strip()
dit[a] = b
base_text.append(dit)
Step 4: speed up multithreading
There are many secondary web pages. One id corresponds to one product page. At this time, we need to speed up multithreading
def thr(ids):
threads=[]
print('=====Start testing!')
for i in range(1, 11): #Set 10 threads, ori give it!!!
thread=threading.Thread(target=get_more, args=(ids,)) #get_more is a function of crawling secondary web pages
thread.start()
threads.append(thread)
time.sleep(0.2)
print('===== No.{} Thread 1 starts working!'.format(i))
for th in threads:
th.join()
print('completed!')
Step 5: organize and make documents
Tired, go straight to the code
f = open('TaoBao\\'+'Python book.csv', 'a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['title', 'Sales shop', 'Number of payers', 'Current selling price', 'Store location', 'Tmall products ID',
'title', 'author', 'price', 'Name of Publishing House', 'ISBN number'])
csv_writer.writeheader()
def make_file(title, shop, v_sale, v_price, item_loc, IDs, text):
for i in range(len(title)):
dit = {
'title': title[i],
'Sales shop': shop[i],
'Number of payers': v_sale[i],
'Current selling price': v_price[i],
'Store location': item_loc[i],
'Tmall products ID': IDs[i],
'title': text[i].get('title', None), #Remember to set None
'author': text[i].get('author', None),
'price': text[i].get('price', None),
'Name of Publishing House': text[i].get('Name of Publishing House', None),
'ISBN number': text[i].get('ISBN number', None),
}
csv_writer.writerow(dit)
last
This is the first time Xiaobian has published an article. I hope the big guys can give me more advice~
Here are all the codes:
('IP()' and Headers() 'are modified into their own, which should also be able to run ~ ha ha ha ha ha ~)
import requests
import csv
import parsel
import random
from userAgent import useragent
import re
import time
import threading
def IP():
f = open('Agent pool_6 November 11.txt', 'r')
list = f.readlines()
ls = list[random.randint(0, 700)]
ip = eval(ls)
return ip
def Headers():
headers = {
'User-Agent': useragent().getUserAgent(),
'cookie': 'enc=t6WpfC08kGDZM5KYgStqGRd8YeXr78GTPPTGtL7SOmdxGsZeMIiRAzfWS6aXgeUX4I3hHwOagG%2BoIldnXvnWviR7qd7QNAt7EtYZyXzr7S8%3D; x5sec=7b227365617263686170703b32223a226630336633393332313539306462306330656239313139343037666463386661434b37746c595947454e713073366559702b546d50786f504d6a49774f5449774d54497a4e4467304d4473784b4149776b7043442f674d3d227d;'
}
return headers
def get_data(num):
url =f'https://s.taobao.com/search?q=Python%E4%B9%A6%E7%B1%8D&s={num}'
result = requests.get(url, headers=Headers(), proxies=IP())
data = result.text
list = re.findall('g_page_config = (.*?)"recommendAuctions"', data, re.S)
lis = str(list)
title = re.findall('"raw_title":"(.*?)"', lis, re.S)
shop = re.findall('"nick":"(.*?)"', lis, re.S)
v_sale = re.findall('"view_sales":"(.*?)"', lis, re.S)
v_price = re.findall('view_price":"(.*?)"', lis, re.S)
item_loc = re.findall('"item_loc":"(.*?)"', lis, re.S)
IDs = re.findall('"auctionNids":\[(.*?)]', data, re.S)
ids = re.findall('"(.*?)"', str(IDs), re.S)
return title,shop,v_sale,v_price,item_loc,ids
def get_more(ids):
while True:
if len(ids) == 0:
break
id = ids.pop()
try:
new_url = f'https://detail.tmall.com/item.htm?id={id}'
resp = requests.get(new_url, headers=Headers(), proxies=IP(),timeout=5)
n_data = resp.text
text = parsel.Selector(n_data)
d_list = text.css('div.attributes-list ul li::text').getall()
dit = {}
for lis in d_list[1:]:
a = lis.split(':')[0]
b = lis.split(':')[1].strip()
dit[a] = b
base_text.append(dit)
print('Processing page{}Message'.format(len(base_text)))
time.sleep(1)
except:
pass
def make_file(title, shop, v_sale, v_price, item_loc, IDs, text):
for i in range(len(title)):
dit = {
'title': title[i],
'Sales shop': shop[i],
'Number of payers': v_sale[i],
'Current selling price': v_price[i],
'Store location': item_loc[i],
'Tmall products ID': IDs[i],
'title': text[i].get('title', None),
'author': text[i].get('author', None),
'price': text[i].get('price', None),
'Name of Publishing House': text[i].get('Name of Publishing House', None),
'ISBN number': text[i].get('ISBN number', None),
}
csv_writer.writerow(dit)
def thr(ids):
threads=[]
print('=====Start testing!')
for i in range(1, 11):
thread=threading.Thread(target=get_more, args=(ids,))
thread.start()
threads.append(thread)
time.sleep(0.2)
print('===== No.{} Thread 1 starts working!'.format(i))
for th in threads:
th.join()
print('completed!')
if __name__ == '__main__':
f = open('TaoBao\\'+'Python book.csv', 'a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['title', 'Sales shop', 'Number of payers', 'Current selling price', 'Store location', 'Tmall products ID',
'title', 'author', 'price', 'Name of Publishing House', 'ISBN number'])
csv_writer.writeheader()
base_text = []
for page in range(0,10):
print('=========Climbing to the third{}page==========\n'.format(int(page)+1))
num = int(page)*44
datas = get_data(num)
title, shop, v_sale, v_price, item_loc, IDs= [data for data in datas]
ids = list(IDs)
thr(ids)
print(title, shop, v_sale, v_price, item_loc, IDs, base_text)
make_file(title, shop, v_sale, v_price, item_loc, IDs, base_text)
Here's a little trick: when the crawler is running, it can switch to the Taobao page of the browser, and then pretend to visit Taobao. In this way, it is not easy to trigger anti crawling, and the verification can be completed manually in time. The timeout time should be set long enough (this trick really works!!! Pretending to visit Taobao while crawling ~ ahahaha...)
Finally, take a look at the result map
