python crawler, crawling with scratch
After learning the crawler for a period of time, I was ready to do a crawler exercise to consolidate it, so I chose the daily fund to crawl the data, and the problems and solutions encountered were recorded as follows.
Attach code address: https://github.com/Marmot01/python-scrapy-
Crawling idea
I Analysis website
-
Preferred to come Daily fund home page http://fund.eastmoney.com/jzzzl.html , analyze the content to crawl.
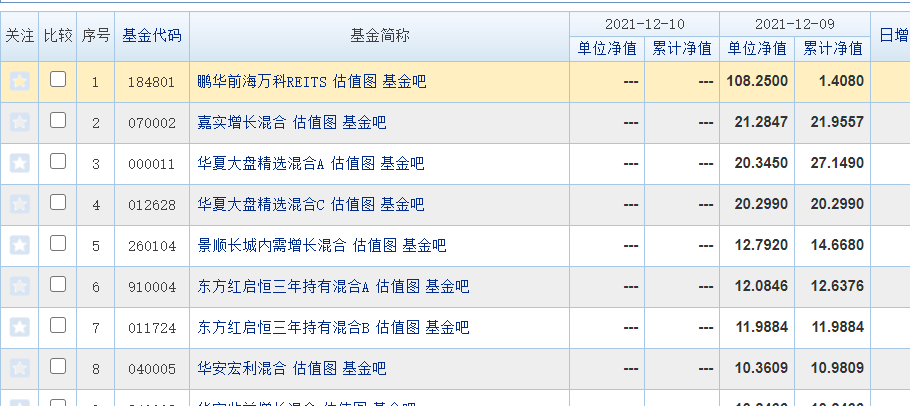
On the home page, we mainly get the fund code and fund abbreviation. The rest of the data can be analyzed by jumping to other pages through hyperlinks. Then F12 captures the packet and obtains the page response
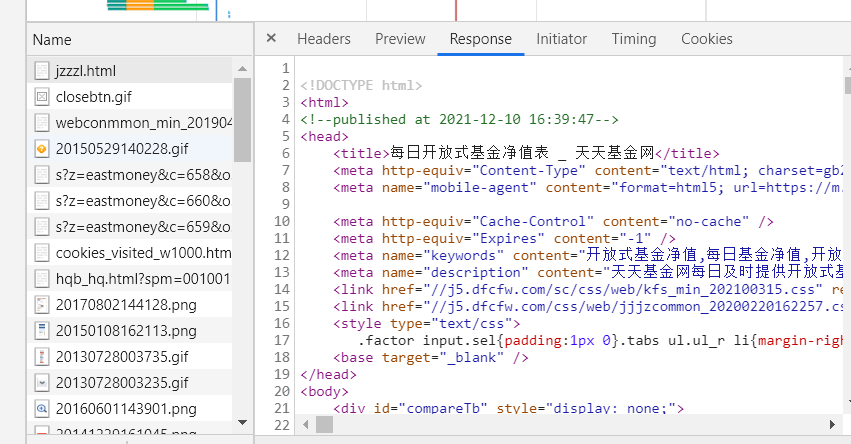
In the response, we can find that the response format is html. We can search the page content we need (fund code and fund abbreviation) through ctrl+f. all the findings can be found in the response. -
Analyze other content to crawl
Through the hyperlink in the fund abbreviation, we can jump to the home page of a fund
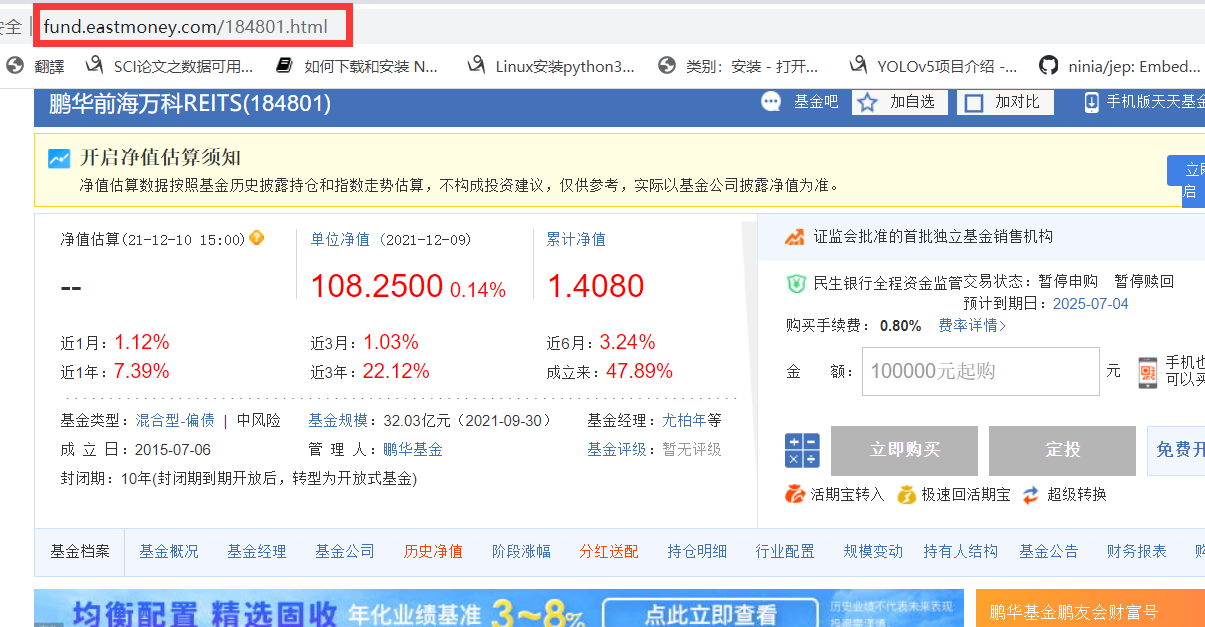
By analyzing the home page URL, it is easy to observe that the home page URL is composed of the home page address and the fund code (which is very important for subsequent crawling). On this page, you can select the content you want to crawl according to your needs. Here I crawl the unit net value, recent rise and fall, fund managers, etc.
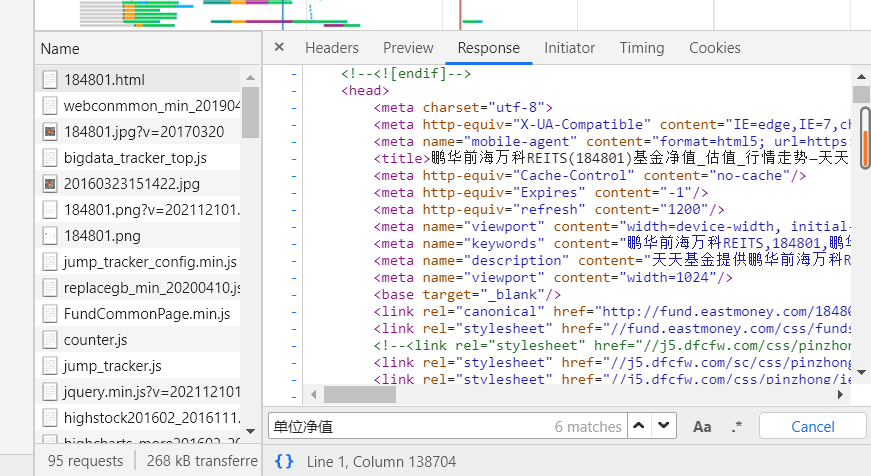
It is found that the response of this page is also html, and the content to be crawled can also be found in the response. -
Crawl past unit net worth
Here, I also want to get the past unit net value data of the fund, so click the unit net value hyperlink to see that this website is also very easy to analyze. I won't say more here.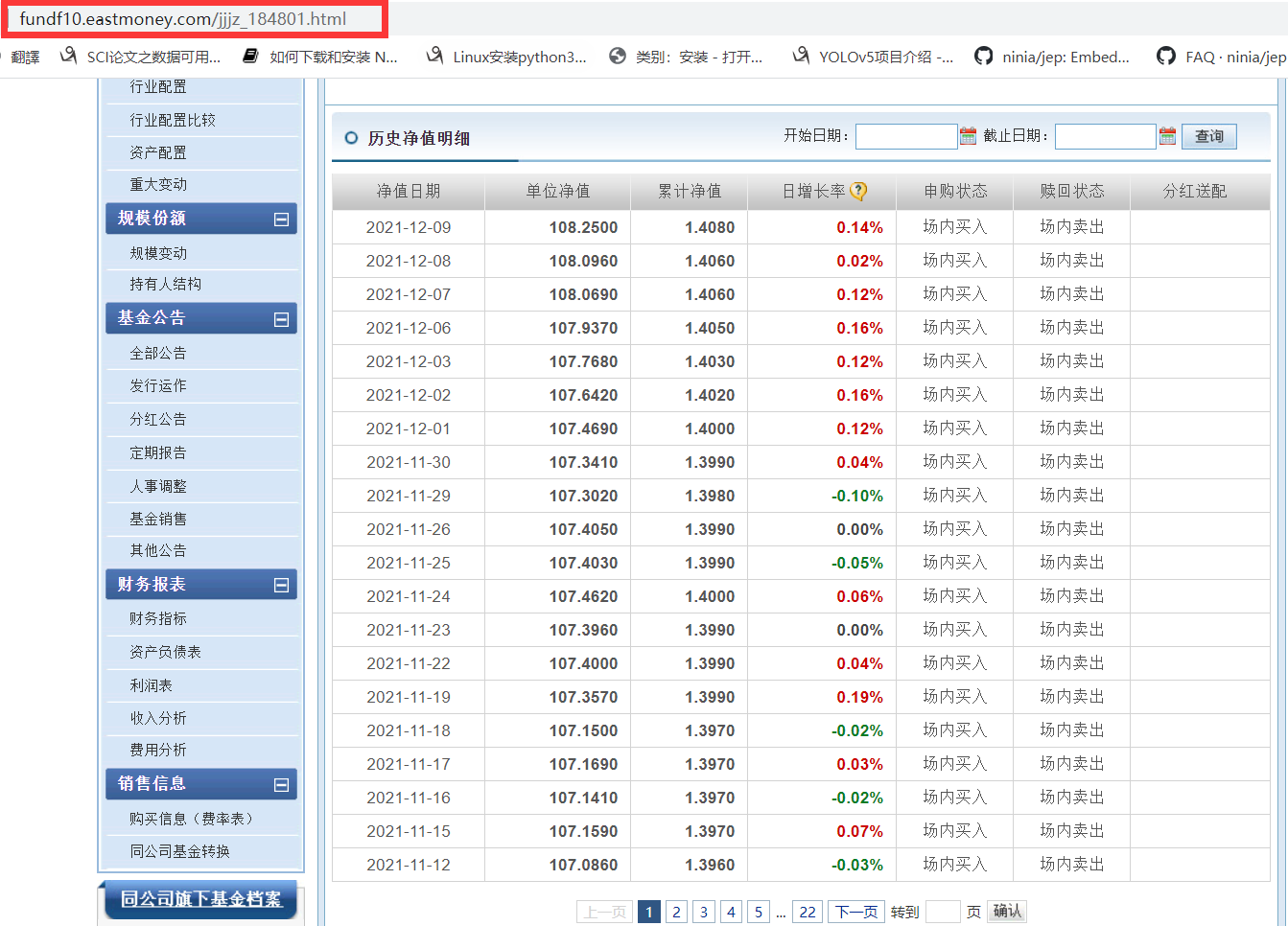
For crawling data analysis, it should be noted that although the response of this page is html, through search, we can find that only the unit net value of the current date will be displayed in this response, and the historical data we want will not appear.
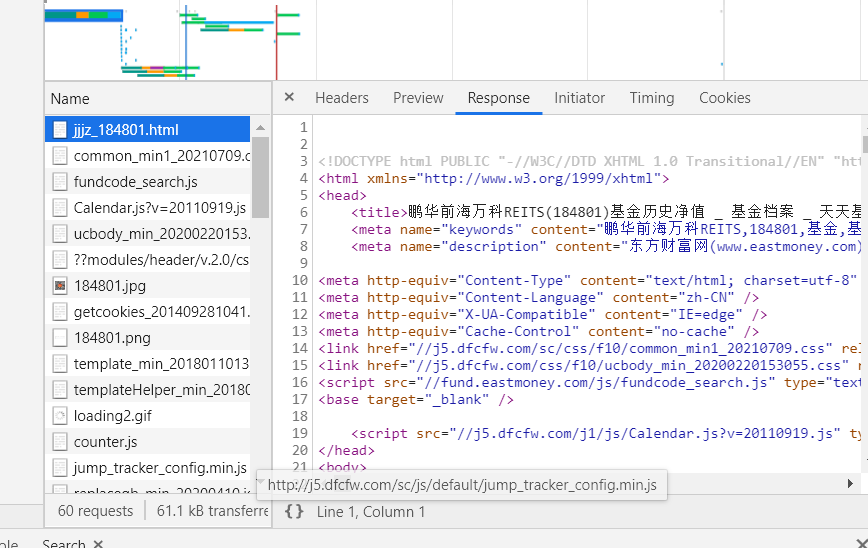
Here, I guess that the historical data should not be in this package, but in other packages, so click the next page to capture the package again. I found that this package will be sent every time I click the next page
After analyzing the package, we find that the response is in jQuery format (different from the previous html), and the historical data we want is also in it.
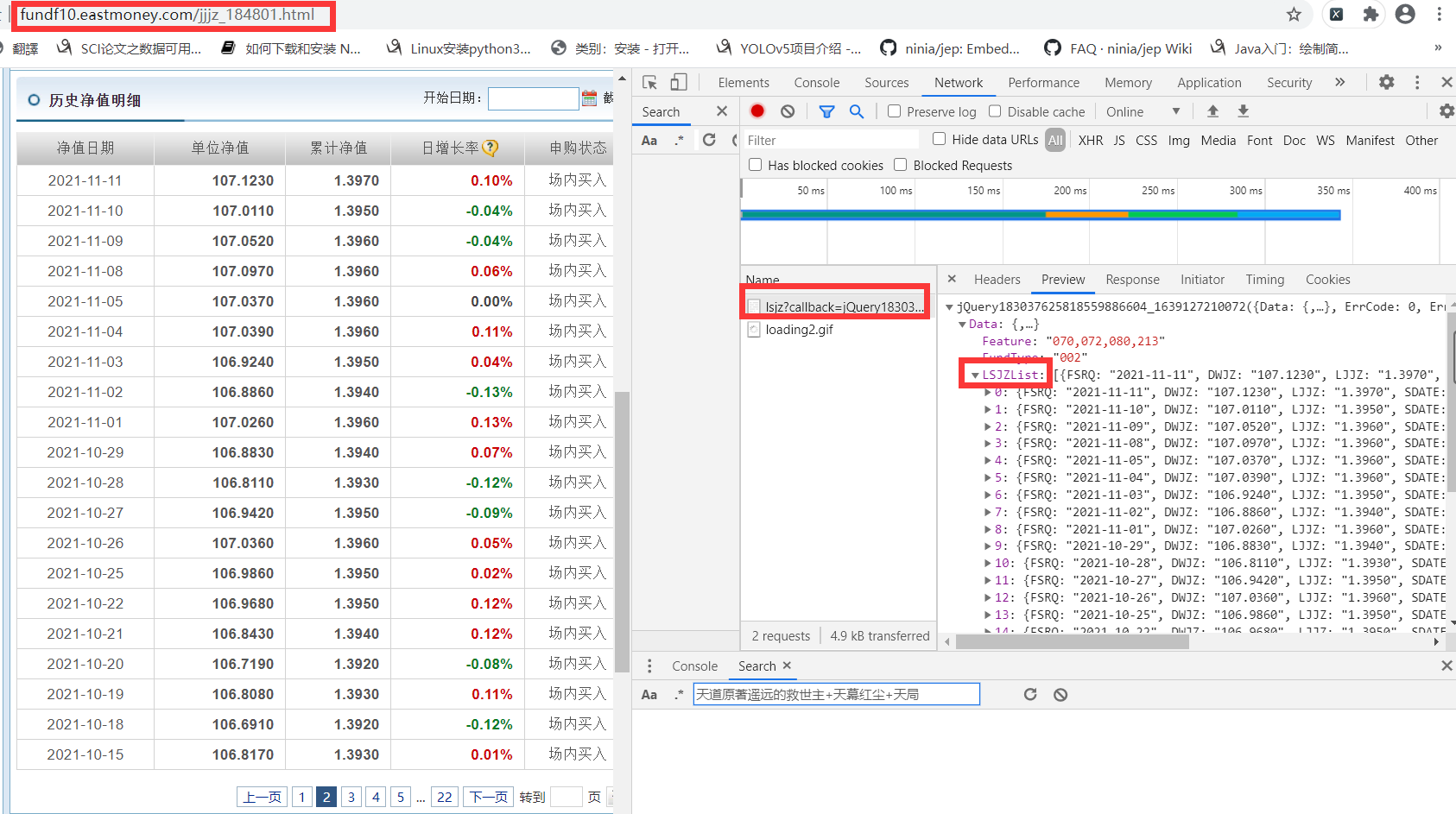
However, there is a problem here, that is, when you click the next page, the website address is actually unchanged, which causes great trouble for turning the page. However, don't worry. We continue to analyze the header of the package and find that the request address of the package is not the web address of the page, as shown in the figure.
We copied the address in the Request URL and opened a new page for access. We found that the content of the response is as follows, in JQuery format. However, it is obvious that the content is not what we want. I guess it should be the page's anti pickpocketing of the request address.
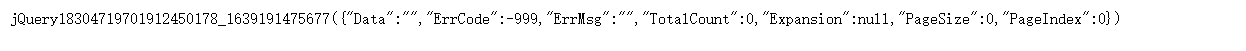 After several attempts, it is found that the address in the Request URL cannot be accessed directly, and special processing needs to be done for the request. That is, when initiating a request for this URL, the request header should tell the browser that it jumps from that URL, that is, it cannot access this URL directly, and it needs to jump with the help of another URL, Otherwise, the server will recognize it as crawler behavior and return wrong data. This intermediate URL is generally the Referer in Headers, as shown in the figure below.
After several attempts, it is found that the address in the Request URL cannot be accessed directly, and special processing needs to be done for the request. That is, when initiating a request for this URL, the request header should tell the browser that it jumps from that URL, that is, it cannot access this URL directly, and it needs to jump with the help of another URL, Otherwise, the server will recognize it as crawler behavior and return wrong data. This intermediate URL is generally the Referer in Headers, as shown in the figure below.
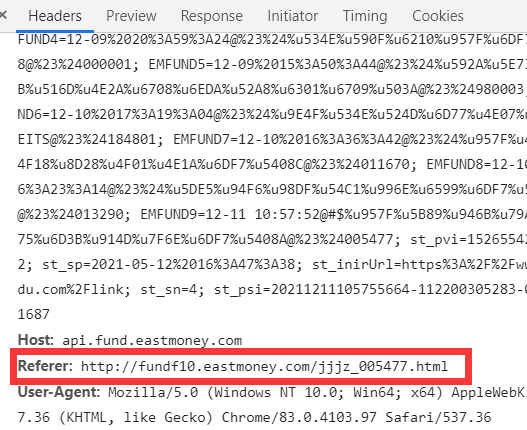
In other words, to access the address in the Request URL, we need to tell the browser that we came from the address in the Referer (that is, the address of the current page). After finding out, I wrote a test code to see what he will return. The code is as follows:
import requests
import json
headers = {
'Referer': 'http://fundf10.eastmoney.com/jjjz_000001.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
# kw = {'fundCode': '000001',
# 'pageIndex': '2',
# 'pageSize': '20',}
kw = {'fundCode': '000001',
'pageIndex': '1',
'pageSize': '20'
}
url = 'http://api.fund.eastmoney.com/f10/lsjz'
res=requests.get(url=url,headers=headers,params=kw)
print(res.content.decode())
data_dict = json.loads(res.content.decode())
print(len(data_dict['Data']['LSJZList']))
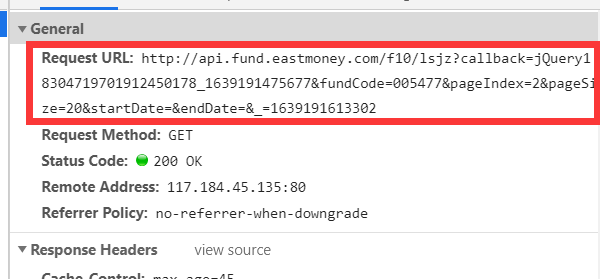
It should be noted that we have simplified the address of the Request URL here,
Original url:
http://api.fund.eastmoney.com/f10/lsjz?callback=jQuery18304719701912450178_1639191475677&fundCode=005477&pageIndex=2&pageSize=20&startDate=&endDate=&_=1639191613302a
Simplified:
http://api.fund.eastmoney.com/f10/lsjz?fundCode=005477&pageIndex=2&pageSize=20
callback=jQuery means that the data format after the response is jQuery. If you remove it, the data format after the response will become json. It is easy to see that the following string is related to time. Removing it will not affect the final response content.
Finally, the rest is easy to judge. One is the fund code, the other is the current page, and the other is the amount of data displayed on each page. With these, it is much easier to turn the page.
However, every time I change the pageIndex to turn the page, I feel a little troublesome, so I try to change the pageSize to obtain all the data in one page. I didn't expect it to be true. In this way, I can specify the size of the pageSize to obtain the data without turning the page and sending requests many times, which is much more convenient.
Second, write code
After analyzing the web pages to be crawled, you can crawl them with scratch. The construction of the scratch framework is not described in detail here. You can search the Internet. Here is the idea of writing code
- Determine what to crawl
Determine the content to be crawled in items. I have a lot of content to climb. I won't list them one by one here. Go directly to the code
import scrapy
class TtfundItem(scrapy.Item):
# define the fields for your item here like:
#Fund code
fund_code = scrapy.Field()
#Fund abbreviation
fund_name = scrapy.Field()
#Fund link
fund_link = scrapy.Field()
#Current net unit value
fund_current_value = scrapy.Field()
#current date
fund_current_date = scrapy.Field()
#Accumulated Net
fund_total_value = scrapy.Field()
#Rise and fall in recent January
one_month_rate = scrapy.Field()
#Rise and fall in recent March
three_month_rate = scrapy.Field()
#Rise and fall in recent June
six_month_rate = scrapy.Field()
#Rise and fall in recent year
one_year_rate = scrapy.Field()
#Rise and fall in recent three years
three_year_rate = scrapy.Field()
#Rise and fall since its establishment
total_rate = scrapy.Field()
#Establishment time
fund_start_time = scrapy.Field()
#fund manager
fund_manager = scrapy.Field()
#Fund size
fund_size = scrapy.Field()
#Fund type
fund_type = scrapy.Field()
# Fund risk
fund_risk = scrapy.Field()
#Fund rating
fund_rating = scrapy.Field()
#Historical net worth
history_value = scrapy.Field()
- Fill in crawler method
In the crawler class, first fill in the starting url of the crawler. Note here that we just started to analyze Daily fund website home page , if we want to page flip, we will find that its page address is also unchanged, which is similar to the previous analysis of crawling the unit net value. When we align the page to grab packets, we will find that its request is the following address: http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?t=1&lx=1&letter=&gsid=&text=&sort=zdf ,desc&page=2,200&dt=1639200673765&atfc=&onlySale=0
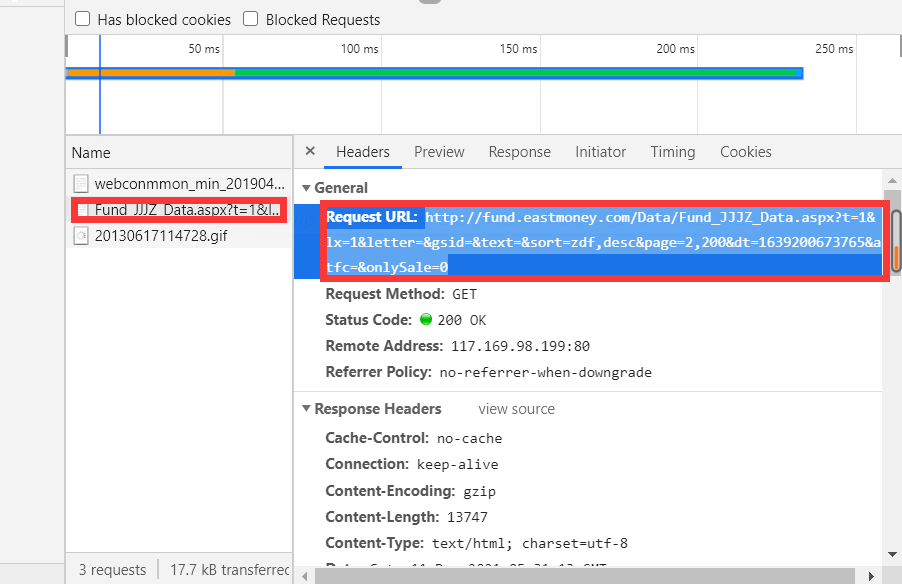
However, unlike crawling historical net worth data, this website can be accessed directly. The contents of the visit are as follows:

Check the response data format and find that it is similar to js format, so you need to parse the data by parsing js.
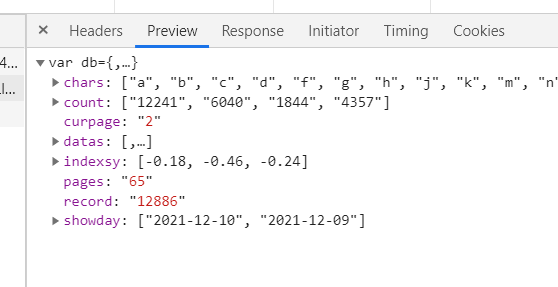
Similar to before, we can also simplify the initial url, and then obtain the amount of data we want by changing the amount of data on each page
The simplified url is: http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?&page=1 ,100
Page = 1100 means to crawl the first page, with 100 data per page. Of course, you can modify it as needed.
The crawl code is attached below
import scrapy
from TTFund.items import TtfundItem
import json
import execjs
class TtfundSpider(scrapy.Spider):
name = 'ttfund'#The name of the reptile
allowed_domains = ['eastmoney.com']
#start_urls = ['http://fund.eastmoney.com/jzzzl.html']
start_urls = ['http://fund. eastmoney. com/Data/Fund_ JJJZ_ Data. aspx?& Page = 1100 ']# you can select how much data to crawl by setting the last number
def parse(self, response):
print(response.request.headers)
data = response.body.decode('utf-8')
#The returned data format is js format
jsContent = execjs.compile(data)
data_dict = jsContent.eval('db')
datas = data_dict['datas']
for data in datas:
temp = {}
temp['fund_code'] = data[0]
temp['fund_name'] = data[1]
temp['fund_link'] = "http://fund.eastmoney.com/"+data[0]+".html"
detail_link = temp['fund_link']
#print(detail_link)
# nodelists = response.xpath('//*[@id="oTable"]/tbody/tr')
# for node in nodelists:
# temp = {}
# temp['fund_code'] = node.xpath('./td[4]/text()').extract_first()
# temp['fund_name'] = node.xpath('./td[5]/nobr/a[1]/text()').extract_first()
# temp['fund_link'] = response.urljoin(node.xpath('./td[5]/nobr/a[1]/@href').extract_first())
# detail_link = temp['fund_link']
#Simulate click link
yield scrapy.Request(
url=detail_link,
meta={'temp':temp},
callback=self.parse_detail,
)
def parse_detail(self,response):
temp = response.meta['temp']
temp['fund_current_value'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dd[1]/span[1]/text()').extract_first()
hisetory_link = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dt/p/span/span/a/@href').extract_first()
temp['fund_current_date'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dt/p/text()').extract_first().strip(')')
temp['fund_total_value'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[3]/dd[1]/span/text()').extract_first()
temp['one_month_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[1]/dd[2]/span[2]/text()').extract_first()
temp['three_month_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dd[2]/span[2]/text()').extract_first()
temp['six_month_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[3]/dd[2]/span[2]/text()').extract_first()
temp['one_year_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[1]/dd[3]/span[2]/text()').extract_first()
temp['three_year_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dd[3]/span[2]/text()').extract_first()
temp['total_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[3]/dd[3]/span[2]/text()').extract_first()
#To remove tbody from xpath
temp['fund_start_time'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[2]/td[1]/text()').extract_first().strip(': ')
temp['fund_manager'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[1]/td[3]/a/text()').extract_first()
temp['fund_size'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[1]/td[2]/text()').extract_first().strip(': ')
temp['fund_risk'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[1]/td[1]/text()[2]').extract_first().strip('\xa0\xa0|\xa0\xa0')
temp['fund_type'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[1]/td[1]/a/text()').extract_first()
temp['fund_rating'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[2]/td[3]/div/text()').extract_first()
#print(temp)
headers = {
'Referer': hisetory_link,
}
kw = {'fundCode': temp['fund_code'],
'pageIndex': 1,
'pageSize': 5000,}#You can set the amount of data you want to crawl. If the set data is more than the total data of the website, only the total data of the website will be crawled
yield scrapy.Request(
url="http://api.fund.eastmoney.com/f10/lsjz?fundCode={}&pageIndex={}&pageSize={}".format(temp['fund_code'],1,5000),
headers=headers,
meta={'temp':temp},
callback=self.parse_history
)
def parse_history(self,response):
temp = response.meta['temp']
history_value = []
dict_data = json.loads(response.body.decode())
for data in dict_data['Data']['LSJZList']:
tp = {}
tp['Net worth date'] = data['FSRQ']
tp['Average NAV'] = data['DWJZ']
tp['Accumulated Net '] = data['LJJZ']
history_value.append(tp)
items = TtfundItem()
items['fund_code'] = temp['fund_code']
items['fund_name'] = temp['fund_name']
items['fund_link'] = temp['fund_link']
items['fund_current_value'] = temp['fund_current_value']
items['fund_current_date'] = temp['fund_current_date']
items['fund_total_value'] = temp['fund_total_value']
items['one_month_rate'] = temp['one_month_rate']
items['three_month_rate'] = temp['three_month_rate']
items['six_month_rate'] = temp['six_month_rate']
items['one_year_rate'] = temp['one_year_rate']
items['three_year_rate'] = temp['three_year_rate']
items['total_rate'] = temp['total_rate']
items['fund_start_time'] = temp['fund_start_time']
items['fund_manager'] = temp['fund_manager']
items['fund_size'] = temp['fund_size']
items['fund_risk'] = temp['fund_risk']
items['fund_type'] = temp['fund_type']
items['fund_rating'] = temp['fund_rating']
items['history_value'] =history_value
yield items
Here, I use xpath to extract data. xpath statements can be written according to the crawling content, or you can directly select the elements to be crawled. Copy directly to xpath at the corresponding position of elements. However, some minor modifications need to be made during copy. Here, you need to have a certain understanding of xpath. I don't want to describe more. You can check it on the Internet. It's not difficult. In particular, it should be noted that when crawling fund managers and other contents, the copy xpath contains tbody, which needs to be removed, otherwise it will not be able to crawl data. After checking, it is because the page source code does not contain the option of tbody, but there is tbody in the browser, so the copy xpath needs to remove tbody.
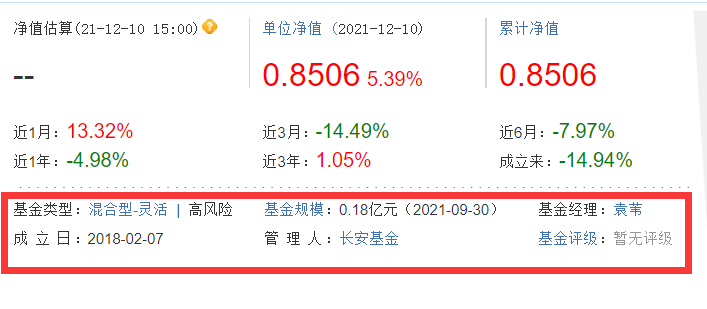
III. save data
scrapy The crawled data will eventually pass yield Return data to pipelines Pipes, so we need to pipelines.py The file defines the location we want to save. Here I save it in mongodb In the database.
from itemadapter import ItemAdapter
from pymongo import MongoClient
class TtfundPipeline:
def open_spider(self, spider):
if spider.name =="ttfund":
#Stored in mongodb database
self.client = MongoClient('127.0.0.1',27017)
self.db = self.client['TTFund']
self.col = self.db['ttfund']
def process_item(self, item, spider):
if spider.name == "ttfund":
data = dict(item)
self.col.insert(data)
return item
def close_spider(self,spider):
if spider.name == "ttfund":
self.client.close()
It should be noted that after the code is written, we also need to set Py, otherwise the pipeline cannot be used. At the same time, you can also set user in setting_ Agent (you can also use random agents).
Here is setting Py code
# Scrapy settings for TTFund project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from fake_useragent import UserAgent
BOT_NAME = 'TTFund'
SPIDER_MODULES = ['TTFund.spiders']
NEWSPIDER_MODULE = 'TTFund.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
#Random request header (ten randomly generated)
#USER_AGENT_LIST = [UserAgent().random for i in range(10)]
USER_AGENT_LIST = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (X11; NetBSD) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36"]
# Obey robots.txt rules
#ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'TTFund.middlewares.TtfundSpiderMiddleware': 543,
#
# }
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
#'TTFund.middlewares.TtfundDownloaderMiddleware': 543,
'TTFund.middlewares.RandomUserAgent': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'TTFund.pipelines.TtfundPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
Four results
The next step is to crawl the data. In fact, it's quite fast. Store the crawled data into the database mongodb In the database, the following is the final result
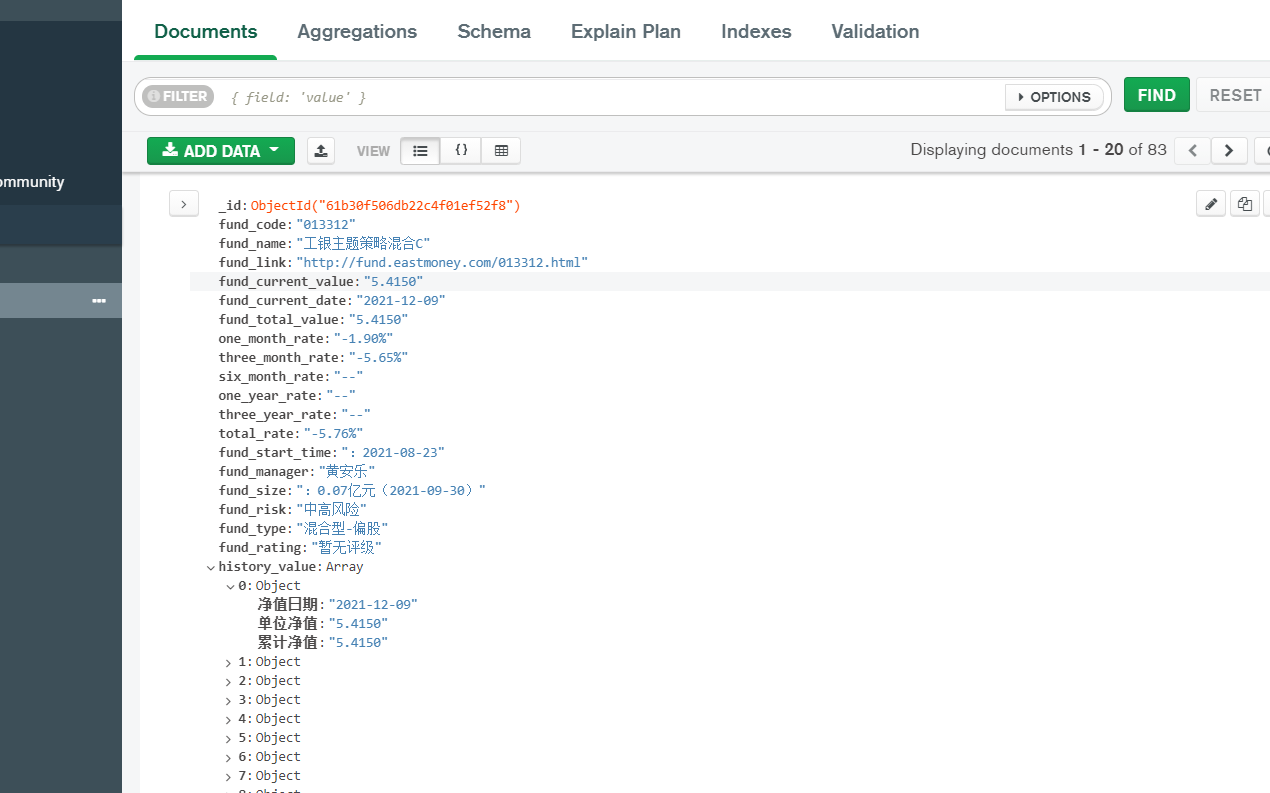
You can see the data. It's done!
Finally, attach the code address: https://github.com/Marmot01/python-scrapy-
V. summary
1. Generally speaking, this website is relatively easy to climb, and there is not much cheating
2. The main difficulty is to analyze page turning and obtain response data. It really took a lot of time here. Each website is different, but the general idea of crawling can be used for reference
3. The results of the last crawl. In fact, I set up to crawl 100 fund data, but I don't know why there were only 83 results (I guess some skipped due to network reasons).
4. About random request header_ Agent and random agent ip, you can actually try to do it here, but I turn the page of the starting url at one time and will not send multiple requests, so random User_Agent is not very useful.