PYTHON reptile diary 01
Record your learning reptile diary
Choose python as the programming language
1. Environmental preparation
python3.6+
mysql
pycharm
2. Ideas
The goal is to climb the top 100 of the cat's eye
1. Analyze the law of url
https://maoyan.com/board/4?offset=10 Find their URLs and use the url parameter offset as the offset parameter of the page
Later, we can automatically crawl all pages through loop traversal
2. Crawl the corresponding HTML according to the url
Crawling html may trigger the anti crawling mechanism, which can be avoided by configuring headers (solved, but not completely solved)
3. Parsing html pages
By introducing the parsing package of python, html is parsed into a tree, and then parsed according to the tree structure. There are many parsing methods
You can use the api provided in the package or regular, and it is better to use it flexibly in combination
4. Save data
Encapsulate the data after parsing the html page and save it to mysql
5. Display the data in the visual interface
3. Start drying
1. Create a new python project
Select your favorite directory and create a new project
2. Introduction package
from time import sleep #Delay access to avoid ip blocking caused by too frequent access import pymysql #Connect to mysql and store the data from bs4 import BeautifulSoup #Parsing html import re # regular expression import urllib.request, urllib.error # Get web page data by customizing url
3. Function test
urllib.request page
import urllib.request
url = 'https://maoyan.com/board/4?offset = '# request url
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
pymysql connection mysql
import pymysql
#Open database connection
conn = pymysql.connect(
host='xxx.xx.xx.xx',# host
port = 3306, # Default port, modified according to actual conditions
user='root',# user name
passwd='123456', # password
db ='luke_db', # DB name
)
cur = conn.cursor()
print(conn,cur)
cur.close()
conn.close()

It can be output successfully, indicating that it has been successfully connected with mysql
mysql can be built locally or remotely. Here is a mysql I built in linux and realized through remote connection
bs4.BeautifulSoup parses html pages
import urllib.request
from bs4 import BeautifulSoup
url = 'https://maoyan.com/board/4?offset = '# request url
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# print(response.read().decode('utf-8'))
html = response.read().decode('utf-8')
html_parser = BeautifulSoup(html, "html.parser") #Parse the html returned by the request and specify html Parser parser
html_a = html_parser.find_all("a") #Extract a tag
print(html_a)
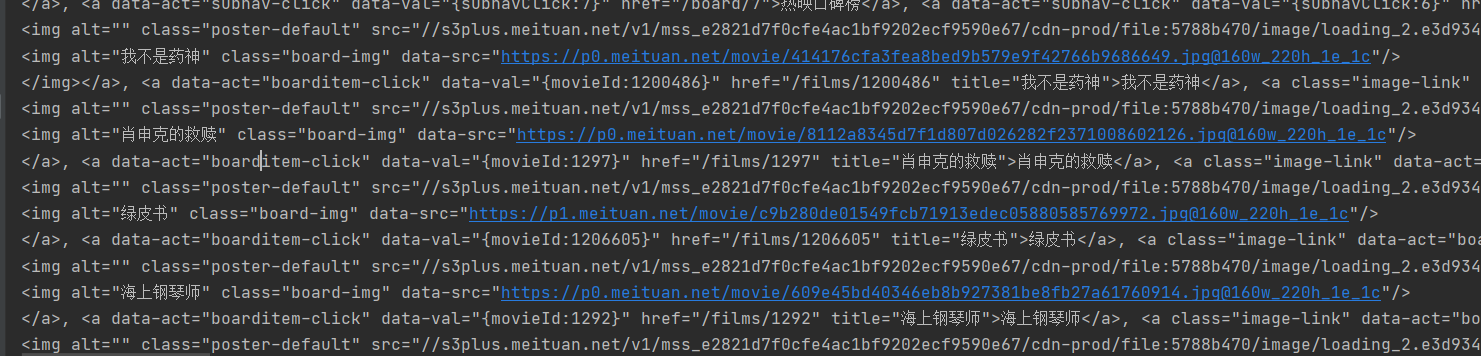
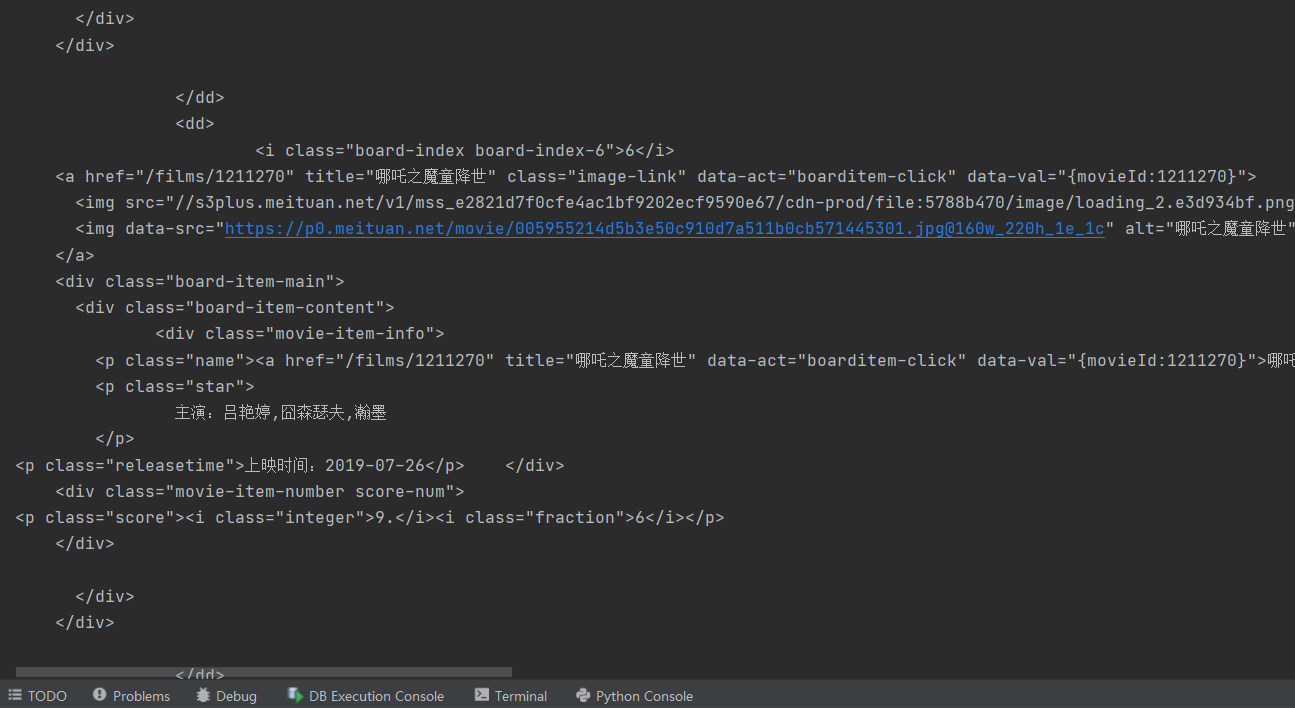
You can see that the output results are all a tags
Some common methods of recording beautiful soup
#1.Tag tag and its contents; Get the first thing it finds # print(bs.title.string) # # print(type(bs.title.string)) #2. Contents in navigablestring tag (string) #print(bs.a.attrs) #print(type(bs)) #3. Beautiful soup refers to the whole document #print(bs.name) #print(bs) # print(bs.a.string) # print(type(bs.a.string)) #4.Comment is a special NavigableString, and the output content does not contain comment symbols #------------------------------- #Document traversal #print(bs.head.contents) #print(bs.head.contents[1])
Regular expressions are often used to parse html, and re package is introduced
import urllib.request
from bs4 import BeautifulSoup
import re
url = 'https://maoyan.com/board/4?offset = '# request url
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# print(response.read().decode('utf-8'))
html = response.read().decode('utf-8')
html_parser = BeautifulSoup(html, "html.parser")
html_a = html_parser.find_all("a") #Remove the A label
html_a=str(html_a)#To string
find_maoyan_link = re.compile(r'.*?href="(.*?)"')#Regular rules
html_href = re.findall(find_maoyan_link,html_a)#Regular matching
for item in html_href :#Traversal printing
print(item)
# print(html_href)
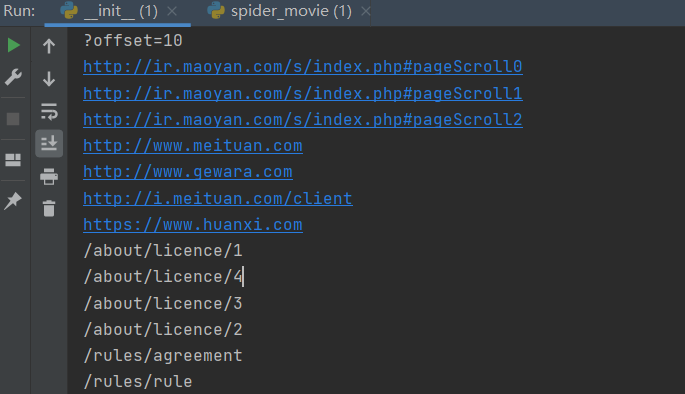
General function has been tested ok
4. Complete code
import random
from time import sleep
import pymysql
from bs4 import BeautifulSoup
import re # regular expression
import urllib.request, urllib.error # Get web page data by customizing url
def main():
parser_url_save()
def parser_url_save():
print("doing parser url ....")
# cat eye https://maoyan.com/board/4?offset=10
# Watercress https://movie.douban.com/top250?start=25
urls = ['https://maoyan.com/board/4?offset=','https://movie.douban.com/top250?start=']
for url in urls:
if url.find('https://maoyan.com') !=-1 :
datalist = parser_html(url)
# datalist = getData_maoyan(html)
# print(datalist)
saveData_maoyan(datalist)
else :
# parser_DOUBAN(url)
print("parser douban ...")
# Regular list
# Cat's eye title
find_maoyan_title = re.compile(r'.*?title="(.*?)"')
# Cat's eye link
find_maoyan_link = re.compile(r'.*?href="(.*?)"')
# Cat's eye picture
find_maoyan_pic = re.compile(r'.*?<img.*?data-src="(.*?)"')
# Cat's eye score
find_maoyan_score1 = re.compile(r'<p class="score"><i class="integer">(.*?)<')
find_maoyan_score2 = re.compile(r'</i><i class="fraction">(.*?)<')
# to star
find_maoyan_star = re.compile(r'.*to star:(.*)')
# Release time
find_maoyan_date = re.compile(r'Release time:(.*)<')
def parser_html (url):
cookie = '###'
# agent=random.choice(user_agent)
agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
data_maoyan_list=[]
for i in range (0,10) :
sleep(3)
url_tmp = url+str(i*10)
headers = {
"User-Agent":agent
,"Cookie":cookie
}
req = urllib.request.Request(url_tmp, headers=headers)
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
data_maoyan_list = getData_maoyan(html,data_maoyan_list)
return data_maoyan_list
def getData_maoyan (html,data_maoyan_list):
html_parser = BeautifulSoup(html, "html.parser")
base_url = 'https://maoyan.com/'
item_list = html_parser.find_all('dd')
for item in item_list:
sleep(1) # Delayed access
# Data set of a single movie
data = []
item_a = str(item.a)
# Take title
title = re.findall(find_maoyan_title, item_a)[0]
# Take link
curr_url = base_url + str(re.findall(find_maoyan_link, item_a)[0])
# Take picture link
pic = re.findall(find_maoyan_pic, item_a)[0]
# score
item_p = item.select("p[class='score']")
# if i * 10 == 20:
# print(item_p)
score = "0.0" # There is a reset 0.0 without a score
if len(re.findall(find_maoyan_score1, str(item_p))) > 0:
score = float(str(re.findall(find_maoyan_score1, str(item_p))[0]) + str(
re.findall(find_maoyan_score2, str(item_p))[0]))
# to star
# '<p class="star">'
item_star = item.select("p[class='star']")
# print(str(item_star))
star = re.findall(find_maoyan_star, str(item_star))[0]
# Release time < p class = "releasetime" >
item_releasetime = item.select("p[class='releasetime']")
releasetime = re.findall(find_maoyan_date, str(item_releasetime))[0]
# Add to dataset, title,curr_url,pic,score,star,releasetime
data.append(title)
data.append(curr_url)
data.append(pic)
data.append(score)
data.append(star)
data.append(releasetime)
data_maoyan_list.append(data)
return data_maoyan_list
def saveData_maoyan(data_list):
conn = pymysql.connect(
host='xxx.xx.xx.xx',# host
port = 80, # Default port, modified according to actual conditions
user='root',# user name
passwd='123456', # password
db ='luke_db', # DB name
)
cur=conn.cursor()
print(conn)
# Data list obtained
for id in range(0,len(data_list)):
# Get field
ind_id = str(id);
title = '"'+str(data_list[id][0])+'"' # title
link = '"'+str(data_list[id][1])+'"' # connect
pic_link = '"'+str(data_list[id][2])+'"' # Picture connection
score = str(data_list[id][3]) # score
actor = '"'+str(data_list[id][4])+'"' # to star
pub_date = '"'+str(data_list[id][5])+'"' # Release time
arr=[ind_id,title,link,pic_link,score,actor,pub_date]
sql='''
insert into luke_db.t_movie_top100_maoyan (xh,m_title,m_link,m_pic,m_score,m_actor,m_pubdate)
values(%s)'''%",".join(arr)
print(sql)
print(cur.execute(sql))
conn.commit() # insert data
cur.close()
conn.close()
if __name__== '__main__':
main()
Such a simple crawler is realized
Check the database
You can see that the data has been imported into the database
Later, you can build a visual structure according to the data of the database