Preface
Text and pictures of the text come from the network for learning and communication purposes only. They do not have any commercial use. Copyright is owned by the original author. If you have any questions, please contact us in time for processing.
Author: C vs. Python
PS: If you need Python learning materials for your child, click on the link below to get them
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
For each worker, there are always several job changes to go through. How can I find the job I want online?How do I prepare in advance for the job interview I want?Today, let's grab the recruitment information of Zhilian to help you change your job successfully!
-
Running Platform: Windows
-
Python version: Python 3.6
-
IDE: Sublime Text
-
Other Tools: Chrome Browser
1. Web page analysis
1.1 Analysis Request Address
Take the python Engineer in Haidian District of Beijing as an example to do web page analysis.Open the front page of the recruitment for Zhilian, select the Beijing area, type "python engineer" in the search box, and click "search job":

Next, jump to the search results page, press F12 to open the developer tools, and then select Haidian in the Hot Areas bar. Let's take a look at the address bar: 
As you can see from the second half of the address bar, search result.ashx?Jl=Beijing&kw=python engineer&sm=0&isfilter=1&p=1&re=2005, we have to construct the address ourselves.Next, you'll analyze the developer tools and follow the steps shown in the figure to find the data we need: Request Headers and Query String Parameters: 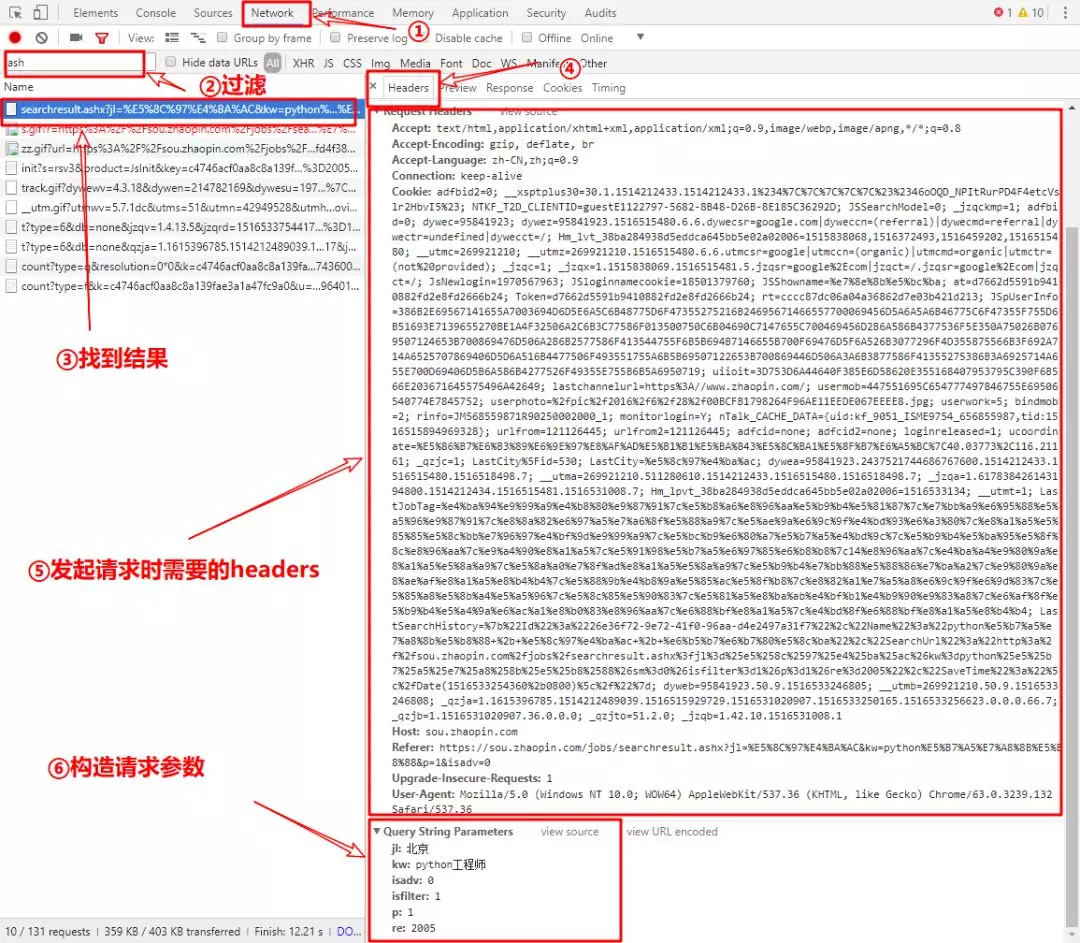 Construct the request address:
Construct the request address:
1 paras = { 2 'jl': 'Beijing', # Search City 3 'kw': 'python Engineer', # Search keywords 4 'isadv': 0, # Whether to turn on more detailed search options 5 'isfilter': 1, # Whether to filter results 6 'p': 1, # The number of pages 7 're': 2005 # region Abbreviation for, Region, 2005 for Haidian 8 } 9 10 url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras)
Request Header:
1 headers = { 2 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 3 'Host': 'sou.zhaopin.com', 4 'Referer': 'https://www.zhaopin.com/', 5 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 6 'Accept-Encoding': 'gzip, deflate, br', 7 'Accept-Language': 'zh-CN,zh;q=0.9' 8 }
1.2 Analyzing useful data
Next, we will analyze the useful data. From the search results, we need the following data: job name, company name, address of company details page, job monthly salary:
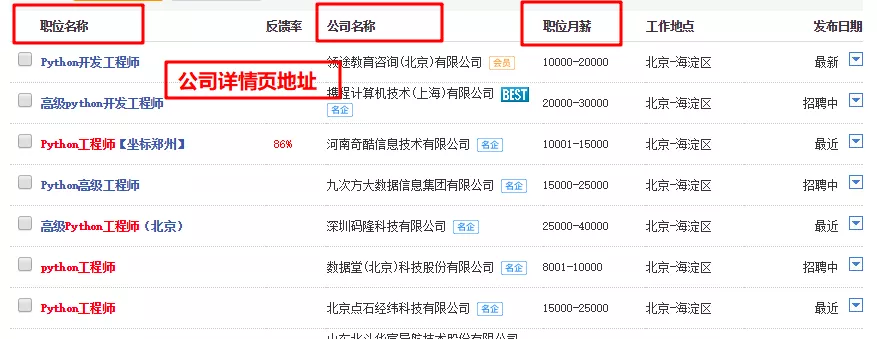
Find these items in the HTML file by locating the page elements, as shown in the following image:
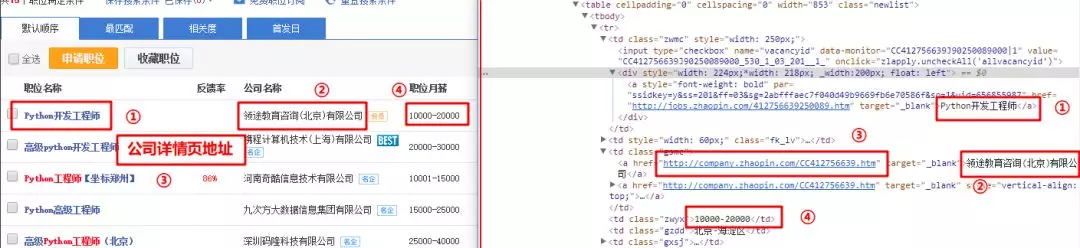
These four items are extracted using regular expressions:
# Regular expression parsing pattern = re.compile('<a style=.*? target="_blank">(.*?)</a>.*?' # Match position information '<td class="gsmc"><a href="(.*?)" target="_blank">(.*?)</a>.*?' # Match company web address and company name '<td class="zwyx">(.*?)</td>', re.S) # Match monthly salary # Match all eligible content items = re.findall(pattern, html)
Note: Some of the resolved job names have labels, as shown in the following figure:
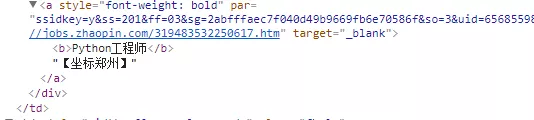
Then, after parsing, the data is processed to remove the tags, using the following code:
for item in items: job_name = item[0] job_name = job_name.replace('<b>', '') job_name = job_name.replace('</b>', '') yield { 'job': job_name, 'website': item[1], 'company': item[2], 'salary': item[3] }
2. Writing Files
The data we get is the same for each position and can be written to the database, but this paper chooses csv file, which is explained by Baidu Encyclopedia below:
Comma-Separated Values (CSV, sometimes referred to as character-separated values) are files that store tabular data (numbers and text) in plain text, since separator characters can also be non-commas.Plain text means that the file is a sequence of characters and does not contain data that must be interpreted like a binary number
python is convenient because it has built-in library functions for csv file operations:
import csv def write_csv_headers(path, headers): ''' //Write to Header ''' with open(path, 'a', encoding='gb18030', newline='') as f: f_csv = csv.DictWriter(f, headers) f_csv.writeheader() def write_csv_rows(path, headers, rows): ''' //Write line ''' with open(path, 'a', encoding='gb18030', newline='') as f: f_csv = csv.DictWriter(f, headers) f_csv.writerows(rows)
3. Progress display
In order to find the ideal job, we must filter more positions, so we must capture a large amount of data, dozens of pages, hundreds of pages or even thousands of pages, so we need to master the capture progress mind to be more realistic, so we need to add the progress bar display function.
This article chooses tqdm for progress display to see cool results (picture source network):
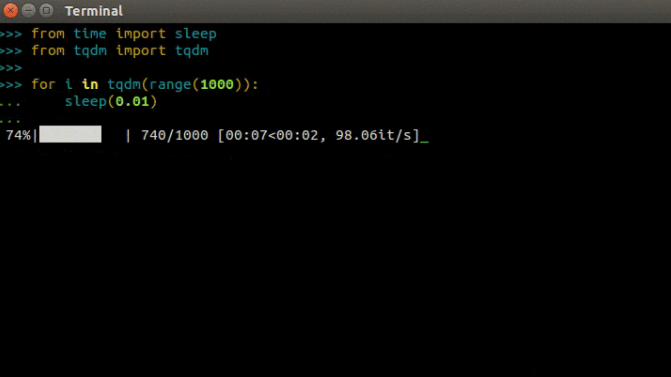
Perform the following commands to install:
pip install tqdm
Simple examples:
from tqdm import tqdm from time import sleep for i in tqdm(range(1000)): sleep(0.01)
4. Complete Code
The above is an analysis of all the functions, as follows is the complete code:
1 #-*- coding: utf-8 -*- 2 import re 3 import csv 4 import requests 5 from tqdm import tqdm 6 from urllib.parse import urlencode 7 from requests.exceptions import RequestException 8 9 def get_one_page(city, keyword, region, page): 10 ''' 11 Get Web Page html Content and Return 12 ''' 13 paras = { 14 'jl': city, # Search City 15 'kw': keyword, # Search keywords 16 'isadv': 0, # Whether to turn on more detailed search options 17 'isfilter': 1, # Whether to filter results 18 'p': page, # The number of pages 19 're': region # region Abbreviation for, Region, 2005 for Haidian 20 } 21 22 headers = { 23 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 24 'Host': 'sou.zhaopin.com', 25 'Referer': 'https://www.zhaopin.com/', 26 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 27 'Accept-Encoding': 'gzip, deflate, br', 28 'Accept-Language': 'zh-CN,zh;q=0.9' 29 } 30 31 url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras) 32 try: 33 # Get web content, return html data 34 response = requests.get(url, headers=headers) 35 # Determine success by status code 36 if response.status_code == 200: 37 return response.text 38 return None 39 except RequestException as e: 40 return None 41 42 def parse_one_page(html): 43 ''' 44 analysis HTML Code, extract useful information and return 45 ''' 46 # Regular expression parsing 47 pattern = re.compile('<a style=.*? target="_blank">(.*?)</a>.*?' # Match position information 48 '<td class="gsmc"><a href="(.*?)" target="_blank">(.*?)</a>.*?' # Match company web address and company name 49 '<td class="zwyx">(.*?)</td>', re.S) # Match monthly salary 50 51 # Match all eligible content 52 items = re.findall(pattern, html) 53 54 for item in items: 55 job_name = item[0] 56 job_name = job_name.replace('<b>', '') 57 job_name = job_name.replace('</b>', '') 58 yield { 59 'job': job_name, 60 'website': item[1], 61 'company': item[2], 62 'salary': item[3] 63 } 64 65 def write_csv_file(path, headers, rows): 66 ''' 67 Write headers and rows csv file 68 ''' 69 # join encoding Prevent Chinese Writing Errors 70 # newline Parameters prevent one more blank line per write 71 with open(path, 'a', encoding='gb18030', newline='') as f: 72 f_csv = csv.DictWriter(f, headers) 73 f_csv.writeheader() 74 f_csv.writerows(rows) 75 76 def write_csv_headers(path, headers): 77 ''' 78 Write to Header 79 ''' 80 with open(path, 'a', encoding='gb18030', newline='') as f: 81 f_csv = csv.DictWriter(f, headers) 82 f_csv.writeheader() 83 84 def write_csv_rows(path, headers, rows): 85 ''' 86 Write line 87 ''' 88 with open(path, 'a', encoding='gb18030', newline='') as f: 89 f_csv = csv.DictWriter(f, headers) 90 f_csv.writerows(rows) 91 92 def main(city, keyword, region, pages): 93 ''' 94 Principal function 95 ''' 96 filename = 'zl_' + city + '_' + keyword + '.csv' 97 headers = ['job', 'website', 'company', 'salary'] 98 write_csv_headers(filename, headers) 99 for i in tqdm(range(pages)): 100 ''' 101 Get all position information on this page and write csv file 102 ''' 103 jobs = [] 104 html = get_one_page(city, keyword, region, i) 105 items = parse_one_page(html) 106 for item in items: 107 jobs.append(item) 108 write_csv_rows(filename, headers, jobs) 109 110 if __name__ == '__main__': 111 main('Beijing', 'python Engineer', 2005, 10)
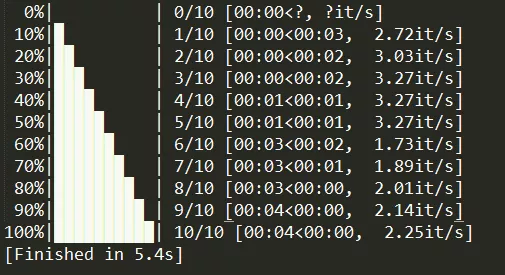
The above code executes as shown in the figure:
When the execution is completed, a file named: zl Beijing python engineer.csv will be generated under the py peer folder. The effect after opening is as follows: 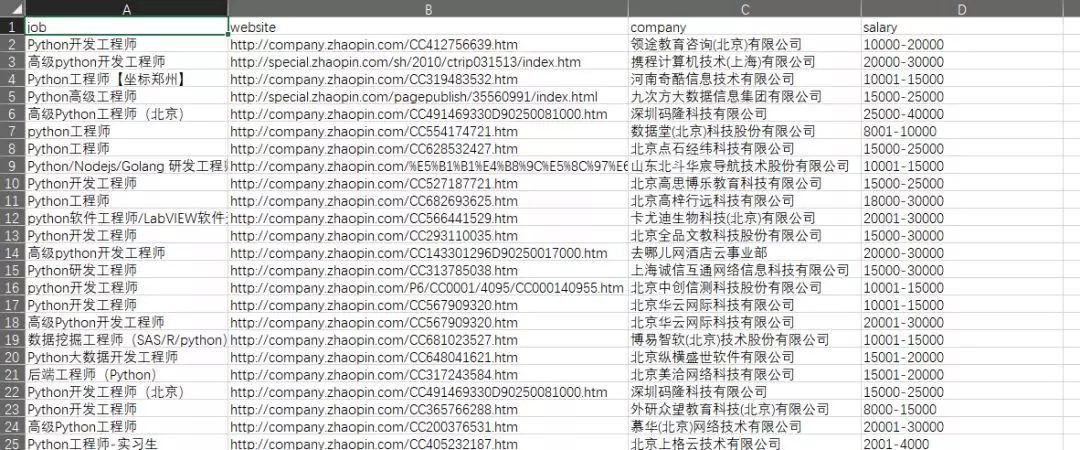 .
.