Song search element
Netease cloud music website is: https://music.163.com/
The idea is to enter a song name after entering, click the search button, and capture the search request through the developer debugging tool. The captured data information is as follows:
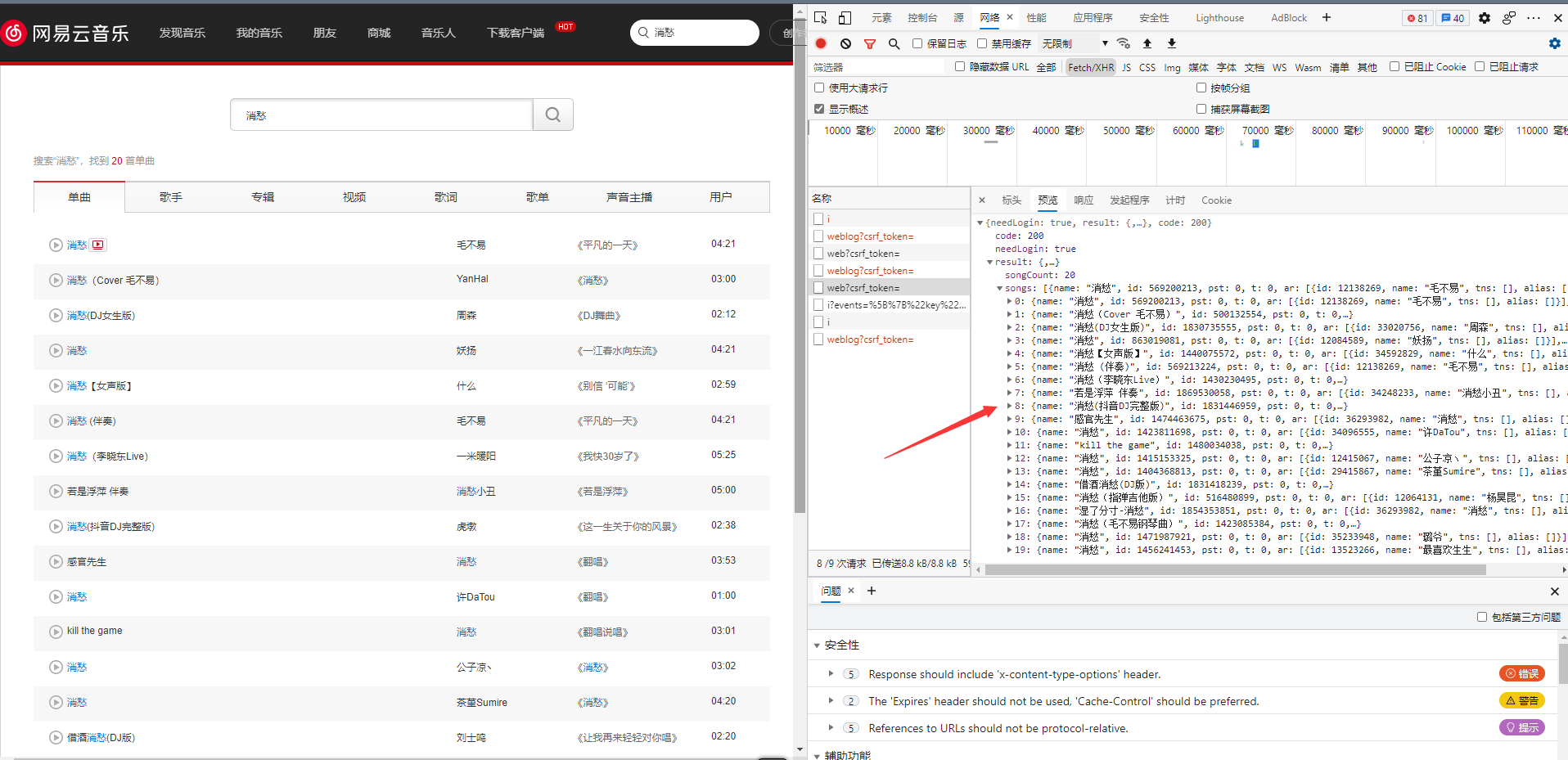
All song related information is in the result. Each a tag (hyperlink) carries a lot of information, including song name, id number, singer, etc. the most critical information needed here is its id number, because the song name author may be repeated, but the id is unique. Other information of the song can be obtained through the id.

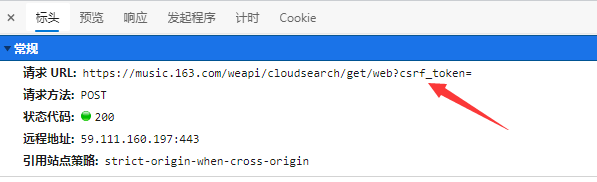
Then view the URL of the request, https://music.163.com/weapi/cloudsearch/get/web?csrf_token= , you can get the id of the song through this URL
How to search after obtaining the id? Take the first song as an example to enter the details page: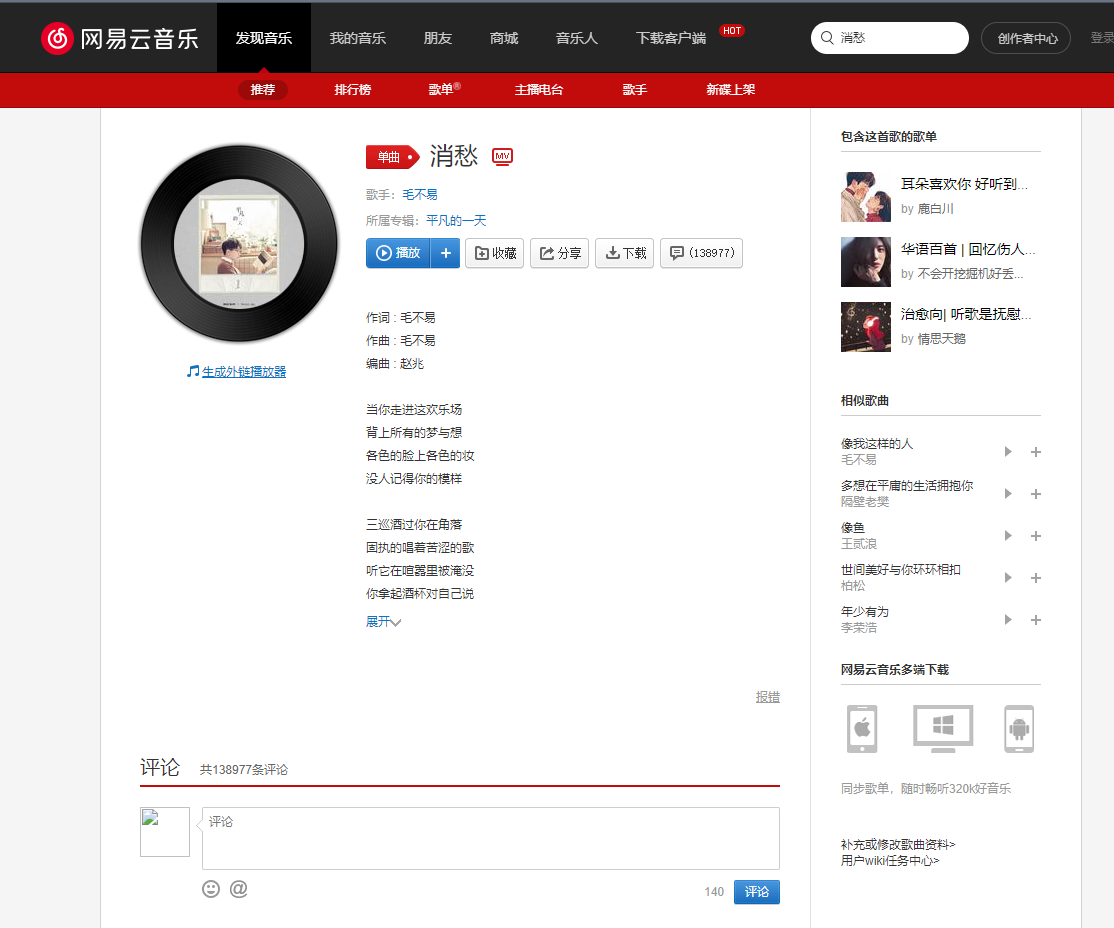
You only need to fill in the id number behind the web address and splice some strings

In this way, you can search the id of the song:
import requests
from Netease_cloud_comment_capture.Encrypt import Encrypted
class search():
'''Different from direct download of song list, 1.namely headers of referer
2.Encrypted text The content is different!
3.Searchable URL It's different
Enter the search content to get songs ID
'''
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Host': 'music.163.com',
'Referer': 'http://music.163.com/search/'}
self.main_url='http://music.163.com/'
self.session = requests.Session()
self.session.headers=self.headers
self.ep = Encrypted()
def search_song(self, search_content, search_type=1, limit=9):
"""
Search by music name
:params search_content: Music name
:params search_type: ignorance
:params limit: Number of returned results
return: Can get id Go in again. The song is specific url
"""
url = 'http://music.163.com/weapi/cloudsearch/get/web?csrf_token='
text = {'s': search_content, 'type': search_type, 'offset': 0, 'sub': 'false', 'limit': limit}
data = self.ep.search(text)
resp = self.session.post(url, data=data)
result = resp.json()
if result['result']['songCount']<= 0:
print('Not found!!')
else:
songs = result['result']['songs']
for song in songs:
song_id = song['id']
return song_idContent analysis
On the song details page, you can continue to use the debugging tool to capture the data package corresponding to the comments. You can find that the comments to be captured are placed in the comments in the data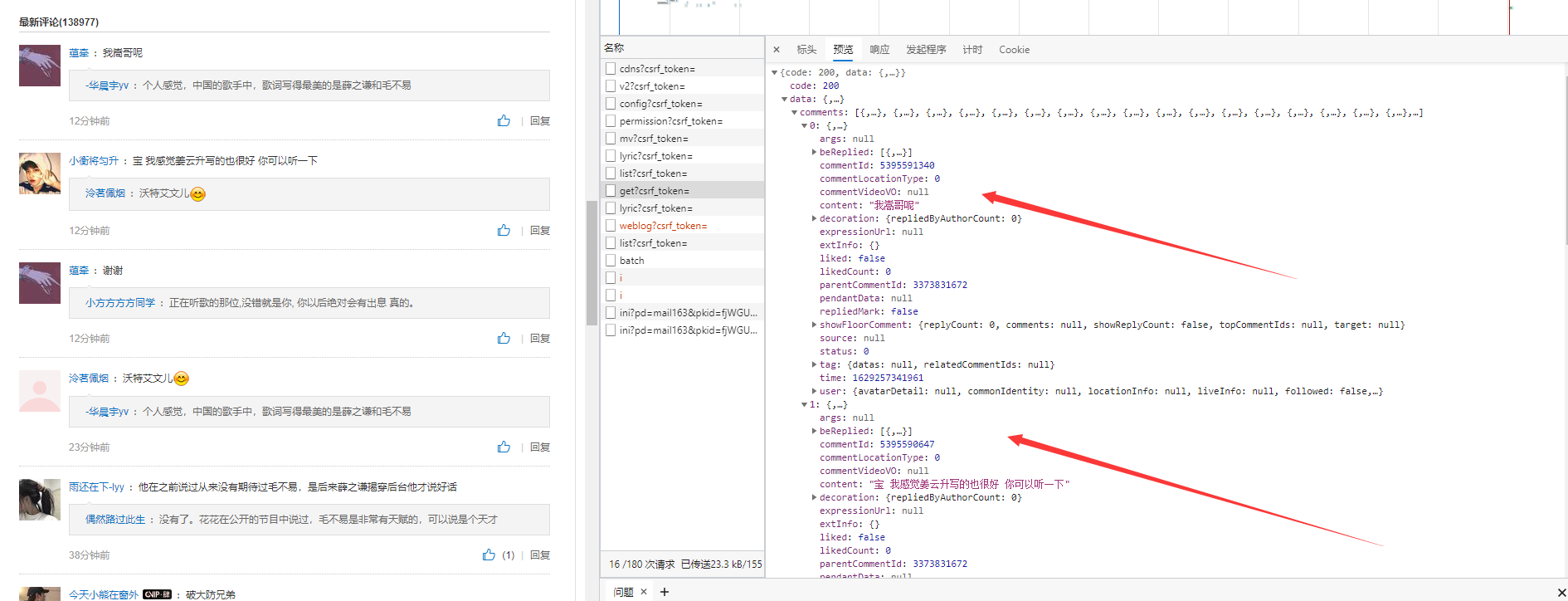
Then you can get the comment content through the form
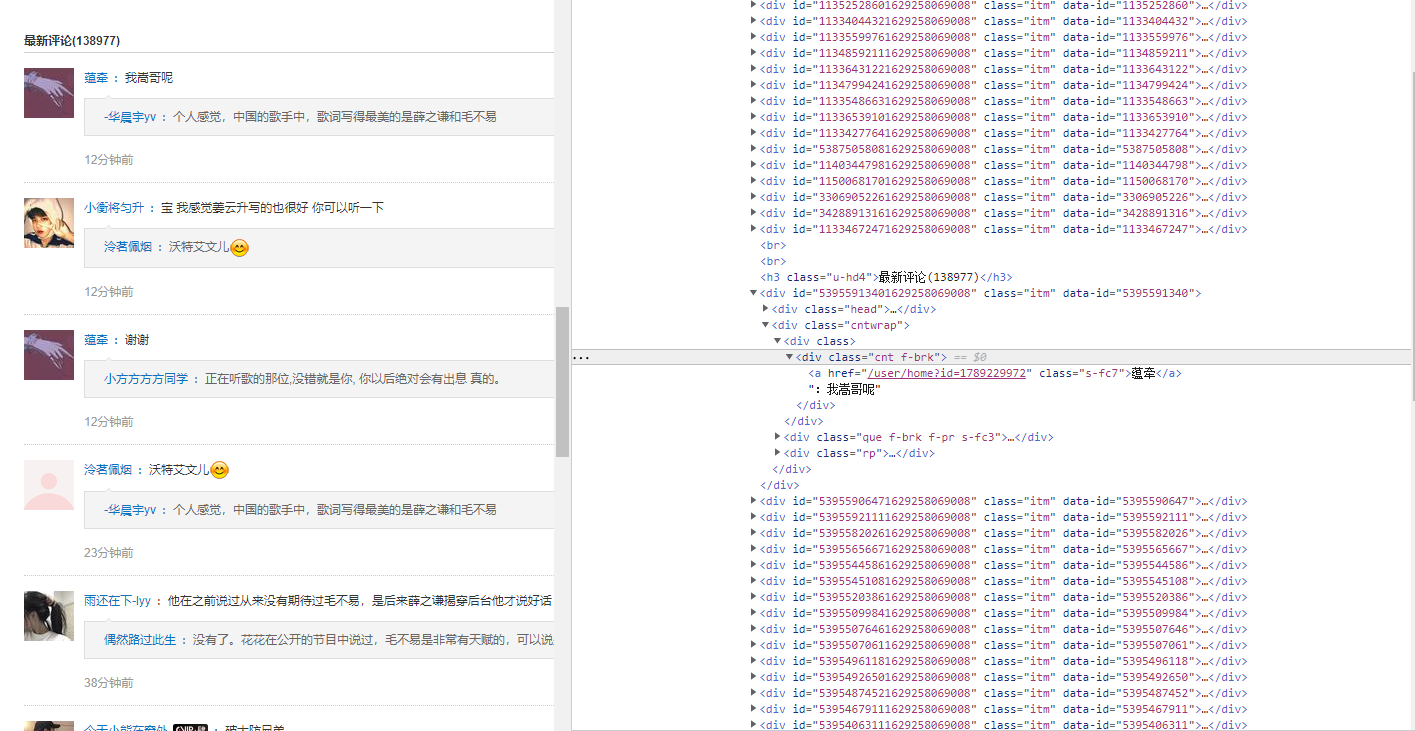
However, it is found through the packet header that the data of the form is encrypted, and the params and encSecKey need to be decoded.
 After checking, it is AES encryption. Now there are many decryption methods, and the encryption problem has been solved:
After checking, it is AES encryption. Now there are many decryption methods, and the encryption problem has been solved:
import base64
import json
import os
from binascii import hexlify
from Crypto.Cipher import AES
second_param = "010001"
third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
forth_param = "0CoJUm6Qyw8W8jud"
# Encryption and decryption
class Encrypted():
'''Incoming songs ID,Encryption generation'params','encSecKey return'''
def __init__(self):
self.pub_key = second_param
self.modulus = third_param
self.nonce = forth_param
def create_secret_key(self, size):
return hexlify(os.urandom(size))[:16].decode('utf-8')
def aes_encrypt(self, text, key):
iv = '0102030405060708'
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key.encode('utf-8'), AES.MODE_CBC, iv.encode('utf-8'))
result = encryptor.encrypt(text.encode('utf-8'))
result_str = base64.b64encode(result).decode('utf-8')
return result_str
def rsa_encrpt(self, text, pubKey, modulus):
text = text[::-1]
rs = pow(int(hexlify(text.encode('utf-8')), 16), int(pubKey, 16), int(modulus, 16))
return format(rs, 'x').zfill(256)
def search(self, text):
text = json.dumps(text)
i = self.create_secret_key(16)
encText = self.aes_encrypt(text, self.nonce)
encText = self.aes_encrypt(encText, i)
encSecKey = self.rsa_encrpt(i, self.pub_key, self.modulus)
data = {'params': encText, 'encSecKey': encSecKey}
return dataimport requests, base64
from Crypto.Cipher import AES
from Netease_cloud_comment_capture.Encrypt import forth_param
def get_params(page): # page is the number of incoming pages
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1): # If it is the first page
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page - 1) * 20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset, 'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
def AES_encrypt(text, key, iv):
if type(text) == type(b'123'):
text = text.decode('utf-8')
# text=text.decode('utf-8')
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
iv = iv.encode('utf-8')
key = key.encode('utf-8')
encryptor = AES.new((key), AES.MODE_CBC, (iv))
text = text.encode('utf-8')
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
# Constructor to get singer information
def get_comments_json(url, data):
headers={'Accept': 'text/html, application/xhtml+xml, application/xml;q=0.9, image/webp, image/apng, */*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN, zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'WM_TID=36fj4OhQ7NdU9DhsEbdKFbVmy9tNk1KM; _iuqxldmzr_=32; _ntes_nnid=26fc3120577a92f179a3743269d8d0d9, 1536048184013; _ntes_nuid=26fc3120577a92f179a3743269d8d0d9; __utmc=94650624; __utmz=94650624.1536199016.26.8.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); WM_NI=2Uy%2FbtqzhAuF6WR544z5u96yPa%2BfNHlrtTBCGhkg7oAHeZje7SJiXAoA5YNCbyP6gcJ5NYTs5IAJHQBjiFt561sfsS5Xg%2BvZx1OW9mPzJ49pU7Voono9gXq9H0RpP5HTclE%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eed5cb8085b2ab83ee7b87ac8c87cb60f78da2dac5439b9ca4b1d621f3e900b4b82af0fea7c3b92af28bb7d0e180b3a6a8a2f84ef6899ed6b740baebbbdab57394bfe587cd44b0aebcb5c14985b8a588b6658398abbbe96ff58d868adb4bad9ffbbacd49a2a7a0d7e6698aeb82bad779f7978fabcb5b82b6a7a7f73ff6efbd87f259f788a9ccf552bcef81b8bc6794a686d5bc7c97e99a90ee66ade7a9b9f4338cf09e91d33f8c8cad8dc837e2a3; JSESSIONID-WYYY=G%5CSvabx1X1F0JTg8HK5Z%2BIATVQdgwh77oo%2BDOXuG2CpwvoKPnNTKOGH91AkCHVdm0t6XKQEEnAFP%2BQ35cF49Y%2BAviwQKVN04%2B6ZbeKc2tNOeeC5vfTZ4Cme%2BwZVk7zGkwHJbfjgp1J9Y30o1fMKHOE5rxyhwQw%2B%5CDH6Md%5CpJZAAh2xkZ%3A1536204296617; __utma=94650624.1052021654.1536048185.1536199016.1536203113.27; __utmb=94650624.12.10.1536203113',
'Host': 'music.163.com',
'Referer': 'http://music.163.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/66.0.3359.181 Safari/537.36'}
try:
r = requests.post(url, headers=headers, data=data)
r.encoding = "utf-8"
if r.status_code == 200: # The status code 200 represents the normal response of the server
# Return data in json format
return r.json()
except:
print("Crawl failed!")
Comment capture
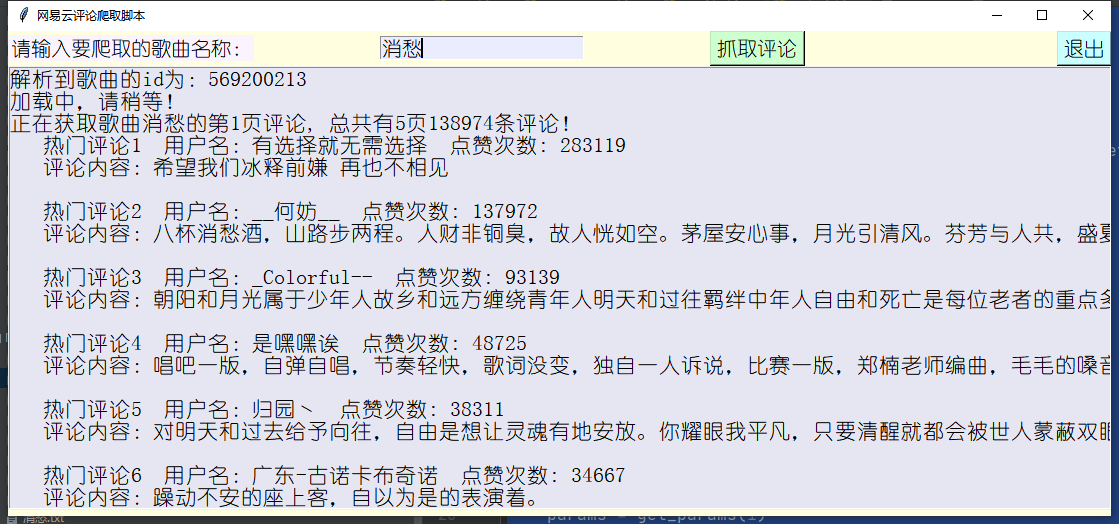
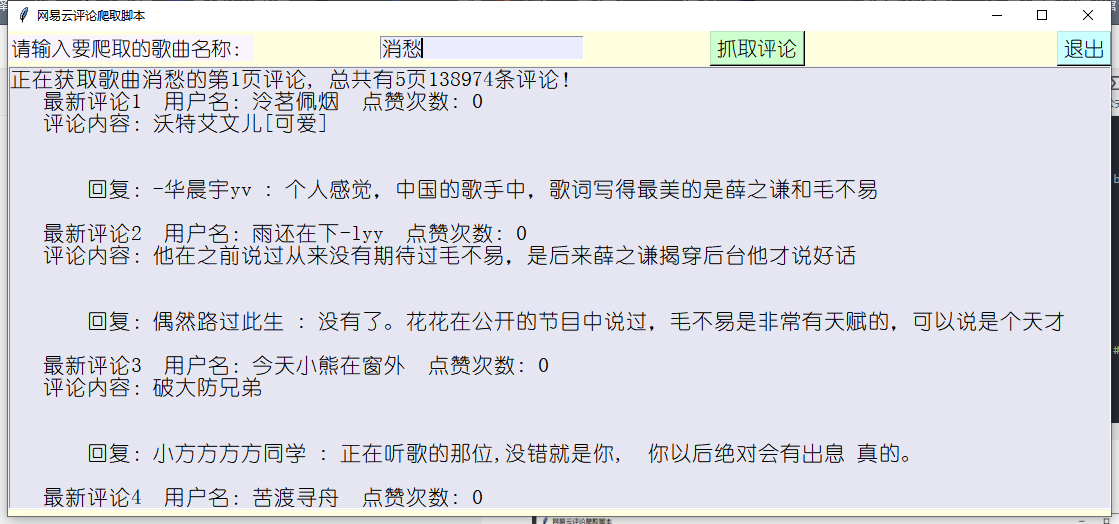
There are two kinds of comments, one is wonderful comments, which is what we call hot comments, and the other is the latest comments, maybe sorted by time
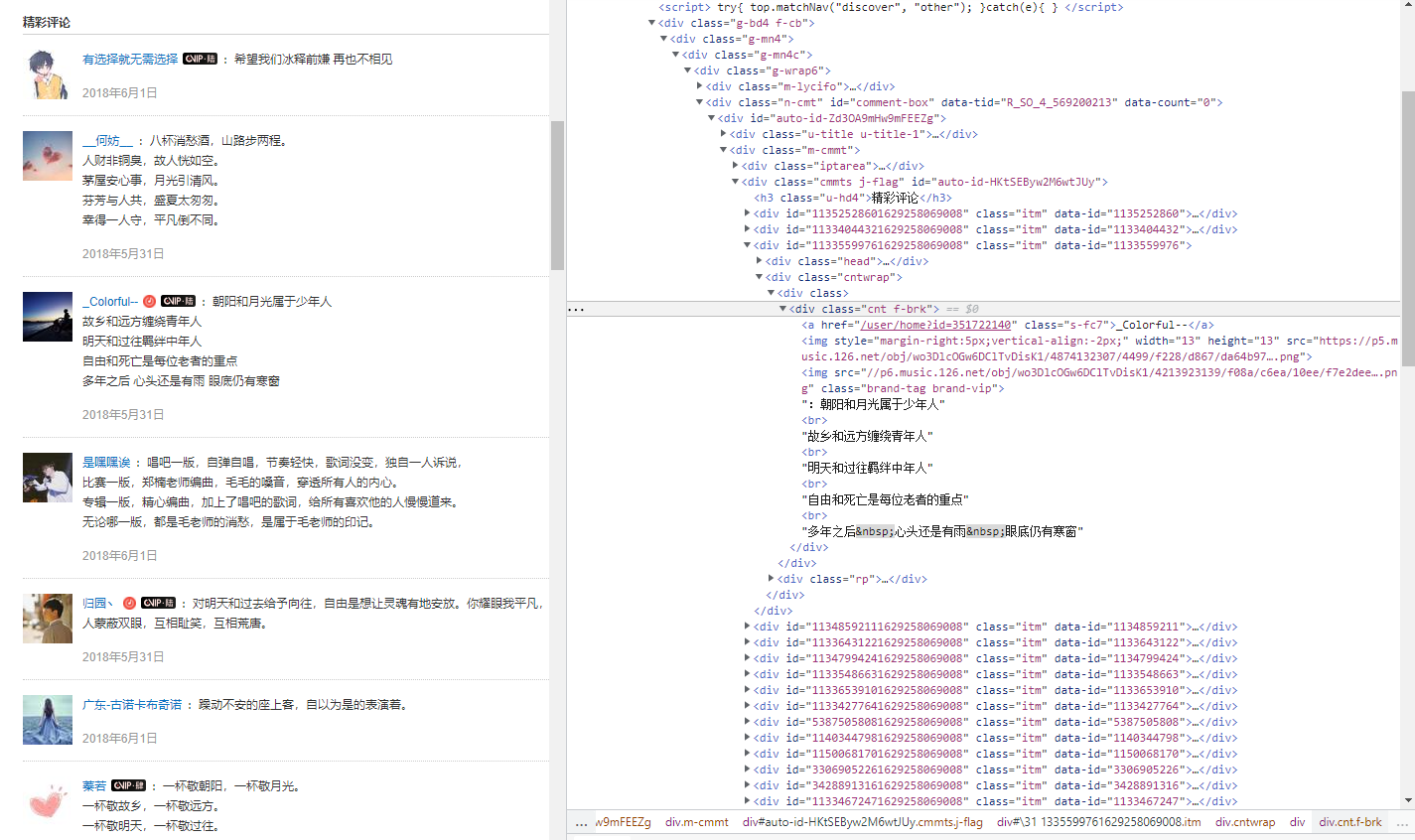
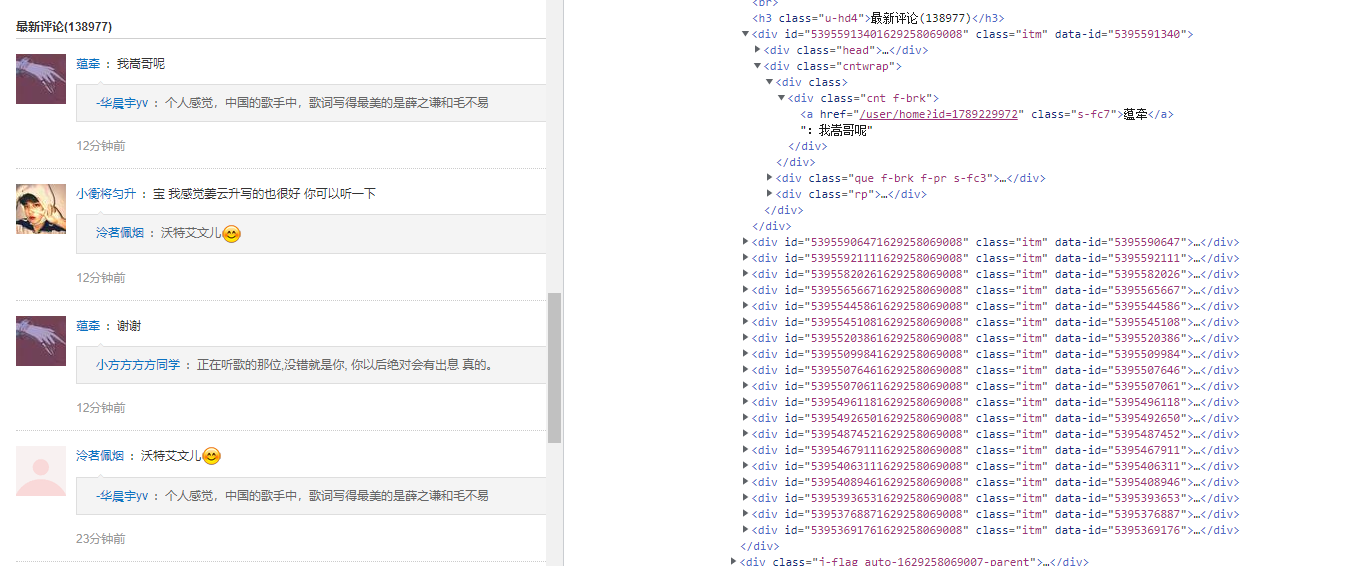
Next, you only need to parse the web content. The two comments are located in different paths, so you can get the comments
After getting the comments, write a GUI interface using tkinter to display the crawled content, and write the crawled comments into the file for storage
import math
import tkinter
from tkinter import *
from Netease_cloud_comment_capture.searchMusic import search
# Search for song names
from Netease_cloud_comment_capture.tool import get_params, get_comments_json, get_encSecKey
def get_music_name():
d = search()
song_id = d.search_song(entry.get())
text.insert(END, 'Parse to song id Is:{}\n'.format(song_id))
text.update()
# Song name
songname = entry.get()
# File storage path
filepath = songname + ".txt"
page = 1
params = get_params(1)
encSecKey = get_encSecKey()
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_' + str(song_id) + '?csrf_token='
data = {'params': params, 'encSecKey': encSecKey}
# Get first page comments
html = get_comments_json(url, data)
# Total comments
total = html['total']
# PageCount
pages = math.ceil(total / 20)
if(total>5):
pages = 5
else:
pages = total
hotcomments(html, songname, page, pages, total, filepath)
comments(html, songname, page, pages, total, filepath)
# Start getting all comments on the song
page = 2
while page <= pages:
params = get_params(page)
encSecKey = get_encSecKey()
data = {'params': params, 'encSecKey': encSecKey}
html = get_comments_json(url, data)
# Get comments from page 2
comments(html, songname, page, pages, total, filepath)
page += 1
tkinter.messagebox.showinfo('Tips', 'Comment capture completed, please check!')
########
def hotcomments(html, songname, i, pages, total, filepath):
text.insert(END, 'Loading, please wait!\n')
text.update()
text.after(100)
# write file
with open(filepath, 'a', encoding='utf-8') as f:
f.write("Getting songs{}The first{}Page comments, Total{}page{}Comments!\n\n".format(songname, i, pages, total))
text.insert(END, "Getting songs{}The first{}Page comments, Total{}page{}Comments!\n\n".format(songname, i, pages, total))
text.update()
text.after(100)
# Wonderful comments
m = 1
# Returns True if the key is in the dictionary, False otherwise
if 'hotComments' in html:
for item in html['hotComments']:
# Extract user names for popular comments
user = item['user']
# write file
text.insert(END, " Popular comments{} user name:{} Like times: {}\n\n".format(m, user['nickname'],item['likedCount']))
text.insert(END, " Comments:{}\n\n".format(item['content']))
text.update()
text.after(100)
with open(filepath, 'a', encoding='utf-8') as f:
f.write(" Popular comments{} user name:{} Like times: {}\n\n".format(m, user['nickname'], item['likedCount']))
f.write(" Comments:{}\n\n".format(item['content']))
text.insert(END, "\n\n")
# Reply to comments
if len(item['beReplied']) != 0:
for reply in item['beReplied']:
# Extract the user name to reply to comments
replyuser = reply['user']
text.insert(END, " reply:{} : {}".format(replyuser['nickname'], reply['content']))
text.insert(END, "\n\n")
text.update()
text.after(100)
f.write(" reply:{} : {}\n".format(replyuser['nickname'], reply['content']))
m += 1
def comments(html, songname, i, pages, total, filepath):
with open(filepath, 'a', encoding='utf-8') as f:
f.write("\n\n Getting songs{}The first{}Page comments, Total{}page{}Comments!\n".format(songname, i, pages, total))
text.insert(END, "\n\n Getting songs{}The first{}Page comments, Total{}page{}Comments!\n".format(songname, i, pages, total))
text.update()
text.after(100)
# All comments
j = 1
for item in html['comments']:
# Extract user name for comment
user = item['user']
text.insert(END, " Latest comments{} user name:{} Like times: {}\n\n".format(j, user['nickname'],item['likedCount']))
text.insert(END, " Comments:{}\n\n".format(item['content']))
text.insert(END, "\n\n")
text.update()
text.after(10)
with open(filepath, 'a', encoding='utf-8') as f:
f.write(" Latest comments{} user name:{} Like times: {}\n\n".format(j, user['nickname'], item['likedCount']))
f.write(" Comments:{}\n\n".format(item['content']))
text.insert(END, "\n\n")
# Reply to comments
if len(item['beReplied']) != 0:
for reply in item['beReplied']:
# Extract the user name to reply to comments
replyuser = reply['user']
text.insert(END, " reply:{} : {}".format(replyuser['nickname'], reply['content']))
text.insert(END, "\n\n")
text.update()
text.after(10)
f.write(" reply:{} : {}\n".format(replyuser['nickname'], reply['content']))
j += 1
# Create interface
root = Tk()
# title
root.title("Netease cloud comment crawling script")
# Set window size
root.geometry('1123x410')
root.configure(bg="#FFFFDF")
# Label control
label = Label(root, text='Please enter the song name to crawl:', font=('Immature', 15,), bg='#FAF4FF')
# Label positioning
label.grid(sticky=W)
# Input box
entry = Entry(root, font=('Immature', 15), bg='#ECECFF')
entry.grid(row=0, column=1, sticky=W)
# Grab button
button = Button(root, text='Grab comments', font=('Immature', 15), command=get_music_name, bg='#CEFFCE')
# Align left
button.grid(row=0, column=2, sticky=W)
# list box
text = Listbox(root, font=('Immature', 16), width=100, height=20, bg='#E6E6F2')
text.grid(row=1, columnspan=4)
# Exit button
button1 = Button(root, text='sign out', font=('Immature', 15), command=root.quit, bg='#CAFFFF')
button1.grid(row=0, column=3, sticky=E)
# Display interface
root.mainloop()
Crawling results