Case 1
Grab objects:
Sina National News ( http://news.sina.com.cn/china/ ), the title name, time, link in the list.
Full code:
1 from bs4 import BeautifulSoup 2 import requests 3 4 url = 'http://news.sina.com.cn/china/' 5 web_data = requests.get(url) 6 web_data.encoding = 'utf-8' 7 soup = BeautifulSoup(web_data.text,'lxml') 8 9 for news in soup.select('.news-item'): 10 if(len(news.select('h2')) > 0): 11 h2 = news.select('h2')[0].text 12 time = news.select('.time')[0].text 13 a = news.select('a')[0]['href'] 14 print(h2,time,a)
Run result: (Show only part)

Explanation:
1. First insert the libraries you need: BeautifulSoup, requests, and then parse the web page.After parsing, under print, confirm that the parsing is correct.
1 from bs4 import BeautifulSoup 2 import requests 3 4 url = 'http://news.sina.com.cn/china/' 5 web_data = requests.get(url) 6 soup = BeautifulSoup(web_data.text,'lxml') 7 print(soup)
At this time, we can see that the parsed web page contains a lot of garbage, which is not correctly parsed.Look at the result and see the opening sentence:
<meta content="text/html; charset=utf-8" http-equiv="Content-type"/>
[charset=utf-8] The character set representing the current content is in UTF-8 encoding format, so we need to use encoding to unlock it, and then we can parse out the normal content.
1 from bs4 import BeautifulSoup 2 import requests 3 4 url = 'http://news.sina.com.cn/china/' 5 web_data = requests.get(url) 6 web_data.encoding = 'utf-8' 7 soup = BeautifulSoup(web_data.text,'lxml') 8 print(soup)
2. After parsing the web page, start grabbing what we need.First, add a few points.
Look at the first line in the code below, soup.select('.news-item'), when removing an element with a specific CSS attribute, such as:
- Find all the elements that have a class of news-item, prefixed by a dot (.), the period in English;
- Find all the elements whose id is artibodyTitle, prefixed with a pound sign (#).
In addition, when you get a HTML element with a specific tag, write the tag name directly after the select, as in line 3 of the for loop below, news.select('h2').
1 for news in soup.select('.news-item'): 2 # print(news) 3 if(len(news.select('h2')) > 0): 4 # print(news.select('h2')[0].text) 5 h2 = news.select('h2')[0].text 6 time = news.select('.time')[0].text 7 a = news.select('a')[0]['href'] 8 print(h2,time,a)
Now let's take a closer look at the definition of each line of this code.
Line 1: soup.select('.news-item'), take out the elements in the news-item class;
Line 2: news under print to see if it has been parsed properly, continue normally, and comment out when not in use;
Line 3: By looking at the code, you can see that the title is stored in the label h2. If the length of H2 is greater than 0, this is to remove empty header data;
Line 4: news.select('h2')[0].text, [0] is the first element in the list, text is the text data, print to see if it is correct, you can comment it out when not in use;
Line 5: Store news.select('h2')[0].text in variable h2;
Line 6: Time is a class type, preceded by a dot, as above, storing its data in the variable time;
Line 7: The link we want to grab is stored in the a tag, the link is no longer a text, and then the link data is stored in the variable a with href.
Line 8: The final output is the data we want to capture, title, time, link.
Case 2
Grab objects:
Capture the title, time (format conversion), source, details, responsible editing, number of comments, and news ID of the news details page.
Sample News: http://news.sina.com.cn/c/nd/2017-05-08/doc-ifyeycfp9368908.shtml
Full code:
1 from bs4 import BeautifulSoup 2 import requests 3 from datetime import datetime 4 import json 5 import re 6 7 news_url = 'http://news.sina.com.cn/c/nd/2017-05-08/doc-ifyeycfp9368908.shtml' 8 web_data = requests.get(news_url) 9 web_data.encoding = 'utf-8' 10 soup = BeautifulSoup(web_data.text,'lxml') 11 title = soup.select('#artibodyTitle')[0].text 12 print(title) 13 14 time = soup.select('.time-source')[0].contents[0].strip() 15 dt = datetime.strptime(time,'%Y year%m month%d day%H:%M') 16 print(dt) 17 18 source = soup.select('.time-source span span a')[0].text 19 print(source) 20 21 print('\n'.join([p.text.strip() for p in soup.select('#artibody p')[:-1]])) 22 23 editor = soup.select('.article-editor')[0].text.lstrip('Responsible editors:') 24 print(editor) 25 26 comments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fyeycfp9368908&group=&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=20') 27 comments_total = json.loads(comments.text.strip('var data=')) 28 print(comments_total['result']['count']['total']) 29 30 news_id = re.search('doc-i(.+).shtml',news_url) 31 print(news_id.group(1))
Run result:
Ministry of Homeland: The reporting system of daily geological disasters in flood season will be implemented from May to September
2017-05-08 17:21:00
CCTV news
Originally titled: Ministry of Land and Resources: Implementing a daily reporting system in the high incidence of geological disasters
According to the Ministry of Land and Resources, May will gradually enter a high incidence of geological disasters, and the situation of disaster prevention and mitigation will be more serious.According to the forecast of China Meteorological Bureau, most of the precipitation in the south, East and northwest of China in May is higher than that in the same period of years. It is necessary to strengthen the prevention of geological disasters such as landslides and mudslides caused by extreme weather events.From May to September, the emergency department of the Ministry of Land and Resources shall implement the reporting system of daily geological disasters in flood season. All localities must deploy their daily disasters and major work to report to the emergency department of the Ministry of Land and Resources before 3 p.m. on that day.
Li Weishan
4
fyeycfp9368908
Explanation:
1. First insert the libraries you need: BeautifulSoup, requests, datetime (time processing), json (decoding: decoding json format string into a Python object), re (regular expression), and then parse the web page.
First grab the title:
1 from bs4 import BeautifulSoup 2 import requests 3 from datetime import datetime 4 import json 5 import re 6 7 url = 'http://news.sina.com.cn/c/nd/2017-05-08/doc-ifyeycfp9368908.shtml' 8 web_data = requests.get(url) 9 web_data.encoding = 'utf-8' 10 soup = BeautifulSoup(web_data.text,'lxml') 11 title = soup.select('#artibodyTitle')[0].text 12 print(title)
datetime, json, re are used in later time transitions and when fetching data from js.
We'll mainly look at the second-to-last line of code: title = soup.select('#artibodyTitle')[0].text, which is used in the same way as in the case where id is preceded by a pound sign (#) to indicate the location of such elements, unlock the only element by [0], extract the text information.
2. Grab the time and convert the original date format into standard format:
1 # time = soup.select('.time-source')[0] 2 # print(time) 3 time = soup.select('.time-source')[0].contents[0].strip() 4 dt = datetime.strptime(time,'%Y year%m month%d day%H:%M') 5 print(dt)
Line 1: Grab time;
Line 2: Time under print, you will find that the results contain both time and news sources as follows:
<span class="time-source" id="navtimeSource">2017 17 May 08, 2005:21 <span> <span data-sudaclick="media_name"><a href="http://M.news.cctv.com/2017/05/08/ARTIPEcvpHjWzuGDP WQhn77z170508.shtml "rel=" nofollow "target="_blank">CCTV News</a></span></span> </span>
Next, we need to find ways to separate time from source, using contents.
Line 3: We add. contents first, and when running, we see that the above content is divided into the following two elements in the list. At this time, we take the first element, add [0] after the contents, and finally. strip() removes the \t at the end of the time.
['2017 17 May 08, 2005:21\t\t', <span> <span data-sudaclick="media_name"><a href="http://M.news.cctv.com/2017/05/08/ARTIPEcvpHjWzuGDP WQhn77z170508.shtml "rel=" nofollow "target="_blank">CCTV News</a></span>,'\n']
Line 4: datetime.strptime() is used to format the time. The original time is the time of the month and day of the year, so the time of the month and day of the year is used for conversion. Among them,%Y is the four-digit year representation,%m is the month,%d is the day of the month,%H is the hour in the 24-hour system,%M is the minute number, and it is stored in the variable dt.
Line 5: Output dt, you get the formatted time, for example, 2017-05-08 17:21:00.
3. Grab news sources:
Previous Articles Python Crawler: Crawling Data Where Everyone Is a Product Manager It is mentioned that you can use Copy selector to copy and paste the location of the news source, as shown in the first line below. You can also use the representations of the class classes that are often used in this article to illustrate its location, as shown in the second line below.
1 # source = soup.select('#navtimeSource > span > span > a')[0].text 2 source = soup.select('.time-source span span a')[0].text 3 print(source)
4. Capture news details:
1 article = [] 2 for p in soup.select('#artibody p')[:-1]: 3 article.append(p.text.strip()) 4 # print(article) 5 print('\n'.join(article))
Line 1: article is an empty list;
Line 2: By looking at the code, you can see that the details of the news are stored in the p tag. If you output directly, you can see the information responsible for editing in the last column. If you don't want responsible editing, adding [: -1] removes the last editing information;
Line 3: Insert the captured data into the article list, and.strip() removes the blank information;
Line 4: You can see if the result is correct by print first. We find that the original title and body of the news details are in the same row, which is not very good. We can change the method after commenting it out.
Line 5: The join() method is used to concatenate elements in the list with specified characters to produce a new string, where \n is used to line up the original title and body of the list.
This is a way to connect articles, and of course, a more concise way to write them.We take out the for loop above, precede it with p.text.strip(), and bracket it as a whole, which forms a list, then join it together in front, replacing the above lines with a simple line of code.
1 print('\n'.join([p.text.strip() for p in soup.select('#artibody p')[:-1]]))
5. Grab responsible editors:
The lstrip used here is to remove the content on the left, and the bracketed'responsible editing:'refers to removing this content, leaving only the editor's name.The strip used before is to remove both sides, the lstrip is to remove the left side, and the rstrip used later is to remove the right side.
1 editor = soup.select('.article-editor')[0].text.lstrip('Responsible editors:') 2 print(editor)
6. Number of comments captured:
1 # comments = soup.select('#commentCount1') 2 # print(comment) 3 comments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fyeycfp9368908&group=&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=20') 4 # print(comments.text) 5 comments_total = json.loads(comments.text.strip('var data=')) 6 # print(comments_total) 7 print(comments_total['result']['count']['total'])
First, we select('#commentCount1') to filter out the number of comments, then the output under print is [<span id="commentCount1"></span>], there is blank information in the middle of the span, and there are no comments we want.
At this point, we need to look at the web page code again and see that the number of comments may have been increased through JavaScript, so we need to find out where JavaScript (or JS) was called from.
Mouse over number of comments (4), right mouse click "Check" in Google browser, select the top network, and then find a number of 4 links in the following numerous links.
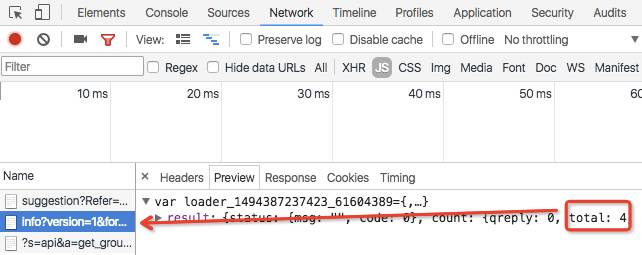
Copy the link, with the bold middle part newid and a timestamp-like string at the end'&jsvar=loader_1494295822737_91802706''. We need to remove that, and then try print, and you can see that the result will not be affected.
http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fyeycfp9368908&group=&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=20&jsvar=loader_1494295822737_91802706
Once you've processed the links, how do we read data from JavaScript?We need to use json for this, and at the beginning, we imported json when we imported the library, which can be used directly here.
json.loads is used to decode json data.In line 5, we store the decoded data in the variable comments_total; in line 6, when we print the variable, we get the result and find that there is more information than the number of comments.
So we need to re-output, and based on the results of the previous line of print, we can see that on the last line we can use ['result']['count']['total'] to indicate the position of the number of comments.
7. Capture news ID:
1 print(news_url.split('/')[-1].rstrip('.shtml').lstrip('doc-i'))
When we just grabbed the number of comments at point 6 above, we found a newsid in the link and the same ID part in the link of the news page, so we can make sure where its news ID is.
split() slices a string by specifying a separator, [-1] is the last element, then removes the end.shtml with rstrip, removes the doc-i on the left with lstrip, and gets the news ID we want.
In addition to this method, we can also express it in regular expressions.We need to use the re library at this point, and at the beginning, we already imported re in advance, which is used directly here.
Where re.search scans the entire string and returns the first successful match, group() is the matched string, where group(0), is the full display of the matched string (doc-ifyeycfp9368908.shtml), and group(1) is the display within (. +), which is the news ID we want.
1 news_id = re.search('doc-i(.+).shtml',news_url) 2 # print(news_id.group(0)) 3 print(news_id.group(1))
Operating Environment: Python Version, 3.6; PyCharm Version, 2016.2; Computer: Mac
----- End -----
Author: Du Wangdan, WeChat Public Number: Du Wangdan, Internet Product Manager.
