What is a reptile
Crawler is to grab the information in the web page according to certain rules. The crawler process is roughly divided into the following steps:
- Send request to target page
- Get the response content of the request
- Parse the returned response content according to certain rules to obtain the desired information
- Save the obtained information
Pre war preparation
Before we start, let's take a look at what we need to prepare:
- Development environment: Python 3 six
- Development tool: PyCharm
- Use frame: requests2 21.0,lxml4. three point three
These are the things used in this development. PyCharm is used in Python 3 6. The development uses two frameworks, requests and lxml, which are very simple.
make war
Create project
-
You can create a Pure Python project without using other frameworks. The project name is arbitrary. In my example, I take py Spiderman
-
Create a python file. The file name is arbitrary. In my example, I take # first_spider
Install requests and lxml
-
requests is a very powerful network request module in Python, which is simple and easy to use,
Directly enter "pip install requests" in PyCharm's Terminal.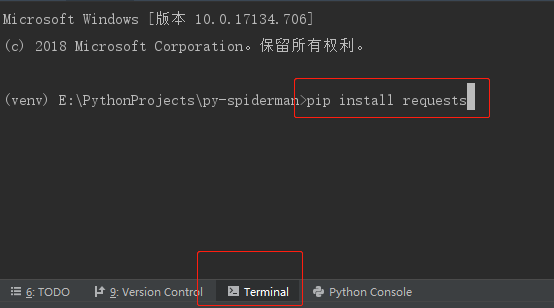
-
lxml is a module that we use to parse the response content of the request XPath Grammar, very powerful. The installation method is the same as above. Enter pip install lxml in Terminal.
Start programming
Before starting programming, we first select a target page. The target page of this example is https://www.archdaily.cn/cn/915495/luo-shan-ji-guo-ji-ji-chang-xin-lu-ke-jie-yun-xi-tong-yi-dong-gong
We need to capture the article title, time, author and content text information in the web page.

In the python file we created, we first import the modules we need to use, then create a class called simplesplider, and then write the crawler method in the class
# Import the system information module, which is used to obtain the project root directory import os # Import the network request library, which is used to request the target web page and obtain the web page content import requests # Import time library to get the current time from datetime import datetime # The etree module that imports lxml is used to parse the html returned by the request from lxml import etree # Create a crawler class class SimpleSpider:
Send request to get web content
In python, the method is identified by "def". A double sliding line is added before the method to indicate that the method is a private method of the class and cannot be accessed externally. The get() method of requests can directly send a get request to the web page and return a response object.
def __get_target_response(self, target):
"""
Send a request and get the response content
:param target(str): Target page link
"""
# Send a get request to the target url and return a response object
res = requests.get(target)
# Returns the html text of the web page of the target url
return res.text
Analyze the web content and get the information you want
Before parsing the response content, we first use Chrome browser to open the target web page, open the web page source code, click "F12" on the keyboard, and then find the information we need in the source code, such as the title, as shown in the following figure: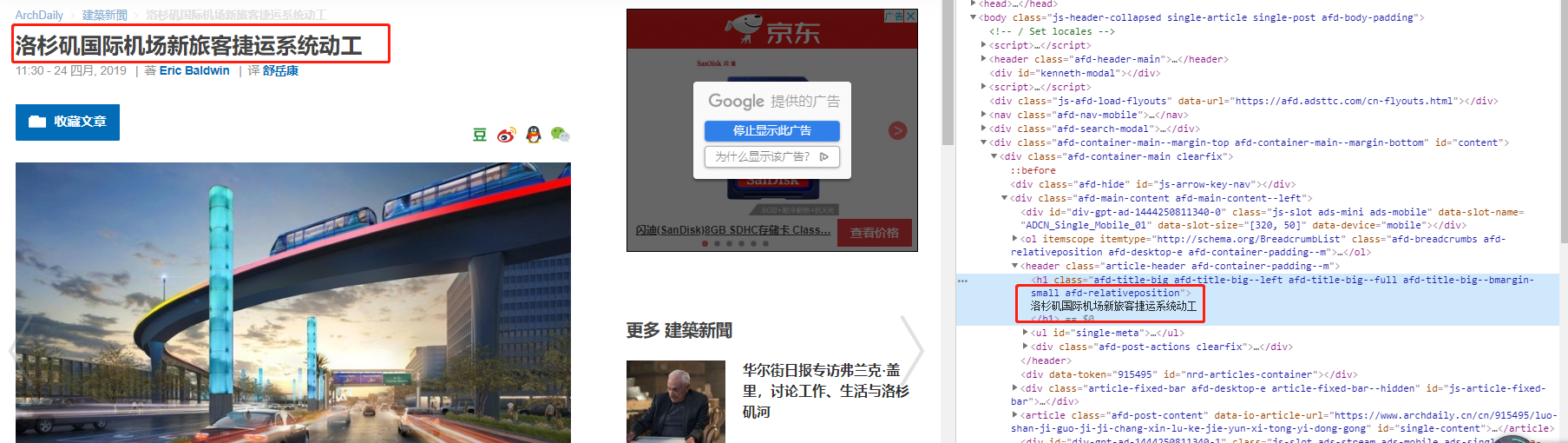

As can be seen from the figure, the title is in the h1 tag under the header tag, so how can we extract it? At this time, we need to use the etree module in the imported lxml library. How to use etree?
- First, let's go through etree HTML () method to create a XPath If you don't understand XPath, take a minute to understand it. It's very simple.
dom = etree.HTML(The response content text returned by the above method)
The dom object here is the html content element after converting the html text
- Then you can start parsing, as follows
title = dom.xpath('//h1/text()')[0]
//h1/text() is an XPath statement, / / refers to all descendants of the current node. You can simply understand it as all nodes under the < HTML > tag, / / h1 refers to all < h1 > tags under the < HTML > node, and h1/text() refers to the text content under the < h1 > tag, but it is only the text content of the first level. For example, < h1 > ABC < / h1 >, the value of h1/text() is ABC, However, the h1/text() value of < h1 > ABC < span > SS < / span > < / h1 > is still ABC, not ABCSS, because SS is wrapped by the < span > label and belongs to the second level.
Therefore, the above / / h1/text() means to obtain the text content of the first layer under all < H1 > tags under the < html > tag. If there are multiple < H1 > tags, an array of text content will be returned in the order of < H1 > tags in html. If there is only one < H1 > tag, an array is returned, but there is only one text content in it. In the current web page, there is only one < H1 > tag, so an array with only one element is returned, [0] means to get the first element in the array.
The complete parsing code is as follows:
def __parse_html(self, res):
"""
Parse the response content, using XPath analysis html Text and save
:param res(str): Target page html text
"""
# Initialize and generate an XPath parsing object to obtain html content elements
dom = etree.HTML(res)
# Gets the text content in the h1 tag, where dom XPath ('/ / h1 / text()') returns an array and extracts an element
title = dom.xpath('//h1/text()')[0]
# Get the text content in the li tag of class="theDate"
date = dom.xpath('//li[@class="theDate"]/text()')[0]
# Get the text content in the a tag of rel="author"
author = dom.xpath('//a[@rel="author"]/strong/text()')[0]
# Get the href attribute content in the a tag of rel="author"
author_link = 'https://www.archdaily.cn/' + dom.xpath('//a[@rel="author"]/@href')[0]
# Get all the attributes of the element without the label of article
p_arr = dom.xpath('//article/p[not(@*)]')
# Create an array to store the paragraph text in the article
paragraphs = []
# Traversal p tag array
for p in p_arr:
# Extract all text content under the p tag
p_txt = p.xpath('string(.)')
if p_txt.strip() != '':
paragraphs.append(p_txt)
paragraphs = paragraphs
Save information to txt file
This part is the code of the previous part, which belongs to the method__ parse_html(self, res) is split to better understand the crawler process. We write the information into a txt file. The file name is the string , first , followed by the current time string. The directory where the file is located is the root directory of the project.
# If the file does not exist, it is created automatically
# os.getcwd() gets the root directory of the project
# datetime.now().strftime('%Y%m%d%H%M%S') gets the current time string
with open('{}/first{}.txt'.format(os.getcwd(), datetime.now().strftime('%Y%m%d%H%M%S')), 'w') as ft:
ft.write('title:{}\n'.format(title))
ft.write('Time:{}\n'.format(date))
ft.write('Author:{}({})\n\n'.format(author, author_link))
ft.write('Text:\n')
for txt in paragraphs:
ft.write(txt + '\n\n')
implement
Now that the basic methods have been written, let's connect all the methods in series. We can write another method to connect the above methods:
def crawl_web_content(self, target):
"""
Crawler execution method
:param target(str): Target page link
"""
# Call the network request method and return a response
res = self.__get_target_response(target)
# Call the resolve response method
self.__parse_html(res)
Then we write an execution method
if __name__ == '__main__':
url = 'https://www.archdaily.cn/cn/915495/luo-shan-ji-guo-ji-ji-chang-xin-lu-ke-jie-yun-xi-tong-yi-dong-gong'
spider = SimpleSpider()
spider.crawl_web_content(url)
The text content of the saved txt is as follows:
title: Construction of new rapid transit system for passengers at Los Angeles International Airport starts Time: 11:30 - 24 April, 2019 Author: Eric Baldwin(https://www.archdaily.cn//cn/author/eric-baldwin) Text: The new passenger rapid transit system at Los Angeles International Airport is now in operation. After completion, the ground train will help passengers shuttle between the Los Angeles light rail and the airport. Last week, the mayor of Los Angeles Eric Garcetti Participated in municipal activities to celebrate the commencement of the project, LAX It is hoped that the project can improve the connection between terminals and reduce the congestion of motor vehicles entering and leaving the airport. As one of the busiest airports in the world, the new system connects newly completed car rental facilities to provide LAX Reduce traffic pressure. The ground breaking ceremony of the MRT system was held last Thursday. Last year, the City Council agreed LAX Combined with the MRT scheme, the whole project will cost $4.9 billion. As the world's fourth busiest airport, LAX We are looking for ways to reduce dependence on motor vehicle access. LAWA Officials estimate that when the new system is completed, the number of visitors will reach 85 million a year. The new system will stop at six stations, three of which are in the airport terminal. just as LAWA State that the MRT system expects to connect to the green line subway( the Metro Green),Crenshaw/ LAX Light rail line and fixed car rental center, the goal is to concentrate more than 20 car rental Offices in one location. This facility will reduce the number of free vehicles entering and leaving the central terminal area due to car rental demand, and reduce about 3200 vehicles entering and leaving the airport every day. The ground train runs every two minutes, and each train can carry 200 passengers. The MRT system is expected to be completed in 2023. Peng Li
Portal
Github: https://github.com/albert-lii/py-spiderman
summary
The above is the whole content of this article. It is just a simple example of crawler. In subsequent articles, we will gradually upgrade the crawler function, such as crawling multiple web pages at the same time, how to improve efficiency, how to use the powerful crawler framework sweep, etc.