1, IP proxy pool (relatively simple, subsequent updates)
Two protocols are used to verify ip and proxies, http and https
import re
import requests
url = 'https://tool.lu/ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'
}
proxies ={
'http':'47.243.190.108:7890',
'https':'47.243.190.108:7890'
}
res = requests.get(url=url,headers=headers,proxies=proxies,timeout=3).text
ip = re.search(r'[\d]{1,3}\.[\d]{1,3}\.[\d]{1,3}\.[\d]{1,3}',res,flags=re.S).group(0)
print(ip)
2, python crawler's scratch framework
Paste a picture first

Basic command
- Generate basic framework
scrapy startproject myspider
- Create crawler file
cd myspider scrapy genspider -t crawl SpiderName DomaimName
ps: the parameter - t crawl added above is to create a crawlespider, and the Rule method in it can help extract the url
Example: biqu Pavilion, crawling all over the station
- First, get more links, then enter this category, get the url of the page, then get the url of each page of the book, and enter the details page

- Using the crawlespider, you only need three lines to get it

- Explain the code above
- Link extractor: extractor (that is, to extract the page url, just put the rules of the page url directly into it)
- Callback: the callback function is to extract the page content. The above method is used to extract the url. This is used when extracting the details page (data)
- Follow: do you want to extract the url of each book for the extracted page, and then extract the detailed page data? At this time, you need to add follow=True
- function
scrapy crawl SpiderName
- The data after running is in

- Notice that the function name is parse_item()
- If it is a framework without any parameters, the generated function is parse()
scrapy stratproject myspider
Some return values and parameters of response

- Return value
- These are the return parameters of requests, URL, headers and status
- response.body.decode(): returns a text object
- Headers: request headers
- parameter
- meta: this parameter is mainly used to pass the item dictionary object
- Callback: callback function (multi page data or detail page)
- dont_filter: the default value is False, and the duplicate is removed
- Proxy: sets the proxy, usually in the item dictionary
- request.meta['proxy'] = 'https://' + 'ip:port'
- Configuration in setting
- download_timeout: like the timeout of the request module, set the timeout
- max_retry_times: maximum number of requests (two by default)
- dont_retry: the url that failed the request is no longer requested
- dont_merge_cookies: scratch will automatically save the returned cookies. If you add them or don't use them, set True
- bindaddress: output binding IP
- ROBOTSTXT_OBEY: compliance with the agreement
- LOG_LEVEL: print log level
- ERROR
- WARNING
- INFO
- CONCURRENT_REQUESTS: number of open threads
- DOWNLOAD_DELAY: Download delay
- DEFAULT_REQUEST_HEADERS: overrides the default request header when enabled
- The smaller the parameters behind downloading middleware and crawler middleware, the higher the priority
Basic usage of scratch
Set run file (setting peer)
from scrapy import cmdline
cmdline.execute('scrapy crawl xt'.split())
Override method start_requests
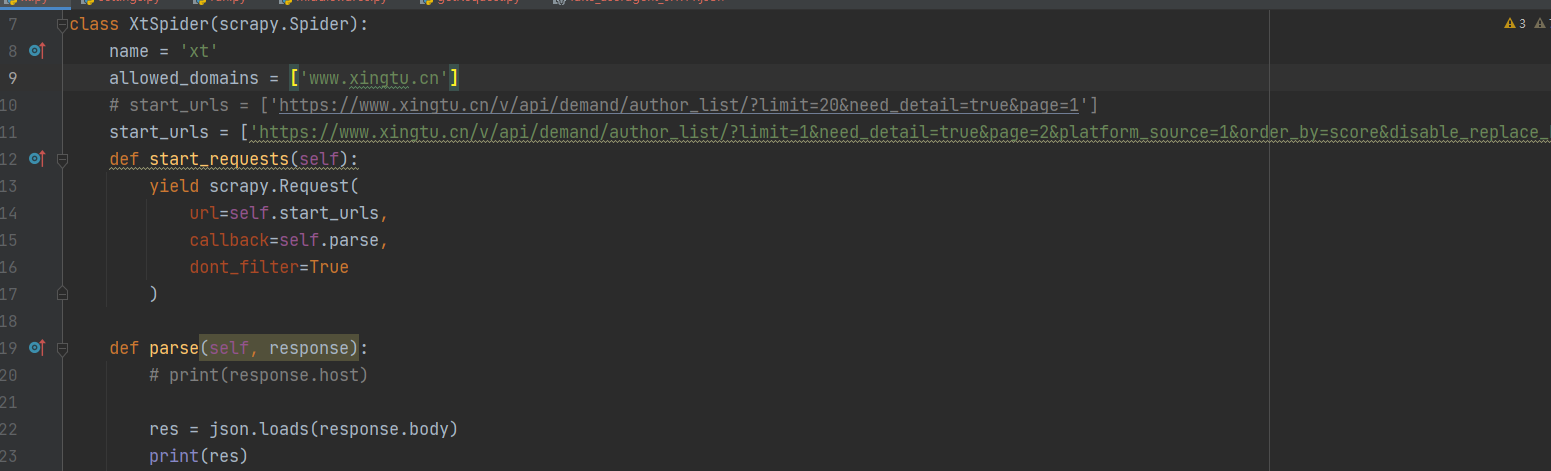
Change middleware Middleware
Random UA agent
fake_useragent is a package. pip install it
from fake_useragent import UserAgent
class DouyinxingtuUserAgentDownloaderMiddleware:
def process_request(self, request, spider):
agent = UserAgent(path='fake_useragent_0.1.11.json').random
request.headers['User-Agent'] = agent
Set user agent ip
class DouyinxingtuProxiesDownloaderMiddleware:
def process_request(self, request, spider):
porixList = getIp()
self.porix = random.choice(porixList) # 116.208.24.72:8118
request.meta['proxy'] ='https://'+self.porix
print(request.meta)
# If an error is reported, return
def process_exception(self, request, exception, spider):
print('Delete database values')
return request
Set the cookie (the dictionary format is required to set the cookie in the scratch Middleware)

The above is copied directly from the browser to convert the string into a dictionary
class DouyinxingtuCookieDownloaderMiddleware:
def process_request(self, request, spider):
cookie = self.get_cookie()
cookies = dict([l.split("=", 1) for l in cookie.split("; ")])
request.cookies=cookies
Pipeline based storage
Open the setting configuration first
This is the class name in pipelines

Pipe class configuration
# mysql database storage
class DouyinxingtuPipelineMysqlSave:
fp=None
def open_spider(self,spider):
print('Reptile start')
# Connect to database
pass
def process_item(self,item,spider):
print(item) # This is the item in items
pass
def close_spider(self,spider):
print('Reptile end')
pass
Personal habits, introduce classes in items
-
Introduce classes and assign values
item = DouyinxingtuItem() item['data'] = response['data']
-
items
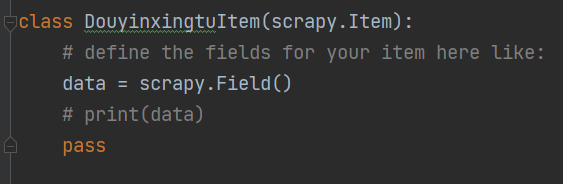
-
Save database (mysql, native sql)