As a self-study note, this article is for reference only
Learning course: IT of Feixue City, station B
Reptiles:
Use the program to obtain resources on the Internet.
robots.txt protocol: specifies which data in the website cannot be crawled. It is only a protocol, but it does not prevent malicious crawling
General steps of crawler:
- Get the page source code
- Analyze the source code and get the data
Before learning about crawlers, you should first understand the HTTP protocol.
HTTP protocol
HTTP protocol is the communication foundation of the world wide web. In short, it is the rules that computers need to follow when accessing web pages.
Next is the basic knowledge of computer network.
There are two kinds of HTTP messages, request message and response message.
Request message:
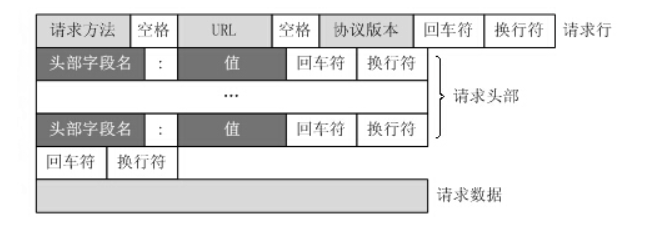
The request message that the client sends an HTTP request to the server includes the following formats: request line, request header, blank line and request data. The following figure shows the general format of the request message.
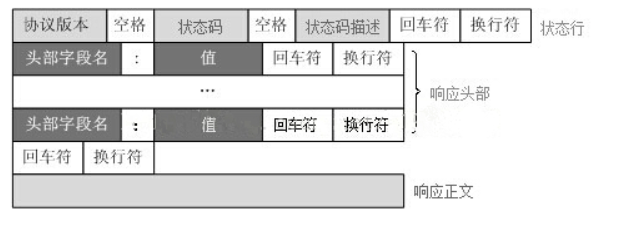
Response message:
The HTTP response also consists of four parts: status line, message header, blank line and response body
Some of the most common important contents in the request header:
- User agent: the identity of the request carrier (the request sent by what)
- Referer: which page will the anti-theft request come from this time
- cookie: local string data information (user login information, anti crawling token)
Some important contents in the response header:
- cookie
- All kinds of magical and inexplicable strings (usually tokens)
Request method:
GET: explicit commit
POST: implicit submission
Next, we will use get and post methods to crawl some web pages. If you haven't studied computer networking, just remember that there are two ways to request.
requests module
get() and post() functions
Mainly use requests Get() function and requests The post () function to request the content on the web page
Whether to use get or post depends on the request mode of the page to be crawled
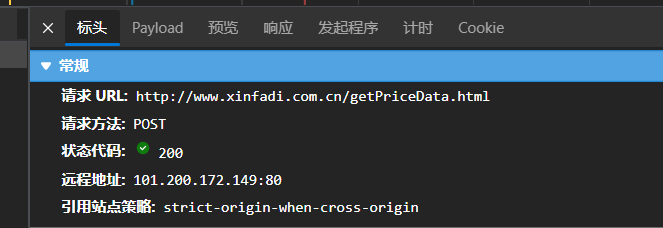
For example, the menu price page of Beijing Xinfadi is post
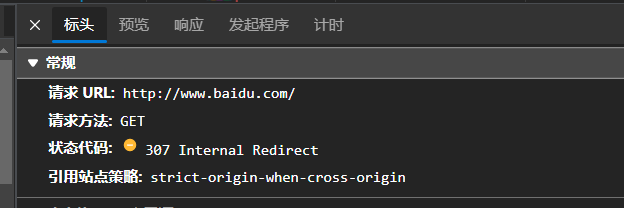
Baidu's is get
requests.get()
The first parameter passed in is url, which is the uniform resource location identifier. In short, it is the web page address to be crawled.
# The simplest get request method url = "http://www.baidu.com" requests.get(url)
Add url parameter, parameter name: params, dictionary form
For example:
The contents of the params parameter will be added directly after the url.
requests.post()
post plus url parameter. The parameter name is in the form of data dictionary
The contents of some web pages do not appear directly in the source code page, but are loaded dynamically. At this time, we need to capture the package, view its request parameters, and use this parameter to request the page.
For example: Beijing Xinfadi
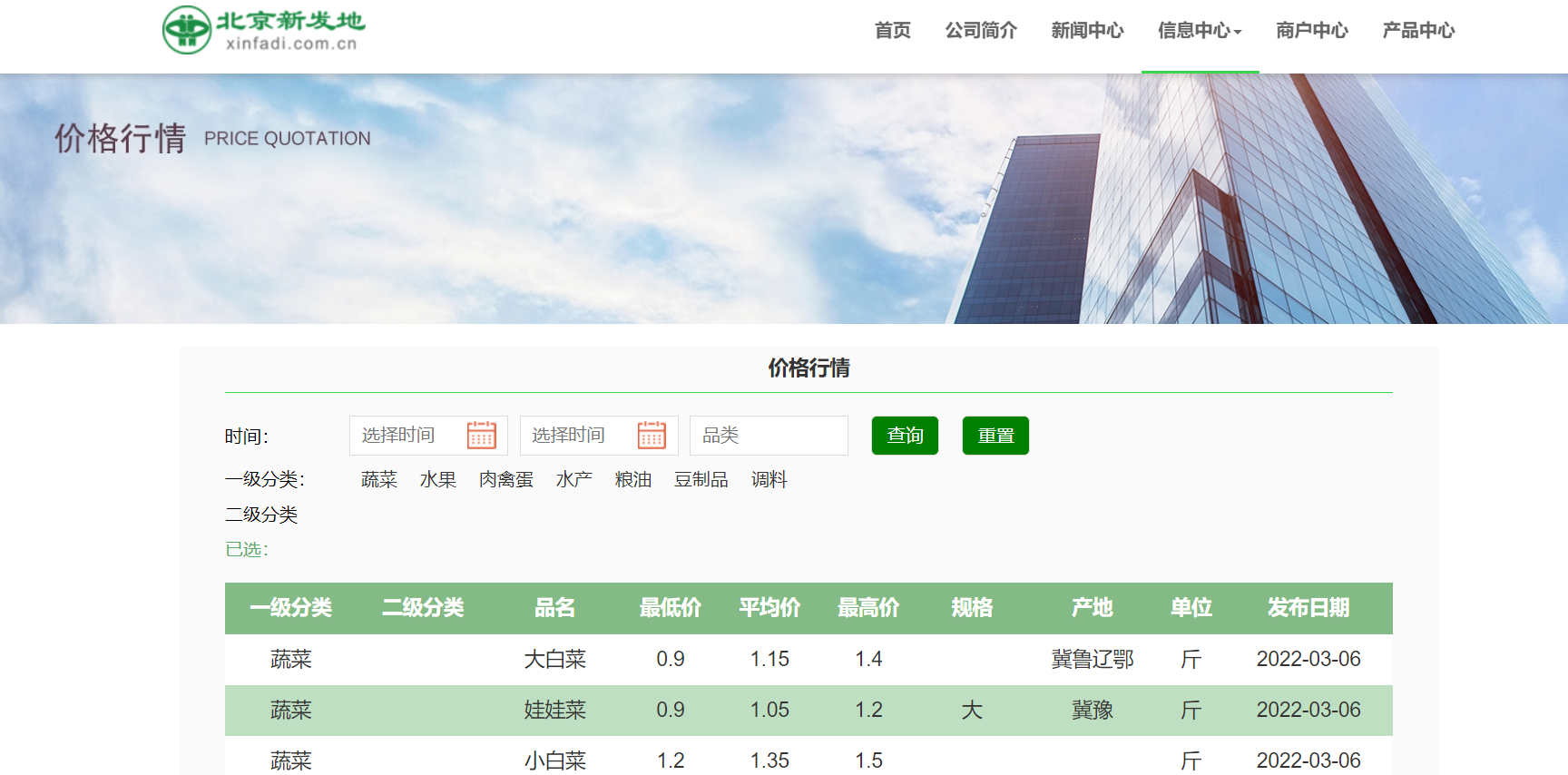
Let's check the source code
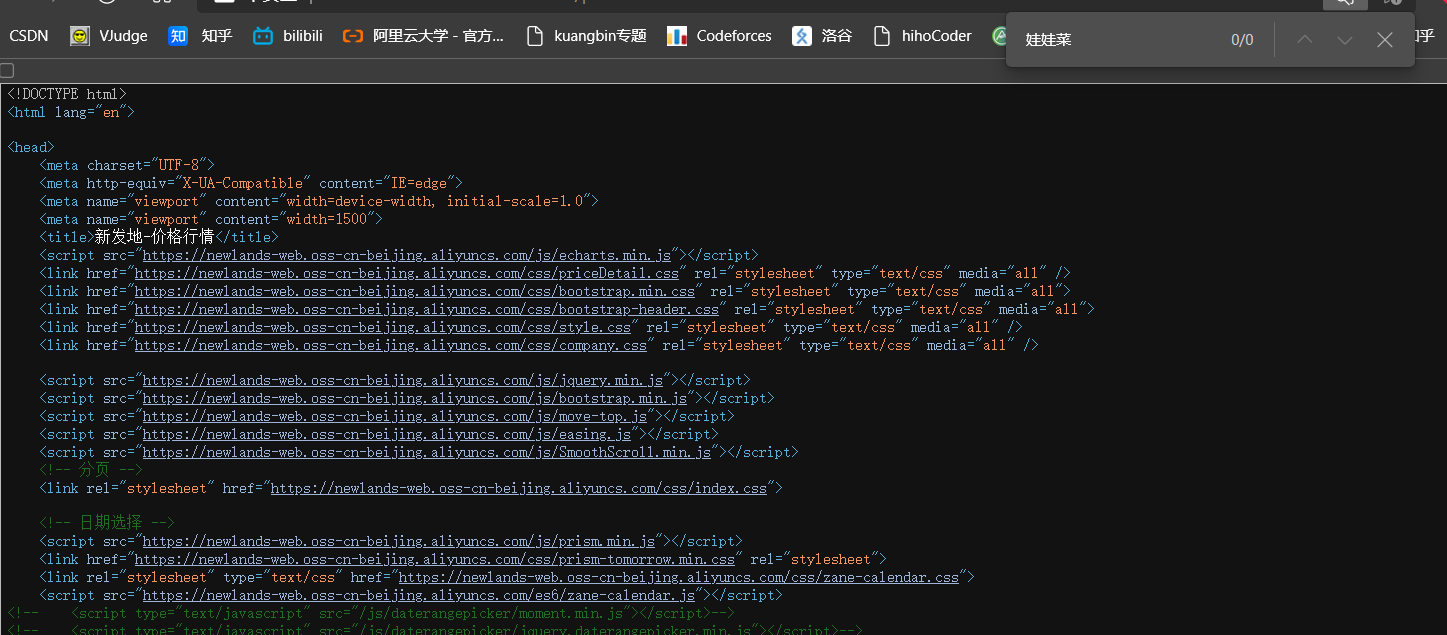
It can be seen that there is no information related to vegetable price in the source code. At this time, grab the package
In XHR, you can see that there is a getpricedata html
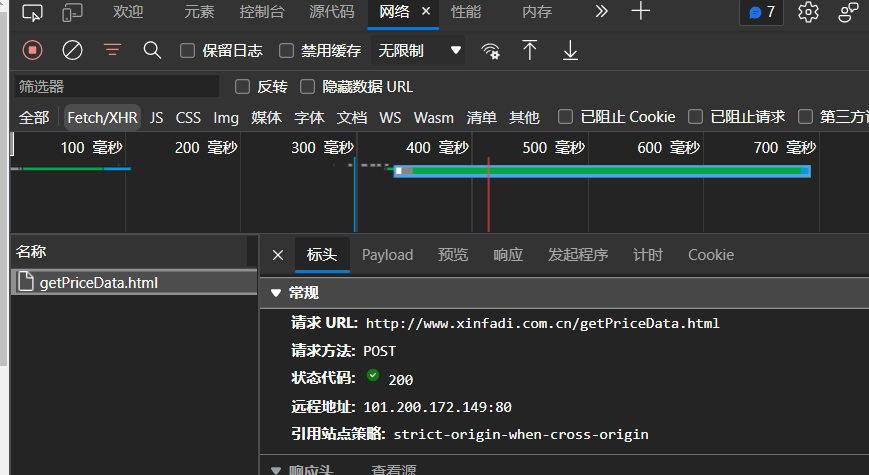
Click preview to expand the list
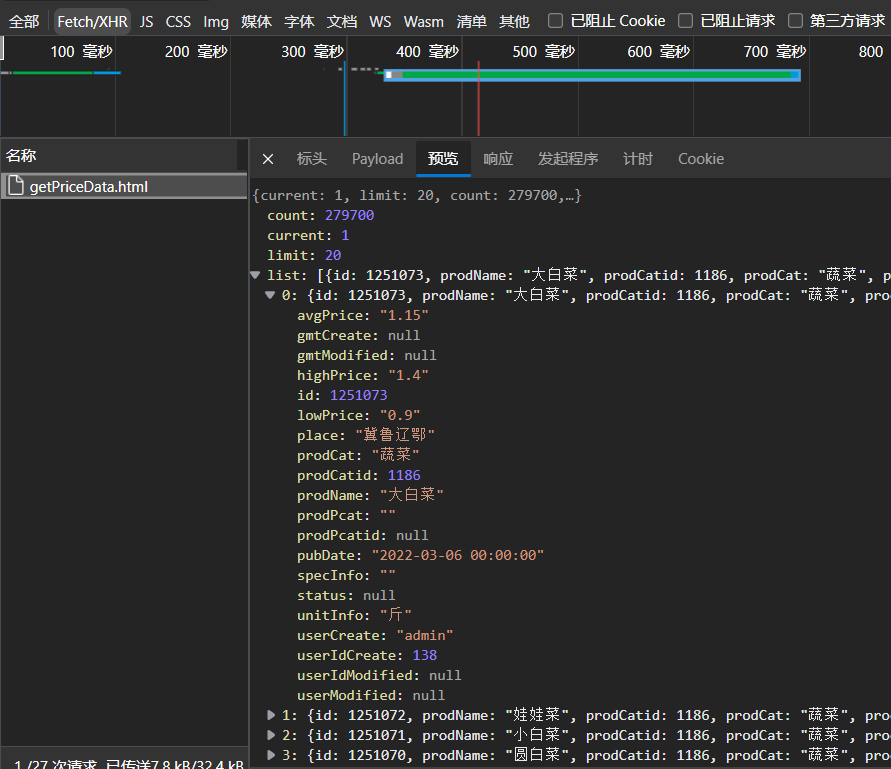
You can find the price information on this page
We directly copy the request address in the header, which can only open the food price information on the first page, so how do we get the food price information on the second page
After capturing the packet on the second page, you will find that the request URL has not changed, but its parameters have changed
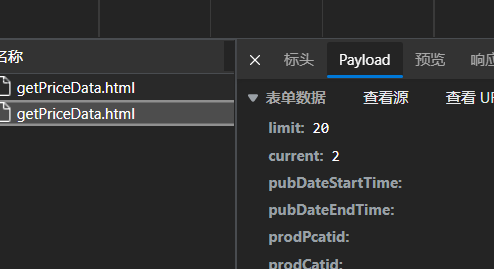
The value of current becomes 2, which means that the value of current represents the page number.
Therefore, when using the post request, we need to add the data parameter and the current parameter. In this way, by modifying the value of current, you can obtain the vegetable price information of all pages.
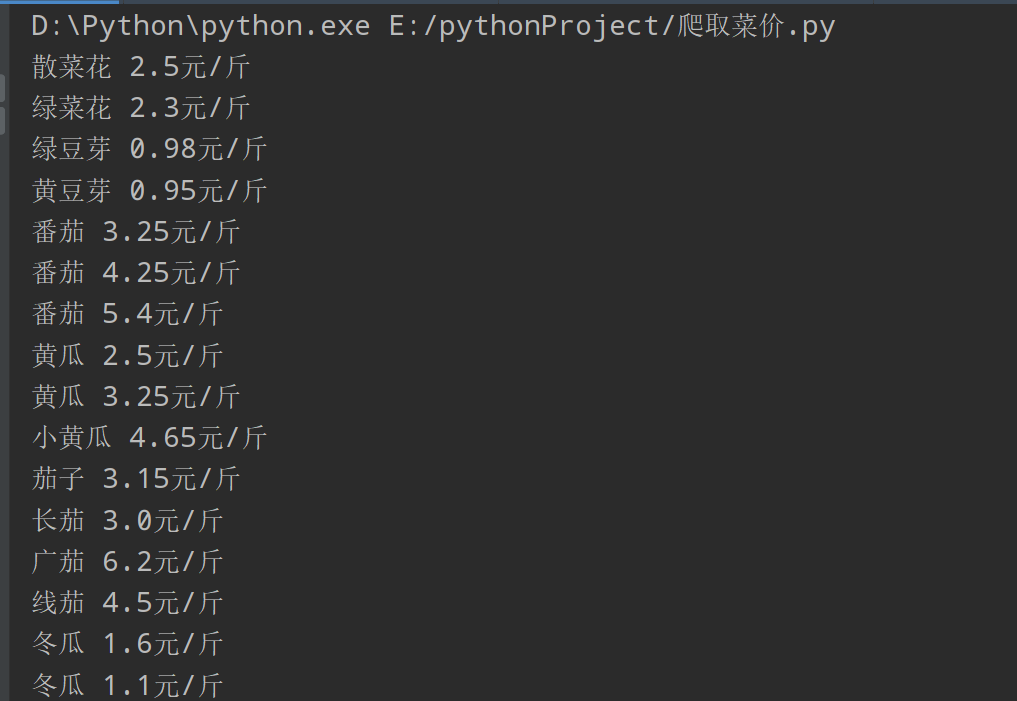
import requests
url = "http://www.xinfadi.com.cn/getPriceData.html"
data = {
"limit": 20,
"current": 2
}
# Get page source code
resp = requests.post(url, data=data)
dic = resp.json() // Since the vegetable price information is in json format, the course is directly saved in json format
lst = dic["list"]
for it in lst:
print(it["prodName"] + " " + it["avgPrice"] + "element/Jin") //Output information
headers
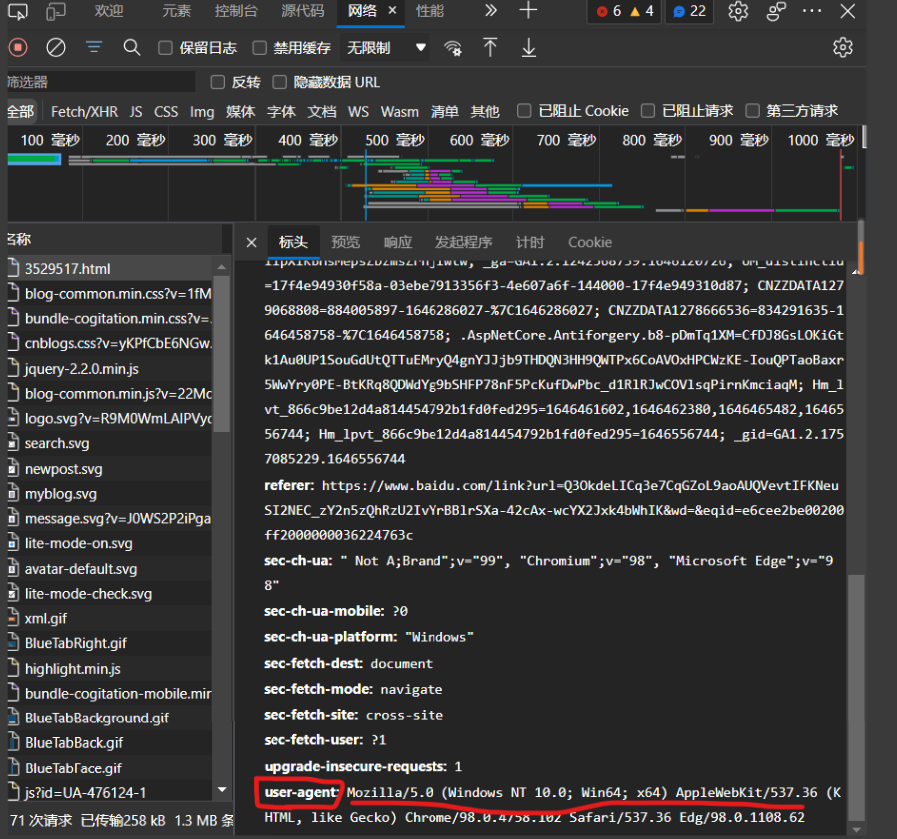
Because some websites have some simple anti crawling mechanisms, sometimes we need to add a header parameter in the get or post function. headers is a dictionary, in which there is only one key value pair, namely "user agent": "xxxxxxxx"
The Chinese name of User Agent is User Agent, which is a part of Http protocol and a part of header domain. User Agent is also referred to as UA for short. It is a special string header, which is an identification that provides information such as the type and version of the browser you use, the operating system and version, the browser kernel, and so on. Through this logo, the website visited by users can display different typesetting, so as to provide users with better experience or information statistics; For example, accessing Google by mobile phone is different from accessing by computer. These are judged by Google according to the UA of visitors. UA can be disguised.
Generally speaking, the user agent who obtains the web page can successfully cheat.
Steps: (take Edge browser as an example)
- Open the web page you want to crawl
- F12 open console
- Click on network
- F5 refresh page
- Click the first html file that appears in the list
- Find the user agent in the request header and copy all subsequent text
- Construct the user agent field just copied into dictionary form
example:
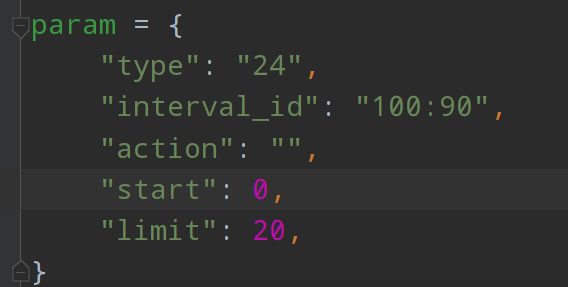
Climbing watercress ranking
import requests
# get request with parameters
url = "https://movie.douban.com/j/chart/top_list"
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}
headers = { // Basic anti creep
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62"
}
resp = requests.get(url=url, params=param, headers=headers)
print(resp.json())
resp.close()
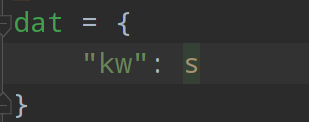
Crawl Baidu translation
import requests
url = 'https://fanyi.baidu.com/sug'
s = input()
dat = {
"kw": s
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62"
}
resp = requests.post(url, data=dat, headers=headers)
print(resp.json())
resp.close()
Data analysis
After using get or post to request the page source code, the next step is to analyze the source code and get the data we want.
There are three common methods of data analysis: regular expression, bs4 and Xpath
regular expression
Metacharacters: basic components of regular expressions
. Matches any character except the newline character \w Match letters or numbers or underscores \s Match any whitespace \d Match number \n Match a newline character \t Match a tab ^ Start of matching string $ Matches the end of the string Uppercase is the opposite of lowercase \W Matches non letters or numbers or underscores \S Match non whitespace \D Match non numeric a|b Match character a Or character b () Matches the expression in parentheses and also represents a group [...] Match characters in character group [a-z] Indicates a match a-z All characters of [A-Z0-9]Indicates a match A-Z And 0-9 All characters of [a-zA-Z0-9]Similarly [^...] Matches all characters except those in the character group
Quantifier: controls the number of times the preceding metacharacter appears
* Repeat zero or more times
+ Repeat one or more times
? Repeat zero or once
{n} repeat n second
{n,} repeat n Times or more
{n,m} repeat n reach m second
Greedy matching and inert matching
.* Greedy matching .*? Inert matching
re module
re.match(pattern, string, flags=0) re.match Try to match a pattern from the starting position of the string. If the matching is not successful, match() Just return none. re.search(pattern, string, flags=0) re.search Scans the entire string and returns the first successful match. re.compile(pattern, flags=0) compile Function is used to compile a regular expression and generate a regular expression( Pattern )Object, Offer match() ,search(), findall(), finditer()use. re.findall(pattern, string, flags=0) Find all substrings matched by the regular expression in the string and return a list. If there are multiple matching patterns, return a tuple list, If no match is found, an empty list is returned, be careful: match and search It's a match, findall Match all. re.finditer(pattern, string, flags=0) and findall Similarly, all substrings matched by the regular expression are found in the string and returned as an iterator.
The most commonly used is Finder ()
Example: climb Douban top 250
import requests
import re
import csv
url = "https://movie.douban.com/top250?start=0"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62"
}
resp = requests.get(url, headers=header) // Get web page source code
page_content = resp.text
# Analyze the data with regular matching and generate a regular expression (Pattern) object
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>', re.S)
# Start matching
result = obj.finditer(page_content) // Find all strings that match the pattern
f = open("data.csv", mode="a+", newline="") # newline = "" is added here to prevent more blank lines from being written to the file
csvwriter = csv.writer(f) // Create csv file writer
# Traversal iterator
for it in result:
dic = it.groupdict()
dic['year'] = dic['year'].strip() # Eliminate white space characters
csvwriter.writerow(dic.values()) # Write data csv
f.close()
print("OVER!")
bs4 parsing HTML syntax
bs4 is simpler than parsing HTML text using regular expressions.
Before that, you need to know some basic syntax of HTML.
HyperText Markup Language (HTML) is a standard markup language for creating web pages.
It is similar to some syntax of markdown. In short, it uses labels to modify the display mode, size, color, position and so on.
Basic labels:
-
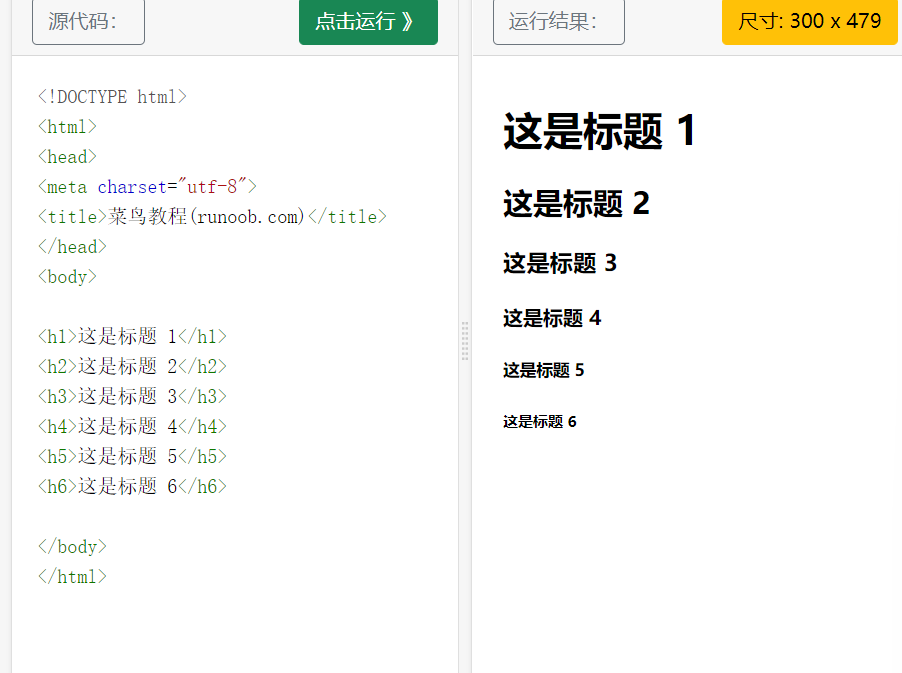
title
HTML Heading is through
-
Label.
<h1>This is a title</h1> <h2>This is a title</h2> <h3>This is a title</h3>
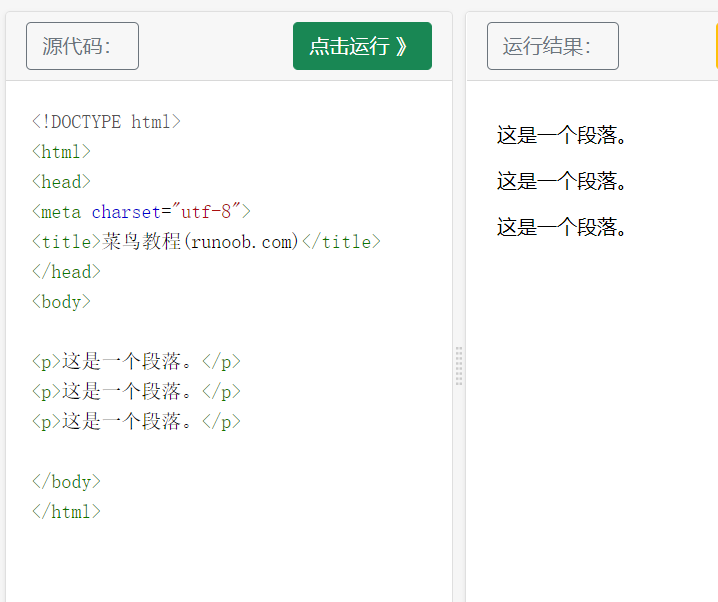
- HTML paragraph
HTML paragraphs are passed through tags
To define.
- HTML link
HTML links are defined by tags.
<a href="https://www.runoob. Com "> this is a link</a>
href specifies the address of the link.
-
HTML image
HTML images are defined by tags
<img src="/images/logo.png" width="258" height="39" />
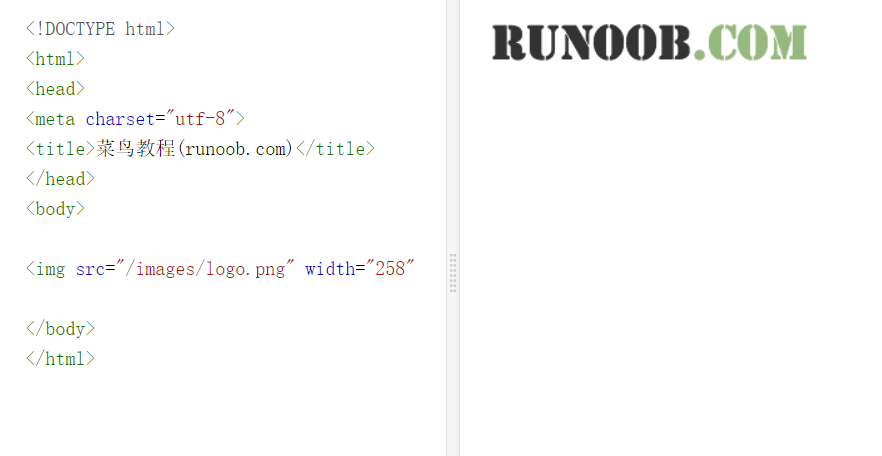
src is followed by the image address, and width and height are width and height -
HTML element
HTML documents are defined by HTML elements
An HTML element consists of a start tag element and a content end tag
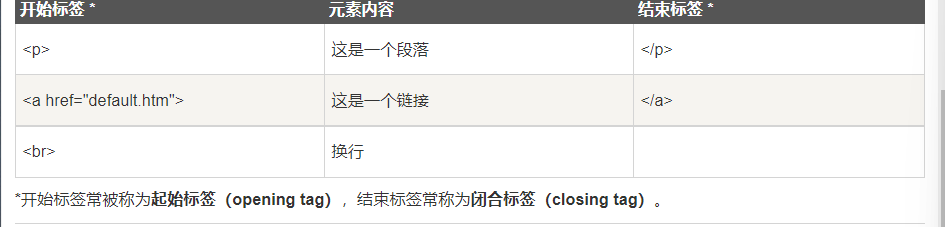
-
HTML element syntax
- HTML elements start with a start tag
- HTML elements terminate with end tags
- The content of the element is the content between the start tag and the end tag
- Some HTML elements have empty content
- Empty elements are closed in the start tag (ending at the end of the start tag)
- Most HTML elements can have attributes
-
HTML attributes
Attributes are additional information provided by HTML elements.For example:
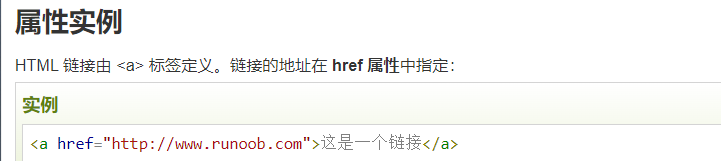
The herf attribute indicates the address of the link
In short, the general HTML syntax format is
<Label properties="Attribute value">
Marked content
</label>