Don't stay after the wind and the moon. The spring mountain is at the end of Pingwu.
Finally have time to update my blog!!
This time, let's climb Baidu Index.
1, Web page analysis
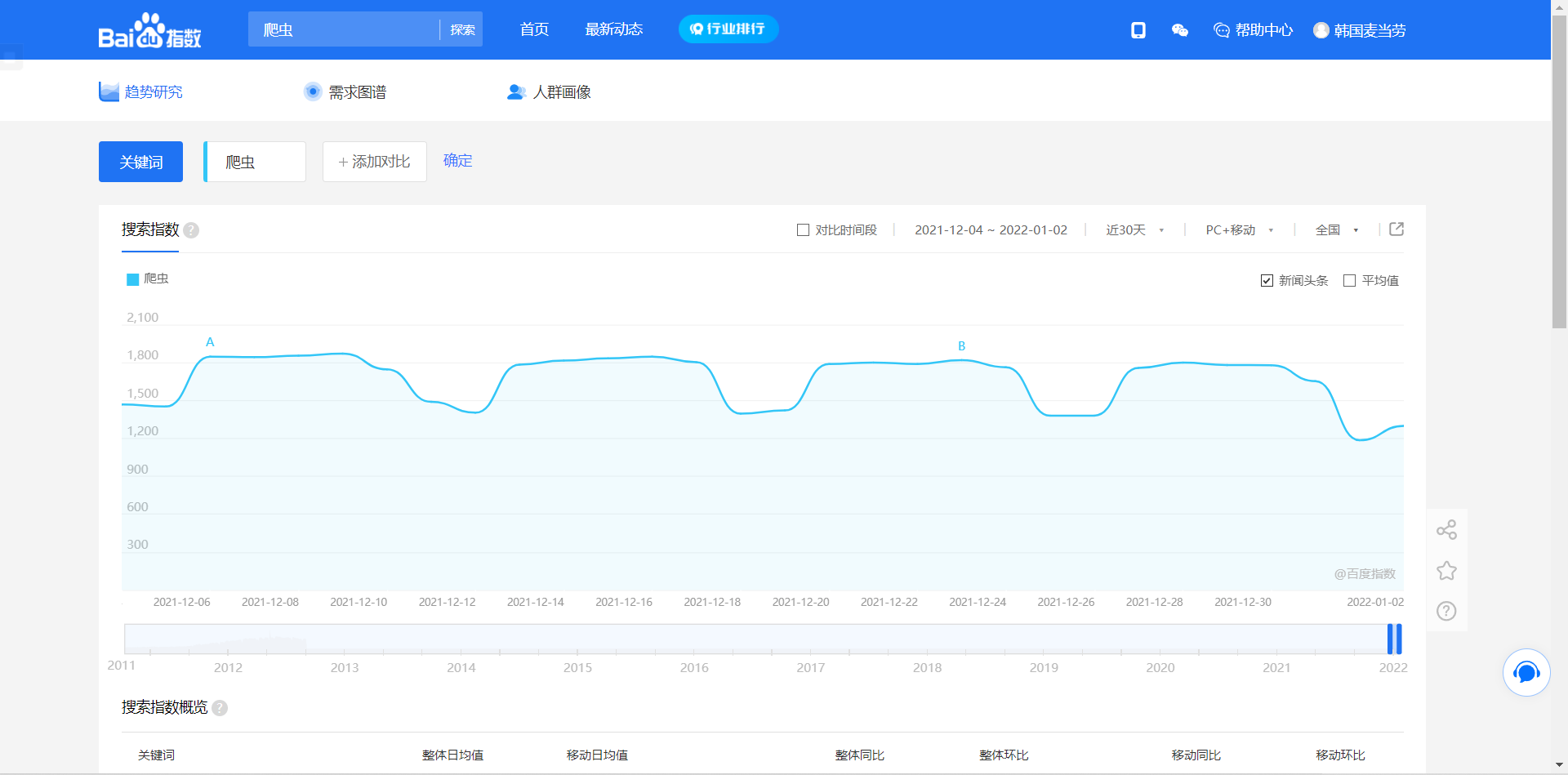
We take reptile as the keyword to analyze Baidu Index
Then, F12 developer mode, refresh, and click Network - > XHR - > index? area=0&word=... -> Preview, and then you'll see
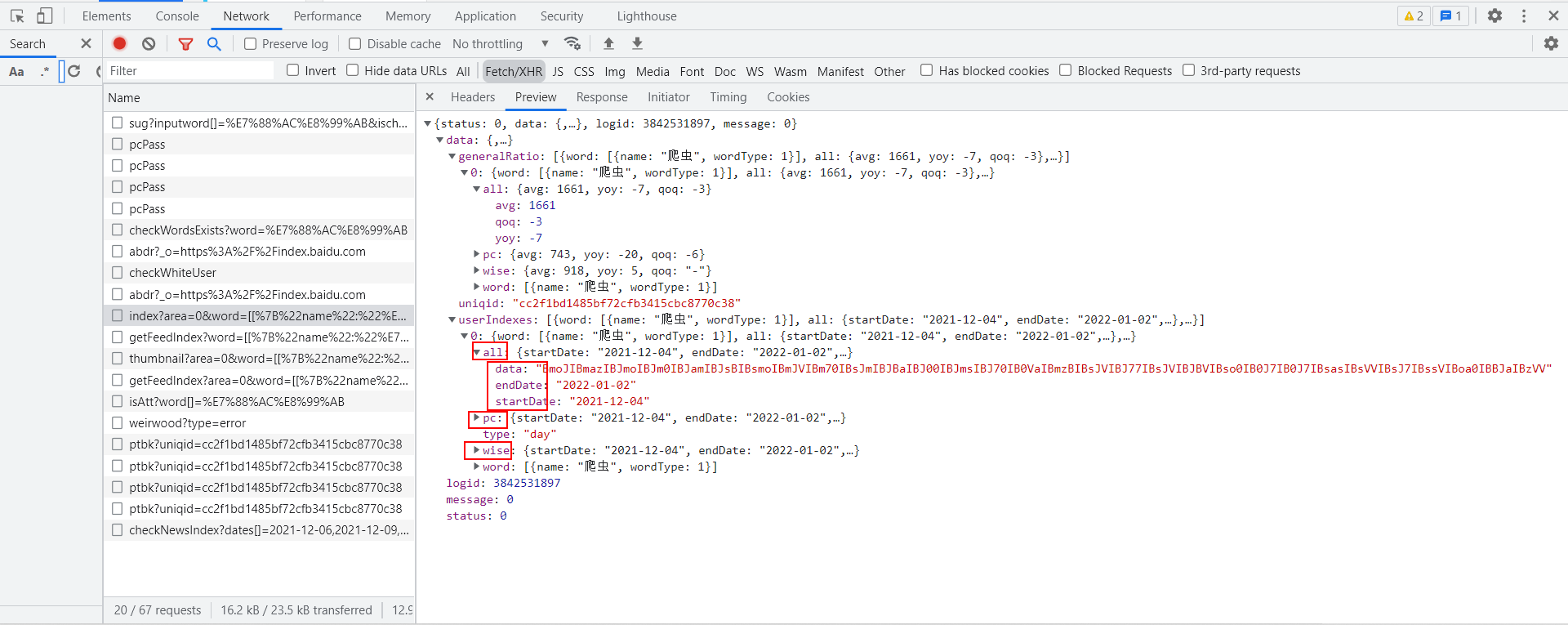
What are these? Obviously, the data is encrypted and bald.
First press the no watch, then look at the back.
2, Interface analysis
url analysis
https://index.baidu.com/api/SearchApi/index?area=0&word= [[% 7b% 22name% 22: crawler% 22,% 22wordtype% 22:1% 7d]] & & StartDate = 2011-01-02 & enddate = 2022-01-02
Obviously, he has three parameters:
- word
This parameter controls the keywords to be searched - startDate
This parameter represents the start time of the data - endDate
This parameter represents the end time of the data
If you can control these three parameters well, the data is easy to get!
Return data analysis
It is a get request, and the returned data format is json format, encoded as utf-8

3, Write code
Knowing the url rules and the format of the returned data, our task now is to construct the url and then request the data
url = "https://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22{}%22,%22wordType%22:1%7D]]&startDate=2011-01-02&endDate=2022-01-02".format(keyword)
Then go directly and ask him directly
So for convenience, we write the code to request the web page as the get function_ HTML (url), the passed in parameter is url, and the returned content is the requested content.
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Host": "index.baidu.com",
"Referer": "http://index.baidu.com/v2/main/index.html",
}
cookies = {
"Cookie": Yours cookie
}
response = requests.get(url, headers=headers, cookies=cookies)
return response.text
Note that you must replace your cookie here, or you won't be able to request the content.
Cookie acquisition method
get data
Format the obtained data into json format.
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Host": "index.baidu.com",
"Referer": "http://index.baidu.com/v2/main/index.html",
}
cookies = {
"Cookie": Yours cookie
}
response = requests.get(url, headers=headers, cookies=cookies)
return response.text
def get_data(keyword):
url = "https://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22{}%22,%22wordType%22:1%7D]]&startDate=2011-01-02&endDate=2022-01-02".format(keyword)
data = get_html(url)
data = json.lodas(data)
data = data['data']['userIndexes'][0]['all']['data']
ok, this is the end of the data acquisition. I'll see you next time. Bye~

Well, what about the encrypted data???
You can see that data should be encrypted, all represents all data, pc refers to the pc end, wise refers to the mobile end, which can be found in the js file; First, find out how the encrypted data is decrypted; We now know that this data is in json format, so it must take these data from it. Therefore, refresh the web page to make all js load out, and then use the search function to find them. The search process is not shown in the figure above. I found it by searching decrypt; First, I used decrypt to find a js file with a method called decrypt
decrypt
def decrypt(t,e):
n = list(t)
i = list(e)
a = {}
result = []
ln = int(len(n)/2)
start = n[ln:]
end = n[:ln]
for j,k in zip(start, end):
a.update({k: j})
for j in e:
result.append(a.get(j))
return ''.join(result)
You may feel that it has been solved, but you don't know what the parameter t is and how it came from. I won't take you to analyze it here. You can try to analyze it yourself. I directly say that the result is obtained by using uniqid to request another interface.
This t is actually called ptbk. GET the url of the ptbk: http://index.baidu.com/Interface/ptbk?uniqid= There is a parameter uniqid, GET request, and return json content
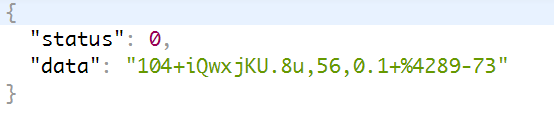
The data is t, and the data in all in the previous step is e
def get_ptbk(uniqid):
url = 'http://index.baidu.com/Interface/ptbk?uniqid={}'
resp = get_html(url.format(uniqid))
return json.loads(resp)['data']
Complete code
# -*- coding:utf-8 -*-
# @time: 2022/1/4 8:35
# @Author: Korean McDonald's
# @Environment: Python 3.7
import datetime
import requests
import sys
import time
import json
word_url = 'http://index.baidu.com/api/SearchApi/thumbnail?area=0&word={}'
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Host": "index.baidu.com",
"Referer": "http://index.baidu.com/v2/main/index.html",
}
cookies = {
'Cookie': Yours Cookie
}
response = requests.get(url, headers=headers, cookies=cookies)
return response.text
def decrypt(t, e):
n = list(t)
i = list(e)
a = {}
result = []
ln = int(len(n) / 2)
start = n[ln:]
end = n[:ln]
for j, k in zip(start, end):
a.update({k: j})
for j in e:
result.append(a.get(j))
return ''.join(result)
def get_ptbk(uniqid):
url = 'http://index.baidu.com/Interface/ptbk?uniqid={}'
resp = get_html(url.format(uniqid))
return json.loads(resp)['data']
def get_data(keyword, start='2011-01-02', end='2022-01-02'):
url = "https://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22{}%22,%22wordType%22:1%7D]]&startDate={}&endDate={}".format(keyword, start, end)
data = get_html(url)
data = json.loads(data)
uniqid = data['data']['uniqid']
data = data['data']['userIndexes'][0]['all']['data']
ptbk = get_ptbk(uniqid)
result = decrypt(ptbk, data)
result = result.split(',')
start = start_date.split("-")
end = end_date.split("-")
a = datetime.date(int(start[0]), int(start[1]), int(start[2]))
b = datetime.date(int(end[0]), int(end[1]), int(end[2]))
node = 0
for i in range(a.toordinal(), b.toordinal()):
date = datetime.date.fromordinal(i)
print(date, result[node])
node += 1
if __name__ == '__main__':
keyword = "Reptile"
start_date = "2011-01-02"
end_date = "2022-01-02"
get_data(keyword, start_date, end_date)
Welcome to triple CLICK!
Which website crawler do you want to see? Welcome to leave a message. Maybe what you want to analyze next time is what you want to see!