SuperSpider
==Ten thousand words long text, it is recommended to use the directory to click and consult, which is conducive to efficient development. Suggest like collection==
Request capture steps
[1]First determine whether to load the website dynamically [2]look for URL law [3]regular expression | xpath expression [4]Define the program framework, complete and test the code
- Key details: check whether the page code charset and verify=FALSE need to be verified during the request
Idea of multi-level page data capture
[1]Overall thinking
1.1> Crawl first level page,Extract required data+link,Follow up
1.2> Crawl secondary page,Extract required data+link,Follow up
1.3> ... ...
[2]Code implementation ideas
2.1> Avoid duplicate code - Functions to be defined for request and parsing
UserAgent anti crawling processing
[1]be based on User-Agent Reverse climbing
1.1) Send request carry request header: headers={'User-Agent' : 'Mozilla/5.0 xxxxxx'}
1.2) Random handoff in case of multiple requests User-Agent
a) definition py Large amount of documents User-Agent,Use after import random.choice()Every random selection
b) use fake_useragent The module is randomly generated every time it accesses User-Agent
from fake_useragent import UserAgent
agent = UserAgent().random
Details: pycharm Download in fake-useragent
[2]There are special characters in the response content
Used in decoding ignore parameter
html = requests.get(url=url, headers=headers).content.decode('', 'ignore')
Cookie anti crawl
Cookie parameter usage
-
Form of cookie parameter: Dictionary
Cookies = {"name of cookie": "value of cookie"}
- The dictionary corresponds to the Cookie string in the request header, and each pair of dictionary key value pairs is divided by semicolons and spaces
- To the left of the equal sign is the name of a cookie, which corresponds to the key of the cookie dictionary
- The right side of the equal sign corresponds to the value of the cookie dictionary
-
How to use cookie parameters
response = requests.get(url, cookies)
-
Dictionary required to convert cookie strings to cookie parameters:
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
-
Note: cookie s usually have expiration time. Once they expire, they need to be retrieved again
Convert CookieJar object to cookie dictionary
The reposne object obtained by using requests has the cookie attribute. The attribute value is a cookie jar type, which contains the cookies set locally by the other server. How can we convert it into a cookie dictionary?
-
Conversion method
cookies_dict = requests.utils.dict_from_cookiejar(response.cookies)
-
Where response Cookies return objects of type cookie jar
-
requests. utils. dict_ from_ The cookie jar function returns the cookie dictionary
Summary of requests module parameters
[1]Method 1 : requests.get()
[2]parameter
2.1) url
2.2) headers
2.3) timeout
2.4) proxies
[3]Method 2: requests.post()
[4]parameter
data
requests.get()
-
thinking
[1]url [2]proxies -> {} proxies = { 'http':'http://1.1.1.1:8888', 'https':'https://1.1.1.1:8888' } [3]timeout [4]headers [5]cookies
requests.post()
-
Applicable scenario
[1]Applicable scenario : Post Type requested web site [2]parameter : data={} 2.1) Form Form Data : Dictionaries 2.2) res = requests.post(url=url,data=data,headers=headers) [3]POST Request characteristics : Form Form submission data data : Dictionaries, Form Form Data -
Regular processing of headers and formdata in pycharm
[1]pycharm Entry method: Ctrl + r ,Select Regex [2]handle headers and formdata (.*): (.*) "$1": "$2", [3]click Replace All -
Classic Demo Youdao translation
request.session()
- The Session class in the requests module can automatically process the cookie s generated in the process of sending requests and obtaining responses, so as to maintain the state. Next, let's learn it
Role and application scenario
- requests. Role of session
- Automatically process cookies, that is, the next request will bring the previous cookie
- requests. Application scenario of session
- Automatically handle cookie s generated during successive multiple requests
usage method
After a session instance requests a website, the local Cookie Set by the other server will be saved in the session. The next time it uses the session to request the other server, it will bring the previous cookie
session = requests.session() # Instantiate session object response = session.get(url, headers, ...) response = session.post(url, data, ...)
- The parameters of the get or post request sent by the session object are exactly the same as those sent by the requests module
response
response.text and response The difference between content:
- response.text
- Type: str
- Decoding type: the requests module automatically infers the encoding of the response according to the HTTP header, and infers the text encoding
- response.content
- Type: bytes
- Decoding type: not specified
Dynamic load data grab Ajax
-
characteristic
[1]Right click -> There is no specific data in the web page source code [2]Load when scrolling mouse wheel or other actions,Or partial page refresh
-
Grab
[1]F12 Open the console, and the page action grabs the network packet [2]Grab json file URL address 2.1) In the console XHR : Asynchronously loaded packets 2.2) XHR -> QueryStringParameters(Query parameters)
-
Classic Demo: Douban movie
json parsing module
json.loads(json)
[1]effect : hold json Format string to Python data type [2]Examples : html = json.loads(res.text)
json.dump(python,f,ensure_ascii=False)
[1]effect
hold python Data type changed to json Formatted string,Generally let you save the captured data as json Use when file
[2]Parameter description
2.1) First parameter: python Type of data(Dictionaries, lists, etc)
2.2) Second parameter: File object
2.3) 3rd parameter: ensure_ascii=False Serialization time encoding
[3]Sample code
# Example 1
import json
item = {'name':'QQ','app_id':1}
with open('millet.json','a') as f:
json.dump(item,f,ensure_ascii=False)
# Example 2
import json
item_list = []
for i in range(3):
item = {'name':'QQ','id':i}
item_list.append(item)
with open('xiaomi.json','a') as f:
json.dump(item_list,f,ensure_ascii=False)
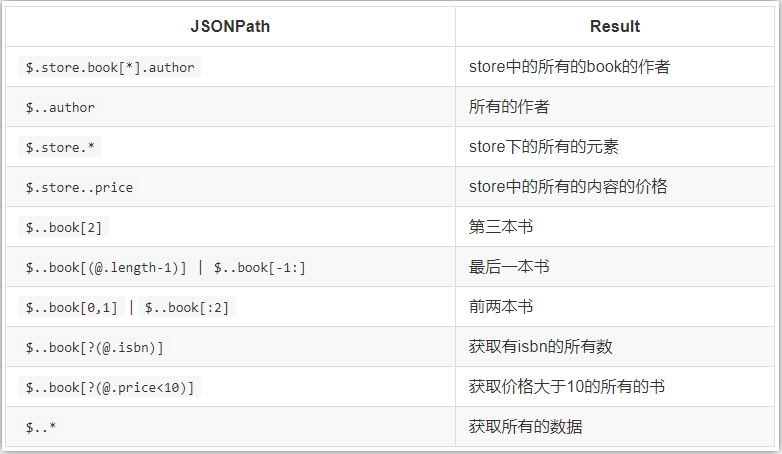
jsonpath
jsonpath usage example
book_dict = {
"store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
from jsonpath import jsonpath
print(jsonpath(book_dict, '$..author')) # If not, it will return False # Returns the list. If it is not available, it will return False
json module summary
# Reptiles are most commonly used
[1]Data capture - json.loads(html)
Change the response content from: json Turn into python
[2]Data saving - json.dump(item_list,f,ensure_ascii=False)
Save the captured data locally json file
# General processing method of grabbing data
[1]txt file
[2]csv file
[3]json file
[4]MySQL database
[5]MongoDB database
[6]Redis database
Console packet capture
-
Opening method and common options
[1]Open the browser, F12 Open the console and find Network tab [2]Common console options 2.1) Network: Grab network packets a> ALL: Grab all network packets b> XHR: Grab asynchronously loaded network packets c> JS : Grab all JS file 2.2) Sources: Format output and break point debugging JavaScript Code to help analyze some parameters in the crawler 2.3) Console: Interactive mode, you can JavaScript Test the code in [3]After capturing specific network packets 3.1) Click the network packet address on the left to enter the packet details and view the right 3.2) right: a> Headers: Entire request information General,Response Headers,Request Headers,Query String,Form Data b> Preview: Preview the response content c> Response: Response content
Proxy settings
Definition and classification
agent ip Degree of anonymity, proxy IP It can be divided into the following three categories:
1.Transparent agent(Transparent Proxy): Although transparent agents can directly "hide" your IP Address, but you can still find out who you are.
2.anonymous proxy (Anonymous Proxy): Using anonymous proxy, others can only know you used the proxy, but can't know who you are.
3.High concealment agent(Elite proxy or High Anonymity Proxy): High concealment agent makes it impossible for others to find that you are using an agent, so it is the best choice.
The protocols used for proxy service requests can be divided into:
1.http Proxy: target url by http agreement
2.https Proxy: target url by https agreement
3.socks Tunnel agent (e.g socks5 Agent, etc.:
socks The agent simply transmits data packets, and does not care about the application protocol( FTP,HTTP and HTTPS Etc.).
socks Agent ratio http,https Agent takes less time.
socks Agent can forward http and https Request for
General agency idea
[1]Get agent IP website
Western thorn agent, fast agent, whole network agent, agent wizard, Abu cloud and sesame agent... ...
[2]Parameter type
proxies = { 'agreement':'agreement://IP: port number '}
proxies = {
'http':'http://IP: port number ',
'https':'https://IP: port number ',
}
General agent
# Use free general proxy IP to access the test website: http://httpbin.org/get
import requests
url = 'http://httpbin.org/get'
headers = {'User-Agent':'Mozilla/5.0'}
# Define proxy and find free proxy IP in proxy IP website
proxies = {
'http':'http://112.85.164.220:9999',
'https':'https://112.85.164.220:9999'
}
html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
print(html)
Private agent + exclusive agent
[1]Grammatical structure
proxies = { 'agreement':'agreement://User name: password @ IP: port number '}
[2]Examples
proxies = {
'http':'http://User name: password @ IP: port number ',
'https':'https://User name: password @ IP: port number ',
}
Private agent + exclusive agent - example code
import requests
url = 'http://httpbin.org/get'
proxies = {
'http': 'http://309435365:szayclhp@106.75.71.140:16816',
'https':'https://309435365:szayclhp@106.75.71.140:16816',
}
headers = {
'User-Agent' : 'Mozilla/5.0',
}
html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
print(html)
Establish your own proxy IP pool - open proxy | private proxy
"""
Charging agent:
Establishment of agent IP pool
Idea:
1,Get open proxy
2,For each agent in turn IP Test,Save what you can use to a file
"""
import requests
class ProxyPool:
def __init__(self):
self.url = 'Proxy website API link'
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36'}
# Open the file to store the available proxy IP addresses
self.f = open('proxy.txt', 'w')
def get_html(self):
html = requests.get(url=self.url, headers=self.headers).text
proxy_list = html.split('\r\n')
for proxy in proxy_list:
# Test whether each proxy IP is available in turn
if self.check_proxy(proxy):
self.f.write(proxy + '\n')
def check_proxy(self, proxy):
"""Test 1 agent IP Available,Available return True,Otherwise return False"""
test_url = 'http://httpbin.org/get'
proxies = {
'http' : 'http://{}'.format(proxy),
'https': 'https://{}'.format(proxy)
}
try:
res = requests.get(url=test_url, proxies=proxies, headers=self.headers, timeout=2)
if res.status_code == 200:
print(proxy,'\033[31m available\033[0m')
return True
else:
print(proxy,'invalid')
return False
except:
print(proxy,'invalid')
return False
def run(self):
self.get_html()
# Close file
self.f.close()
if __name__ == '__main__':
spider = ProxyPool()
spider.run()
Dragonet Abu cloud agent
import json
import re
import time
import requests
import multiprocessing
from job_data_analysis.lagou_spider.handle_insert_data import lagou_mysql
class HandleLaGou(object):
def __init__(self):
#Using session to save cookie information
self.lagou_session = requests.session()
self.header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
self.city_list = ""
#How to get the list of all cities in the country
def handle_city(self):
city_search = re.compile(r'www\.lagou\.com\/.*\/">(.*?)</a>')
city_url = "https://www.lagou.com/jobs/allCity.html"
city_result = self.handle_request(method="GET",url=city_url)
#Get a list of cities using regular expressions
self.city_list = set(city_search.findall(city_result))
self.lagou_session.cookies.clear()
def handle_city_job(self,city):
first_request_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput="%city
first_response = self.handle_request(method="GET",url=first_request_url)
total_page_search = re.compile(r'class="span\stotalNum">(\d+)</span>')
try:
total_page = total_page_search.search(first_response).group(1)
print(city,total_page)
#exception due to lack of position information
except:
return
else:
for i in range(1,int(total_page)+1):
data = {
"pn":i,
"kd":"web"
}
page_url = "https://www.lagou.com/jobs/positionAjax.json?city=%s&needAddtionalResult=false"%city
referer_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput="%city
#The URL of the referer needs to be encode d
self.header['Referer'] = referer_url.encode()
response = self.handle_request(method="POST",url=page_url,data=data,info=city)
lagou_data = json.loads(response)
job_list = lagou_data['content']['positionResult']['result']
for job in job_list:
lagou_mysql.insert_item(job)
def handle_request(self,method,url,data=None,info=None):
while True:
#Join the dynamic agent of Abu cloud
proxyinfo = "http://%s:%s@%s:%s'% ('account', 'password', 'http-dyn.abuyun.com', '9020')
proxy = {
"http":proxyinfo,
"https":proxyinfo
}
try:
if method == "GET":
response = self.lagou_session.get(url=url,headers=self.header,proxies=proxy,timeout=6)
elif method == "POST":
response = self.lagou_session.post(url=url,headers=self.header,data=data,proxies=proxy,timeout=6)
except:
# You need to clear the cookie information first
self.lagou_session.cookies.clear()
# Retrieve cookie information
first_request_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput=" % info
self.handle_request(method="GET", url=first_request_url)
time.sleep(10)
continue
response.encoding = 'utf-8'
if 'frequently' in response.text:
print(response.text)
#You need to clear the cookie information first
self.lagou_session.cookies.clear()
# Retrieve cookie information
first_request_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput="%info
self.handle_request(method="GET",url=first_request_url)
time.sleep(10)
continue
return response.text
if __name__ == '__main__':
lagou = HandleLaGou()
#Methods for all cities
lagou.handle_city()
print(lagou.city_list)
#Introduce multi process accelerated crawl
pool = multiprocessing.Pool(2)
for city in lagou.city_list:
pool.apply_async(lagou.handle_city_job,args=(city,))
pool.close()
pool.join()
unicode and encode
-
unicode: it is used to convert unicode encoding into other encoded strings and unify all languages into unicode [if the content is English, the storage space of unicode encoding is twice that of ASCII, and the transmission needs twice as much transmission at the same time]
-
encode: it is used to convert unicode encoding into other encoded strings
-
decode: it is used to convert other encoded strings into unicode encoding, and the original encoding format needs to be specified
-
Code change:
s = ("I love China, i love china") s.decode("gb2312").encode("utf-8") -
View current code
import sys sys.getdefaultencoding()
-
-
Python 3 is encoded in unicode, so it can be encoded directly in unicode: s.encode("utf-8")
-
Usually, the window is encoded in GB2312
-
linux is usually encoded in utf8
Analysis module summary
re canonical analysis
import re
pattern = re.compile('regular expression ',re.S)
r_list = pattern.findall(html)
lxml+xpath parsing
from lxml import etree
p = etree.HTML(res.text)
r_list = p.xpath('xpath expression')
[Remember] just call xpath,The result must be'list'
xpath expression
-
Matching rules
[1]result: Node object list 1.1) xpath Examples: //div,//div[@class="student"],//div/a[@title="stu"]/span [2]result: String list 2.1) xpath The end of the expression is: @src,@href,/text()
-
Most commonly used
[1]benchmark xpath expression: Get a list of node objects [2]for r in [Node object list]: username = r.xpath('./xxxxxx') [[note] continue after traversal xpath Be sure to: . The beginning represents the current node -
Douban Book grab
import requests from lxml import etree from fake_useragent import UserAgent import time import random class DoubanBookSpider: def __init__(self): self.url = 'https://book.douban.com/top250?start={}' def get_html(self, url): """Use random User-Agent""" headers = {'User-Agent':UserAgent().random} html = requests.get(url=url, headers=headers).text self.parse_html(html) def parse_html(self, html): """lxml+xpath Data analysis""" parse_obj = etree.HTML(html) # 1. Benchmark xpath: extract the node object list of each book table_list = parse_obj.xpath('//div[@class="indent"]/table') for table in table_list: item = {} # title name_list = table.xpath('.//div[@class="pl2"]/a/@title') item['name'] = name_list[0].strip() if name_list else None # describe content_list = table.xpath('.//p[@class="pl"]/text()') item['content'] = content_list[0].strip() if content_list else None # score score_list = table.xpath('.//span[@class="rating_nums"]/text()') item['score'] = score_list[0].strip() if score_list else None # Number of evaluators nums_list = table.xpath('.//span[@class="pl"]/text()') item['nums'] = nums_list[0][1:-1].strip() if nums_list else None # category type_list = table.xpath('.//span[@class="inq"]/text()') item['type'] = type_list[0].strip() if type_list else None print(item) def run(self): for i in range(5): start = (i - 1) * 25 page_url = self.url.format(start) self.get_html(page_url) time.sleep(random.randint(1,2)) if __name__ == '__main__': spider = DoubanBookSpider() spider.run()
Data persistence
mysql
"""
sql Table creation
mysql -uroot -p
create database maoyandb charset utf8;
use maoyandb;
create table maoyantab(
name varchar(100),
star varchar(300),
time varchar(100)
)charset=utf8;
"""
"""
pymysql Module use
"""
import pymysql
# 1. Connect to the database
db = pymysql.connect(
'localhost','root','123456','maoyandb',charset='utf8'
)
cur = db.cursor()
# 2. Execute sql command
ins = 'insert into maoyantab values(%s,%s,%s)'
cur.execute(ins, ['The Shawshank Redemption','Starring: Zhang Guorong,Zhang Manyu,Lau Andy','2018-06-25'])
# 3. Submit to database for execution
db.commit()
cur.close()
db.close()
Mysql template
import pymysql
# __init__(self):
self.db = pymysql.connect('IP',... ...)
self.cursor = self.db.cursor()
# save_html(self,r_list):
self.cursor.execute('sql',[data1])
self.cursor.executemany('sql', [(),(),()])
self.db.commit()
# run(self):
self.cursor.close()
self.db.close()
mongodb
- https://www.runoob.com/python3/python-mongodb.html [rookie tutorial]
"""
[1]Non relational database,Data is stored in key value pairs, port 27017
[2]MongoDB Disk based storage
[3]MongoDB Single data type,Value is JSON file,and Redis Memory based,
3.1> MySQL Data type: numeric type, character type, date time type and enumeration type
3.2> Redis Data type: string, list, hash, set, ordered set
3.3> MongoDB Data type: value is JSON file
[4]MongoDB: library -> aggregate -> file
MySQL : library -> surface -> Table record
"""
"""
Linux get into: mongo
>show dbs - View all libraries
>use Library name - Switch Library
>show collections - View all collections in the current library
>db.Collection name.find().pretty() - View documents in collection
>db.Collection name.count() - Count the number of documents
>db.Collection name.drop() - Delete collection
>db.dropDatabase() - Delete current library
"""
import pymongo
# Create connection object
connect = pymongo.MongoClient(host='127.0.0.1',port=27017)
# Connect library objects
db = connect['maoyandb']
# Object collection creation
myset = db['maoyanset']
# Insert a single piece of data
# myset.insert_one({'name': 'money day'})
# Insert multiple pieces of data
myset.insert_many[{'name':'Zhang San'},{'name':'Li Si'},{'name':'Wang Wu'}]
mongodb template
import requests
import re
import time
import random
import pymongo
class MaoyanSpider:
def __init__(self):
self.url = 'https://maoyan.com/board/4?offset={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36'}
# Three objects: connection object, library object and library collection
self.conn = pymongo.MongoClient('127.0.0.1',27017)
self.db = self.conn['maoyandb']
self.myset = self.db['maoyanset']
##Extract web page data
def get_html(self,url):
html = requests.get(url,url,headers=self.headers).text
self.parse_html(html)
##Parsing web data
def parse_html(self,html):
regex = '<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>'
pattern = re.compile(regex,re.S)
r_list = pattern.findall(html)
self.save_html(r_list)
## Data processing and extraction
def save_html(self,r_list):
for r in r_list:
item ={}
item['name'] = r[0].strip()
item['star'] = r[1].strip()
item['time'] = r[2].strip()
print(item)
# Save to mongodb database
self.myset.insert_one(item)
def run(self):
"""Program entry function"""
for offset in range(0, 91, 10):
url = self.url.format(offset)
self.get_html(url=url)
# Control the frequency of data fetching: uniform() generates floating-point numbers within the specified range
time.sleep(random.uniform(0, 1))
if __name__ == '__main__':
spider = MaoyanSpider()
spider.run()
Json
import json
# Demo1
item = {'name':'QQ','e-mail':99362}
with open('qq.json','a')as f:
json.dump(item,f,ensure_ascii=False)
# Demo2
# import json
# item_list =[]
# for i in range(3):
# item = {'name':'QQ','e-mail':'99362'}
# item_list.append(item)
#
# with open('demo2.json','a')as f:
# json.dump(item_list,f,ensure_ascii=False)
Jason template
import requests
from fake_useragent import UserAgent
import time
import random
import re
import json
# Douban movie full stack capture
class DoubanSpider:
def __init__(self):
self.url = 'https://movie.douban.com/j/chart/top_list?'
self.i = 0
# Save json file
self.f = open('douban.json', 'w', encoding='utf-8')
self.all_film_list = []
def get_agent(self):
"""Get random User-Agent"""
return UserAgent().random
def get_html(self, params):
headers = {'User-Agent':self.get_agent()}
html = requests.get(url=self.url, params=params, headers=headers).text
# Convert the string in json format to python data type
html = json.loads(html)
self.parse_html(html)
def parse_html(self, html):
"""analysis"""
# html: [{},{},{},{}]
item = {}
for one_film in html:
item['rank'] = one_film['rank']
item['title'] = one_film['title']
item['score'] = one_film['score']
print(item)
self.all_film_list.append(item)
self.i += 1
def run(self):
# d: 'romantic comedy', '{:' 5 ','...} '
d = self.get_d()
# 1. Prompt the user to choose
menu = ''
for key in d:
menu += key + '|'
print(menu)
choice = input('Please enter movie category:')
if choice in d:
code = d[choice]
# 2. Total: total number of movies
total = self.get_total(code)
for start in range(0,total,20):
params = {
'type': code,
'interval_id': '100:90',
'action': '',
'start': str(start),
'limit': '20'
}
self.get_html(params=params)
time.sleep(random.randint(1,2))
# Store data in json file
json.dump(self.all_film_list, self.f, ensure_ascii=False)
self.f.close()
print('quantity:',self.i)
else:
print('Please make the right choice')
def get_d(self):
"""{'plot':'11','love':'13','comedy':'5',...,...}"""
url = 'https://movie.douban.com/chart'
html = requests.get(url=url,headers={'User-Agent':self.get_agent()}).text
regex = '<span><a href=".*?type_name=(.*?)&type=(.*?)&interval_id=100:90&action=">'
pattern = re.compile(regex, re.S)
# r_list: [('plot', '11'), ('comedy ',' 5 '), ('Love':'13 ')...]
r_list = pattern.findall(html)
# d: {'plot':'11 ',' love ':'13', 'comedy':'5 ',...,...}
d = {}
for r in r_list:
d[r[0]] = r[1]
return d
def get_total(self, code):
"""Gets the total number of movies in a category"""
url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(code)
html = requests.get(url=url,headers={'User-Agent':self.get_agent()}).text
html = json.loads(html)
return html['total']
if __name__ == '__main__':
spider = DoubanSpider()
spider.run()
json common operations
import json
data = {
'name': 'pengjunlee',
'age': 32,
'vip': True,
'address': {'province': 'GuangDong', 'city': 'ShenZhen'}
}
# Convert Python dictionary type to JSON object
json_str = json.dumps(data)
print(json_str) # Results {"name": "pengjunlee", "age": 32, "vip": true, "address": {"province": "GuangDong", "city": "ShenZhen"}}
# Converting JSON object types to Python Dictionaries
user_dic = json.loads(json_str)
print(user_dic['address']) # Result {'province':'guangdong ',' city ':'shenzhen'}
# Output Python dictionary directly to file
with open('pengjunlee.json', 'w', encoding='utf-8') as f:
json.dump(user_dic, f, ensure_ascii=False, indent=4)
# Converts the JSON string in the class file object directly to a Python dictionary
with open('pengjunlee.json', 'r', encoding='utf-8') as f:
ret_dic = json.load(f)
print(type(ret_dic)) # Results < class' dict '>
print(ret_dic['name']) # Result pengjunlee
json storage list
import json
all_app_list = [
{'name':'QQ'},
{'name':'Glory of Kings'},
{'name':'Game for Peace'}
]
with open('xiaomi.json', 'w') as f:
json.dump(all_app_list, f, ensure_ascii=False)
CSV template
import csv
from urllib import request, parse
import re
import time
import random
class MaoyanSpider(object):
def __init__(self):
self.url = 'https://maoyan.com/board/4?offset={}'
# count
self.num = 0
def get_html(self, url):
headers = {
'user-agent': 'Mozilla / 5.0(Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# Call parsing function directly
self.parse_html(html)
def parse_html(self, html):
# Create regular compilation objects
re_ = '<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p> '
pattern = re.compile(re_, re.S)
# film_list: [('Farewell My Concubine', 'Zhang Guorong', '1993')]
film_list = pattern.findall(html)
self.write_html(film_list)
# Save to csv file - writerows
def write_html(self, film_list):
L = []
with open('maoyanfilm.csv', 'a',newline='') as f:
# Initialize the write object. Note that the parameter f cannot be forgotten
writer = csv.writer(f)
for film in film_list:
t = (
film[0].strip(),
film[1].strip(),
film[2].strip()[5:15]
)
self.num += 1
L.append(t)
# The writerow() parameter is a list
writer.writerows(L)
print(L)
def main(self):
for offset in range(0, 91, 10):
url = self.url.format(offset)
self.get_html(url)
time.sleep(random.randint(1, 2))
print('Grab data together', self.num, "Department")
if __name__ == '__main__':
start = time.time()
spider = MaoyanSpider()
spider.main()
end = time.time()
print('execution time:%.2f' % (end - start))
txt template
Note: if you need to wrap a line, you should add it to the write content yourself \ n
- Single line write
# Write in binary mode
f = open("write.txt","wb")
# Append in binary mode
# f = open("write.txt","ab")
# write in
res = f.write(b"Big Bang Bang\n")
print(res)
res = f.write(b"Big Bang Bang\n")
print(res)
#close
f.close()
- Multiline write
f = open("write.txt","w")
# Write information
msg = f.writelines(["Hello","I'm fine","That's good"])
# close
f.close()
Implementation of redis incremental URl crawler
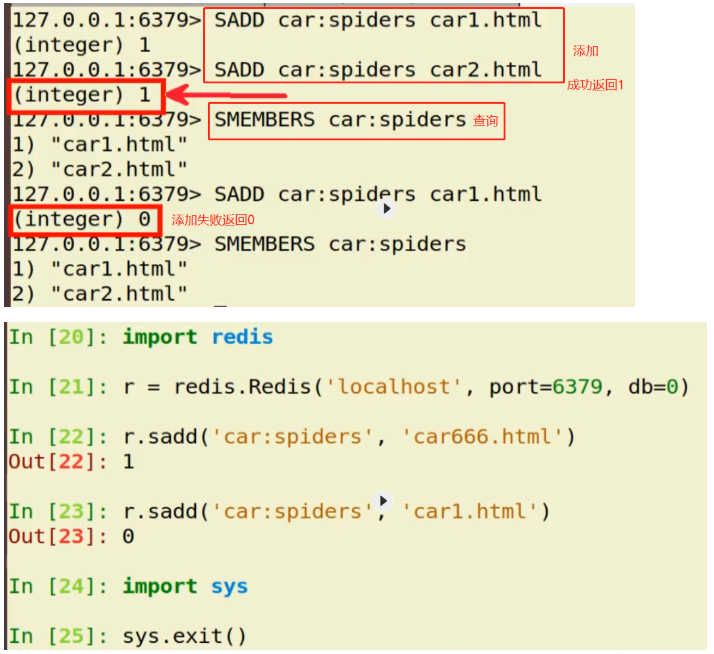
[1]principle
utilize Redis Collection feature, which can add the captured fingerprint to redis In the collection, whether to grab is determined according to the return value
The return value is 1: it means that it has not been captured before and needs to be captured
The return value is 0: it means that it has been crawled and there is no need to crawl again
hash Encryption: md5 32 Bit sha1 40 position
establish md5 object
use update take href Turn into byte type
Finally passed hexdigest Get password
[2]Code implementation template
import redis
from hashlib import md5
import sys
class XxxIncrSpider:
def __init__(self):
self.r = redis.Redis(host='localhost',port=6379,db=0)
def url_md5(self,url):
"""yes URL conduct md5 Encryption function"""
s = md5()
s.update(url.encode())
return s.hexdigest()
def run_spider(self):
href_list = ['url1','url2','url3','url4']
for href in href_list:
href_md5 = self.url_md5(href)
if self.r.sadd('spider:urls',href_md5) == 1:
A return value of 1 indicates that the addition is successful, that is, if it has not been crawled before, it starts to crawl
else:
sys.exit()
Sleep settings
# Control data capture frequency: uniform() generates floating-point numbers within the specified range time.sleep(random.uniform(2,5)) # Generate a shaped array time.sleep(random.randint(1,2))
Time parameter
import datetime
timestape = str(datetime.datetime.now()).split(".")[0]
Coding platform
- Atlas
- Super Eagle
Cloud words
import os,time,json,random,jieba,requests
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# Word cloud shape picture
WC_MASK_IMG = 'wawa.jpg'
# Comment data save file
COMMENT_FILE_PATH = 'jd_comment.txt'
# Word cloud font
WC_FONT_PATH = '/Library/Fonts/Songti.ttc'
def spider_comment(page=0):
"""
Crawl the evaluation data of JD specified page
:param page: The default value is 0
"""
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4646&productId=1263013576&score=0&sortType=5&page=%s&pageSize=10&isShadowSku=0&fold=1' % page
kv = {'user-agent': 'Mozilla/5.0', 'Referer': 'https://item.jd.com/1263013576.html'}
# proxies = {
# '1.85.5.66':'8060',
# '171.11.178.223':'9999',
# '120.194.42.157':'38185',
# '161.35.4.201':'80',
# '175.42.123.196':'9999',
# }
try:
r = requests.get(url, headers=kv)#,proxies=proxies
r.raise_for_status()
except:
print('Crawl failed')
# Intercept json data string
r_json_str = r.text[26:-2]
# String to json object
r_json_obj = json.loads(r_json_str)
# Get evaluation list data
r_json_comments = r_json_obj['comments']
# Traverse the list of comment objects
for r_json_comment in r_json_comments:
# Wrap each comment in append mode
with open(COMMENT_FILE_PATH, 'a+') as file:
file.write(r_json_comment['content'] + '\n')
# Print comment content in comment object
print(r_json_comment['content'])
def batch_spider_comment():
"""
Batch crawling evaluation
"""
# Clear the previous data before writing data
if os.path.exists(COMMENT_FILE_PATH):
os.remove(COMMENT_FILE_PATH)
for i in range(3):
spider_comment(i)
# Simulate user browsing and set a crawler interval to prevent ip from being blocked
time.sleep(random.random() * 5)
def cut_word():
"""
Data segmentation
:return: Data after word segmentation
"""
with open(COMMENT_FILE_PATH) as file:
comment_txt = file.read()
wordlist = jieba.cut(comment_txt, cut_all=True)
wl = " ".join(wordlist)
print(wl)
return wl
def create_word_cloud():
"""
Generate word cloud
:return:
"""
# Set word cloud shape picture
wc_mask = np.array(Image.open(WC_MASK_IMG))
# Set some configurations of word cloud, such as font, background color, word cloud shape and size
wc = WordCloud(background_color="white", max_words=2000, mask=wc_mask, scale=4,
max_font_size=50, random_state=42, font_path=WC_FONT_PATH)
# Generate word cloud
wc.generate(cut_word())
# If you only set the mask, you will get a word cloud with picture shape
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.figure()
plt.show()
if __name__ == '__main__':
# Crawling data
batch_spider_comment()
# Generate word cloud
create_word_cloud()
Multithreaded crawler
Application scenario
[1]Multi process: CPU Intensive program [2]Multithreading: crawler(network I/O),Local disk I/O
Multithreaded crawler example [watercress]
# Capture movie information under Douban movie plot category
"""
Douban film - plot - Grab
"""
import requests
from fake_useragent import UserAgent
import time
import random
from threading import Thread,Lock
from queue import Queue
class DoubanSpider:
def __init__(self):
self.url = 'https://movie.douban.com/j/chart/top_list?type=13&interval_id=100%3A90&action=&start={}&limit=20'
self.i = 0
# Queue + lock
self.q = Queue()
self.lock = Lock()
def get_agent(self):
"""Get random User-Agent"""
return UserAgent().random
def url_in(self):
"""Take everything you want to grab URL Address in queue"""
for start in range(0,684,20):
url = self.url.format(start)
# url in queue
self.q.put(url)
# Thread event function: request + parsing + data processing
def get_html(self):
while True:
# Get URL address from queue
# Judge whether there is only one address left in the queue when get() and get() are empty
self.lock.acquire()
if not self.q.empty():
headers = {'User-Agent': self.get_agent()}
url = self.q.get()
self.lock.release()
html = requests.get(url=url, headers=headers).json()
self.parse_html(html)
else:
# If the queue is empty, the lock must eventually be released
self.lock.release()
break
def parse_html(self, html):
"""analysis"""
# html: [{},{},{},{}]
item = {}
for one_film in html:
item['rank'] = one_film['rank']
item['title'] = one_film['title']
item['score'] = one_film['score']
print(item)
# Lock + release lock
self.lock.acquire()
self.i += 1
self.lock.release()
def run(self):
# Put the URL address into the queue first
self.url_in()
# Create multiple threads and get started
t_list = []
for i in range(1):
t = Thread(target=self.get_html)
t_list.append(t)
t.start()
for t in t_list:
t.join()
print('quantity:',self.i)
if __name__ == '__main__':
start_time = time.time()
spider = DoubanSpider()
spider.run()
end_time = time.time()
print('execution time:%.2f' % (end_time-start_time))
selenium+PhantomJS/Chrome/Firefox
selenium
[1]definition
1.1) GPl Web Automated test tools
[2]purpose
2.1) yes Web Functional test of the system,Avoid repetitive work during version iteration
2.2) Compatibility test(test web Whether the program runs normally in different operating systems and different browsers)
2.3) yes web The system is tested in large quantities
[3]characteristic
3.1) The browser can be manipulated according to instructions
3.2) It is only a tool and must be used in combination with a third-party browser
[4]install
4.1) Linux: sudo pip3 install selenium
4.2) Windows: python -m pip install selenium
Bypass selenium detection
from selenium import webdriver
options = webdriver.ChromeOptions()
# This step is very important. Set it to the developer mode to prevent being recognized by major websites for using Selenium
options.add_experimental_option('excludeSwitches', ['enable-automation'])
#Stop loading pictures
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
browser = webdriver.Chrome(options=options)
browser.get('https://www.taobao.com/')
selenium's handling of cookie s
selenium can help us deal with cookie s in the page, such as obtaining and deleting. Next, we will learn this knowledge
Get cookie
driver.get_cookies() returns a list containing complete cookie information! There are not only name and value, but also cookies such as domain and other dimensions of information. Therefore, if you want to use the obtained cookie information with the requests module, you need to convert it into a cookie dictionary with name and value as key value pairs
# Get all cookie information of the current tab
print(driver.get_cookies())
# Convert cookie s into Dictionaries
cookies_dict = {cookie['name']: cookie['value'] for cookie in driver.get_cookies()}
delete cookie
#Delete a cookie
driver.delete_cookie("CookieName")
# Delete all cookie s
driver.delete_all_cookies()
selenium uses proxy ip
selenium control browser can also use proxy ip!
-
Method of using proxy ip
- Instantiate configuration object
- options = webdriver.ChromeOptions()
- The configuration object adds commands that use proxy ip
- options.add_argument('--proxy-server=http://202.20.16.82:9527')
- Instantiate the driver object with the configuration object
- driver = webdriver.Chrome('./chromedriver', chrome_options=options)
- Instantiate configuration object
-
Reference codes are as follows:
from selenium import webdriver options = webdriver.ChromeOptions() # Create a configuration object options.add_argument('--proxy-server=http://202.20.16.82:9527 ') # using proxy ip driver = webdriver.Chrome(chrome_options=options) # Instantiate the driver object with configuration driver.get('http://www.itcast.cn') print(driver.title) driver.quit()
selenium replaces user agent
When selenium controls Google browser, the user agent defaults to Google browser. In this section, we will learn to use different user agents
-
Method of replacing user agent
- Instantiate configuration object
- options = webdriver.ChromeOptions()
- Add and replace UA command for configuration object
- options.add_argument('--user-agent=Mozilla/5.0 HAHA')
- Instantiate the driver object with the configuration object
- driver = webdriver.Chrome('./chromedriver', chrome_options=options)
- Instantiate configuration object
-
Reference codes are as follows:
from selenium import webdriver options = webdriver.ChromeOptions() # Create a configuration object options.add_argument('--user-agent=Mozilla/5.0 HAHA') # Replace user agent driver = webdriver.Chrome('./chromedriver', chrome_options=options) driver.get('http://www.itcast.cn') print(driver.title) driver.quit()
- selenium replaces user agent
Specify port remote control
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option('debuggerAddress','127.0.0.1:9222')
browser=webdriver.Chrome(executable_path=r'C:\Users\TR\AppData\Local\Google\Chrome
\Application\chromedriver.exe',chrome_options=chrome_options)
browser.get('http://www.zhihu.com')
Phantom JS browser
[1]definition
phantomjs No interface browser(Also known as headless browser),Page loading in memory,Efficient
[2]Download address
2.1) chromedriver : Download the corresponding version
http://npm.taobao.org/mirrors/chromedriver/
2.2) geckodriver
https://github.com/mozilla/geckodriver/releases
2.3) phantomjs
https://phantomjs.org/download.html
[3]Ubuntu install
3.1) Unzip after downloading : tar -zxvf geckodriver.tar.gz
3.2) Copy the extracted file to /usr/bin/ (Add environment variable)
sudo cp geckodriver /usr/bin/
3.3) Add executable permissions
sudo chmod 777 /usr/bin/geckodriver
[4]Windows install
4.1) Download the corresponding version of phantomjs,chromedriver,geckodriver
4.2) hold chromedriver.exe copy to python Of the installation directory Scripts Under the directory(Add to system environment variable)
# View python installation path: where python
4.3) verification
cmd command line: chromedriver
***************************summary**************************************
[1]decompression - Put in user home directory(chromedriver,geckodriver,phantomjs)
[2]Copy - sudo cp /home/tarena/chromedriver /usr/bin/
[3]jurisdiction - sudo chmod 777 /usr/bin/chromedriver
# verification
[Ubuntu | Windows]
ipython3
from selenium import webdriver
webdriver.Chrome()
perhaps
webdriver.Firefox()
[mac]
ipython3
from selenium import webdriver
webdriver.Chrome(executable_path='/Users/xxx/chromedriver')
perhaps
webdriver.Firefox(executable_path='/User/xxx/geckodriver')
Baidu sample code
"""Example code 1: use selenium+Open Baidu browser"""
# Import the webdriver interface of seleinum
from selenium import webdriver
import time
# Create browser object
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
# Close the browser after 5 seconds
time.sleep(5)
browser.quit()
"""Example code 2: open Baidu, search Zhao Liying, click search and view"""
from selenium import webdriver
import time
# 1. Create browser object - the browser has been opened
browser = webdriver.Chrome()
# 2. Input: http://www.baidu.com/
browser.get('http://www.baidu.com/')
# 3. Find the search box and send the text to this node: Zhao Liying
browser.find_element_by_xpath('//*[@id="kw"]').send_keys('zhao Liying ')
# 4. Find the baidu button and click it
browser.find_element_by_xpath('//*[@id="su"]').click()
Browser object method
[1]browser.get(url=url) - Address field input url Address and confirm
[2]browser.quit() - Close browser
[3]browser.close() - Close current page
[4]browser.page_source - HTML Structure source code
[5]browser.page_source.find('character string')
from html Search the specified string in the source code,Return not found:-1,Often used to determine whether it is the last page
[6]browser.maximize_window() - Maximize browser window
Eight methods of Selenium locating nodes
[1]Single element search('The result is 1 node object')
1.1) [[most commonly used] browser.find_element_by_id('id Attribute value')
1.2) [[most commonly used] browser.find_element_by_name('name Attribute value')
1.3) [[most commonly used] browser.find_element_by_class_name('class Attribute value')
1.4) [[the most versatile] browser.find_element_by_xpath('xpath expression')
1.5) [matching a Node [common] browser.find_element_by_link_text('Link text')
1.6) [matching a Node [common] browser.find_element_by_partical_link_text('Partial link text')
1.7) [Most useless] browser.find_element_by_tag_name('Tag name')
1.8) [[more commonly used] browser.find_element_by_css_selector('css expression')
[2]Multi element search('The result is[Node object list]')
2.1) browser.find_elements_by_id('id Attribute value')
2.2) browser.find_elements_by_name('name Attribute value')
2.3) browser.find_elements_by_class_name('class Attribute value')
2.4) browser.find_elements_by_xpath('xpath expression')
2.5) browser.find_elements_by_link_text('Link text')
2.6) browser.find_elements_by_partical_link_text('Partial link text')
2.7) browser.find_elements_by_tag_name('Tag name')
2.8) browser.find_elements_by_css_selector('css expression')
Cat's eye movie example
from selenium import webdriver
import time
url = 'https://maoyan.com/board/4'
browser = webdriver.Chrome()
browser.get(url)
def get_data():
# Benchmark XPath: [< selenium XXX Li at XXX >, < selenium XXX Li at >]
li_list = browser.find_elements_by_xpath('//*[@id="app"]/div/div/div[1]/dl/dd')
for li in li_list:
item = {}
# info_list: ['1', 'Farewell My Concubine', 'Starring: Zhang Guorong', 'release time: January 1, 1993', '9.5']
info_list = li.text.split('\n')
item['number'] = info_list[0]
item['name'] = info_list[1]
item['star'] = info_list[2]
item['time'] = info_list[3]
item['score'] = info_list[4]
print(item)
while True:
get_data()
try:
browser.find_element_by_link_text('next page').click()
time.sleep(2)
except Exception as e:
print('congratulations!Grab end')
browser.quit()
break
-
Node object operation
[1]Text box operation 1.1) node.send_keys('') - Send content to text box 1.2) node.clear() - Empty text 1.3) node.get_attribute('value') - Get text content [2]Button operation 1.1) node.click() - click 1.2) node.is_enabled() - Determine whether the button is available 1.3) node.get_attribute('value') - Get button text
chromedriver set no interface mode
from selenium import webdriver
options = webdriver.ChromeOptions()
# Add no interface parameters
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
selenium - mouse operation
from selenium import webdriver
# Import mouse event class
from selenium.webdriver import ActionChains
driver = webdriver.Chrome()
driver.get('http://www.baidu.com/')
# When moving to the setting, perform() is the real operation, and there must be
element = driver.find_element_by_xpath('//*[@id="u1"]/a[8]')
ActionChains(driver).move_to_element(element).perform()
# Click to pop up the Ajax element and find it according to the text content of the link node
driver.find_element_by_link_text('Advanced search').click()
selenium handles iframe backcrawl
- Classic cases: Civil Affairs Bureau capture, QQ email login, 163 email login
[1]Mouse operation
from selenium.webdriver import ActionChains
ActionChains(browser).move_to_element(node).perform()
[2]Switch handle
all_handles = browser.window_handles
time.sleep(1)
browser.switch_to.window(all_handles[1])
[3]iframe Subframe
browser.switch_to.frame(iframe_element)
# Script 1 - any scene can:
iframe_node = browser.find_element_by_xpath('')
browser.switch_to.frame(iframe_node)
# Writing 2 - two attribute values of id and name are supported by default:
browser.switch_to.frame('id Attribute value|name Attribute value')