python crawler - requests+xpath crawling 8684 bus query website
Posted by renojim on Thu, 13 Feb 2020 20:39:33 +0100
1, Analysis website
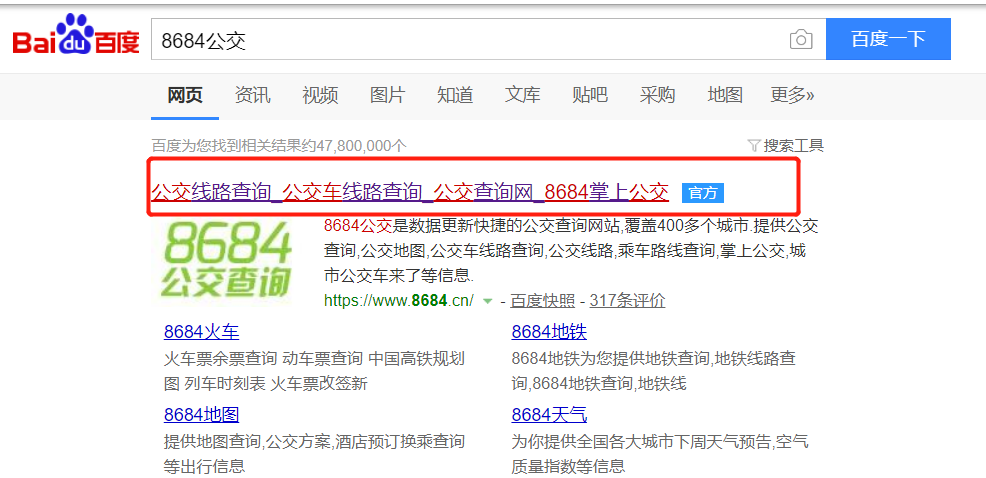
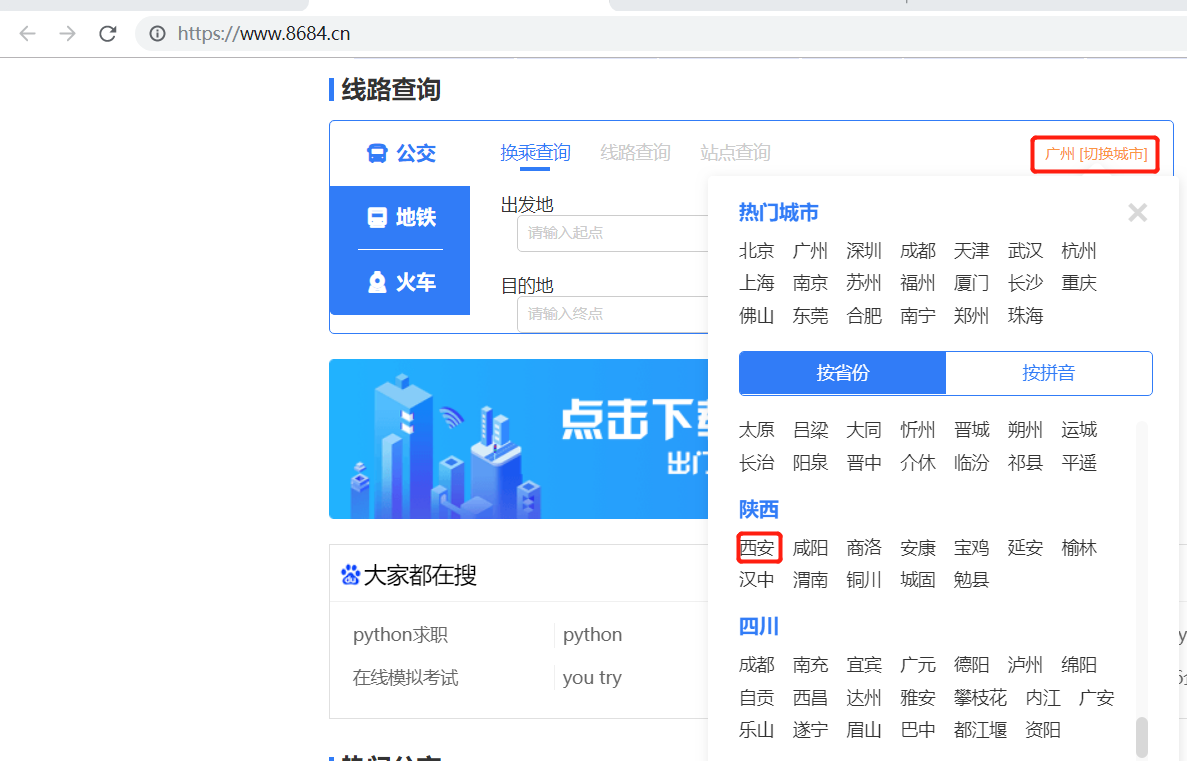
url = 'http://xian.8684.cn/'
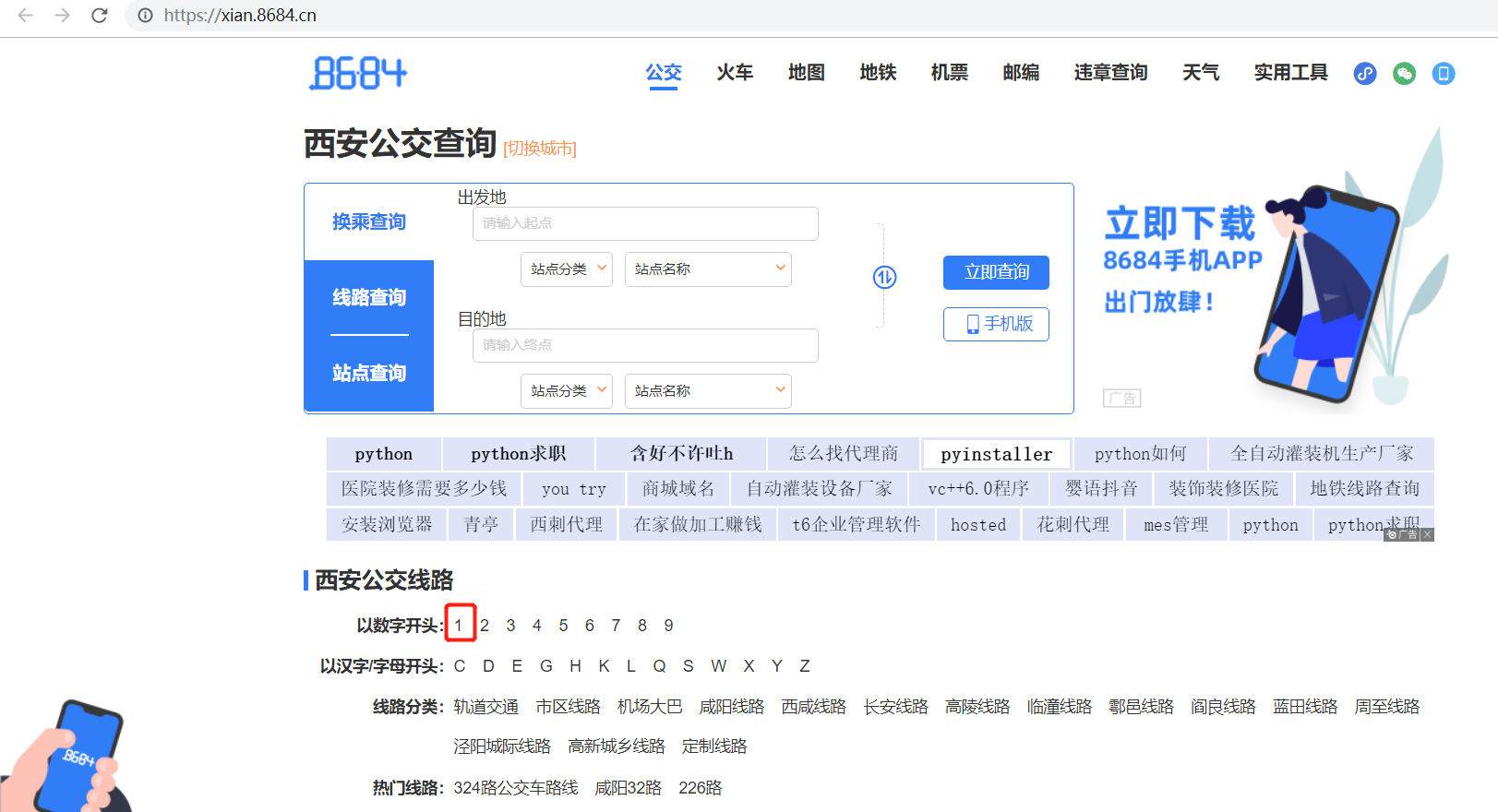
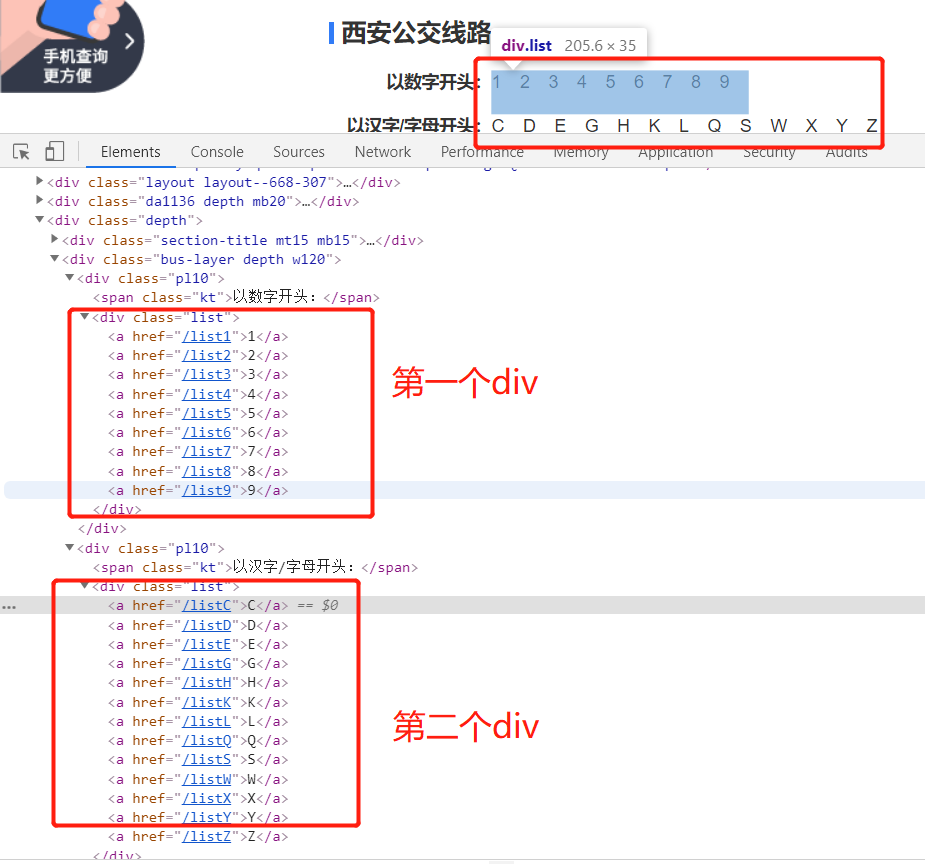
1. Route xpath of the second layer:
number_href_list = tree.xpath('//div[@class="list"][1]/a/@href')
char_href_list = tree.xpath('//div[@class="list"][2]/a/@href')
2. Exact route xpath:
route_list = tree.xpath('//div[@class="list clearfix"]/a/@href')
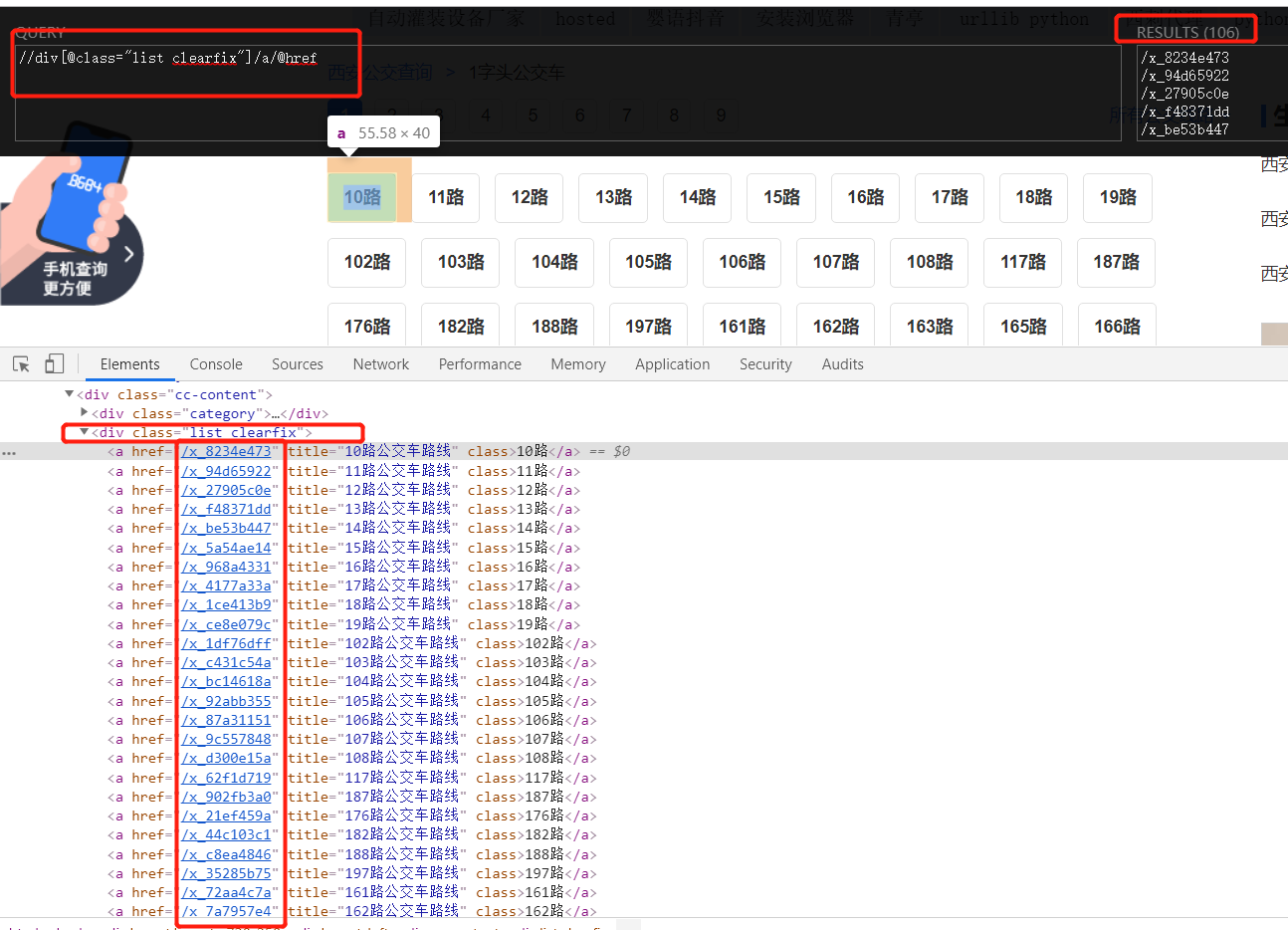
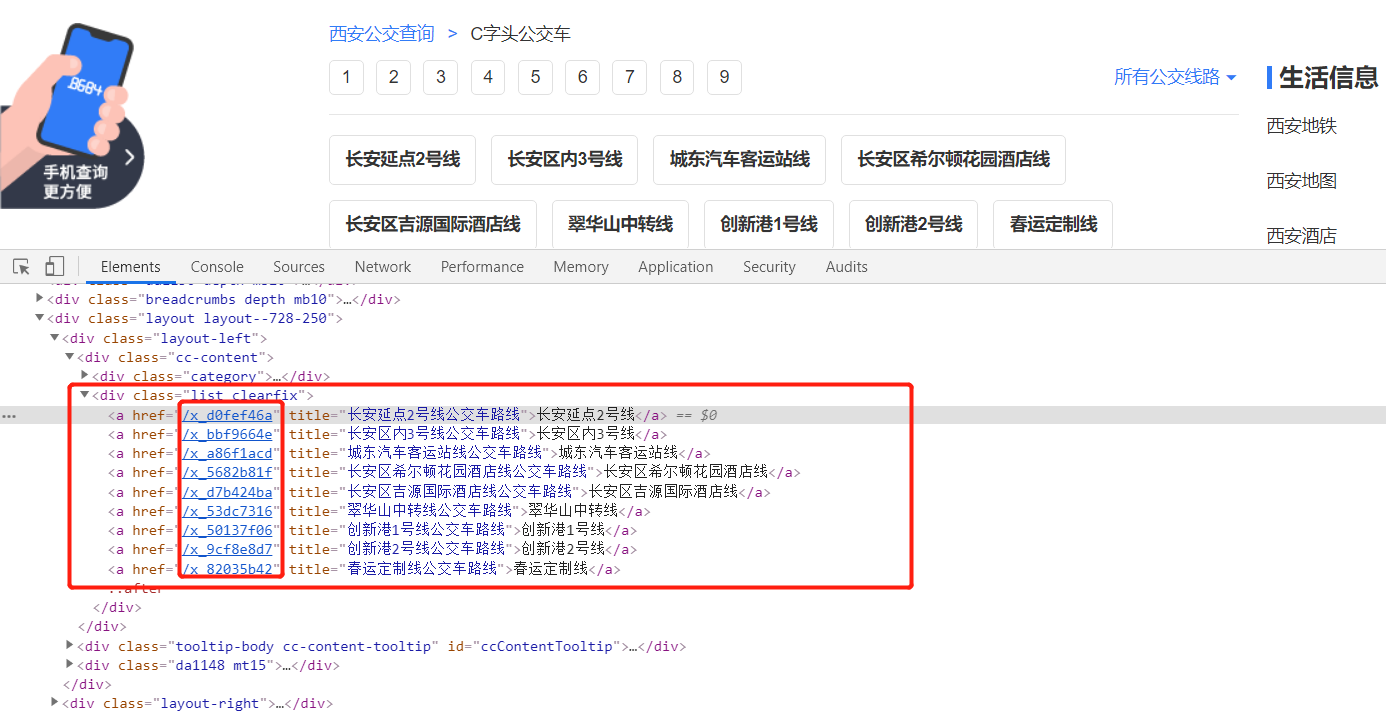
3. Extract the content to be crawled:
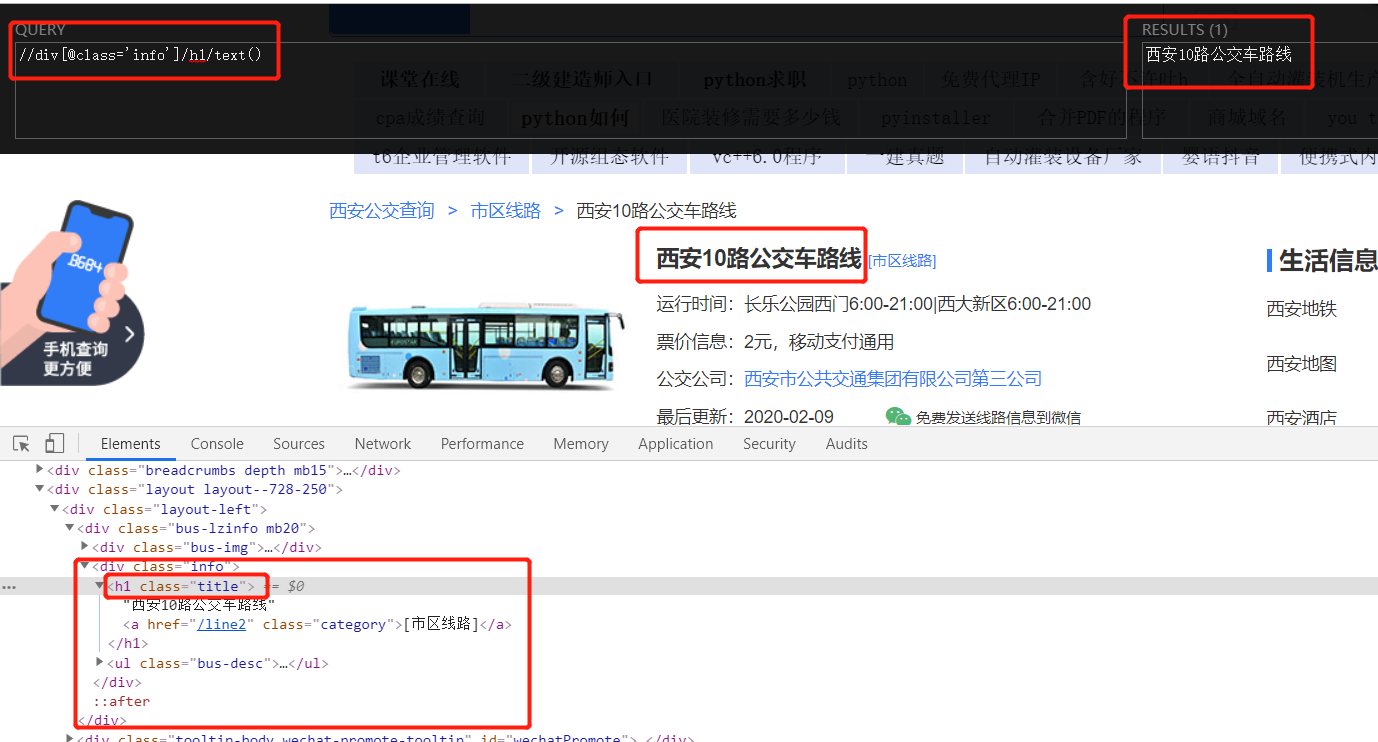
3.1 access to public transport information:
bus_number = tree.xpath('//div[@class="info"]/h1/text()')[0]
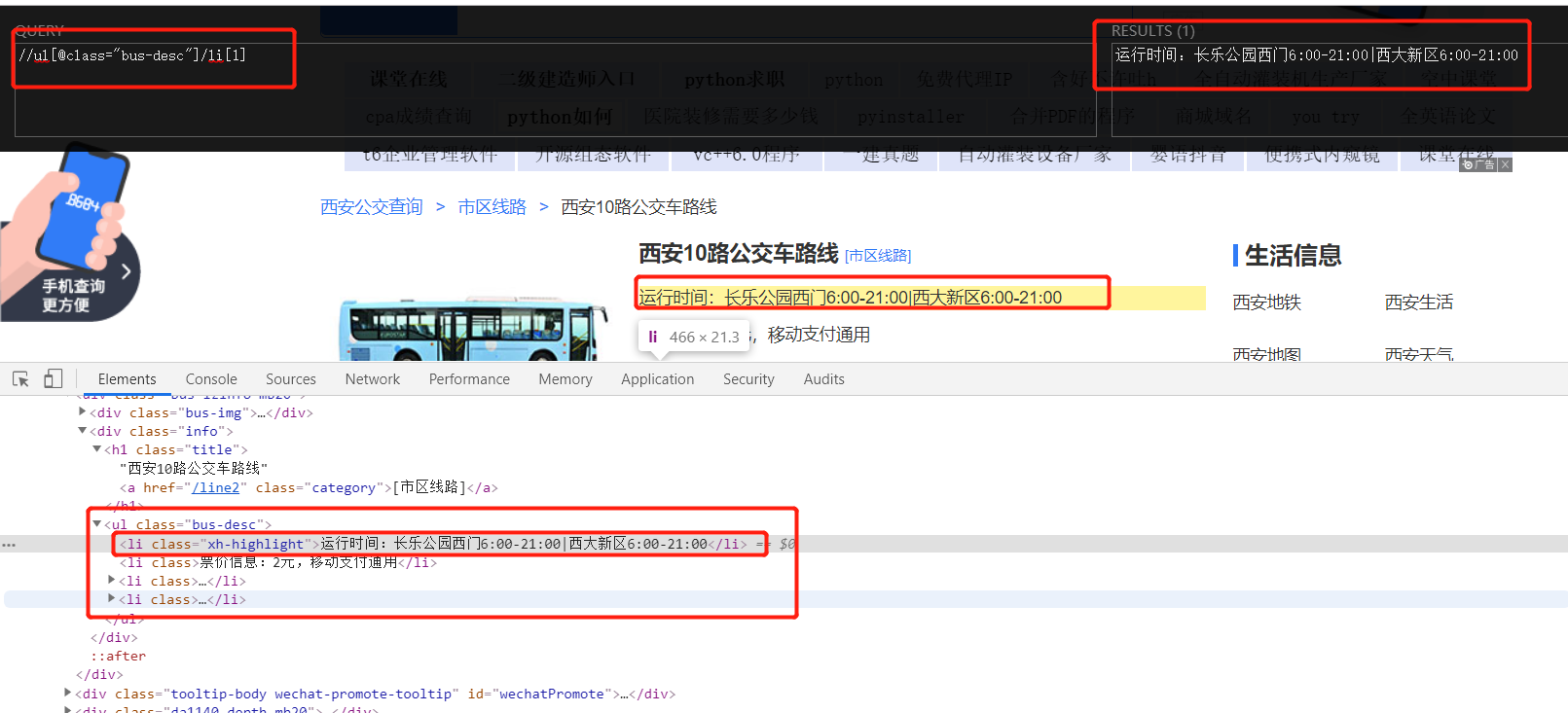
3.2 get running time:
run_time = tree.xpath('//ul[@class="bus-desc"]/li[1]/text()')[0]
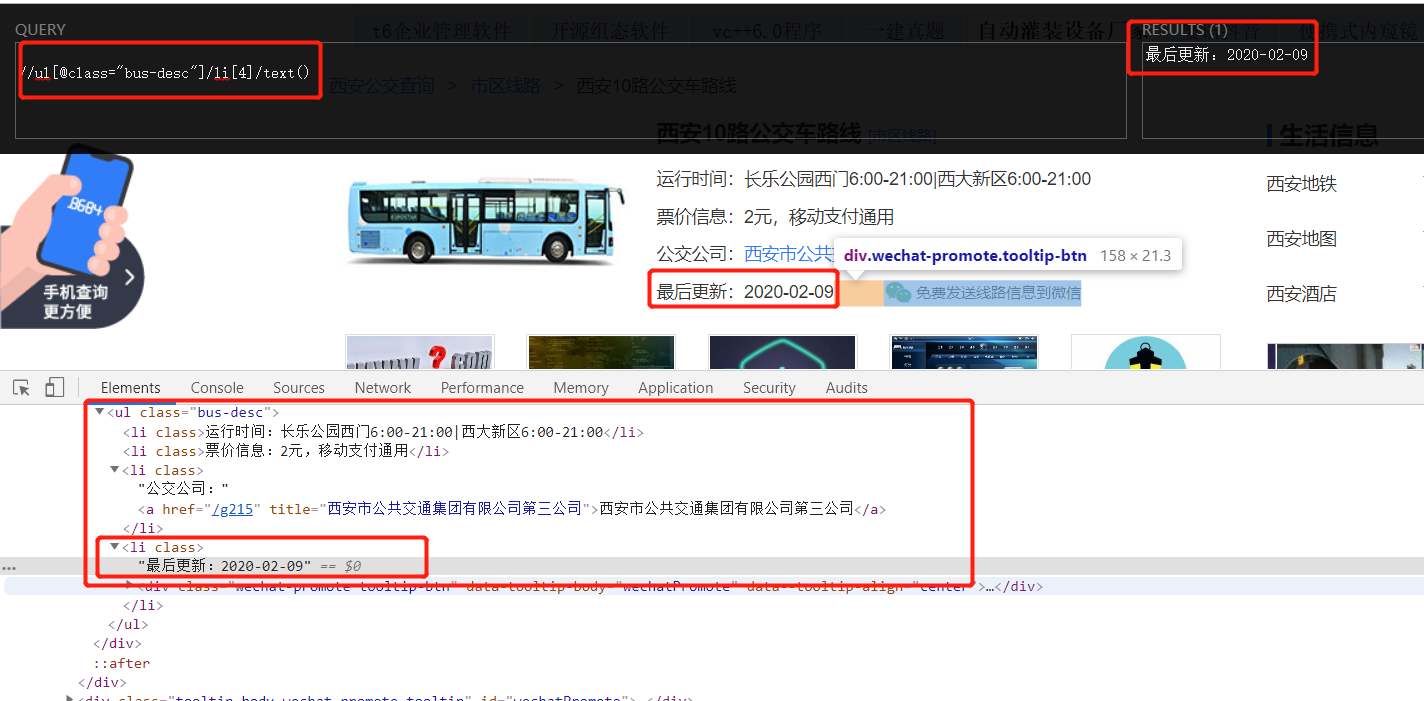
3.3 get update time:
laster_time = tree.xpath('//ul[@class="bus-desc"]/li[4]/text()')[0]
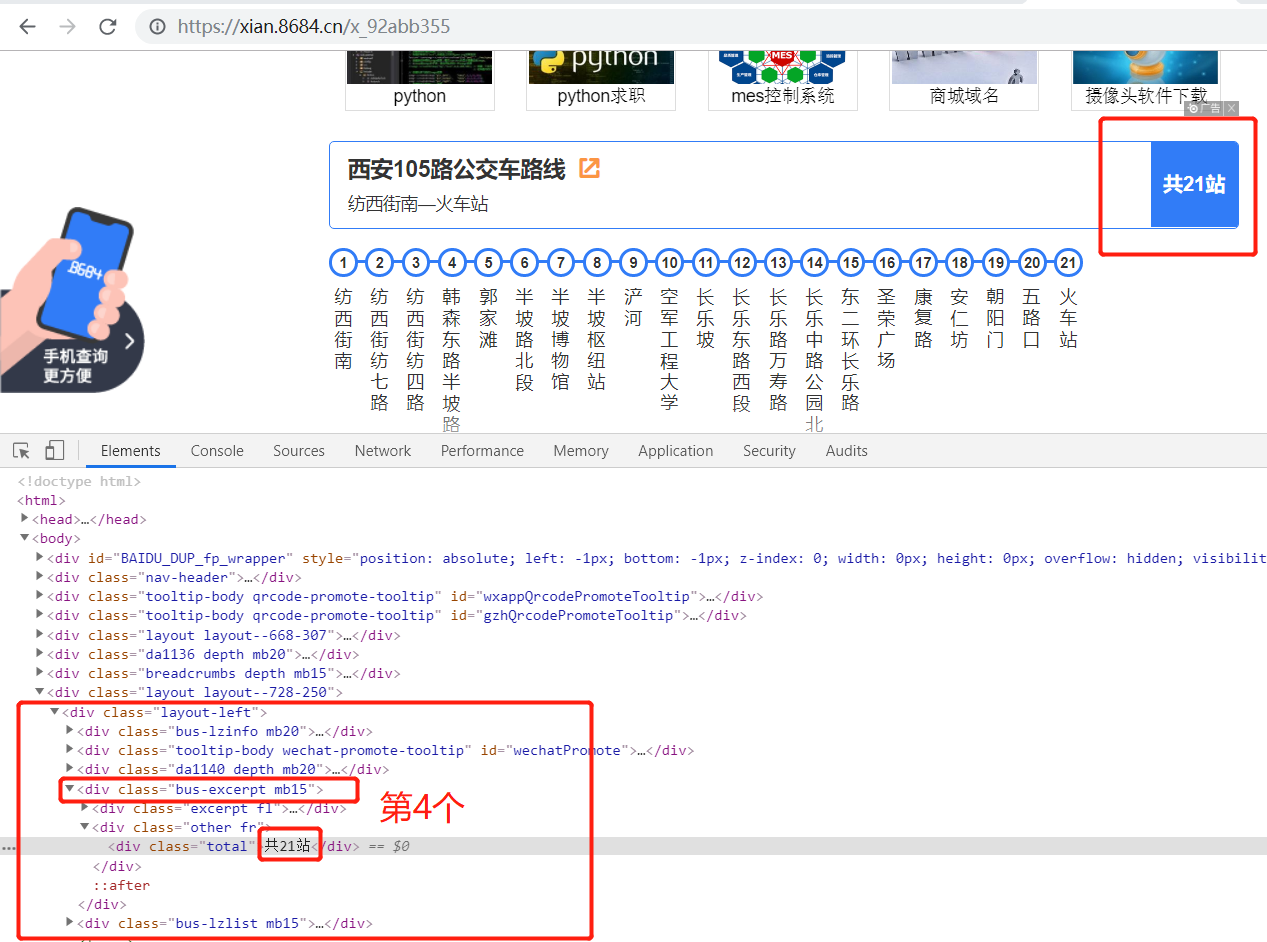
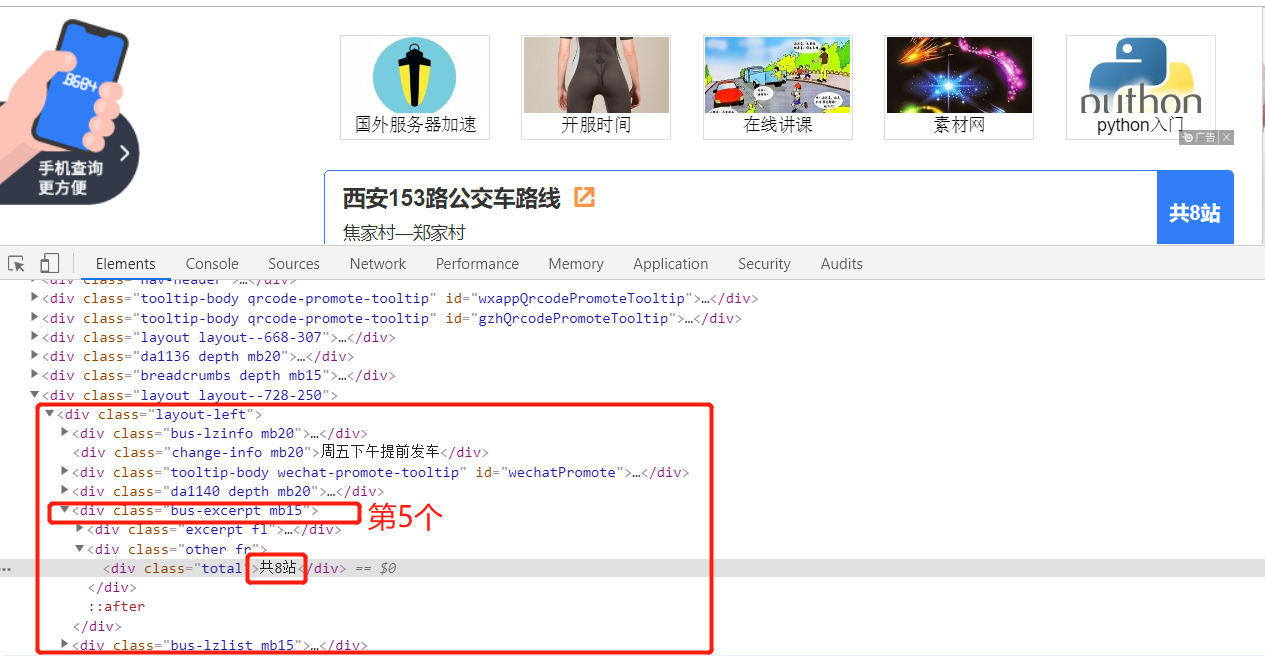
3.4 obtain the number of uplink terminals:
up_total = tree.xpath('//div[@class="layout-left"]/div[4]/div/div[@class="total"]/text()')[0]
//or
up_total = tree.xpath('//div[@class="layout-left"]/div[5]/div/div[@class="total"]/text()')[0]
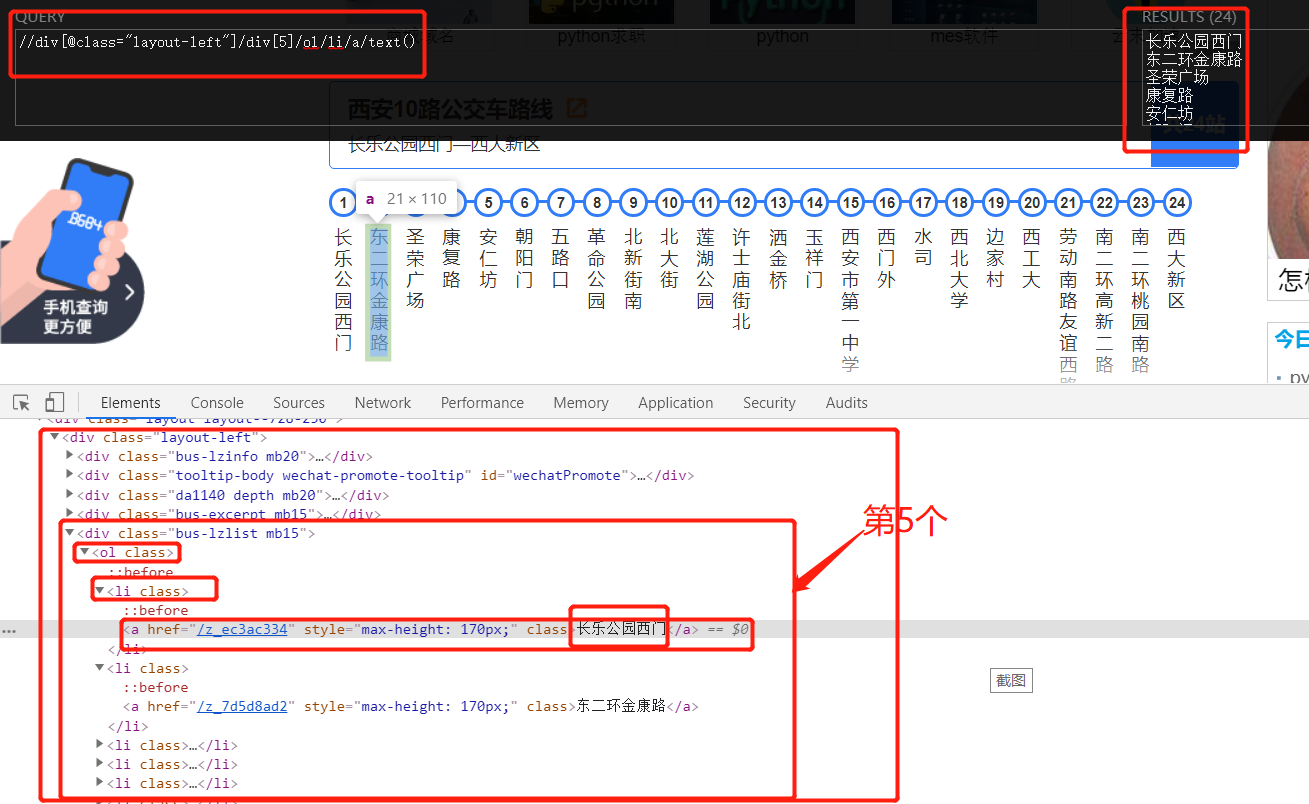
3.5 get the names of all uplink stations:
up_route = tree.xpath('//div[@class="layout-left"]/div[5]/ol/li/a/text()')[0]
//or
up_route = tree.xpath('//div[@class="layout-left"]/div[6]/ol/li/a/text()')[0]
3.6 obtain the number of downlink terminals (some routes are closed circles, regardless of uplink and downlink):
down_total = tree.xpath('//div[@class="layout-left"]/div[6]/div/div[@class="total"]/text()')[0]
//or
down_total = tree.xpath('//div[@class="layout-left"]/div[7]/div/div[@class="total"]/text()')[0]
//or
down_total = ''
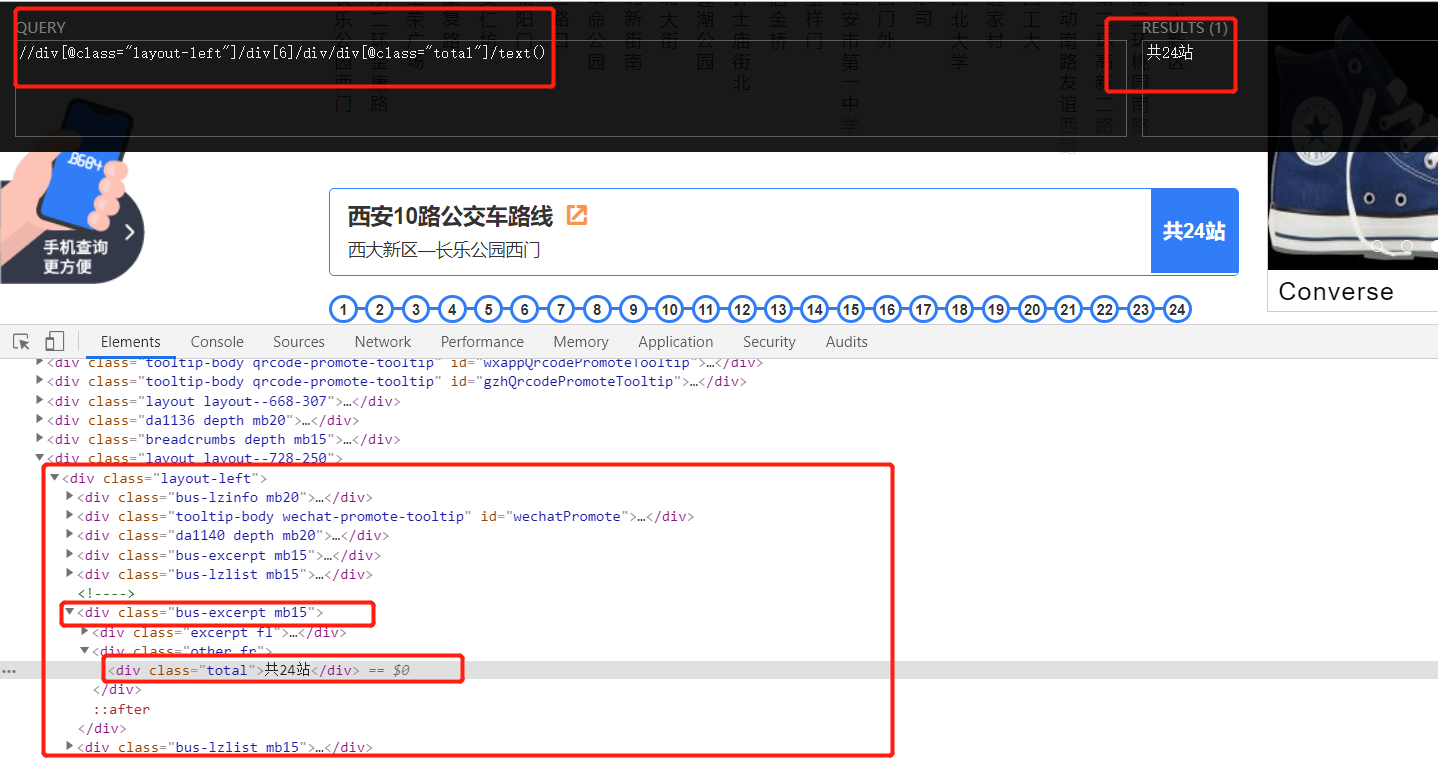
3.7 get the names of all stations in the downlink (some routes are closed circles, regardless of the uplink and downlink):
down_route = tree.xpath('//div[@class="layout-left"]/div[7]/ol/li/a/text()')[0]
//or
down_route = tree.xpath('//div[@class="layout-left"]/div[8]/ol/li/a/text()')[0]
//or
down_route = ''
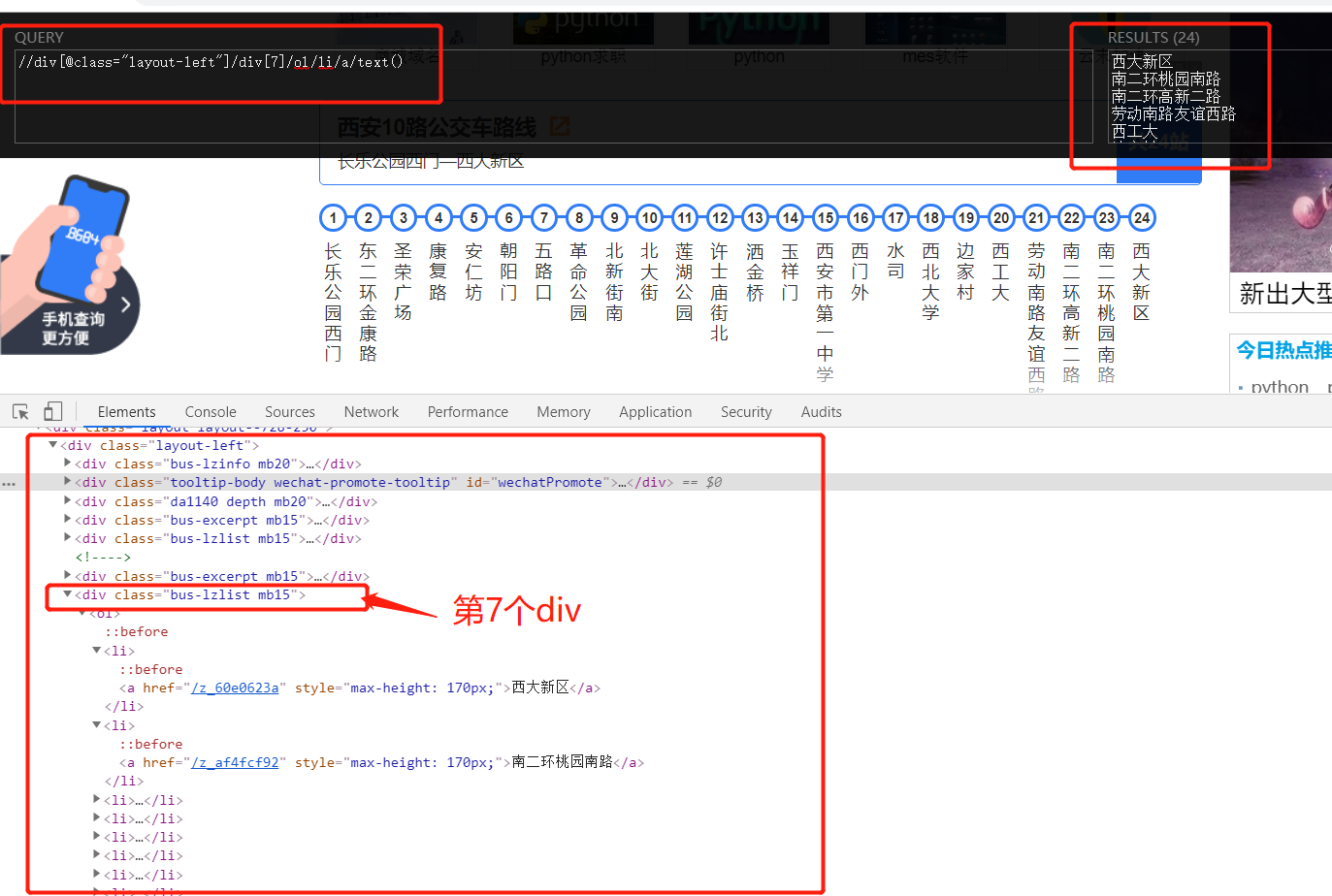
2, Code implementation
import requests
from lxml import etree
items = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
}
def parse_navigation():
url = 'https://foshan.8684.cn/'
r = requests.get(url, headers=headers)
tree = etree.HTML(r.text)
number_href_list = tree.xpath('//div[@class="bus-layer depth w120"]/div[1]/div/a/@href')
char_href_list = tree.xpath('//div[@class="bus-layer depth w120"]/div[2]/div/a/@href')
return number_href_list + char_href_list
def parse_second_route(content):
tree = etree.HTML(content)
route_list = tree.xpath('//div[@class="list clearfix"]/a/@href')
route_name = tree.xpath('//div[@class="list clearfix"]/a/text()')
i = 0
for route in route_list:
print('Start crawling%s line······' % route_name[i])
route = 'https://foshan.8684.cn'+route
r = requests.get(url=route,headers=headers)
parse_third_route(r.text)
print('End crawl%s line······' % route_name[i])
i += 1
def parse_third_route(content):
tree = etree.HTML(content)
bus_number = tree.xpath('//div[@class="info"]/h1/text()')[0]
run_time = tree.xpath('//ul[@class="bus-desc"]/li[1]/text()')[0]
ticket_info = tree.xpath('//ul[@class="bus-desc"]/li[2]/text()')[0]
laster_time = tree.xpath('//ul[@class="bus-desc"]/li[4]/text()')[0]
if tree.xpath('//div[@class="layout-left"]/div[5]/@class')[0] == 'bus-excerpt mb15':
up_total = tree.xpath('//div[@class="layout-left"]/div[5]/div/div[@class="total"]/text()')[0]
up_route = tree.xpath('//div[@class="layout-left"]/div[6]/ol/li/a/text()')
try:
down_total = tree.xpath('//div[@class="layout-left"]/div[7]/div/div[@class="total"]/text()')[0]
down_route = tree.xpath('//div[@class="layout-left"]/div[8]/ol/li/a/text()')
except Exception as e:
down_total = ''
down_route = ''
else:
up_total = tree.xpath('//div[@class="layout-left"]/div[4]/div/div[@class="total"]/text()')[0]
up_route = tree.xpath('//div[@class="layout-left"]/div[5]/ol/li/a/text()')
try:
down_total = tree.xpath('//div[@class="layout-left"]/div[6]/div/div[@class="total"]/text()')[0]
down_route = tree.xpath('//div[@class="layout-left"]/div[7]/ol/li/a/text()')
except Exception as e:
down_total = ''
down_route = ''
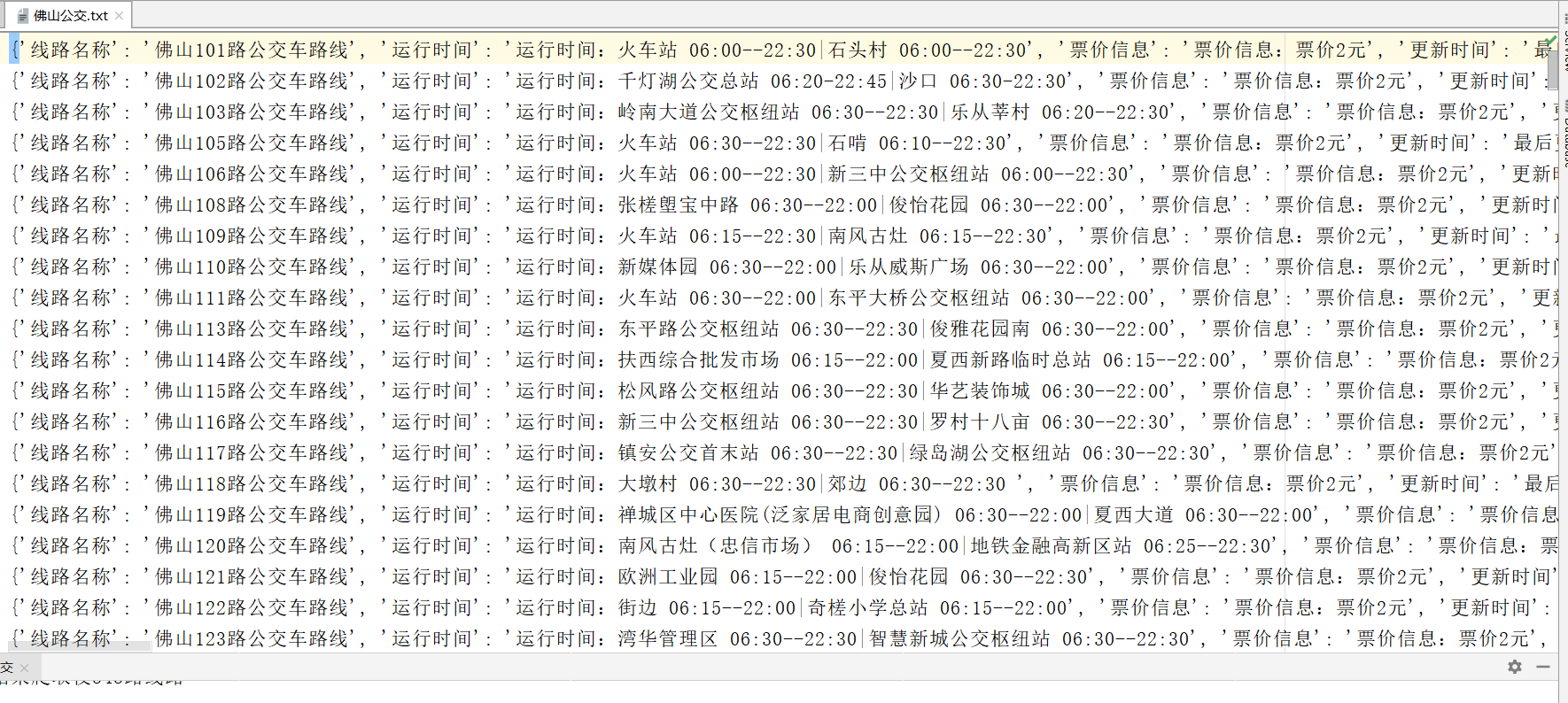
item = {
'Line name': bus_number,
'Running time': run_time,
'Fare information': ticket_info,
'Update time': laster_time,
'Number of uplink terminals': up_total,
'Name of all uplink stations': up_route,
'Number of downlink terminals': down_total,
'Name of all down line stations': down_route
}
items.append(item)
def parse_second(navi_list):
for first_url in navi_list:
first_url = 'https://foshan.8684.cn' + first_url
print('Start crawling%s All public transport information' % first_url)
r = requests.get(url=first_url, headers=headers)
parse_second_route(r.text)
fp = open('Foshan public transport.txt', 'w', encoding='utf8')
for item in items:
fp.write(str(item) + '\n')
fp.close()
def main():
navi_list = parse_navigation()
parse_second(navi_list)
if __name__ == '__main__':
main()

Published 125 original articles, won praise 4, visited 8878
Topics:
Windows
encoding

