Spider What is it?
Spider Is a basic class provided by scripy, and other basic classes contained in scripy (such as CrawlSpider )And custom spider s must inherit this class.
Spider Is a class that defines how to crawl a website, including how to crawl and how to extract structured data from its web pages.
The source code is as follows:
The base class of all crawlers from which user-defined crawlers must inherit
class Spider(object_ref):
#Name is the most important attribute of the spider and is required. The general practice is to name the spider after the domain (with or without suffix). For example, if the spider crawls to mywebsite COM, the spider is usually named mywebsite
name = None
#Initialization, extract crawler name, start_ruls
def __init__(self, name=None, **kwargs):
#Judge whether the crawler name name exists. If not, an error will be reported
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
#python objects or types through built-in members__ dict__ To store member information
self.__dict__.update(kwargs)
#Determine whether start exists_ URLs list. Start the request from the URL of the page obtained from the list, and the subsequent URL will be extracted from the obtained data.
if not hasattr(self, 'start_urls'):
self.start_urls = []
#Log information after scripy execution
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
#Judge whether the attribute of the object exists. If it does not exist, assert it
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#This method reads start_urls, and generate a Request object for each address, give it to scripy to download and return the Response
#Note: this method is called only once
def start_requests(self):
for url in self.start_urls:
#Function to generate Request object
yield self.make_requests_from_url(url)
#The default callback function of the Request object is parse(), and the submission method is get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#The default Request object callback function handles the returned response.
#Generate Item or Request objects. Users need to rewrite the contents of this method themselves
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
def __str__(self):
return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
Therefore, it can be concluded that Scrapy The process of crawling data is as follows:
1. The spider's entry method (start_requests()) requests start_ The url defined in the URLs list returns the Request object (and a callback function named parse is passed to it by default).
2. After the downloader obtains the Respose, the callback function will parse the reply, and the returned result may be a dictionary, Item or Request object, or an iterative type composed of these objects. The returned Request will also contain a callback function and be processed by the callback function after being downloaded (i.e. repeat step 2).
3. To parse the data, you can use the Selectors tool of scripy or lxml, BeautifulSoup and other modules.
4. Finally, Scrapy saves the returned data dictionary (or Item object) as a file or in the database.
scrapy. spider. Introduction to spider class
Common class properties
name : is a string. It identifies the name of each spider, which must be defined and unique. In practice, we usually create a spider for each independent website.
start_url : is a list containing the url of the initial Request page and must be defined. start_ The requests () method will reference this property and issue the initial Request.
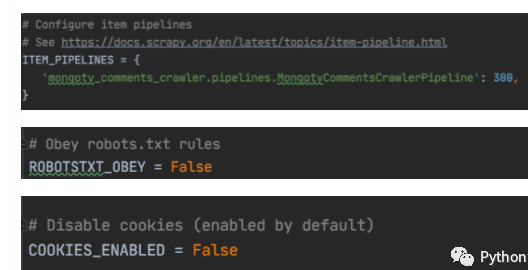
custom_settings : is a dictionary. Each key value pair represents a configuration, which can be used to override SETTINGS (the global configuration module of scripy, located in the settings.py file).
Example: custom_settings = {'COOKIES_ENABLED': True,'ROBOTSTXT_OBEY': False}. Overrides the global attribute cookies_ ENABLED.
Extension: several methods to set the value in settings. The priority from high to low is as follows:
1. Command line options
2. custom_settings
3. settings.py file
4. Default settings of the command line. Each command line has its own default settings
5. The default global setting is defined in the scene settings. default_ In settings
allowed_domains : is a list of strings. It specifies the domain name of the website that is allowed to crawl, and the web pages under non domain names will be automatically filtered.
Example: allowed_domains = cnblogs.com,start_url = 'https://www.zhihu.com '. In this example, the domain name that does not belong to CSDN is almost known, so it will be filtered in the crawling process.
crawler : is a Crawler object. You can access some components of Scrapy through it (for example, extensions, middle wars, settings).
Example: spider crawler. settings. getbool('xxx'). In this example, we access the global properties through crawler.
settings : is a settings object. It contains the configuration of the Spider at run time. This is the same as using Spider crawler. Settings access is the same. Logger: is a logger object. Created according to the name of Spider, which records the event log.
common method
start_requests : this method is the entry method of Spider. By default, this method requests start_ The url defined in the url returns the corresponding Request. If this method is rewritten, it can return an iteratable object containing * * Request (as the first Request) or a FormRequest object * *. Generally, POST requests rewrite this method.
parse : when no callback function is specified for other requests, it is used to process the default callback of download response. Its main function is to parse the returned web page data (response.body), extract structured data (generate item) and generate the URL Request that needs the next page. This method is used to write the specific logic of parsing web pages (including parsing data or parsing new pages), so this method is very important!
Spider case: brother's comments
Recently, I was attracted by my brother who cut through thorns and thorns, but I still have to serve you well and update the articles every day! Introduce this variety show.
Brother through thorns is a panoramic music competition variety launched by mango TV. The program guests challenge each other and cut through thorns and thorns. Through the process of mutual exploration between men and family establishment, they interpret "the hot life will shine forever" and witness the spiritual power that will never fall.
This time we use Scrapy to crawl the comments of our brothers.
Analysis ideas:
Open Google browser and visit the link of issue 01( https://www.mgtv.com/b/367750/13107580.html ), turn off JavaScript loading, refresh, and find that the comment data below is missing, indicating that the data is loaded asynchronously, and the comment data cannot be found in the source code of this web page link;
Since it is asynchronous loading, it is necessary to capture packets. Open the JavaScript that has just been turned off, reload the web page, right-click to check that the data is generally in XHR or JS, so check these two items first. At this time, click the next page of the comment and find that the data is in JS:
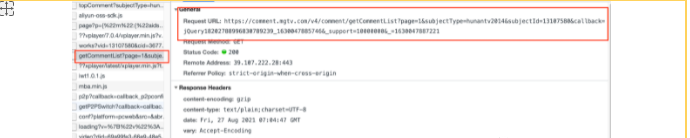
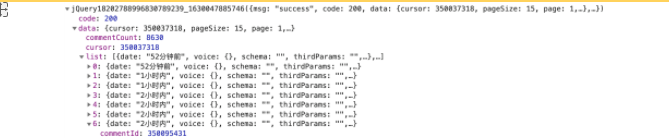

As can be seen from the real link of the above comment, the real request website of the comment is:“ https://comment.mgtv.com/v4/comment/getCommentList? ”, followed by a series of parameters (callback, _support, subjectType, subjectId, page, _). You can see:
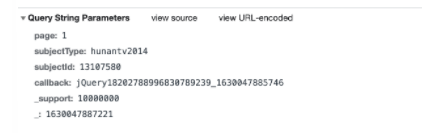
We know that page is the number of page numbers, subjectId is the id corresponding to each video, and the callback function. The last bold guess is to add a 3-bit random number after the unix timestamp (or the unix timestamp is multiplied by 1000 and rounded). It should only serve as a placeholder. It may be a completely useless parameter, just to scare us.
But I'm not sure. Let's take a look, so I removed the last parameter and made a request in the browser. The results are as follows:
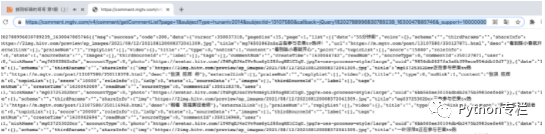
The description is a completely useless parameter. Hahaha, it's used to scare us. Don't be afraid! We don't need it.
Once we have the link, we will start to create a crawler project!
First open the command line and enter:
scrapy startproject mongotv_comments_crawler
Generate new mongotv_comments_crawler project, and then enter:
cd mongotv_comments_crawler scrapy genspider mgtv_crawl mgtv.com
Generate crawler name.
Then, open the project with PyCharm. Since the JSON data is retrieved at last, we directly parse the JSON data and return it to Items.
So in the crawler file mgtv_ crawl. In the mgtvcrawlespider class of. Py, the following definitions are made:
class MgtvCrawlSpider(scrapy.Spider): name = 'mgtv_crawl' allowed_domains = ['mgtv.com'] # start_urls = [' http://mgtv.com/ '] because we need to build mango TV every time, we rewrite start_requests method subject_id = 4327535 #id of the video pages = list(range(1, 100)) #The number of comment pages to crawl, such as 100 pages
Because we need to crawl the contents of multiple pages, we need to constantly modify the page parameters, so we rewrite start_requests method
def start_requests(self): #Override start_requests
start_urls = [f'https://comment.mgtv.com/v4/comment/getCommentList?page={page}&subjectType=hunantv2014&subjectId={self.subject_id}&callback=jQuery18204988030991528978_1630030396693&_support=10000000&_=1630030399968' for page in self.pages]
#Generate all URLs that need to be crawled and save them in start_ url s
for url in start_urls: #Traverse start_ Request from URLs
yield Request(url)
Then rewrite the parse() function to get the json result. However, the json result is preceded by the prefix content as shown in the figure below, which we need to remove
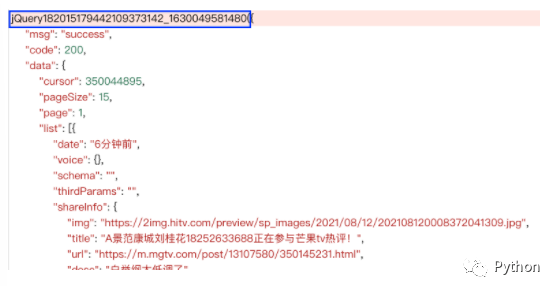
def parse(self, response):
text = response.text[response.text.find('{'):-1] #Remove "jQuery... ()" by string selection
json_data = json.loads(text) #Convert to json format
for i in json_data['data']['list']: #Traverse the list of comments on each page
item = MongotvCommentsCrawlerItem()
item['content'] = i['content']
item['commentId'] = i['commentId']
item['createTime'] = i['createTime']
item['nickName'] = i['user']['nickName']
yield item
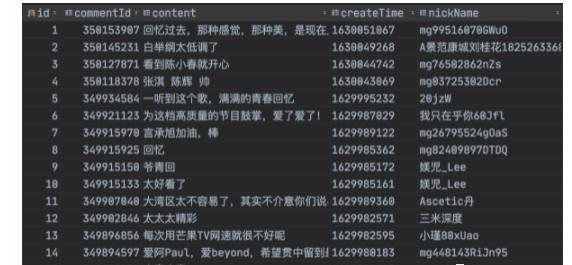
Write an item to get the content, creation time, user name and comment ID of the comment
class MongotvCommentsCrawlerItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() content = scrapy.Field() createTime = scrapy.Field() nickName = scrapy.Field() commentId = scrapy.Field()
Then write pipelines Py file and store the crawled items
import pymysql
class MongotvCommentsCrawlerPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host='127.0.0.1', user='root', password='root',
db='mgtv', charset='utf8')
def process_item(self, item, spider):
commentId = item["commentId"]
content = item['content']
createTime = item['createTime']
nickName = item["nickName"]
sql = "insert into comments(commentId,content,createTime,nickName) values(" + str(commentId) + ",'" + content + "','" + createTime + "','" + nickName + "');"
self.conn.query(sql)
self.conn.commit()
return item
def close_spider(self, spider):
self.conn.close()
In settings Open the corresponding setting item in py:
Start the crawler to crawl:
scrapy crawl mgtv_crawl
The results of crawling are as follows:
① More than 2000 Python e-books (both mainstream and classic books should be available)
② Python standard library materials (the most complete Chinese version)
③ Project source code (forty or fifty interesting and classic hand training projects and source code)
④ Videos on basic introduction to Python, crawler, web development and big data analysis (suitable for Xiaobai)
⑤ Python learning roadmap (bid farewell to non stream learning)
If you need relevant information, you can scan it
