Scrapy
Introduction
Scrapy introduction
1.Scrapy is an application framework written in pure Python for crawling website data and extracting structural data. It is widely used 2. The power of the framework, users only need to customize and develop a few modules to easily realize a crawler, which is used to grab web content and various pictures, very convenient
Scrapy architecture
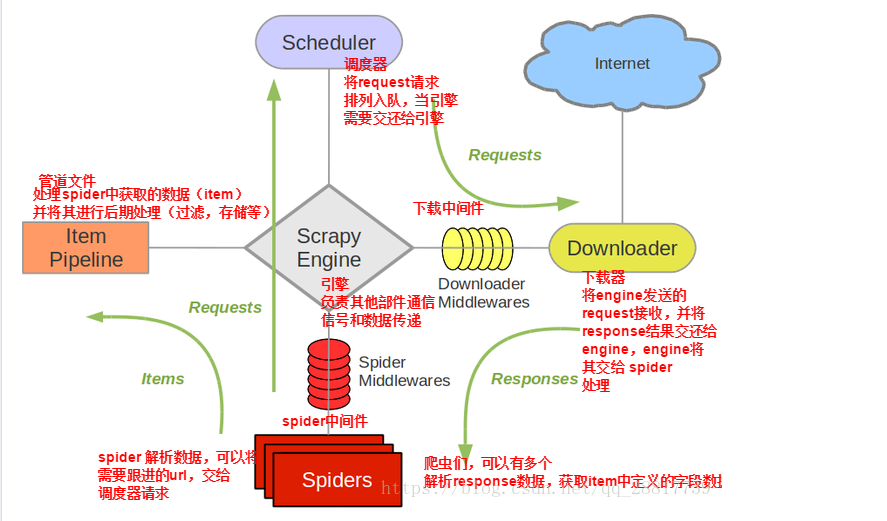
Scrapy mainly includes the following components:
1. Engine (scratch)
It is used to process the data flow of the whole system and trigger transactions (framework core)
2. Scheduler
It is used to accept the request sent by the engine, press it into the queue, and return when the engine requests again. It can be imagined as a priority queue of URL (web address or link to be crawled), which determines what the next web address to be crawled is, and at the same time removes the duplicate web address
3. Downloader
Used to download web content and return it to spiders (the crawler is built on twisted, an efficient asynchronous model)
4. Spiders
Crawlers are mainly used to extract the information they need from a specific web page, namely the so-called entity (Item). The user can also extract the link from it and let Scrapy continue to grab the next page
5. Pipeline
It is responsible for dealing with entities extracted from web pages by crawlers. Its main functions are to persist entities, verify the effectiveness of entities, and clear unnecessary information. When the page is parsed by the crawler, it will be sent to the project pipeline and processed in several specific order.
6. Downloader Middleware
The framework between the Scrapy engine and the downloader mainly deals with requests and responses between the Scrapy engine and the downloader.
7. Spider Middleware
The framework between Scrapy engine and crawler mainly deals with the response input and request output of spiders.
8. Scheduler Middleware
The middleware between the Scrapy engine and the scheduling, which sends requests and responses from the Scrapy engine to the scheduling.Scrapy operation process
1. The engine takes a link (URL) from the scheduler for the next capture, including the filter and the pair of columns. The filtered url is handed to the pair of columns 2. The engine encapsulates the URL as a request to the downloader 3. The downloader downloads the resources and encapsulates them into response packages 4. Reptile resolution Response 5. If the entity (Item) is resolved, it will be delivered to the engine for further processing (persistent storage processing) in the pipeline 6. If the resolved URL is a link, the URL will be handed over to the scheduler for grabbing Will be scheduled by the engine
Two installation
#Windows platform
1,pip3 install wheel #After installation, the software can be installed through the wheel file. The official website of the wheel file is https://www.lfd.uci.edu/~gohlke/pythonlibs
3,pip3 install lxml
4,pip3 install pyopenssl
5,Download and install pywin32: https://sourceforge.net/projects/pywin32/files/pywin32/
6,download twisted Of wheel Document: http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7,implement pip3 install Download directory\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8,pip3 install scrapy
#Linux platform
1,pip3 install scrapyThree command line tools
introduce
#1 view help
scrapy -h
scrapy <command> -h
#2 there are two kinds of commands: project only must be cut to the project folder to execute, while Global's command does not need to
Global commands: #Global command
startproject #Create project
genspider #Create a crawler
# Example scraper Baidu www.baidu.com
settings #If it is in the project directory, you will get the configuration of the project
runspider #Run a separate python file without having to create a project
shell #For example, whether the selector rule is correct or not
fetch #Independent of Cheng simply crawling a page, you can get the request header
view #After downloading, pop up the browser directly to distinguish which data is the ajax request
version #Scan version view the version of the scan, scan version - V view the version of the scan dependency Library
Project-only commands: #Project documents
crawl #To run a crawler, you must create an item. Make sure that ROBOTSTXT_OBEY = False in the configuration file
check #Check for syntax errors in the project
list #List the crawler names included in the project
edit #Editor, generally not used
parse #scrapy parse url address --callback Callback function #In this way, we can verify whether our callback function is correct
bench #Scratch bench pressure test
#3 official website link
https://docs.scrapy.org/en/latest/topics/commands.htmlExample
#1. Execute global command: please make sure not to be in the directory of a project, and exclude the influence of the project configuration
scrapy startproject MyProject(Project name)
cd MyProject (Switch to project)
scrapy genspider baidu www.baidu.com #Create a crawler
#(baidu) the name of the crawler corresponds to the relevant domain name (www.baidu.com can be written at random first)
#On behalf of this crawler, it can only crawl the domain name www.baidu.com or Baidu's sub domain name
scrapy settings --get XXX #If you switch to the project directory, you will see the configuration of the project
scrapy runspider baidu.py #Execute crawler
scrapy shell https://www.baidu.com
response
response.status
response.body
view(response)
scrapy view https://www.taobao.com ා if the content displayed on the page is incomplete, the incomplete content is implemented by ajax request, so as to quickly locate the problem
scrapy fetch --nolog --headers https://www.taobao.com
scrapy version #Version of scratch
scrapy version -v #Dependent library version
#2. Execute project command: switch to the project directory
scrapy crawl baidu
scrapy check
scrapy list
scrapy parse http://quotes.toscrape.com/ --callback parse
scrapy benchIV. project structure and reptile application
directory structure
project_name/
scrapy.cfg
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
//Crawler 1.py
//Crawler 2.py
//Crawler 3.pyApplication notes
Scratch.cfg: the configuration file for the crawler project. __Init. Py: the initialization file of the crawler project, which is used to initialize the project. items.py: the data container file of the crawler project, which is used to define the data to be acquired. pipelines.py: pipeline file of the crawler project, which is used for further processing of the data in items. settings.py: the settings file of the crawler project, which contains the settings information of the crawler project. middlewares.py: the middleware file of the crawler project,
Running crawler in pycharm s
Create the entrypoint.py file in the project directory first. The file name cannot be changed from scrapy.cmdline import execute Execute (['scratch ','crawl','baidu ',' -- nolog ']) (Baidu is the name of the crawler. The first two items of the list remain the same -- nolog can be written or not, and the function is not to print other configuration items, but only the required content
Five Spiders
1. introduction
1.Spider is composed of a series of classes (defined a web address, a group of web addresses will not be crawled), which specifically includes how to perform crawling tasks and how to extract structured data from the page 2.Spider is a place where you can customize the behavior of page crawling or parsing for a specific website or a group of websites
2. Things spider will do in cycles
#1. Generate the initial Requests to crawl the first URLS and identify a callback function
The first Request definition obtains the url address from the start ulurls list by default in the start uurrs() method to generate the Request. The default callback function is the parse method. The callback function is automatically triggered when the download is completed and the response is returned
#2. In the callback function, parse the response and return the value
There are four return values:
Dictionary containing parsed data
Item object
New Request object (new Requests also need to specify a callback function)
Or iteratable objects (including Items or requests)
#3. Parsing page content in callback function
It's common to use scratch's own Selectors, but obviously you can also use beutifusoup, lxml or whatever you like.
#4. Finally, the returned Items object will be persisted to the database
Save to the database through the Item Pipeline component: https://docs.summary.org/en/latest/topics/item-pipeline.html ා topics Item Pipeline)
Or export to different files (via Feed exports: https://docs.summary.org/en/latest/topics/feed-exports.html ා topics Feed exports)3. Crawling format
entrypoint.py
from scrapy.cmdline import execute execute(['scrapy','crawl','amazon1','-a','keywords=iphone8 Mobile phone','--nolog']) //Format with parameters
# -*- coding: utf-8 -*-
import scrapy
from urllib.parse import urlencode
class Amazon1Spider(scrapy.Spider):
name = 'amazon1'
allowed_domains = ['www.amazon.cn'] #It can also not be used. If it is written, the url of the request will be limited. The start_urls below can only request the url in the allowed_domains
start_urls = ['https://www.amazon.cn / '] (url that can hold multiple requests)
#Without writing allowed_domains, you can write multiple URLs in the start_url s request list
# For customized configuration, you can add the configuration of the request header series. First find it here, not in settings
custom_settings = {
'REQUEST_HEADERS':{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
}
}
# Specify parameters for external transmission
def __init__(self,keywords,*args,**kwargs):
super(Amazon1Spider,self).__init__(*args,**kwargs)
self.keywords=keywords
# Send request
def start_requests(self):
url = 'https://www.amazon.cn/s?%s&ref=nb_sb_noss_1' %(urlencode({'k':self.keywords}))
yield scrapy.Request(url=url,
callback=self.parse,
dont_filter=True
) #Request method GET
#post request: summary.formrequest (URL, formdata = data, callback)
# analysis
def parse(self, response):
detail_url = response.xpath('//*[@ id="search"]/div[1]/div[2]/div/span[4]/div[1]/div[1]/div/span/div/div/div[2]/div[3]/div/div/h2/a/@href '). If multiple URLs are obtained here, the product details url is required. The detailed url return request is repeated through the for loop. Each return request must have a corresponding callback function
for url in detail_url:
yiled yield scrapy.Request(url=url,
callback=self.parse_detail
dont_filter=True
)
print(detail_url)
def parse_detail(self,response):
print(response) #Response results of detail page
def close(spider, reason): #close after parsing
print('End')
4. example
Take the title of the Three Kingdoms and the content of each article
from scrapy.cmdline import execute execute(['scrapy','crawl','sang','--nolog'])
# -*- coding: utf-8 -*-
import scrapy
class SangSpider(scrapy.Spider):
name = 'sang'
allowed_domains = ['www.shicimingju.com/book/sanguoyanyi.html']
start_urls = ['http://www.shicimingju.com/book/sanguoyanyi.html/']
custom_settings = { #Add some request header information
'REQUEST_HEADERS':{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
}
}
def start_requests(self):
url = 'http://www.shicimingju.com/book/sanguoyanyi.html/'
yield scrapy.Request(url=url,
callback=self.parse,#Analyze the callback function of main page
) #Request to main page
def parse(self, response): #Analyze response information of main page
all_urls = response.xpath('/html/body/div[4]/div[2]/div[1]/div/div[4]/ul/li/a/@href').extract()#url of all articles
all_title = response.xpath('/html/body/div[4]/div[2]/div[1]/div/div[4]/ul/li/a/text()').extract()#All titles
for url in all_urls:
# print(response.urljoin(url)) #Splicing url
detail_urls = 'http://www.shicimingju.com'+url
print(detail_urls)
yield scrapy.Request(url=detail_urls,
callback=self.parse_detail,#Callback function to parse detail page
dont_filter=True
) #Send request to detailed article
def parse_detail(self,response):
content = response.xpath('/html/body/div[4]/div[2]/div[1]/div[1]/div/p/text()') #Response to parsing detailed articles
print(content)
5. Data analysis
-The data is parsed in the way of xpath encapsulated in the graph.
-What's the difference between the xpath in the story and the xpath in the etree?
xpath in etree returns a string or list
The list element returned by the xpath of the summary after data parsing is the Selector object, and then the corresponding data in the Selector object must be extracted through the extract or extract ﹐ first methods
Extract [first: extract the 0 th selector object in the list element
Extract: extract every selector object in the list6. Data persistent storage
Terminal based instruction storage
Property: the return value of the parse method can only be stored in the local disk file Instruction: scrape crawler name - o filename Limitation: it can only be stored in the disk, and the file name stored is limited, only the file name provided can be used
Example
# Crawling the title and content of a joke
import scrapy
class QiubSpider(scrapy.Spider):
name = 'qiub'
start_urls = ['http://www.lovehhy.net/Joke/Detail/QSBK/']
def parse(self, response):
all_data = []
#response.xpath gets a list of Selector objects
title = response.xpath('//*[@id="footzoon"]/h3/a/text()').extract()
content = response.xpath('//*[@ id="endtext"]//text()').extract() ා because there are br tags in the content, use / / text ()
title=''.join(title)
content=''.join(content)
dic = {
'title':title,
'content':content
}
all_data.append(dic)
return all_data #Must have return value to use terminal instruction based storage
//Terminal storage instructions: scratch qiub - O qiubai.csv (CSV is the file type provided) Pipeline based storage
Implementation process
-Pipeline based: implementation process
1. Data analysis
2. Define related properties in the item class
3. Store or encapsulate the parsed data into an item type object (the object of the corresponding class in the items file)
4. Submit item to pipeline
5. Receive the item in the process item method of the pipeline file for persistent storage
6. Open the pipeline in the configuration file
Pipes can only handle objects of type itemFile form
Example
qiub.py
# -*- coding: utf-8 -*-
import scrapy
from qiubai.items import QiubaiItem
class QiubSpider(scrapy.Spider):
name = 'qiub'
start_urls = ['http://www.lovehhy.net/Joke/Detail/QSBK/']
def parse(self, response):
all_data = []
title = response.xpath('//*[@id="footzoon"]/h3/a/text()').extract()
content = response.xpath('//*[@id="endtext"]//text()').extract()
title=''.join(title)
content=''.join(content)
dic = {
'title':title,
'content':content
}
all_data.append(dic)
item = QiubaiItem() #Instantiate an item object
item['title'] = title #Encapsulated data structure
item['content'] = content
yield item #Submit item s to the pipeline to the pipeline class with the highest priorityitems.py
import scrapy
class QiubaiItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() #Fieid can accept any type of data format / type
content = scrapy.Field()pipelines.py
class QiubaiPipeline(object):
f= None
print('Start crawling.....')
def open_spider(self,spider): # Override parent method, open file
self.f = open('qiubai.txt','w',encoding='utf-8')
def close_spider(self,spider):# Override parent method, close file
print('End crawler')
self.f.close()
def process_item(self, item, spider):
#Item is the item object submitted by the pipeline
title = item['title'] #Value
content = item['content']
self.f.write(title+':'+content+'\n') #write file
return item settings.py
# Open pipes, multiple pipes can be opened
ITEM_PIPELINES = {
'qiubai.pipelines.QiubaiPipeline': 300, #Priority represented by 300
}Persist the same data to different platforms
1. A pipeline class in the pipeline file is responsible for a form of persistent storage of data 2. Items submitted by the crawler file to the pipeline will only be submitted to the pipeline class with the highest priority 3. The return item in the process item of the pipeline class indicates to return / submit the item received by the current pipeline to the next pipeline class to be executed
Database (mysql)
Example
import pymysql
# Responsible for storing data to mysql
class MysqlPL(object):
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='123', db='spider',charset='utf8')
print(self.conn)
def process_item(self, item, spider):
author = item['author']
content = item['content']
sql = 'insert into qiubai values ("%s","%s")' % (author, content)
self.cursor = self.conn.cursor()
try:
self.cursor.execute(sql) #Commit the transaction if the execution is correct
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback() #Rollback, rollback if there is an error
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()7. Crawl the picture of school flower net
Introduction to imagesipeline
Special pipe for crawling pictures 1. Crawl an Item, and put the URLs of the picture into the image? URLs field 2. Transfer the Item returned from Spider to Item Pipeline 3. When the Item is passed to ImagePipeline, the Scrapy scheduler and downloader will be called to complete the scheduling and downloading of the url in 4.image_urls. 5. After the image download is completed successfully, the image download path, url, checksum and other information will be filled into the images field.
Use of imagesipipeline:
from scrapy.pipelines.images import ImagesPipeline
import scrapy
# By overriding the parent class method
class SpiderImgPipeline(ImagesPipeline):
# Send a request to a media resource
# Item is submitted item(src)
def get_media_requests(self, item, info):
yield scrapy.Request(item['src'])
# Develop the name of the media data store
def file_path(self, request, response=None, info=None):
img_name = request.url.split('/')[-1]
print(img_name+'Crawling')
return img_name
# Pass item to next pipeline class to be executed
def item_completed(self, results, item, info):
return item
# Add the storage path of pictures in the configuration
IMAGES_STORE = './imgslib'Climbing example:
settings.py
IMAGES_STORE = './imgslib' #Store crawled pictures
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
ITEM_PIPELINES = {
'spider_img.pipelines.SpiderImgPipeline': 300,
}img.py
# -*- coding: utf-8 -*-
import scrapy
from spider_img.items import SpiderImgItem
class ImgSpider(scrapy.Spider):
name = 'img'
start_urls = ['http://www.521609.com/daxuexiaohua/']
url= 'http://www.521609.com/daxuexiaohua/list3%d.html 'ා general url template, need to add page number, template of each page number
page_num = 1
def parse(self, response):
li_list = response.xpath('//*[@id="content"]/div[2]/div[2]/ul/li')
for li in li_list:
img_src = 'http://Www.521609.com / '+ Li. XPath ('. / a [1] / img / @ SRC '). Extract_first() ාurl of all the pictures obtained, string type of extract_first obtained, list obtained by extract, in which selector object is stored
item = SpiderImgItem() #Instantiate item object
item['src'] = img_src #Add data to item
yield item #Submit to item
if self.page_num < 3: #First two pages crawled
self.page_num += 1
new_url = format(self.url%self.page_num) #url of other pages
yield scrapy.Request(new_url,callback=self.parse) #Request number of pagesitems.py
import scrapy
class SpiderImgItem(scrapy.Item):
src = scrapy.Field()
passpiplines.py
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class SpiderImgPipeline(ImagesPipeline):
# Send a request to a media resource
# Item is submitted item(src)
def get_media_requests(self, item, info):
yield scrapy.Request(item['src'])
# Develop the name of the media data store
def file_path(self, request, response=None, info=None):
img_name = request.url.split('/')[-1]
print(img_name+'Crawling')
return img_name
# Pass item to next pipeline class to be executed
def item_completed(self, results, item, info):
return item8. Request parameter transfer (depth crawling)
Example: crawling movie information of 4567tv Movie Network
movie.py
# Demand: crawling the movie name and the introduction of the movie
# Analysis: go to the homepage of the movie network and ask to see all the movies, but you can't get a brief introduction. Now you need to get the url of all the movies. In the reverse request of the url of each movie, send a request for the details of the movie to get a brief introduction
import scrapy
from movie_spider.items import MovieSpiderItem
class MovieSpider(scrapy.Spider):
name = 'movie'
start_urls = ['https://www.4567tv.tv/index.php/vod/show/class/%E5%8A%A8%E4%BD%9C/id/1.html']
page_num = 1
def parse(self, response):
movie_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for movie_li in movie_list:
movie_title = movie_li.xpath('./div[1]/a/@title').extract_first()
movie_url = 'https://www.4567tv.tv'+movie_li.xpath('./div[1]/a/@href').extract_first()
item = MovieSpiderItem()
item['movie_title'] = movie_title
yield scrapy.Request(movie_url,callback=self.parse_movie_detail,meta={'item':item})#Request dissemination
if self.page_num < 5:
self.page_num += 1
new_url = f'https://www.4567tv.tv/index.php/vod/show/class/%E5%8A%A8%E4%BD%9C/id/1/page/{self.page_num}.html'
yield scrapy.Request(url=new_url,callback=self.parse,meta={'item':item})
def parse_movie_detail(self,response):
item = response.meta['item']#Take out item, receive
movie_about = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
item['movie_about'] = movie_about #Introduction to the film
yield item
# Deep crawling (parameter passing): you can't get the introduction of the movie on the front page of the movie. When you submit the item at the end, the title of the movie and the introduction of the movie are in different parsing callback functions. So first put the title in the item (but don't submit it), pass it to the next callback function, continue to use the item, and store the data to be submitted in the item,!!!
# Why can't it be set to global?
# Because there will be data coverage when the yield item is finally submitted
item['movie_title'] = movie_title #Deposit
meta={'item':item} # meta parameter transfer
item = response.meta['item'] #takeitems.py
import scrapy
class MovieSpiderItem(scrapy.Item):
# define the fields for your item here like:
movie_title = scrapy.Field()
movie_about = scrapy.Field()
passpipelines.py
import pymysql
class MovieSpiderPipeline(object):
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='123', db='movie_spider',charset='utf8')
def process_item(self, item, spider):
movie_title = item['movie_title']
movie_about = item['movie_about']
sql = 'insert into movie_info values ("%s","%s")' % (movie_title, movie_about)
self.cursor = self.conn.cursor()
try:
self.cursor.execute(sql) # Commit the transaction if the execution is correct
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback() # Rollback, rollback if there is an error
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()9. Application of scrape Middleware
Download Middleware
Role: block requests and responses in batches
-
Intercept request:
1.UA camouflage
2. Agent operation
-
Intercept response:
1. Tamper with response data, tamper with response objects that do not meet the requirements, such as dynamically loaded data, direct request is not available
2. Directly replace the response object
-This method is called when process request request is downloaded through middleware -The download result of process ﹣ response is processed by this method when it passes through middleware -Called when an exception occurs during the download of process menu exception # process_request(request, spider) : When each request downloads middleware, the method is called. The method must return any of the following three types: 1. None: Scrapy will continue to process the request, execute other middleware response methods, and know when the download handler function is called, and the request is executed (its reposne is downloaded) 2. Response object: Scrapy will not call other process ﹐ request() or process ﹐ exception() methods, or the download function of the response; it will return response. The process ﹐ response() method of the installed middleware Hu ziai's every response [once returned is called 3. Request object or raise exception: When the request object is returned: Scrap stops calling the process ﹣ request method and reschedules the returned request. When the new request is executed, the corresponding middleware will be called according to the downloaded response When the raise exception: the process_exception() method of the installed download middleware will be called. If there is no method to handle the exception, the errback(Request.errback) method of request will be called. If there is no code to handle the exception thrown, the exception will be ignored and will not be recorded # process_response(request, response, spider) : There are also three return values of process "response: 1. response object: if the returned object is a response (it can be the same as the incoming response, or it can be a brand new object), the response will be processed by the process UU response() method of other middleware in the chain 2. Request object: if it returns a request object, the middleware chain will stop, and the returned request will be rescheduled and downloaded. The processing is similar to that of the return request of process_request() 3. raiseu exception: if it throws an lgnoreRequest exception, call errback(Request.errback) of request. If there is no code to handle the exception thrown, the exception is ignored and not recorded process_exception(request, exception, spider) : When an exception (including lgnorequest exception) is thrown by the download handler or process ⒉ request(), the process ⒉ exception() is called by scratch #process_exception() also returns one of three: 1. Return None: Scrapy will continue to handle the exception, and then call the process menu exception() method of other installed middleware to know that all middleware has been called, then call the default exception handling 2. Return Response: the process UU Response() method of the installed middleware chain is called. Scrapy will not call the process UU exception() method of any other middleware 3. Return a request object: the returned request will be called again for download. Zhejiang stops the execution of the middleware's process ﹣ exception() method, just like returning a response. It is equivalent to a failed retry here if it fails. For example, when visiting a website, because of frequent crawling of blocked ip, you can set an increase agent here Continue to visit
Crawler Middleware
case
Crawler program
# -*- coding: utf-8 -*-
import scrapy
import requests
from wangyi.items import WangyiItem
from selenium import webdriver
class WySpider(scrapy.Spider):
name = 'wy'
start_urls = ['https://news.163.com/']
un_url = []
bro = webdriver.Chrome(executable_path=r'C:\pycahrm file\chromedriver.exe')
def parse(self, response):
li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
model_indexs = [3, 4, 6, 7, 8]
for index in model_indexs:
li_tag = li_list[index]
# The url corresponding to each plate is parsed out
model_url = li_tag.xpath('./a/@href').extract_first()
self.un_url.append(model_url) # The content is generated dynamically, so it is a url that does not meet the conditions, and needs to be further processed in the middleware
yield scrapy.Request(model_url,callback=self.news_parse)
def news_parse(self, response):
div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div/div/ul/li/div/div')
for div in div_list:
title = div.xpath('./div/div[1]/h3/a/text()').extract_first()
# title = div.xpath('./div/div/div[1]/h3/a/text()').extract_first()
news_url = div.xpath('./div/div[1]/h3/a/@href').extract_first()
item = WangyiItem()
#Remove space and wrap the result
item['title'] = title.replace('\n','')
item['title'] = title.replace('\t','')
item['title'] = title.replace(' ','')
item['title'] = title.replace('\t\n','')
yield scrapy.Request(news_url,callback=self.detail_parse,meta={'item':item})
def detail_parse(self,response):
item = response.meta['item']
content = response.xpath('//*[@id="endText"]//text()').extract()
content = ''.join(content)
#Remove space and wrap the result
item['content'] = content.replace('\n','')
item['content'] = content.replace('\t','')
item['content'] = content.replace(' ','')
item['content'] = content.replace('\t\n','')
item['content'] = content.replace(' \n','')
yield itemDownload Middleware
from scrapy import signals
from scrapy.http import HtmlResponse
import time
class WangyiDownloaderMiddleware(object):
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
if request.url in spider.un_url:
spider.bro.get(request.url)
time.sleep(3)
spider.bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(2)
spider.bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(2)
page_text = spider.bro.page_source
# A new construction method of response
new_response = HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request)
return new_response #After intercepting and tampering with the response, a new response object is sent again, and the response construction method
else:
return response
def process_exception(self, request, exception, spider):
pass
10. Crawlespider (whole station data crawling)
Create a crawler file based on crawlespider: scrape genspider - t crawle sun www.xxx.com
Crawlespider use
Access the content title and status of all pages of the sunshine hotline platform http://wz.sun0769.com/html/top/report.shtml
151711 records in total,Hundreds of pages,Realize the data crawling of hundreds of pages
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor #Link extractor
from scrapy.spiders import CrawlSpider, Rule# Rule rule parser
# Link extractor: extract links. You can extract the specified links according to the specified rules
# Extraction rule: allow = 'regular expression'
# Rule resolver: get the link extracted from the link, send the request, and analyze the source code data of the requested page according to the specified rule (callback)
class SunSpider(CrawlSpider):
name = 'sun'
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
link = LinkExtractor(allow=r'page=\d+')
rules = (
# Instantiate a rule object based on linkextractor
Rule(link, callback='parse_item', follow=True),
) # fllow=true continues to apply the link extractor to the page corresponding to the page number link extracted by the link extractor. If fllow = false, the resulting page data is only the displayed page number data of the current page
def parse_item(self, response):
tr_list = response.xpath('/html//div[8]/table[2]//tr')
for tr in tr_list:
title = tr.xpath('./td[3]/a[1]/@title').extract_first()
status = tr.xpath('./td[4]/span/text()').extract_first()
print(title,status)Depth crawling based on crawlespider: crawling detailed data in all pages
sun.py
import scrapy
from scrapy.linkextractors import LinkExtractor #Link extractor
from scrapy.spiders import CrawlSpider, Rule# Rule rule parser
from sun_spider.items import SunSpiderItem,SunSpiderItem_second
class SunSpider(CrawlSpider):
name = 'sun'
start_urls = ['http://wz.sun0769.com/index.php/question/report?page=']
# href="http://wz.sun0769.com/html/question/201912/437515.shtml"
link = LinkExtractor(allow=r'page=\d+')
link_detail = LinkExtractor(allow=r'question/\d+/\d+/.shtml')
rules = (
# Instantiate a rule object based on linkextractor
Rule(link, callback='parse_item', follow=True),
Rule(link_detail, callback='parse_detail'),
) # fllow=true continue to apply the link extractor to the page corresponding to the page number link extracted by the link extractor
def parse_item(self, response):
tr_list = response.xpath('/html//div[8]/table[2]//tr')
for tr in tr_list:
title = tr.xpath('./td[3]/a[1]/@title').extract_first()
status = tr.xpath('./td[4]/span/text()').extract_first()
num = tr.xpath('./td[1]/text()').extract_first()
item = SunSpiderItem_second()
item['title'] = title
item['status'] = status
item['num'] = num #For conditional storage of mysql database, num is the storage condition
if num:
yield item
def parse_detail(self,response):
content = response.xpath('/html/body/div[9]/table[2]/tbody/tr[1]/td//text()').extract()
num = response.xpath('/html/body/div[9]/table[1]/tbody/tr/td[2]/span[2]/text()').extract_first()
num = num.split(':')[-1]
if num:
content = ''.join(content)
item = SunSpiderItem()
item['content'] = content
item['num'] = num
yield itemitems.py
import scrapy
class SunSpiderItem(scrapy.Item):
# define the fields for your item here like:
content = scrapy.Field()
num = scrapy.Field()
class SunSpiderItem_second(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
status = scrapy.Field()
num = scrapy.Field()pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class SunSpiderPipeline(object):
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='123', db='spider',
charset='utf8')
def process_item(self, item, spider):
if item.__class__.__name__ == 'SunSpiderItem':
content = item['content']
num = item['num']
sql = f'insert into spider_crawl_sun values {(content)} where num={num}'
print(num)
# sql = 'insert into spider_crawl_sun values ("%s") where num=%s'%(content,num)
self.cursor = self.conn.cursor()
try:
self.cursor.execute(sql) # Commit the transaction if the execution is correct
self.conn.commit()
except Exception as e:
self.conn.rollback()
return item
elif item.__class__.__name__=='SunSpiderItem_second':
title = item['title']
status = item['status']
num = item['num']
sql = 'insert into spider_crawl_sun values ("%s","%s","%s")'%(title,status,num)
print(sql)
self.cursor = self.conn.cursor()
try:
self.cursor.execute(sql) # Commit the transaction if the execution is correct
self.conn.commit()
except Exception as e:
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
11. Improve the efficiency of crawler data
You need to configure the following five steps in the configuration file
Increase Concurrency:
By default, the number of concurrent threads opened by the script is 32, which can be increased appropriately. In the settings configuration file, change the value of "current" requests = 100 to 100, and set the concurrency to 100.
Lower log level:
In order to reduce the CPU utilization, there will be a lot of log information output when running the graph. You can set the log output information to INFO or ERROR. Write in configuration file: log'level ='INFO '
Forbidden cookie s:
If cookies are not really needed, then cookies can be forbidden when the data is crawled by the scrape to reduce the CPU utilization and improve the crawling efficiency. Write in configuration file: cookies'enabled = false
No retry:
Re requesting (retrying) failed HTTP slows down crawling, so retrying can be prohibited. Write in configuration file: retry? Enabled = false
Reduce download timeout:
If a very slow link is crawled, reducing the download timeout can make the stuck link quickly give up, thus improving the efficiency. Write in the configuration file: download? Timeout = 10s