What is the Selenium library?
Automated testing tools, support a variety of browsers. Support browsers include IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera, etc.
The crawler is mainly used to solve the problem of JavaScript rendering. Used to drive the browser and give the browser action.
Install the Selenium library: pip3 install selenium
Detailed usage of the Selcnium library:
Before using it, we need to install the webDriver driver, the specific installation method, Baidu itself, and remember the corresponding version.
Basic use:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Basic Usage from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait browser = webdriver.Chrome() try: browser.get("http://www.baidu.com") input = browser.find_element_by_id('kw') input.send_keys('Python') input.send_keys(Keys.ENTER) wait = WebDriverWait(browser, 10) wait.until(EC.presence_of_element_located((By.ID,'content_left'))) print(browser.current_url) print(browser.get_cookies()) print(browser.page_source) finally: browser.close()
If this code works, it means that your version of webDriver is correct (you need to install Google Browser)
Operation results:
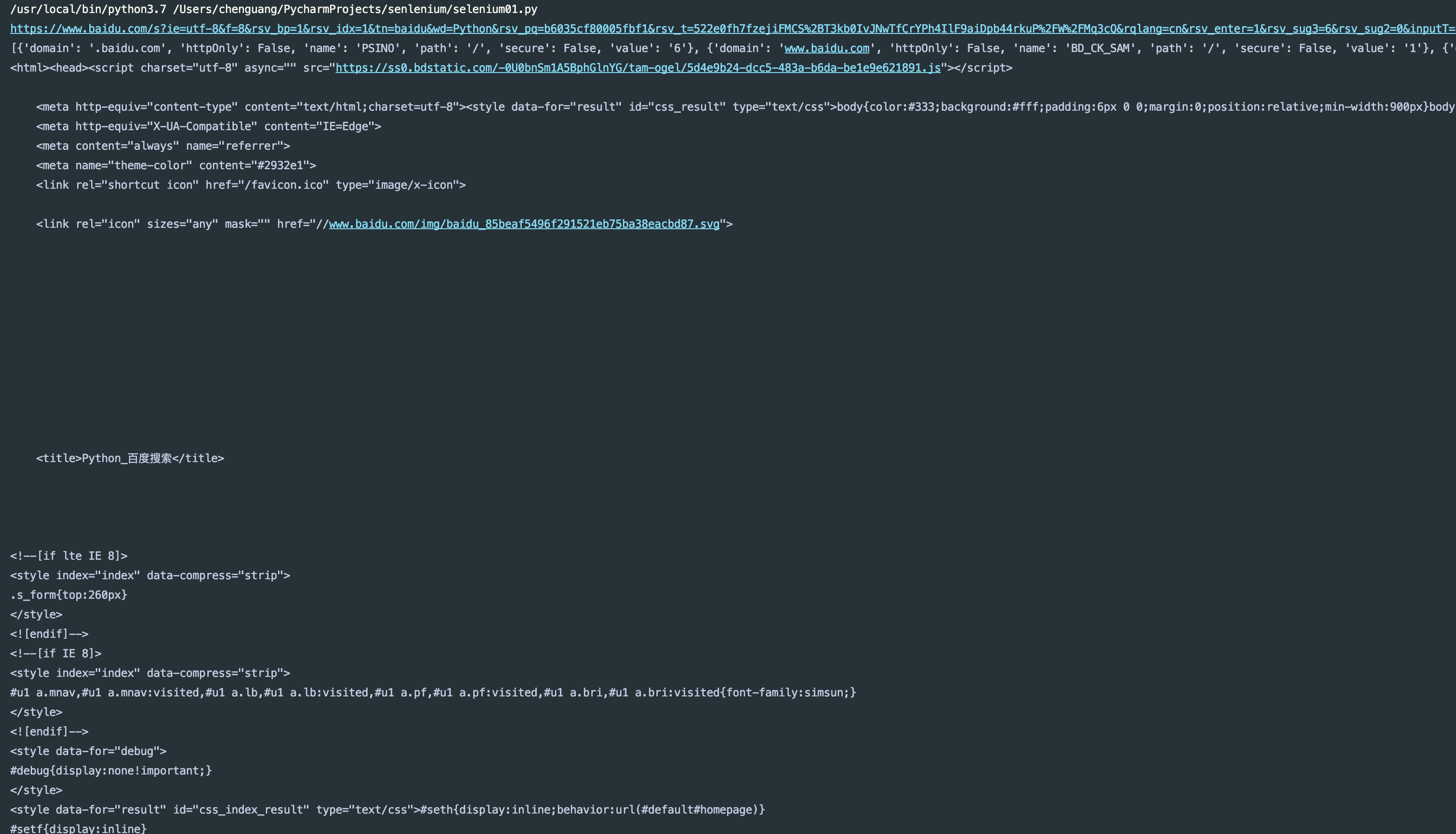
Declare browser objects:
Just now we said that Selenium supports multiple browsers. Let me see how to make the declarations separately.
#!/usr/bin/env python # -*- coding: utf-8 -*- # Declare Browser Objects from selenium import webdriver browser = webdriver.Chrome() browser = webdriver.Safari() browser = webdriver.Edge() browser = webdriver.Firefox() browser = webdriver.PhantomJS()
I don't have those browsers installed here, so I won't run the code for you. I recommend using Chrome Browser (Google Browser).
Access page:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Access page from selenium import webdriver browser = webdriver.Chrome() browser.get("http://baidu.com") print(browser.page_source) browser.close()
Operation results:
Find Elements:
Single element:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Find elements, single elements from selenium import webdriver browser = webdriver.Chrome() browser.get("http://taobao.com") input_first = browser.find_element_by_id('q') input_second = browser.find_element_by_css_selector('#q') input_three = browser.find_element_by_xpath('//*[@id="q"]') print(input_first) print(input_second) print(input_three) browser.close()
Operation results:

-
find_element_by_name
-
find_element_by_xpath
-
find_element_by_link_text
-
find_element_by_partial_link_text
-
find_element_by_tag_name
-
find_element_by_class_name
-
find_element_by_css_selector
These are all search methods.
It can also be found in a general way:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Find elements, single elements from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.get("http://taobao.com") input_first = browser.find_element(By.ID,'q') print(input_first) browser.close()
Operation results:

Multiple elements:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Find elements, multiple elements from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.get("http://taobao.com") input_first = browser.find_elements_by_css_selector('.service-bd li') for i in input_first: print(i) browser.close()
Operation results:
There are many other methods that exactly match the find_elment usage, returning a list of data.
Element Interaction:
Call the interaction method for the acquired element:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Element Interaction from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.get("http://baidu.com") input_first = browser.find_element(By.ID,'kw') input_first.send_keys('python From Entering the Pit to Abandoning') button = browser.find_element_by_class_name('bg s_btn') button.click()
Running the code, we will see the Chrome browser open, and enter the content to search, and then click the search button. More Operational Access Address: https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement
Interaction:
Attach actions to the action chain for serial execution
#!/usr/bin/env python # -*- coding: utf-8 -*- # Interactive operation from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = 'https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to.frame('iframeResult') source = browser.find_element_by_id('draggable') target = browser.find_element_by_id('droppable') actions = ActionChains(browser) actions.drag_and_drop(source, target) actions.perform()
Running the code, we will see that the internal slider has been dragged and pulled. More detailed operations are available: https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
Implementing Javascript:
#!/usr/bin/env python # -*- coding: utf-8 -*- # implement javascript from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.zhihu.com/explore') browser.execute_script('window.scrollTo(0,document.body.scrollHeight)') browser.execute_script('alert("Eject")')
Running the code, we can see that the scrollbar is pulled down and the pop-up box is given.
Get element information:
Get attributes:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Getting element information: Getting attributes from selenium import webdriver browser = webdriver.Chrome() url = "http://www.zhihu.com/explore" browser.get(url) logo = browser.find_element_by_id('zh-top-link-logo') print(logo) print(logo.get_attribute('class'))
Operation results:

Get the text value:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Get text values from selenium import webdriver browser = webdriver.Chrome() url = "http://www.zhihu.com/explore" browser.get(url) question = browser.find_element_by_class_name('zu-top-add-question') print(question.text)
Operation results:

Get ID, location, label name, size:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Obtain ID,Location, label name, size from selenium import webdriver browser = webdriver.Chrome() url = "http://www.zhihu.com/explore" browser.get(url) question = browser.find_element_by_class_name('zu-top-add-question') print(question.id) print(question.location) print(question.tag_name) print(question.size)
Operation results:

Frame:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Frame from selenium import webdriver from selenium.common.exceptions import NoSuchElementException browser = webdriver.Chrome() url = 'https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to.frame('iframeResult') source = browser.find_element_by_id('draggable') print(source) try: logo = browser.find_element_by_class_name('logo') except NoSuchElementException: print("NO LOGO") browser.switch_to.parent_frame() logo = browser.find_element_by_class_name('logo') print(logo) print(logo.text)
Operation results:

Wait:
Implicit waiting:
When implicit wait is used to execute tests, if WebDriver does not find elements in the DOM, it will continue to wait, and if it exceeds the set time, it will throw an exception that cannot find elements. In other words, when the element or the lookup element does not appear immediately, implicit wait will wait for a period of time to find the DOM, the default time is 0.
#!/usr/bin/env python # -*- coding: utf-8 -*- # Implicit waiting from selenium import webdriver browser = webdriver.Chrome() url = "http://www.zhihu.com/explore" browser.get(url) input = browser.find_element_by_class_name('zu-top-add-question') print(input)
Operation results:

Display Waiting: More Commonly Used
#!/usr/bin/env python # -*- coding: utf-8 -*- # Display wait from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait browser = webdriver.Chrome() browser.get("http://www.taobao.com") wait = WebDriverWait(browser, 10) wait.until(EC.presence_of_element_located((By.ID,'q'))) button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'.btn-search'))) print(input,button)
- The title_is title is something.
-
title_contains heading contains something
-
The presence_of_element_location element is loaded out and passed into the location meta-ancestor, such as (By.ID,'p')
-
The visibility_of_element_location element is visible and passed into the location meta-ancestor
-
visibility_of is visible, passing in element objects
-
presence_of_all_elements_located All elements are loaded out
-
text_to_be_present_in_element An element text contains a text
-
Tex_to_be_present_in_element_value An element value contains a text
-
frame_to_be_available_and_switch_to_it loads and switches
-
invisibility_of_element_located element invisible
-
element_to_be_clickable element clickable
-
staleness_of determines whether an element is still in the DOM and whether the page has been refreshed
-
element_to_be_selected element is optional, passing element objects
-
The element_located_to_be_selected element can be selected and passed into the location meta-ancestor.
-
element_selection_state_to_be passes in the element object and state, returning True equally or False otherwise.
-
Element_location_selection_state_to_be passes in the location ancestor and state, returning True equally or False otherwise.
-
Whether Alert appears in alert_is_press
For details, you can read the official address: https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
Forward and backward:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Forward and backward from selenium import webdriver browser = webdriver.Chrome() browser.get("http://www.taobao.com") browser.get("http://www.baidu.com") browser.get("http://www.zhihu.com") browser.back() browser.forward()
Running the code, we'll see that the priority is taobao.com, then open baidu.com, and finally open zhihu.com, then perform the back and forward actions.
Cookies:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Cookies from selenium import webdriver browser = webdriver.Chrome() browser.get("http://www.zhihu.com") print(browser.get_cookies()) browser.add_cookie({'name':'admin','domain':'www.zhihu.com','value':'cxiaocai'}) print(browser.get_cookies()) browser.delete_all_cookies() print(browser.get_cookies())
Operation results:

Tab management:
#!/usr/bin/env python # -*- coding: utf-8 -*- # Tab management from selenium import webdriver browser = webdriver.Chrome() browser.get("http://www.baidu.com") browser.execute_script('window.open()') print(browser.window_handles) browser.switch_to.window(browser.window_handles[1]) browser.get('http://www.taobao.com') browser.switch_to.window(browser.window_handles[0]) browser.get('http://www.zhihu.com')
You can also use the browser's shortcut keys to open the window (it is not recommended to use this, it is recommended to use the above way to manage the tabs)
Exception handling:
#!/usr/bin/env python # -*- coding: utf-8 -*- # exception handling from selenium import webdriver from selenium.common.exceptions import TimeoutException,NoSuchElementException browser = webdriver.Chrome() try: browser.get("http://www.baidu.com") except TimeoutException: print("request timeout") try: browser.find_element_by_id('hello') except NoSuchElementException: print("NoSuchElementException")
Operation results:

Due to the complexity of exception handling, there are many exceptions, not listed here one by one, I suggest you go to the official website to check, address: https://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions
The above code address: https://gitee.com/dwyui/senlenium.git
So far as the use of Selenium library is concerned, python's reptile library has said so much, urllib,Requests,BeautfuliSoup,PyQuery and today's Selenium library. Tomorrow, I will start to explain the real case directly. Recently, I will sort out a few simple reptile cases.