Python crawler crawl complete novel
Python version: Python 3.0 x
Running platform: Windows
preface
Web crawler (also known as web spider, web robot, more often called web chaser in FOAF community) is a program or script that automatically grabs World Wide Web information according to certain rules. Other infrequently used names include ants, automatic indexing, emulators, or worms..
Tip: the following is the main content of this article. The following cases can be used for reference
1, Foundation and environment
Sharp tools make good work
1.1 Web elements
If you want to crawl the content of the website, you must know how the website is rendered, which requires you to know the role of Web elements in Web page rendering (those familiar with it can skip)
Review elements
How can I know what elements a website has?
The most convenient and convenient way, shortcut key F12
After pressing F12, the browser display page is shown in the red box below:

We can see intuitively
- The website consists of tag pairs
- There are attributes and attribute values in the label pair
In order to more intuitively display the directory structure of the website, you can click the Sources (or resources) column
As shown in the figure below
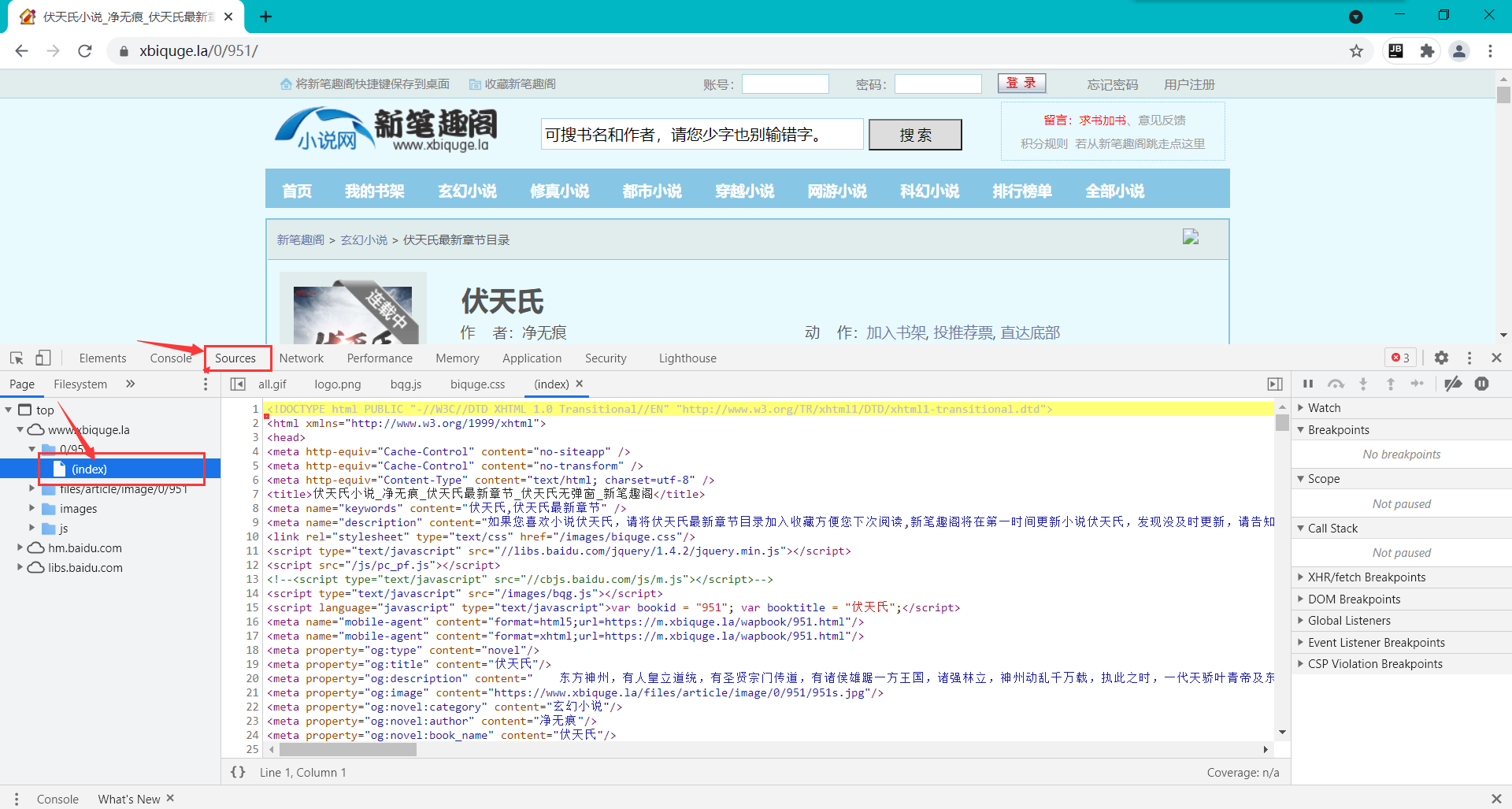
We can clearly see that all we want to see appears in tag pairs or attribute values.
1.2 installation of requests and lxml Libraries
The first step of the web crawler is to get the HTML information of the web page according to the URL.
In Python 3, you can use requests to crawl web pages.
Search and extract tag pairs using lxml
- The requests library and lxml library are third-party libraries that we need to install ourselves.
(1) Requests library and lxml library installation
In order to speed up the installation, the image of Tsinghua University is used here
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
(2) Brief introduction to Requests Library
Detailed introduction here
The basic method of requests library is as follows:

Official Chinese Course
(3) Brief introduction to lxml Library
Detailed introduction here
lxml library search rules for tag or attribute values
| expression | describe |
|---|---|
| // | Select descendant node from current node |
| / | Select direct child node from current node |
| @ | Select Properties |
| [@attrib] | Selects all elements with the given attribute |
| [@attrib='value'] | Selects all elements with a given value for a given attribute |
| text() | Text to select |
2, Use steps
It is divided into directory crawling, novel chapter crawling and complete novel crawling
2.1 directory crawling
2.1.1 using Requests to obtain page information
The code is as follows:
import requests url = "https://www.xbiquge.la/xiaoshuodaquan/" response = requests.get(url) response.encoding="utf-8" html = response.text print(html)
The results are shown in the figure below
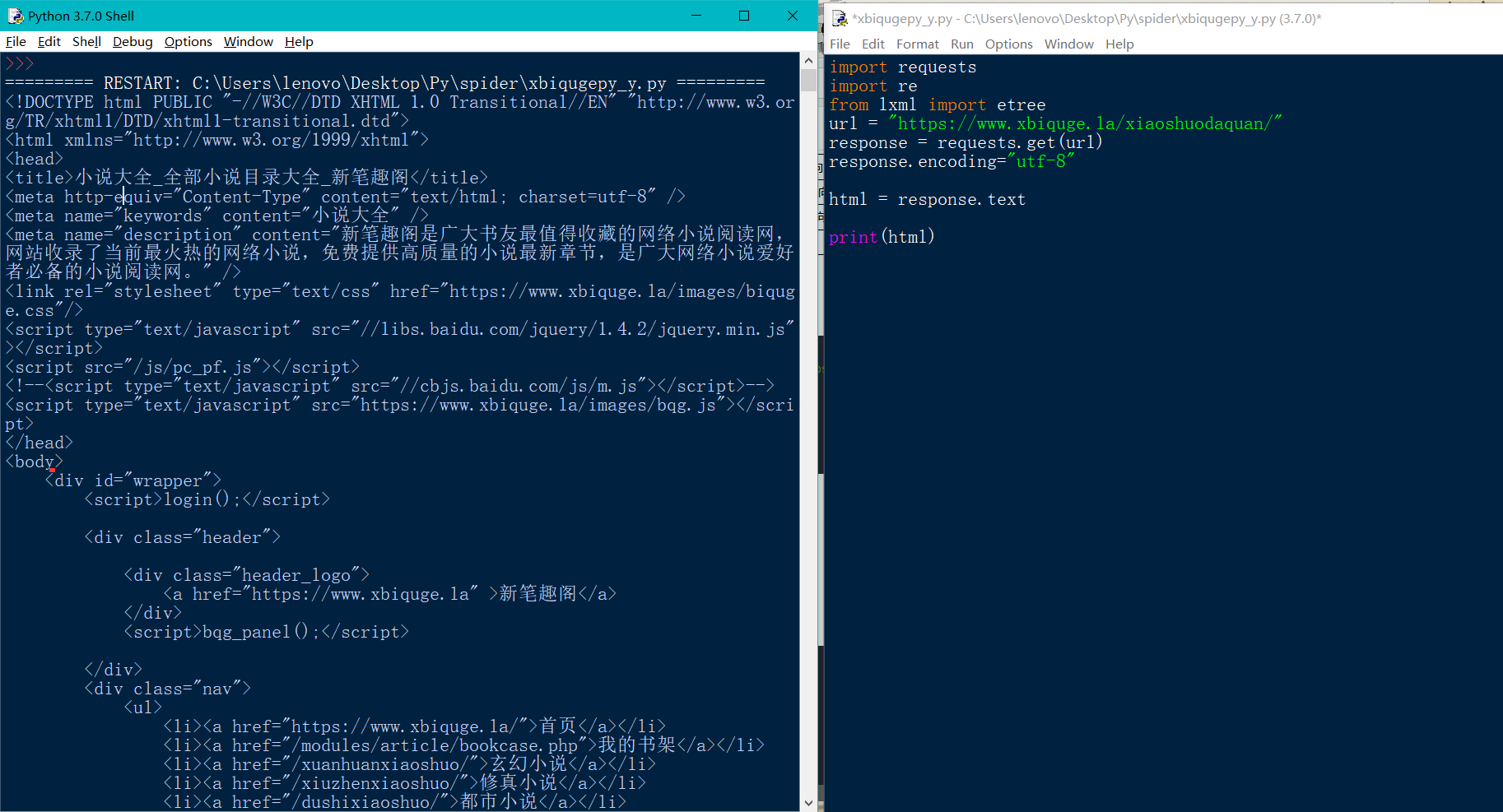
Some of the information we need:
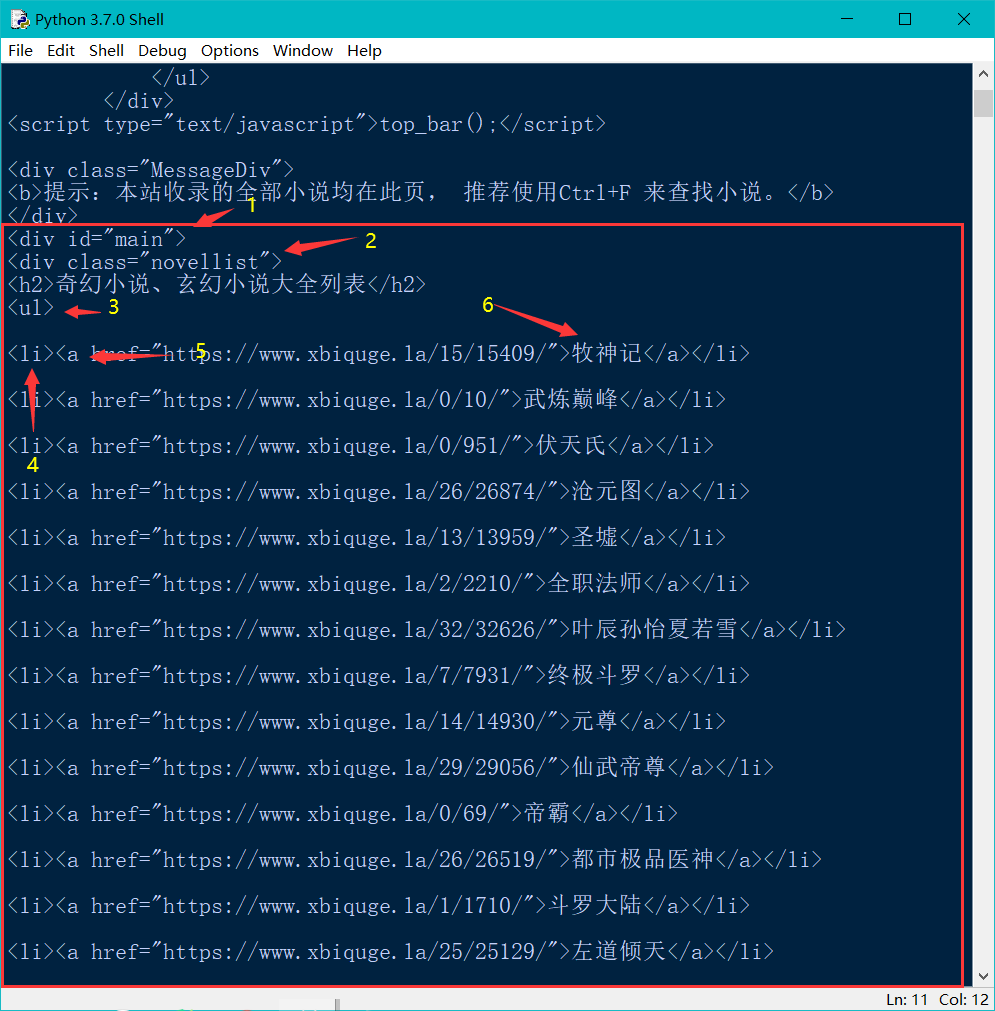
2.1.2 information extraction using rules in lxml
The code is as follows:
import requests
import re
from lxml import etree
url = "https://www.xbiquge.la/xiaoshuodaquan/"
response = requests.get(url)
response.encoding="utf-8"
html = response.text
#ele
ele = etree.HTML(html)
book_names = ele.xpath("//div[@id='main']/div[@class='novellist']/ul/li/a/text()")
book_urls = ele.xpath("//div[@id='main']/div[@class='novellist']/ul/li/a/@href")
#s = ''
print(book_names[0])
print(book_urls[0])
You can get:

2.1.3 write to the file in the form of stream
The code is as follows:
s = ''
for book_name in range(len(book_names)):
s += book_names[book_name] + '\n' + book_urls[book_name] + '\n'
with open('title.txt','w') as file:
file.writelines(s)
print("Input complete")
2.2 novel chapter crawling
2.2.1 read the title file to get the url
Here take the first novel "the story of shepherd God" as an example
The code is as follows:
import requests
from lxml import etree
with open("title.txt",'r') as file:
s = file.read()
#print(s)
s = s.split("\n")
title = s[0]
url = s[1]
print(title)
print(url)

2.2.2 using Requests to obtain page information
response = requests.get(url) response.encoding="utf-8" html = response.text
2.2.3 information extraction using rules in lxml
ele = etree.HTML(html)
book_chapters = ele.xpath("//div[@class='box_con']/div[@id='list']/dl/dd/a/text()")
book_c_urls = ele.xpath("//div[@class='box_con']/div[@id='list']/dl/dd/a/@href")
2.2.4 write to the file in the form of stream
s = ""
for book_chapter in range(len(book_chapters)):
s += book_chapters[book_chapter] + "\n" + book_c_urls[book_chapter] + "\n"
with open("chapter.txt","w") as f:
f.write(s)
2.3 novel crawling
2.3.1 read the chapter file to get the url
with open("chapter.txt",'r') as file:
s = file.read()
#print(s)
s = s.split("\n")
chapter_titles = s[::2]
chapter_urls = s[1::2]
2.3.2 using Requests to obtain page information
o_url = "https://www.xbiquge.la"
#new_url = o_url + chapter_urls[0]
pbar = tqdm(range(len(chapter_urls)))
for i in pbar:
new_url = o_url + chapter_urls[i]
#print(new_url)
response = requests.get(new_url)
response.encoding="utf-8"
html = response.text
2.3.3 data cleaning
def remove_upprintable_chars(s):
"""Remove all invisible characters"""
return ''.join(x for x in s if x.isprintable())
2.3.4 information extraction using rules in lxml
ele = etree.HTML(html)
book_bodys = ele.xpath("//div[@id='content']/text()")
2.3.5 write to the file in the form of stream
s = "\n"+chapter_titles[i]+"\n"
for book_body in book_bodys:
c = "".join(book_body.split())
c = remove_upprintable_chars(c)
s += c
with open("Shepherd God.txt","a") as f:
f.write(s)
3, Complete code
The code is as follows:
Directory crawling
import requests
import re
from lxml import etree
url = "https://www.xbiquge.la/xiaoshuodaquan/"
response = requests.get(url)
response.encoding="utf-8"
html = response.text
#ele
ele = etree.HTML(html)
book_names = ele.xpath("//div[@id='main']/div[@class='novellist']/ul/li/a/text()")
book_urls = ele.xpath("//div[@id='main']/div[@class='novellist']/ul/li/a/@href")
s = ''
for book_name in range(len(book_names)):
s += book_names[book_name] + '\n' + book_urls[book_name] + '\n'
with open('title.txt','w') as file:
file.writelines(s)
print("Input complete")
Novel chapter crawling
import requests
from lxml import etree
with open("title.txt",'r') as file:
s = file.read()
#print(s)
s = s.split("\n")
title = s[0]
url = s[1]
#print(title)
#print(url)
response = requests.get(url)
response.encoding="utf-8"
html = response.text
#print(html)
ele = etree.HTML(html)
book_chapters = ele.xpath("//div[@class='box_con']/div[@id='list']/dl/dd/a/text()")
#book_author = ele.xpath("")
book_c_urls = ele.xpath("//div[@class='box_con']/div[@id='list']/dl/dd/a/@href")
s = ""
for book_chapter in range(len(book_chapters)):
s += book_chapters[book_chapter] + "\n" + book_c_urls[book_chapter] + "\n"
with open("chapter.txt","w") as f:
f.write(s)
print("Input completed!")
Novel crawling
import requests
from lxml import etree
from tqdm import tqdm
with open("chapter.txt",'r') as file:
s = file.read()
#print(s)
s = s.split("\n")
chapter_titles = s[::2]
chapter_urls = s[1::2]
def remove_upprintable_chars(s):
"""Remove all invisible characters"""
return ''.join(x for x in s if x.isprintable())
o_url = "https://www.xbiquge.la"
#new_url = o_url + chapter_urls[0]
pbar = tqdm(range(len(chapter_urls)))
for i in pbar:
new_url = o_url + chapter_urls[i]
#print(new_url)
response = requests.get(new_url)
response.encoding="utf-8"
html = response.text
#print(html)
ele = etree.HTML(html)
book_bodys = ele.xpath("//div[@id='content']/text()")
#print(book_bodys[0])
s = "\n"+chapter_titles[i]+"\n"
for book_body in book_bodys:
c = "".join(book_body.split())
c = remove_upprintable_chars(c)
s += c
with open("Shepherd God.txt","a") as f:
f.write(s)
print("The article "record of shepherd God" has been downloaded!")
summary
The crawler is relatively simple. It can only crawl simple novels, but it can not achieve a certain degree of data integrity. It is being improved~~