xpath review
Import third-party libraries, make requests to web pages, get html files, load html files into elementary objects and load them into tree s, then you can use the xpath method, which is an indeterminate path. By passing in the determined path as a string, you can find elements based on the path.
Requirements:
Remove the text and class values from the first three li tags and save them in the csv file
from lxml import etree
import csv
# etree contains some features of xpath
html = """
<html>
<head>
<title>test</title>
</head>
<body>
<li class="item-0">first item</li>
<li class="item-1">second item</li>
<li class="item-inactive">third item</li>
<li class="item-1">fourth item</li>
<div>
<li class="item-0">fifth item</li>
</div>
<span>
<li class="item-0">sixth item</li>
<div>
<li class="item-0">eighth item</li>
</div>
</span>
</body>
</html>
"""
tree = etree.HTML(html)
# Requirements: Get content from the first three li Tags
# /Represents hierarchical relationships, //Represents child bytes (descendant content)
# text = tree.xpath('//li/text()') # ['first item', 'second item', 'third item', 'fourth item', 'fifth item', 'sixth item', 'eighth item']
# Displays all content in li as a list, indexed by subscripts, left-closed, right-open, and obtains attributes without using text()
text = tree.xpath('//li/text()')[:3] # ['first item', 'second item', 'third item']
cs = tree.xpath('//Li/@class') [:3] # ['item-0','item-1','item-inactive'], get the attribute value of the class
# Stored as {'class':'item-0','text':'first item'},{'class':'item-1','text':'second item'}
# print(text)
# print(cs)
lis_data = [] # Used to store all data
for c in cs:
d = {} # Define a dictionary to hold a piece of data
# print(c) # item-0 item-1 item-inactive
# # print(cs.index(c)) # 0 1 2 Print content and index value one-to-one correspondence
# print(text[cs.index(c)])
# print('*'*50) # Loop through pairs to extract text and attribute values.
d['class'] = c
d['text'] = text[cs.index(c)] # Loop to add key and value values to an empty dictionary
# print(d)
lis_data.append(d) # Add the obtained dictionary to the empty list
# print(lis_data)
# Save data
header = ('class', 'text')
with open('lis_data.csv', 'w', encoding='utf-8', newline="") as f:
write = csv.DictWriter(f, header)
write.writeheader()
write.writerows(lis_data)
Case Study: Crawling a Top250 Valve
target
How to parse data with xpath and become familiar with how xpath parses data.
By observing the target site to understand the crawling requirements, the data is ultimately saved in csv.
demand
What to crawl: Title Rating Number of Ratings Quote Details Page url
Page Analysis
First copy part of the content to see if it is in the source of the web page, click the right mouse button to see the source of the web page. From the picture below, you can see that all the content we need is in the source of the web page. We only need to target the web site. https://movie.douban.com/top250 ) Initiate a request and extract the data from the source code of the web page. The web site is loaded statically and belongs to server rendering. To get 250 pages of data, you have to crawl the contents of the first page and change the start value dynamically to get data from other pages.
Target url: https://movie.douban.com/top250
We can try changing the url of the first page to start=0 and still access the first page
Page flipping:
https://movie.douban.com/top250?start=0 Page 1 025
https://movie.douban.com/top250?start=25 Page 2 125
https://movie.douban.com/top250?start=50 Page 3 225
https://movie.douban.com/top250?start=75 Page 4 325
start = (page-1) * 25
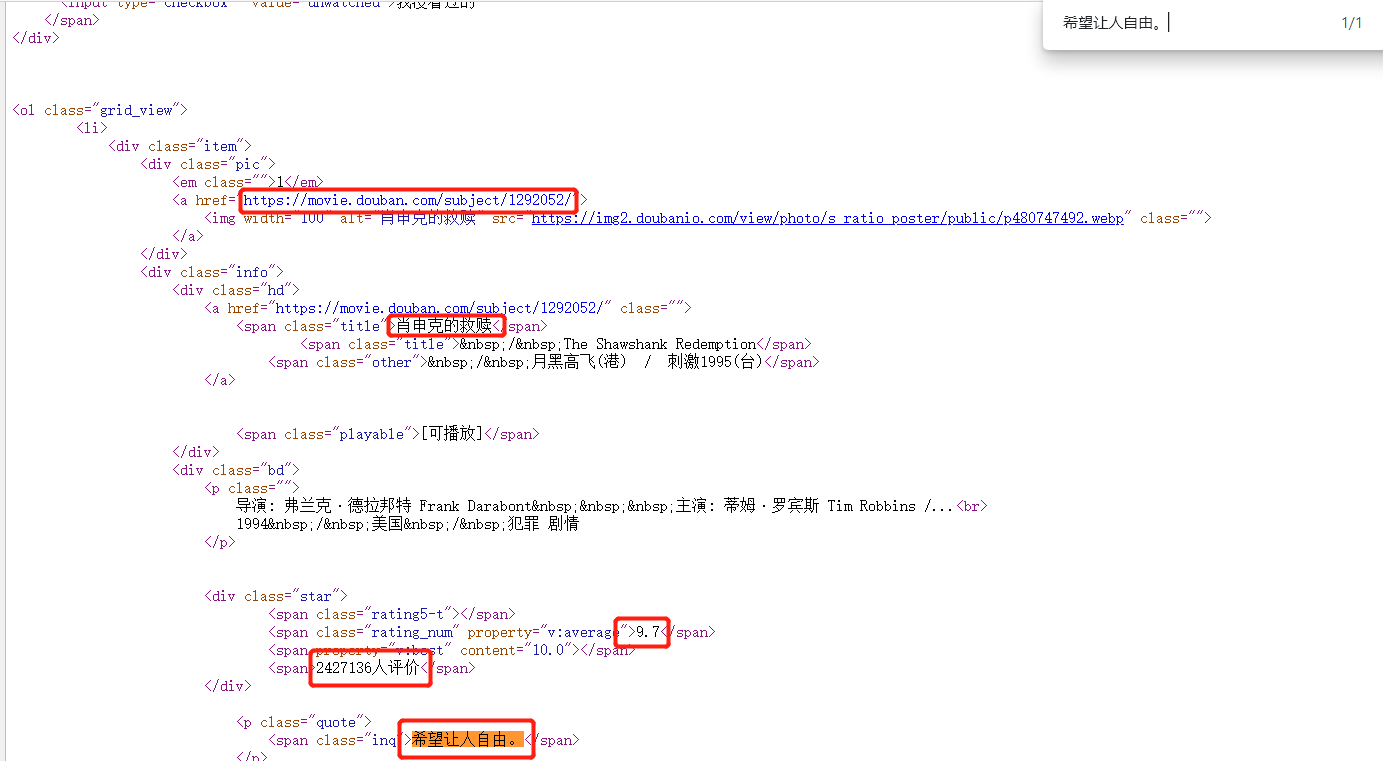
Mouse over the name of the first movie on the page, right-click, check, you can see that when the cursor is placed at the Salvation of Shawson, the corresponding title is highlighted, and the entire movie's information is highlighted at <div class = "info", indicating that the information needed is under this label; Place the cursor at <div class = "pic" and the picture is highlighted so that you can get the information of the picture at this time. When the cursor is placed at <. li>, all the information of the first movie is highlighted, indicating that the <. li> tag contains the information of the entire movie; Look further at a total of 25 /<. li> tags, with the cursor on each tag corresponding to 25 movies on this page. Elementation is loaded last, but we still want to go to the web source to see if it is consistent, such as copying'class='info'to the web source, you can see 25 identical tags.
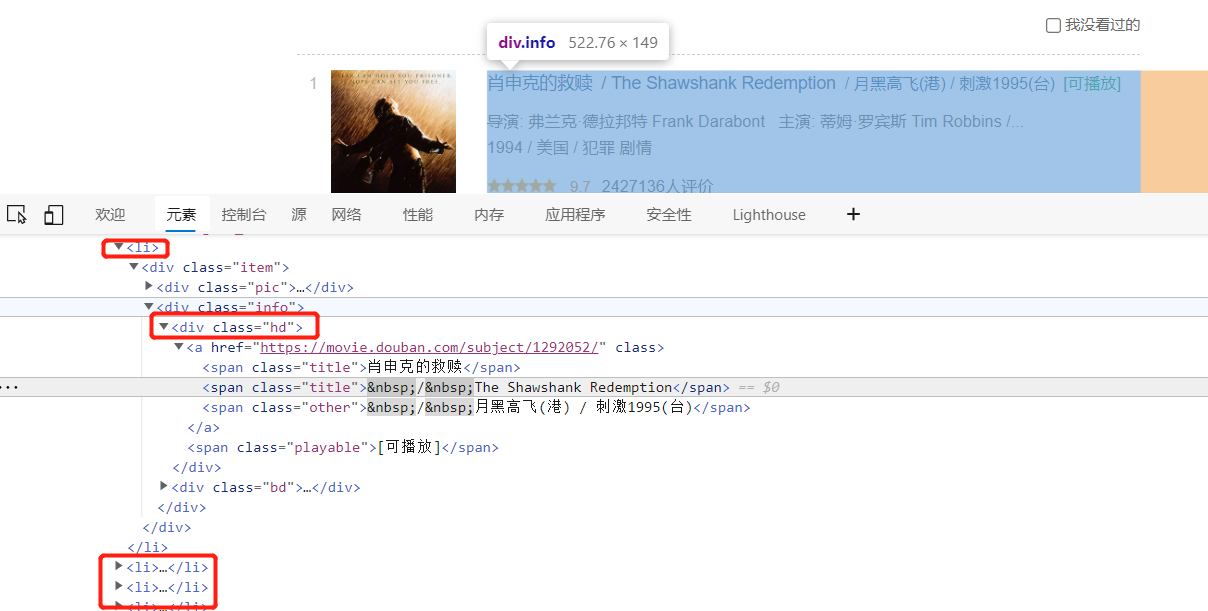
Open xpath helper with shortcut CTRL+shift+x to find the location of the movie name
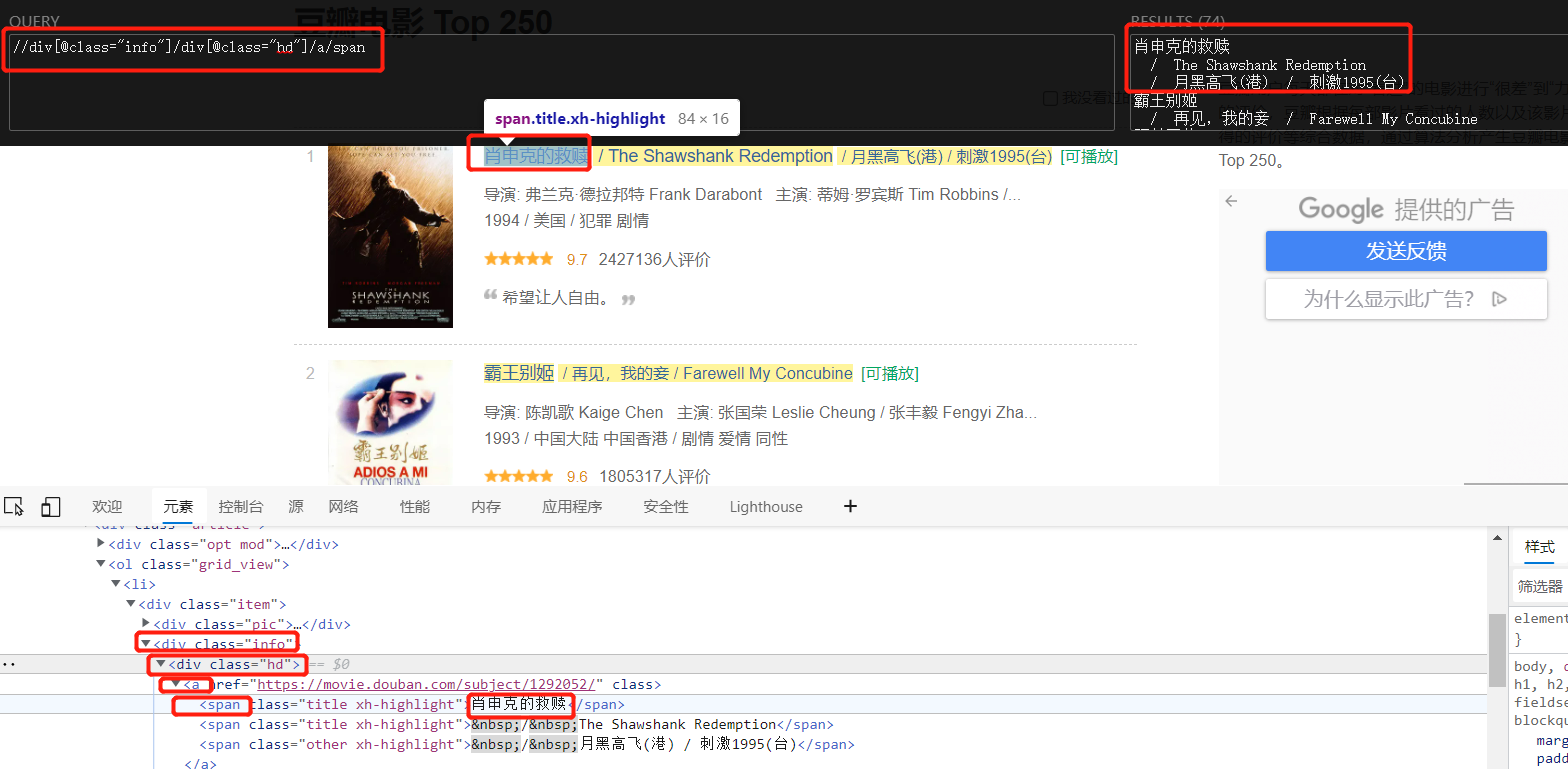
step
- Send request, get web page source, first function
- Get the source code, parse the data, second function. Each piece of data is placed in a div tag with class="info" of a li tag and parsed in a div tag with class="info"
- Save data, third function. [{'title':'xxx','score':'xxx','com_num':'xxx','quote':'xxx','link_url':'xxxx'}, {xxx},{xxx}]
*Tools needed: requests xpath csv
code implementation
import requests
from lxml import etree
import csv
# Send the request and get it accordingly. Incoming url to initiate the request
def get_url(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
res = requests.get(url, headers=headers)
html = res.content.decode("utf-8")
# print(html)
return html
# Parse data
def s_sourse(h):
# Loading Web page source code into an element object
tree = etree.HTML(h)
divs = tree.xpath('//div[@class="info"]')
# print(len(divs)) # 25
last_data = [] # List holding all data
for div in divs: # Use xpath to get info information for all movies and extract it from each movie object
d = {} # A dictionary used to store one piece of data
# print(div)
# Use the relative path of the object to get the information for each movie. The subscript of the list starts at 0, and strip() removes the blank characters at the beginning and end of the string.
# If you remove the white space in the middle of a string, you can use replace()
title = div.xpath('./div[@class="hd"]/a/span[@class="title"][1]/text()')[0].strip()
score = div.xpath('./div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0].strip()
com_mun = div.xpath('./div[@class="bd"]/div[@class="star"]/span[4]/text()')[0].strip()
quote = div.xpath('./div[@class="bd"]/p/span/text()')
link_url = div.xpath('./div[@class="hd"]/a/@href')[0].strip()
# print(title, score, com_mun, quote, link_url)
# [0].strip() takes out the first element of the list for easy storage
# Add to empty dictionary as key, value value
d['title'] = title
d['score'] = score
d['com_mun'] = com_mun
if quote:
d['quote'] = quote[0].strip()
else:
d['quote'] = ""
d['link_url'] = link_url
# print(d)
# Insert a dictionary containing one piece of data into the list
last_data.append(d)
# The data for each movie is stored in a dictionary and for all movies in a large list
# print(last_data)
return last_data
# Save data
def save_page(last_data, header):
# w starts from scratch and a is an append
with open('movie_data2.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
# Write headers no longer pass arguments
writ.writeheader()
# writerows writes multiple rows of data at a time
writ.writerows(last_data)
# Main function calls function
def main():
for m in range(10):
print(f'Crawling #{m}page')
url = f'https://movie.douban.com/top250?start={m*25}'
# url = f'https://movie.douban.com/top250'
h = get_url(url)
# Headers can be passed in as dictionaries, lists, tuples
header = ('title', 'score', 'com_mun', 'quote', 'link_url')
lis = s_sourse(h)
save_page(lis, header)
if __name__ == '__main__':
main()
So far, page crawling has been implemented. There is a pit here. It is important to note that there will be a blank quote section, which causes the program to appear "IndexError: list index out of range". When taking a quote, "quote = div.xpath('. /div[@class="bd"]/p/span/text()')", which cannot be followed by [0]. Strip(), because the data you get is blank, you will have problems with the results when you remove the blanks. This part of the normal value, when added to the dictionary, to judge the quote, if not empty, return "quote[0].strip()", empty directly return ", so as to avoid errors.
Once you get the results, you will find that the headers are printed repeatedly. Here are a few ways to remove duplicate headers.
Method 1: Change only the main function
def main():
data_box = [] # Define a box to hold all the data
# Headers can be passed in as dictionaries, lists, tuples
header = ('title', 'score', 'com_mun', 'quote', 'link_url')
for m in range(10):
time.sleep(5)
print(f'Crawling #{m}page')
url = f'https://movie.douban.com/top250?start={m * 25}'
# url = f'https://movie.douban.com/top250'
h = get_url(url)
data_box += s_sourse(h) # Put all the return values of the function in a box
# print(data_box)
save_page(data_box, header)
Method 1: Define a box in the main function that holds all the data, put all the data you get into the box, and then put the box data_box passed as a parameter to save_ In the page() function, when you print multiple lines, you only print data. During the test, the IP was blocked, using the proxy IP settings described in the crawler file (3), and the cookie s after someone else enters the web page in the request header can be accessed normally. To avoid being blocked again, a time limit was added.
Method 2: Write the header in the main function ahead of time, and after the loop save_page()Only write data in
def save_page(last_data, header):
# w starts from scratch and a is an append
with open('movie_data3.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
# writerows writes multiple rows of data at a time
writ.writerows(last_data)
# Main function calls function
def main():
header = ('title', 'score', 'com_mun', 'quote', 'link_url')
with open('movie_data3.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
writ.writeheader()
for m in range(10):
time.sleep(5)
print(f'Crawling #{m}page')
url = f'https://movie.douban.com/top250?start={m * 25}'
# url = f'https://movie.douban.com/top250'
h = get_url(url)
lis = s_sourse(h) # Put all the return values of the function in a box
# print(data_box)
save_page(lis, header)
Method 2: In the main function, first write the header of the file outside the loop, and then write the data save_ When page, only the crawled data is written.
Method 3: Write the header in the main function first, without writing the function, and write the multiline data directly.
def main():
header = ('title', 'score', 'com_mun', 'quote', 'link_url')
f = open('movie_data4.csv', 'a', encoding='utf-8', newline="")
writ = csv.DictWriter(f, header)
# Write headers no longer pass arguments
writ.writeheader()
for m in range(10):
time.sleep(5)
print(f'Crawling #{m}page')
url = f'https://movie.douban.com/top250?start={m*25}'
# url = f'https://movie.douban.com/top250'
h = get_url(url)
# Headers can be passed in as dictionaries, lists, tuples
lis = s_sourse(h)
# save_page(lis, header)
writ.writerows(lis)
Method 3: Write the header directly in main function, data parsing function s_ Sorse no longer writes data to function save_page is uploaded and stored directly in a table
Method 4: Define traversal in the main function m Is a global variable, when writing a function m Make a judgment, write the header the first time you write, otherwise don't write the header
# Save data
def save_page(last_data, header):
# w starts from scratch and a is an append
with open('movie_data5.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
if m == 0:
writ.writeheader()
# writerows writes multiple rows of data at a time
writ.writerows(last_data)
# Main function calls function
def main():
global m
for m in range(10):
time.sleep(5)
print(f'Crawling #{m}page')
url = f'https://movie.douban.com/top250?start={m * 25}'
# url = f'https://movie.douban.com/top250'
header = ('title', 'score', 'com_mun', 'quote', 'link_url')
h = get_url(url)
lis = s_sourse(h) # Put all the return values of the function in a box
# print(data_box)
save_page(lis, header)
Method 4: The clever point is that the "m" used for traversal is defined as a global variable in main, which allows m to be used in other functions, and in save_ M is judged in page. If 0 is the first page written, the header is written, otherwise the header is not written.