About the crawler crawling data and storing it in MySQL database (take the stock data on Dongfang fortune online as an example, web page: Shennan power A(000037) capital flows to data center Dongfang fortune network)
The first step is to create a data table in the database
import requests
import pandas as pd
import re
import pymysql
db = pymysql.connect(host='localhost', user='root', password='ls101945', db='Eastmoney', port=3306, charset='utf8')
cursor = db.cursor()#Create cursor
cursor.execute("DROP TABLE IF EXISTS Eastmoney")#If there is a table called Oriental Wealth, delete the table
sql = """
create table Eastmoney(
date char(20) not null,
Net inflow of main forces char(20),
Net inflow of small orders char(20),
Net inflow of medium order char(20),
Net inflow of large orders char(20),
Net inflow of super large single char(20) ,
Proportion of main net inflow char(20),
Proportion of small single net inflow char(20),
Proportion of net inflow in single char(20),
Proportion of large single net inflow char(20),
Proportion of super large single net inflow char(20),
Closing price char(20),
Fluctuation range char(20))
"""
try:#If an exception occurs, handle the exception
# Execute SQL statement
cursor.execute(sql)
print("Database created successfully")
except Exception as e:
print("Failed to create database: case%s" % e)Import pymysql, connect to Dongfang wealth database, enable cursor function and create cursor object (Note: when the cursor function is enabled to execute this sql statement, the system will not print the results directly to the frequency screen, but will find a place to store the above results and provide a cursor interface to us. When you need to obtain data, you can get data from it) , use sql statements to create data tables, design field names and types, and whether they can be null. Use the execute() method to execute sql statements. In program development, if the execution of some code is uncertain (the program syntax is completely correct), you can add try to catch exceptions. Try: the code you are trying to execute, except: the handling of errors.
Step 2: crawl data
Left click Check network in the target web page to refresh the web page and find the location of data storage
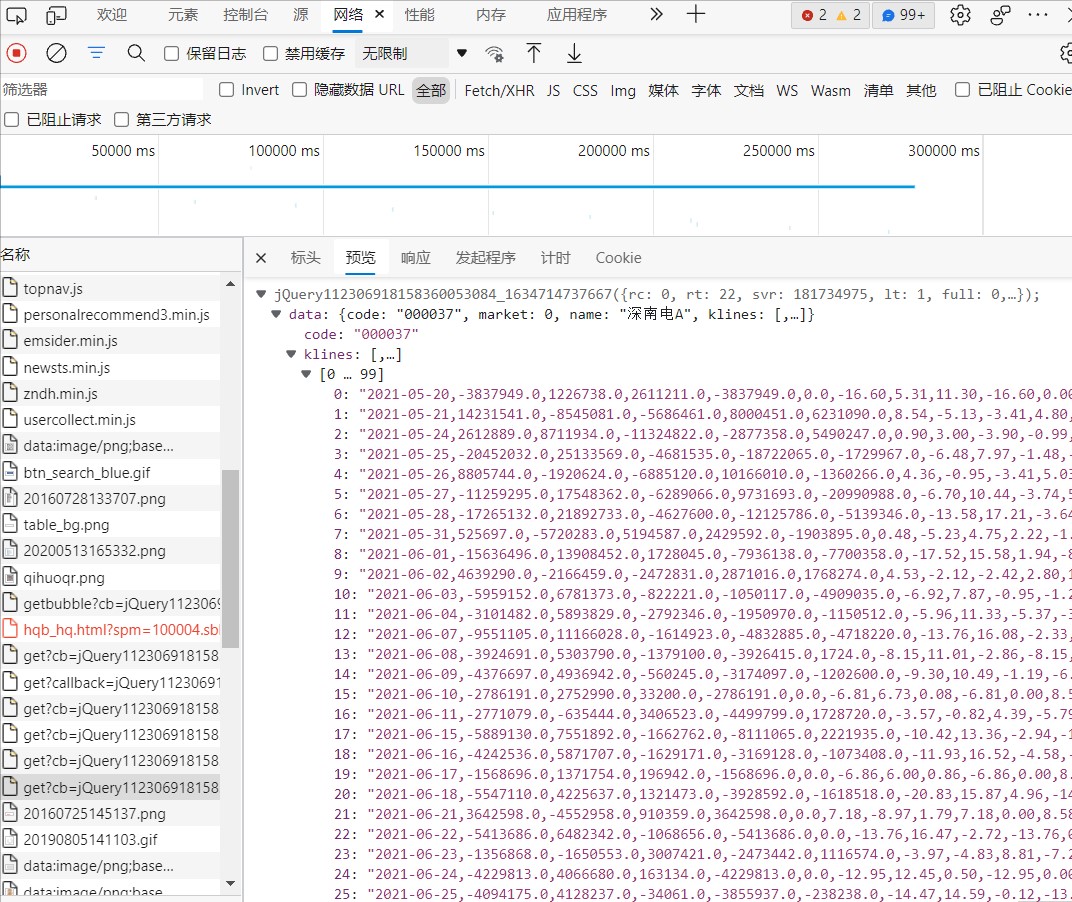
url = 'https://push2his.eastmoney.com/api/qt/stock/fflow/daykline/get?cb=jQuery112301445006905131534_1634624378230&lmt'\
'=0&klt=101&fields1=f1%2Cf2%2Cf3%2Cf7&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf59%2Cf60%2Cf61%2Cf62%'\
'2Cf63%2Cf64%2Cf65&ut=b2884a393a59ad64002292a3e90d46a5&secid=0.000037&_=1634624378231'
headers = {'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50'
}
#Send a url linked request and return the response data
response = requests.get(url=url, headers=headers)
page_text = response.text
#Get data using regular expressions
pat = '"klines":\[(.*?)\]'#(. *?) is the part we want to take out
data = re.compile(pat, re.S).findall(page_text)#The compile function compiles the regular matching expression. re.S represents that line feed matching can be performed. Use the findall function to select the data set, that is, all the source codes crawledURLs and headers can be found in them, construct request headers, send url linked requests, return response data, and obtain data using regular expressions.
Step 3: write to the database
datas = data[0].split('","')#Split string
for i in range(len(datas)):
stock = list(datas[i].replace('"', "").split(","))#Replace "with a space and separate with a separator
#Write data table in sql language
sql1 = """
insert into Eastmoney(
date,
Net inflow of main forces,
Net inflow of small orders,
Net inflow of medium order,
Net inflow of large orders,
Net inflow of super large single,
Proportion of main net inflow,
Proportion of small single net inflow,
Proportion of net inflow in single,
Proportion of large single net inflow,
Proportion of super large single net inflow ,
Closing price ,
Fluctuation range )value('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')
""" % (
stock[0], stock[1], stock[2], stock[3], stock[4], stock[5], stock[6], stock[7], stock[8], stock[9], stock[10],
stock[11], stock[12])#Insert value into placeholder% s
# Execute the statement added by insert. If an exception occurs, handle the exception
try:
cursor.execute(sql1)
db.commit() #Commit the database and write to the database
except:
cursor.rollback() #Data rollback: multiple operations are either executed or not executed
print('Write failed')
# Close cursor connection
cursor.close()
# Close database connection
db.close()
print('Write succeeded!')Divide the crawled data into commas, insert it into the Oriental Wealth data table with sql language, and assign value. Use the execute() method. After executing the sql statement, be sure to submit it with the commit() method. When adding, deleting or changing in the database, you must submit it, otherwise the inserted data will not take effect. rollback() Method: do not want to submit add, delete or modify operations. Use this method to roll back the cancel operations. If there are multiple operations, all of them will be cancelled. Use try to catch exceptions. If there are exceptions when executing sql or submitting to the database, all modifications to the database will be cancelled.
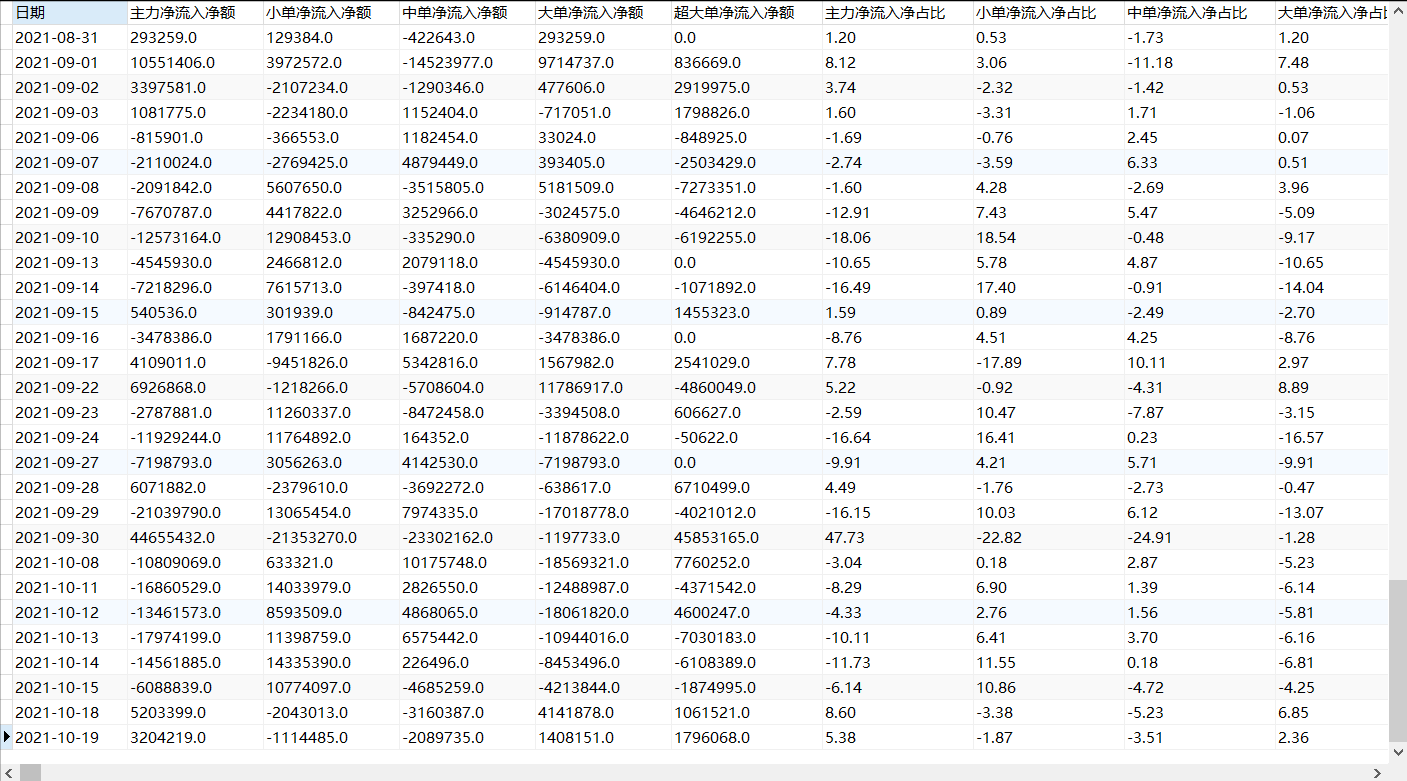
Final effect