Preface
The text and pictures of the article are from the Internet, only for learning and communication, and do not have any commercial use. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
Author: my surname is Liu, but I can't keep your heart
PS: if you need Python learning materials, you can click the link below to get them by yourself
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
The fields obtained in this article are position name, company name, company location, salary, and release time
Create crawler project
scrapy startproject qianchengwuyou
cd qianchengwuyou
scrapy genspider -t crawl qcwy www.xxx.com
Fields to be crawled defined in items
1 import scrapy 2 3 4 class QianchengwuyouItem(scrapy.Item): 5 # define the fields for your item here like: 6 job_title = scrapy.Field() 7 company_name = scrapy.Field() 8 company_address = scrapy.Field() 9 salary = scrapy.Field()
release_time = scrapy.Field()
Write main program in qcwy.py file
1 import scrapy 2 from scrapy.linkextractors import LinkExtractor 3 from scrapy.spiders import CrawlSpider, Rule 4 from qianchengwuyou.items import QianchengwuyouItem 5 6 class QcwySpider(CrawlSpider): 7 name = 'qcwy' 8 # allowed_domains = ['www.xxx.com'] 9 start_urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?'] 10 # https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,7.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare= 11 rules = ( 12 Rule(LinkExtractor(allow=r'https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,(\d+).html?'), callback='parse_item', follow=True), 13 ) 14 15 def parse_item(self, response): 16 17 list_job = response.xpath('//div[@id="resultList"]/div[@class="el"][position()>1]') 18 for job in list_job: 19 item = QianchengwuyouItem() 20 item['job_title'] = job.xpath('./p/span/a/@title').extract_first() 21 item['company_name'] = job.xpath('./span[1]/a/@title').extract_first() 22 item['company_address'] = job.xpath('./span[2]/text()').extract_first() 23 item['salary'] = job.xpath('./span[3]/text()').extract_first() 24 item['release_time'] = job.xpath('./span[4]/text()').extract_first() 25 yield item
Write download rules in pipelines.py file
1 import pymysql 2 3 class QianchengwuyouPipeline(object): 4 conn = None 5 mycursor = None 6 7 def open_spider(self, spider): 8 print('Linked database...') 9 self.conn = pymysql.connect(host='172.16.25.4', user='root', password='root', db='scrapy') 10 self.mycursor = self.conn.cursor() 11 12 def process_item(self, item, spider): 13 print('Writing database...') 14 job_title = item['job_title'] 15 company_name = item['company_name'] 16 company_address = item['company_address'] 17 salary = item['salary'] 18 release_time = item['release_time'] 19 sql = 'insert into qcwy VALUES (null,"%s","%s","%s","%s","%s")' % ( 20 job_title, company_name, company_address, salary, release_time) 21 bool = self.mycursor.execute(sql) 22 self.conn.commit() 23 return item 24 25 def close_spider(self, spider): 26 print('Write to database complete...') 27 self.mycursor.close() 28 self.conn.close()
Open download pipeline and request header in settings.py file
ITEM_PIPELINES = { 'qianchengwuyou.pipelines.QianchengwuyouPipeline': 300, } USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2'
Run the crawler and write the. json file at the same time
scrapy crawl qcwy -o qcwy.json --nolog
Check whether the database is written successfully,
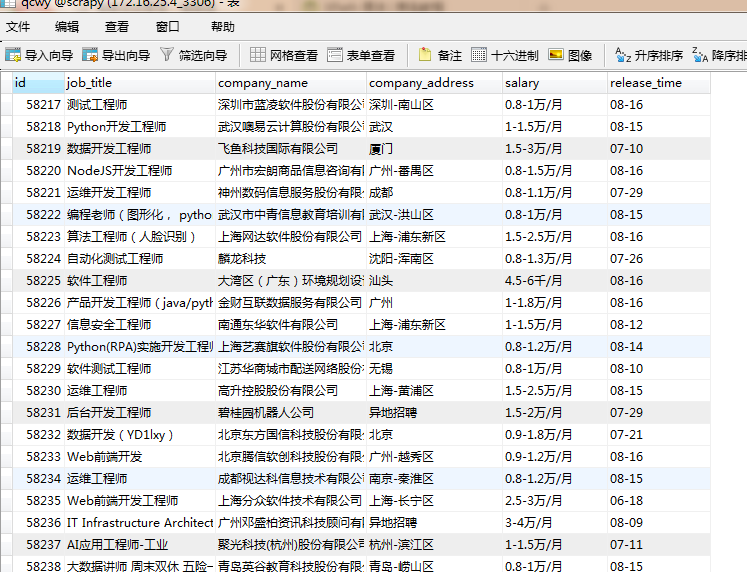
.