These days, my friends say they want to read e-books, but they can only read them on the Internet, but they can't download them to the local area. What can I do? I looked at several novel websites. You can only read them directly on the Internet. To download txt, you have to buy members for money, and you can't copy and paste them directly on the browser. Then I thought that python's crawler could not be crawled and downloaded?
Thoughts:
First, choose the website: http://www.yznnw.com/files/article/html/1/1129/index.html, which is the website of Dragon Blood Warlord, a free novel online:

F12, analysis of web page elements, you can see that under the.zjlist4 li a of this page, all the chapters'URLs are stored. First, we need to get these URLs and put them in an array. Then iterate through the download
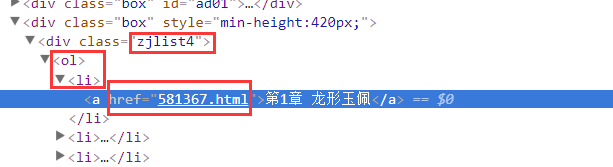
With these websites, we begin to analyze each specific chapter:
Title:

Chapter title:

Contents:

Next chapter:

With this information, we can start to crawl (in fact, we can not crawl the next chapter here, the main idea before me is: download the first chapter of the novel, return to the next chapter of the novel, and then continue to recurse until the last page, after doing so, the download speed is slow, can not be concurrent, and has been recursively occupying a large amount of resources, has been requesting the server will disconnect. That leads to failure.
So I switched to the idea of getting all the page links of chapters first, and then using threads (you can also use processes) to start downloading, and sure enough, the speed has increased a lot. The code is as follows:
#coding:utf-8 import urllib import urllib.request #import threading import multiprocessing from bs4 import BeautifulSoup import re import os def get_pages(url): soup="" try: # Create Request Log Folder if 'Log' not in os.listdir('.'): os.mkdir(r".\Log") # Request the current chapter page params Request parameters request = urllib.request.Request(url) response = urllib.request.urlopen(request) content = response.read() data = content.decode('gbk') # soup Transformation soup = BeautifulSoup(data, "html.parser") except Exception as e: print(url+" Request error\n") with open(r".\Log\req_error.txt",'a',encoding='utf-8') as f: f.write(url+" Request error\n") f.close() return soup # Get links to all chapters of the novel from the front page def get_chartsUrl(indexUrl): soup = get_pages(indexUrl) charts_url = [] charts = soup.select(".zjlist4 li a") for i in charts: charts_url.append(subBase + i.attrs['href']) return charts_url # Passing chapters url Download the content and return to the next page url def get_ChartTxt(url): soup=get_pages(url) # Get title title = soup.select('#htmlhdshuming')[0].text # Get the chapter name subtitle = soup.select('#htmltimu')[0].text # Getting Chapter Text content = soup.select('#htmlContent')[0].text # Replace the chapter content in the specified format and use regular expressions content = re.sub(r'\(.*?\)', '', content) content = re.sub(r'\r\n', '', content) content = re.sub(r'\n+', '\n', content) content = re.sub(r'<.*?>+', '', content) # next page pageDown = soup.select('#htmlxiazhang')[0].attrs['href'] pageDown = base + pageDown # Create folders based on book titles if title not in os.listdir('.'): os.mkdir(r".\%s"%(title)) # Write this chapter try: with open(r'.\%s\%s.txt' % (title, subtitle), 'w', encoding='utf-8') as f: f.write(subtitle + content) f.close() # print(title) # print(content) # print(pageDown) print(subtitle, 'Download successful') except Exception as e: print(subtitle, 'Download failed',pageDown) with open(".\%s\error_url.txt",'a',encoding='utf-8') as f: f.write(subtitle+"Download failed "+url+'\n') return pageDown #Return thread array def thread(charts_url): p=[] # Loading thread for i in charts_url: p.append(multiprocessing.Process(target=get_ChartTxt(i))) # Start thread for i in p: i.start() for i in p: i.join() print("Complete Download") return if __name__=="__main__": # homepage base = 'http://www.yznnw.com' #The unchanging part of the novel subBase=base+'/files/article/html/1/1129/' # home page indexPageUrl=subBase+'index.html' charts_url=get_chartsUrl(indexPageUrl) thread(charts_url)
If you want to download other books, you can change them directly.
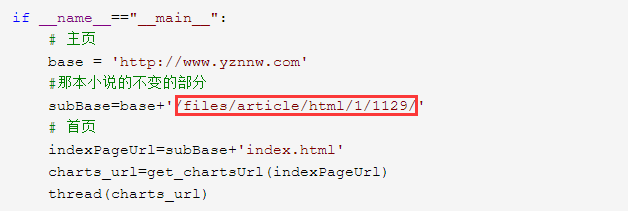
You have to find the part where the URL of the book you want to download is unchanged.
Running results:

After that, you can use the ebook generator and generate it.