Preface
The text and pictures of the article are from the Internet, only for learning and communication, and do not have any commercial use. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
By: Huangwei AI
Source: Python and machine learning
PS: if you need Python learning materials, you can click the link below to get them by yourself
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
Recently, Xiaobian often brushes a video or picture of the question "what do you see that is" think it's a king, and the result is a bronze ". From this question, we can already see the humor element in it. When you click it, you can't stop laughing. So, I think it's better to download these videos and enjoy a good laugh.
Get url
We use the "developer tool" of Google browser to get the url of the web page, then use the requests.get function to get the JSON file, and then use the json.loads function to convert it into a Python object:
1 url = "https://www.zhihu.com/api/v4/questions/312311412/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=20&offset="+str(i*20)+"&platform=desktop&sort_by=default" 2 r = requests.get(url,headers = kv) 3 dicurl = json.loads(r.text)
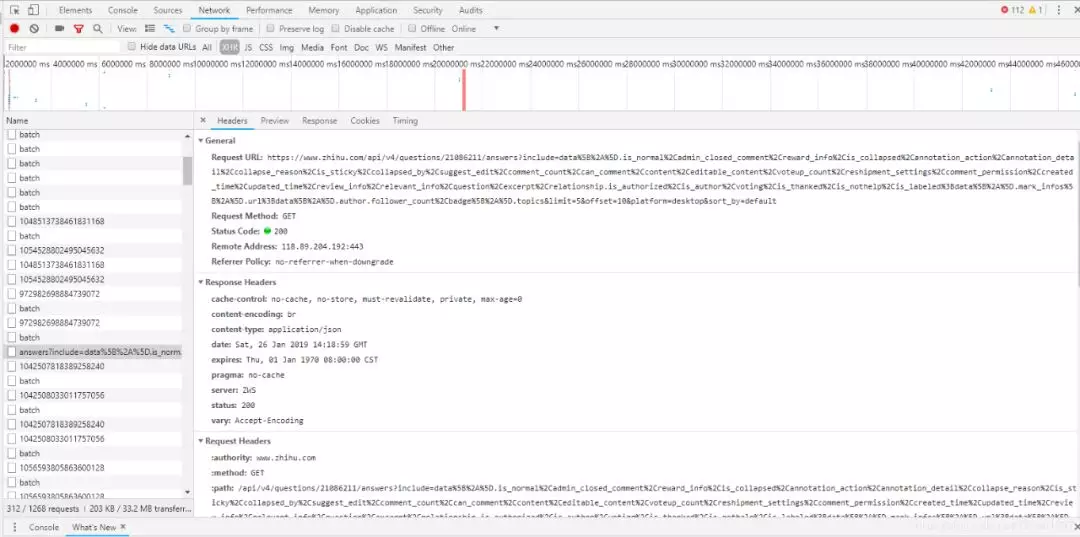
Get content
Using JSONview, a developer tool of Google browser, we can see that there is a content in the opened url, which is the answer we are looking for, and the video url is also in it. After the returned json is converted into a python object, the content in the content is obtained. In other words, we get the content of each answer, including the address of the video.
1 for k in range(20):#Each item dicurl You can parse 20 of them content data 2 name = dicurl["data"][k]["author"]["name"] 3 ID = dicurl["data"][k]["id"] 4 question = dicurl["data"][k]["question"]["title"] 5 content = dicurl["data"][k]["content"] 6 data_lens = re.findall(r'data-lens-id="(.*?)"',content)
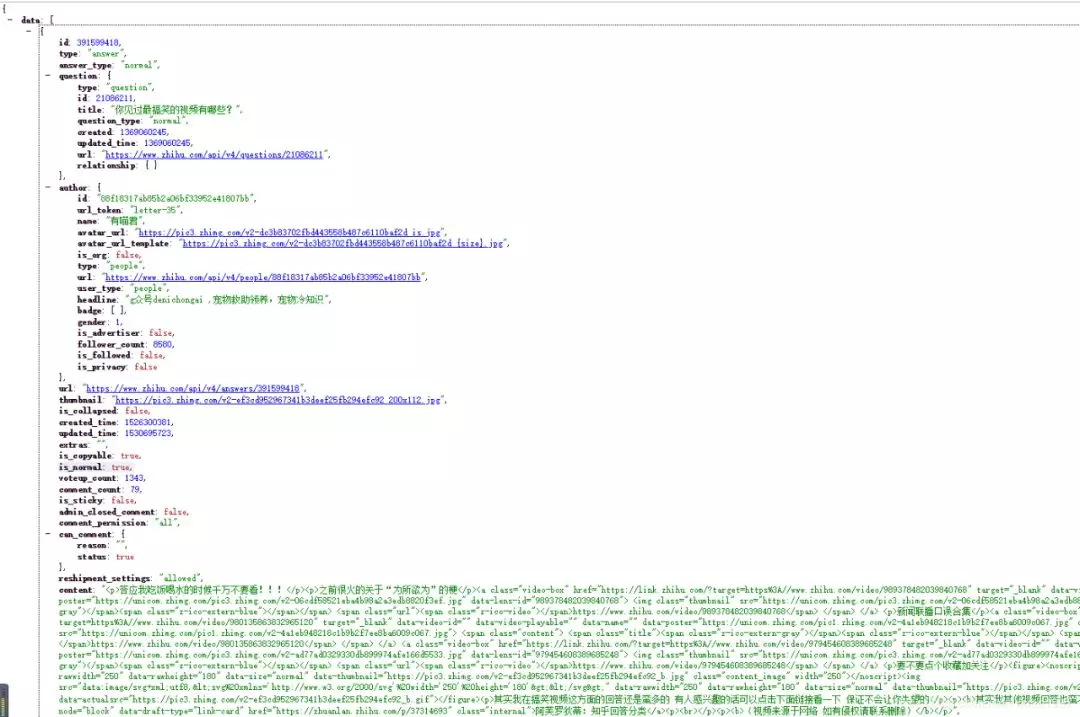
Get video address
Open the obtained content, find the URL after the href, and open it to see if the video is exactly what we want, but find that the URL is not the real address we get. After careful observation, we found that the URL had a jump. To know how to jump here, let's F12 again, open the developer tool, and find that a new URL has been requested. The observation shows that the next string of numbers is actually the previous data lens ID.
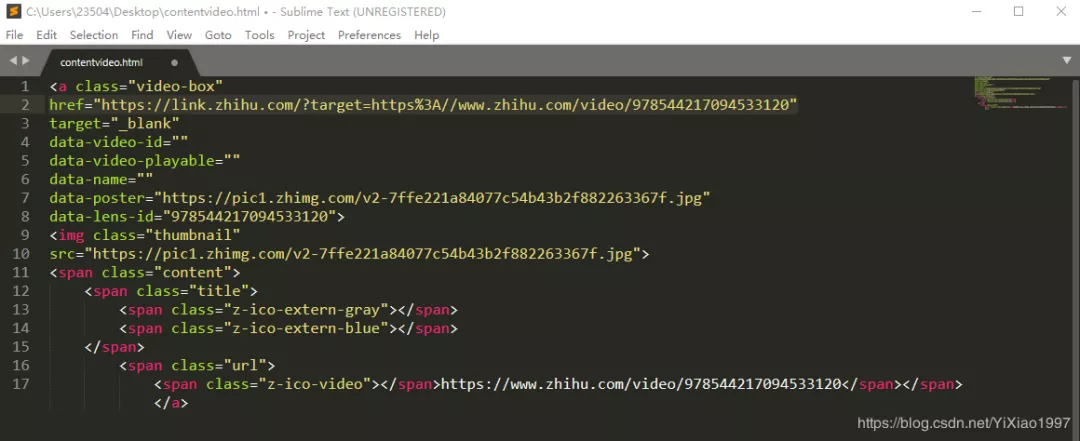
Construct this address:
1 videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j]) 2 R = requests.get(videoUrl,headers = kv) 3 Dicurl = json.loads(R.text) 4 playurl = Dicurl["playlist"]["LD"]["play_url"] 5 #print(playurl)#Video url after jump 6 videoread = request.urlopen(playurl).read()
After that, we can download the video.
Full code:
1 from urllib import request 2 from bs4 import BeautifulSoup 3 import requests 4 import re 5 import json 6 import math 7 def getVideo(): 8 m = 0#Count the number of digital strings 9 num = 0#Number of respondents 10 path = u'/home/zhihuvideo1' 11 #path = u'/home/zhihuimage' 12 kv = {'user-agent':'Mozillar/5.0'} 13 for i in range(math.ceil(900/20)): 14 try: 15 url = "https://www.zhihu.com/api/v4/questions/312311412/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=20&offset="+str(i*20)+"&platform=desktop&sort_by=default" 16 r = requests.get(url,headers = kv) 17 dicurl = json.loads(r.text) 18 for k in range(20):#Each item dicurl You can parse 20 of them content data 19 name = dicurl["data"][k]["author"]["name"] 20 ID = dicurl["data"][k]["id"] 21 question = dicurl["data"][k]["question"]["title"] 22 content = dicurl["data"][k]["content"] 23 data_lens = re.findall(r'data-lens-id="(.*?)"',content) 24 print("Processing section" + str(num+1) + "One answer--Respondent nickname:" + name + "--Respondent ID:" + str(ID) + "--" + "problem:" + question) 25 num = num + 1 # One at a time content Add 1 to represent the number of respondents 26 for j in range(len(data_lens)): 27 try: 28 videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j]) 29 R = requests.get(videoUrl,headers = kv) 30 Dicurl = json.loads(R.text) 31 playurl = Dicurl["playlist"]["LD"]["play_url"] 32 #print(playurl)#Video url after jump 33 videoread = request.urlopen(playurl).read() 34 35 fileName = path +"/" + str(m+1) + '.mp4' 36 print ('===============================================') 37 print(">>>>>>>>>>>>>>>>>The first---" + str(m+1) + "---Video download completed<<<<<<<<<<<<<<<<<") 38 videoname = open(fileName,'wb') 39 40 videoname.write(videoread) 41 m = m+1 42 except: 43 print("this URL External video,Not in accordance with crawling rules") 44 except: 45 print("Tectonics"+str(i+1)+"strip json Data failure") 46 47 if __name__ == "__main__": 48 getVideo()
To run this program, you need to create a folder according to the path where the video is stored:
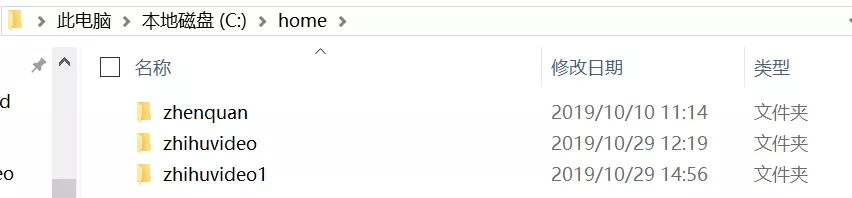
Result
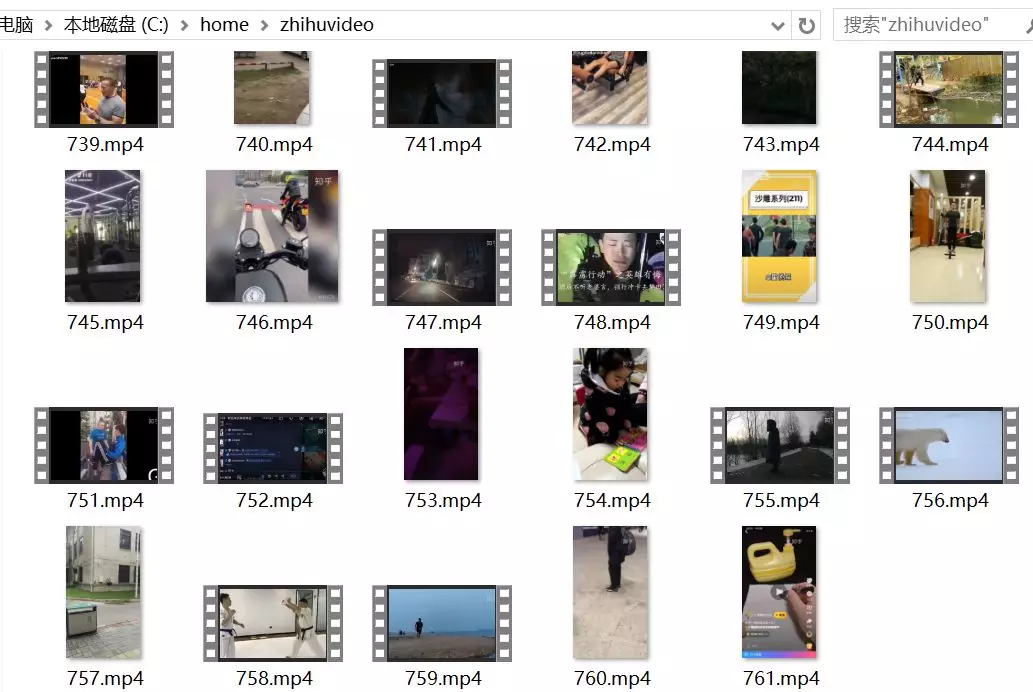
After a period of time, we finally got more than 700 Videos:
.