python data analysis tool
The data analysis function of python itself is not strong, so we need to install some third-party extension libraries to enhance its corresponding functions.
Extension library related to python data analysis and mining;
| expanded memory bank | brief introduction |
|---|---|
| NumPy | Provide array support and corresponding efficient processing functions |
| SciPy | Provide matrix support and matrix related numerical calculation modules |
| Matplotlib | Powerful data visualization tools and drawing library |
| pandas | Powerful and flexible data analysis and exploration tools |
| StatsModels | Statistical modeling and econometrics, including descriptive statistics, statistical model estimation and inference |
| scikit-learn | Support powerful machine learning libraries such as regression, classification and clustering |
| Keras | Deep learning library is used to establish neural network and deep learning model |
| Gensim | It is used as a text topic model library, which may be used in text mining |
Of course, there are other libraries. For example, the pilot library can be used for image processing, OpenCV can be used for video processing, GMPY2 can be used for high-precision computing, etc. Of course, when dealing with problems, we can search relevant information on the Internet.
If Anaconda distribution is used, many libraries already come with them, such as NumPy, SciPy, Matplotlib, pandas and scikit learn.
Of course, if you use other compilers, you need to install the relevant library files yourself.
NumPy
- python does not provide the array function. Although the list can complete the basic array function, when the amount of data is large, the speed of using the list will be very slow;
- NumPy provides real array functions and functions for fast data processing;
- NumPy is a dependent Library of many advanced libraries;
Using NumPy to manipulate arrays
import numpy as np a = np.array([2, 0, 1, 5]) #Create array print(a) print(a[:3]) print(a.min()) a.sort() print(a) b = np.array(([[1,2,3], [4,5,6]])) print(b*b)
Output result: [2 0 1 5] [2 0 1] 0 [0 1 2 5] [[ 1 4 9] [16 25 36]]
Reference links:
Scipy
The functions of SciPy include optimization, linear algebra, integration, interpolation, fitting, special functions, fast Fourier transform, signal processing and image processing, ordinary differential equation solving and other calculations commonly used in science and engineering.
from scipy.optimize import fsolve #Import functions for solving equations
def f(x):
x1 = x[0]
x2 = x[1]
return [2*x1 - x2**2 - 1, x1**2 - x2 - 2]
result = fsolve(f, [1, 1])
print(result)
from scipy import integrate #Import integral function
def g(x): #Integral function definition
return (1 - x**2)**0.5
pi_2, err = integrate.quad(g, -1, 1) # Integration results and errors
print(pi_2 * 2)
print(err)
Output result: [1.91963957 1.68501606] 3.1415926535897967 1.0002354500215915e-09
Reference link:
Matplotlib
Matplotlib is the most famous drawing library, which is mainly used for two-dimensional drawing. Of course, it can also be used for simple three-dimensional drawing.
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 1000) #Independent variable of drawing
y = np.sin(x) + 1 #Dependent variable y
z = np.cos(x**2) + 1 #Dependent variable z
plt.figure(figsize=(8,4)) #Set image size
plt.plot(x, y, label = '$\sin x+1$', color = 'red', linewidth = 2) #Drawing, setting label, line color and line size
plt.plot(x, z, 'b--', label = '$\cos x^2+1$') #Drawing, setting label and line type
plt.xlabel('Time(s) ') #x-axis name
plt.ylabel('Volt') #y-axis name
plt.title('A Simple Example')
plt.ylim(0,2.2)# y-axis range
plt.legend()#Show Legend
plt.show()
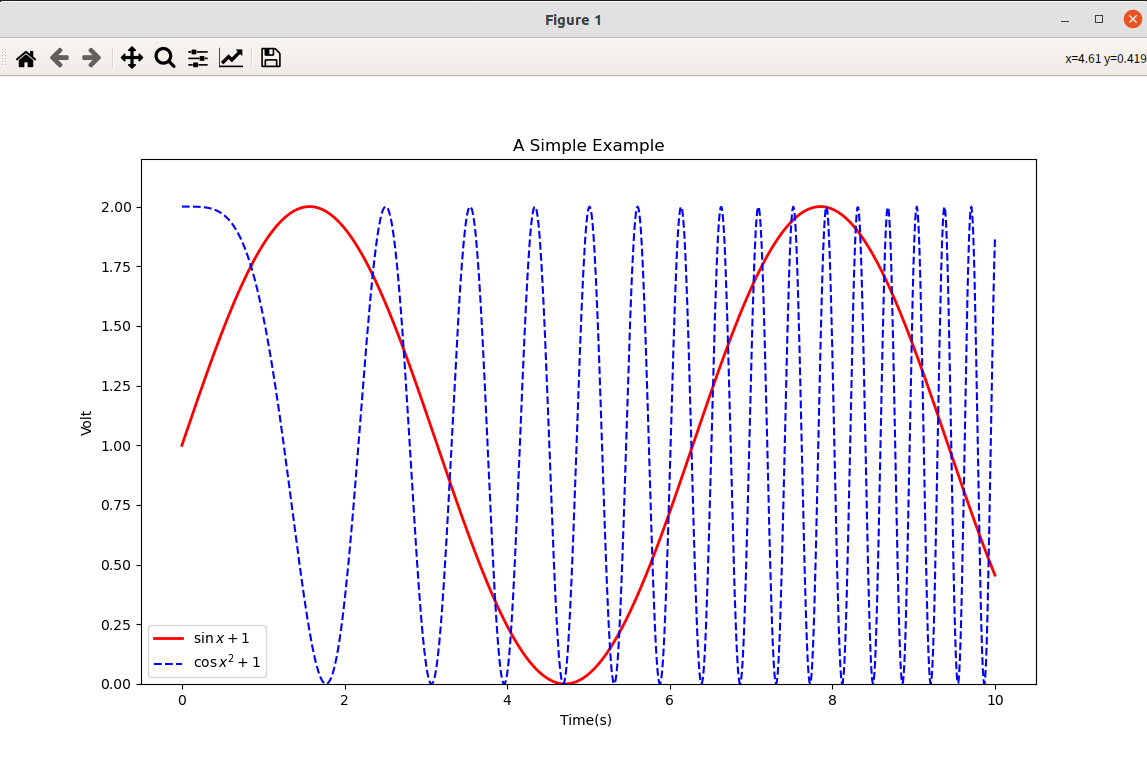
Chinese font needs to be manually specified. The default font is Chinese font.
reference material:
pandas
pandas is the most powerful data analysis and exploration tool in python. pandas is very powerful;
- Support data addition, deletion, query and modification similar to SQL, and have rich data processing functions;
- Support time series analysis function; Support flexible data processing;
The basic data structures of pandas are Series and DataFrame.
import numpy as np
import pandas as pd
s = pd.Series([1, 2, 3], index=list('abc'))
d = pd.DataFrame([[1,2,3],[4,5,6]], columns=['a','b','c'])
d2 = pd.DataFrame(s)
print(d.head())
print(d.describe())
Output result:
a b c
0 1 2 3
1 4 5 6
a b c
count 2.00000 2.00000 2.00000
mean 2.50000 3.50000 4.50000
std 2.12132 2.12132 2.12132
min 1.00000 2.00000 3.00000
25% 1.75000 2.75000 3.75000
50% 2.50000 3.50000 4.50000
75% 3.25000 4.25000 5.25000
max 4.00000 5.00000 6.00000
#When reading the file, note that the storage path of the file cannot contain Chinese, otherwise the reading may be wrong;
pd.read_excel('data.xls') #Read Excel file and create DataFrame;
pd.read_csv('data.csv', encoding='utf-8') #When reading data in text format, encoding is generally used to specify the encoding;
Reference documents;
StatsModels
Pandas focuses on data reading, processing and exploration, while StatsModels pays more attention to data statistical modeling and analysis, which makes Python have the flavor of R language. StatsModels supports data interaction with pandas, so it combines with pandas to become a powerful data mining combination under python.
from statsmodels.tsa.stattools import adfuller as ADF #Import ADF inspection import pandas as pd import numpy as np print(ADF(np.random.rand(100))) #The returned results include ADF value, p value, etc
Output:
(-8.103123291388002, 1.2838791095546032e-12, 1, 98, {'1%': -3.4989097606014496, '5%': -2.891516256916761, '10%': -2.5827604414827157}, 30.91636795599902)
Reference link:
scikit-learn
This is a library related to machine learning. Scikit learn is a powerful machine learning toolkit under python. It provides a perfect machine learning toolkit, including data preprocessing, classification, regression, clustering, prediction, model analysis and so on.
Scikit learn relies on NumPy, SciPy and Matplotlib.
from sklearn.linear_model import LinearRegression #Import linear regression model model = LinearRegression() #Establish linear regression model print(model)
1) The interfaces provided by all models are: model for training model Fit() is fit(X,y) for supervised models and fit(X) for unsupervised models
2) The supervision model provides the following interfaces:
- model.predict(X_new): predict new samples;
- model.predict_proba(X_new): prediction probability, which is only useful for some models (such as LR);
- model.score(): the higher the score, the better the fit;
3) The unsupervised model provides the following interfaces:
- model.transform(): learn new base space from data;
- model.fit_transform(): learn a new base from the data and convert the data according to this set of bases;
Scikit learn itself provides some example data for us to learn. The more common ones are Anderson iris flower data set, handwritten graphic data set and so on.
from sklearn import datasets # Import dataset iris = datasets.load_iris() # Load dataset print(iris.data.shape) from sklearn import svm #Import SVM model clf = svm.LinearSVC() #Establish SVM classifier clf.fit(iris.data, iris.target) #Training model with data clf.predict([[5.0, 3.6, 1.3, 0.25]]) #After inputting the trained model, input new data for prediction print(clf.coef_) #View the parameters of the trained model
Output result: (150, 4) [[ 0.18423149 0.45122757 -0.8079383 -0.45071932] [ 0.05554602 -0.9001544 0.40811885 -0.96012405] [-0.85077276 -0.98663003 1.3810384 1.86530666]]
Reference link:
Keras
Artificial intelligence neural network is a powerful but simple model. It plays an important role in the fields of language processing, image recognition and so on. Keras library can be used to build neural networks. In fact, keras is not a simple neural network library, but a powerful deep learning library based on Theano. It can be used to build not only ordinary neural networks, but also various deep learning models, such as self encoder, cyclic neural networks, recursive neural networks, convolutional neural networks, etc.
To use Keras, you need to install TensorFlow package.
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGD
model = Sequential()#Model initialization
model.add(Dense(20,64))#Add the connection of the input layer (20 nodes) and the first hidden layer (64 nodes)
model.add(Activation('tanh'))#The first hidden layer uses tanh as the activation function
model.add(Dropout(0.5))#Use Dropout to prevent overfitting
model.add(Dense(64, 64))#Add the connection of the first hidden layer (64 nodes) and the second hidden layer (64 nodes)
model.add(Activation('tanh'))
model.add(Dropout(0.5))
model.add(Dense(64,1))#Add the connection of the second hidden layer (64 nodes) and the output layer (1 node)
model.add(Activation('sigmoid'))#The output layer uses sigmoid as the activation function
sgd = SGD(lr=0.1, decay=1e-6,momentum=0.9,nesterov=True)#Define solution algorithm
model.compile(loss='mean_squraed_error', optimizer=sgd)#Compile and generate the model, and the loss function is the sum of squares of the average error
model.fit(X_train, y_train, nb_epoch=20,batch_size=16)#Training model
score = model.evaluate(X_test, y_test, batch_size=16)#test model
reference material;
Gensim
Gensim is used to deal with language tasks, such as text similarity calculation, LDA, Word2Vec, etc. tasks in these fields often need more background knowledge.
import gensim, logging logging.basicConfig(format='%(asctime)s: %(levelname)s : %(message)s', level=logging.INFO) #logging is used to output training logs #Divide the sentences into words, and input each sentence in the form of word list sentences=[['first', 'sentence'],['secend','sentence']] #The above sentence is trained with vector model model = gensim.models.Word2Vec(sentences, min_count=1) print(model['sentence'])#Output the word vector of the word sentence
reference material: