A data structure and GIL
1 queue
Standard library queue module, provides queue, LIFO queue, priority queue for FIFO
The Queue class is thread-safe, suitable for secure exchange of data between multiple threads, using Lock and Condition internally
The reason why the size of the container is inaccurate is that it is impossible to get the exact size without locking it, because you have just read a size and have not yet been removed, it may have been modified by other threads. Although the size of the queue class has been locked, it is still not guaranteed that get immediately will succeed because putRead size and get,put method is separate.
2 GIL
1 Introduction
Global Interpreter Lock, Process Level Lock GIL
Cpython has a lock in the interpreter process called the GIL global interpreter lock.
GIL guarantees that only one thread executes code at a time in a Cpython process, even in multi-core situations.
2 IO and CPU intensive
In Cpython
IO intensive, because threads are blocked, other threads are scheduled
CPU-intensive. Current threads may continuously acquire GIL s, making it virtually impossible for other threads to use the CPU. To wake up other threads, data needs to be prepared at a high cost.
IO-intensive, multi-threaded solution, CPU-intensive, multi-process solution, bypass GIL.
The vast majority of read and write operations for built-in data structures in python are atomic
Because of GIL s, python's built-in data types become secure when programming with multiple threads, but in fact they are not thread-safe themselves
3 Reason for retaining GIL
Guido adheres to the simple philosophy of using python without requiring advanced system knowledge for beginners.
Remove the GIL instead.This reduces the efficiency of Cpython single-threaded execution.
4 Verify that it is single-threaded
Related Instances
import logging
import datetime
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s ")
start=datetime.datetime.now()
def calc():
sum=0
for _ in range(1000000000):
sum+=1
calc()
calc()
calc()
calc()
calc()
delta=(datetime.datetime.now()-start).total_seconds()
logging.info(delta)
Calculation results in multithreaded mode
import logging
import datetime
import threading
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s ")
start=datetime.datetime.now()
def calc():
sum=0
for _ in range(1000000000):
sum+=1
lst=[]
for _ in range(5):
t=threading.Thread(target=calc)
t.start()
lst.append(t)
for t in lst:
t.join()
delta=(datetime.datetime.now()-start).total_seconds()
print (delta)give the result as follows

From these two programs, multithreading in Cpython has no advantage at all and takes as long as a thread because of the GIL
Two-process
1 Concept
1 Multiprocess description
Because of GIL s in python, multithreading is not the best choice for CPU-intensive programs
Multiprocess can run programs in a completely separate process, making full use of multiprocessors
However, isolation of the process itself causes data not to be shared, and threads are much lighter than processes.
Multiprocessing is also a means of resolving concurrency
2 Process and Thread Differences
Same:
Processes can be terminated, threads cannot be terminated by command. Thread termination either throws an exception or the program itself executes.
Inter-process synchronization provides the same classes as thread synchronization and works in the same way, but it is more expensive than thread synchronization and the underlying implementation is different.
Multprocessing also provides shared memory, server processes to share data, queue queues, and matching pipelines for interprocess communication
Difference
Different modes of communication
1 Multiprocess means enabling multiple interpreter processes. Interprocess communication must be serialized and deserialized
2 Security issues with data
Multi-process is best performed in main
Multithreaded has already processed the data and does not need to be serialized again
Multiprocess delivery must be serialized and deserialized.
3 Process Application
Remote Call, RPC, Cross Network
2 Parameter introduction
process class in multiprocessing
The process class follows the API of the Thread class, reducing learning difficulty
Different processes can be fully scheduled to execute on different CPU s
Multi-threading is best for IO intensive
Multi-process is best for CPU intensive
Related properties provided by the process
| Name | Meaning |
|---|---|
| pid | Process ID |
| exitcode | Status code for process exit |
| terminate() | Terminate the specified process |
3 Instances
import logging
import datetime
import multiprocessing
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s ")
start=datetime.datetime.now()
def calc(i):
sum=0
for _ in range(1000000000):
sum+=1
lst=[]
for i in range(5):
p=multiprocessing.Process(target=calc,args=(i,),name="P-{}".format(i))
p.start()
lst.append(p)
for p in lst:
p.join()
delta=(datetime.datetime.now()-start).total_seconds()
print (delta)give the result as follows

Multiprocess itself avoids the time required for scheduling between processes. Multicore is used. There is CPU scheduling problem here
Multiprocess CPU promotion is obvious.
Single-threaded, multi-threaded running for a long time, and multi-process only takes half and a half, is true parallelism
4 process pool correlation
import logging
import datetime
import multiprocessing
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s ")
start=datetime.datetime.now()
def calc(i):
sum=0
for _ in range(1000000000):
sum+=1
print (i,sum)
if __name__=='__main__':
start=datetime.datetime.now()
p=multiprocessing.Pool(5) # This is used to initialize the process pool, where resources are reusable
for i in range(5):
p.apply_async(calc,args=(i,))
p.close() # To perform a join below, you must close above
p.join()
delta=(datetime.datetime.now()-start).total_seconds()
print (delta)give the result as follows

Many processes are created, using process pools is a better way to handle them
5 Multi-process and multi-threaded selection
1 Choice
1 CPU intensive
Cpython uses GIL s, competes with each other when multithreaded, and the multicore advantage is not available. Ppython uses multiprocesses more efficiently
2 IO intensive
Suitable for multi-threading, reduces IO serialization overhead, and when IO waits, switches to other threads to continue execution, which is efficient, although multi-process is also suitable for IO-intensive
2 Applications
Request/Response Models: Common Processing Models in WEB Applications
master starts multiple worker worker processes, typically with the same number of CPU s
A worker starts multiple threads in a worker process to improve concurrent processing. A worker processes user requests and often needs to wait for data
This is how nginx works
Work processes generally have the same number of CPU cores, CPU affinity, and process migration costs in the CPU are higher.
Three concurrent packages
1 Concept
concurrent.futures
Modules introduced in version 3.2
Asynchronous Parallel Task Programming Module, provides an advanced asynchronous executable convenient interface
Two pool executors are provided
Executor of ThreadPoolExecutor asynchronous call thread pool
ProcessPoolExecutor asynchronously calls Executor of the process pool
2 Parameter Details
| Method | Meaning |
|---|---|
| ThreadPoolExecutor(max_workers=1) | Create a pool of up to max_workers threads in the pool to execute asynchronously at the same time, returning an Executor instance |
| submit(fn,*args,**kwagrs) | Submit the executed functions and parameters and return a Future instance |
| shutdown(wait=True) | Clean Pool |
Future class
| Method | Meaning |
|---|---|
| result() | You can view the return of the call |
| done() | Return to True if the call was successfully cancelled or the execution completed |
| cancelled() | Return True if the call is successfully cancelled |
| running() | Return True if running and cannot be cancelled |
| cancel() | Attempts to cancel the call, returns False if it has been executed and cannot be canceled, or returns True otherwise |
| result(timeout=None) | Get the returned result, timeout is None, wait for return, timeout set to expire, throw concurrent.futures.TimeoutError exception |
| execption(timeout=None) | Get the returned exception, timeout is None, wait for return, timeout set to expire, throw concurrent.futures.TimeoutError exception |
3 Thread Pool Related Instances
import logging
import threading
from concurrent import futures
import logging
import time
logging.basicConfig(level=logging.INFO,format="%(asctime)-15s\t [%(processName)s:%(threadName)s,%(process)d:%(thread)8d] %(message)s")
def worker(n): # Define tasks to be performed in the future
logging.info("begin to work{}".format(n))
time.sleep(5)
logging.info("finished{}".format(n))
# Create a thread pool with a capacity of 3
executor=futures.ThreadPoolExecutor(max_workers=3)
fs=[]
for i in range(3):
f=executor.submit(worker,i) # Pass in parameter, return Future object
fs.append(f)
for i in range(3,6):
f=executor.submit(worker,i) # Pass in parameter, return Future object
fs.append(f)
while True:
time.sleep(2)
logging.info(threading.enumerate()) #Return to the list of surviving threads
flag=True
for f in fs:
logging.info(f.done()) # Return to True here if called or cancelled successfully
flag=flag and f.done() # Returns True if all calls succeed or False if none
if flag:
executor.shutdown() # If all calls succeed, the pool needs to be cleaned up
logging.info(threading.enumerate())
break
give the result as follows
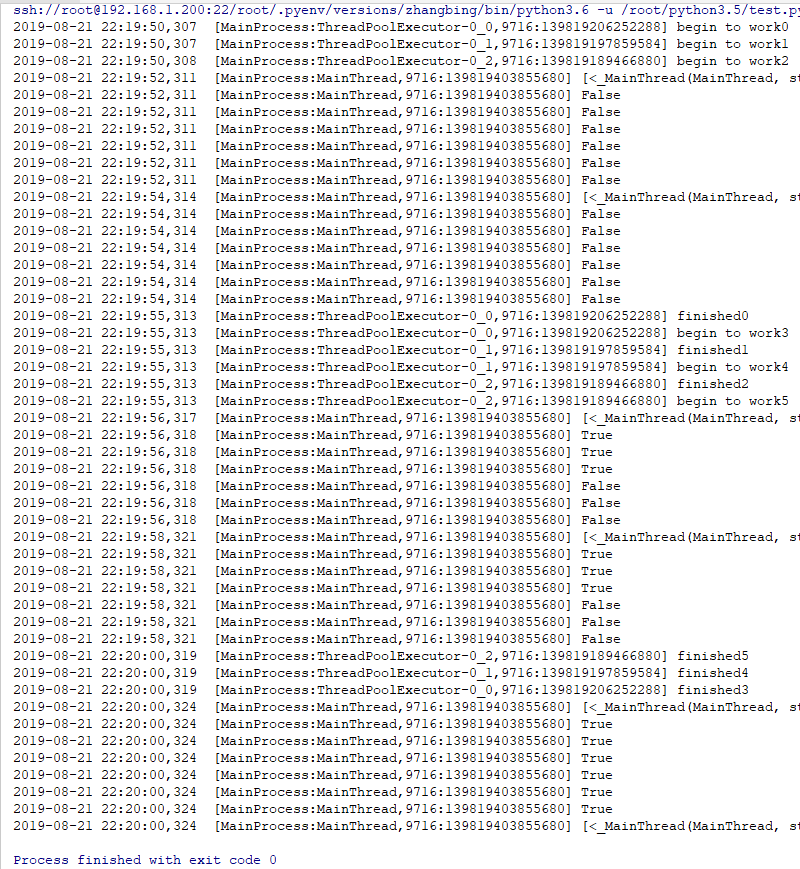
The threads in its thread pool are used continuously. Once a thread is created, it does not change. The only bad thing is that the thread name does not change, but it most affects the printing result.
4 Process pool related instances
import logging
import threading
from concurrent import futures
import logging
import time
logging.basicConfig(level=logging.INFO,format="%(asctime)-15s\t [%(processName)s:%(threadName)s,%(process)d:%(thread)8d] %(message)s")
def worker(n): # Define tasks to be performed in the future
logging.info("begin to work{}".format(n))
time.sleep(5)
logging.info("finished{}".format(n))
# Create a process pool with a capacity of 3
executor=futures.ProcessPoolExecutor(max_workers=3)
fs=[]
for i in range(3):
f=executor.submit(worker,i) # Pass in parameter, return Future object
fs.append(f)
for i in range(3,6):
f=executor.submit(worker,i) # Pass in parameter, return Future object
fs.append(f)
while True:
time.sleep(2)
flag=True
for f in fs:
logging.info(f.done()) # Return to True here if called or cancelled successfully
flag=flag and f.done() # Returns True if all calls succeed or False if none
if flag:
executor.shutdown() # If all calls succeed, the pool needs to be cleaned up
breakgive the result as follows
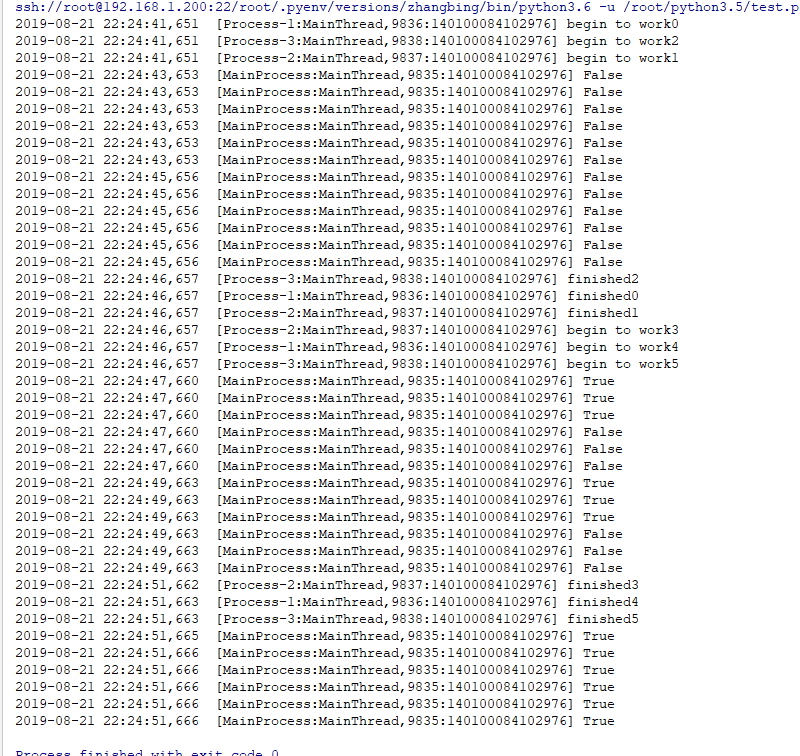
5 Support context management
concurrent.futures.ProcessPoolExecutor inherits from concurrent.futures.base.Executor, while the parent class has the enter,_exit method, which supports context management and can use the with statement
import logging
import threading
from concurrent import futures
import logging
import time
logging.basicConfig(level=logging.INFO,format="%(asctime)-15s\t [%(processName)s:%(threadName)s,%(process)d:%(thread)8d] %(message)s")
def worker(n): # Define tasks to be performed in the future
logging.info("begin to work{}".format(n))
time.sleep(5)
logging.info("finished{}".format(n))
fs=[]
with futures.ProcessPoolExecutor(max_workers=3) as executor:
for i in range(6):
futures=executor.submit(worker,i)
fs.append(futures)
while True:
time.sleep(2)
flag=True
for f in fs:
logging.info(f.done()) # Return to True here if called or cancelled successfully
flag=flag and f.done() # Returns True if all calls succeed or False if none
if flag:
executor.shutdown() # If all calls succeed, the pool needs to be cleaned up
breakgive the result as follows
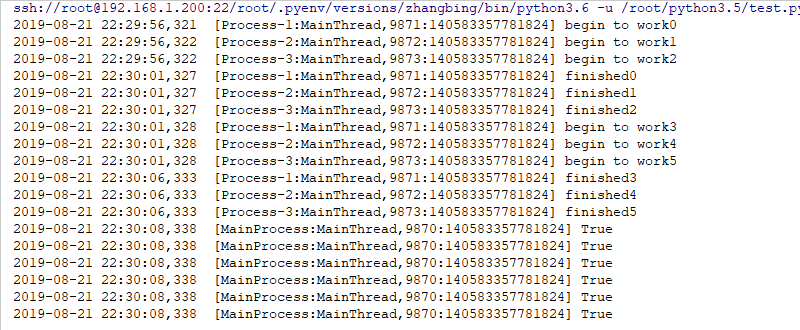
6 Summary
Unified thread pool, process pool invocation, simplified programming, is a reflection of python's simple philosophy of thought
Unique disadvantage: Unable to set thread name