Python Data Type and Its Method
When we learn programming languages, we will encounter data types, which are very basic and inconspicuous, but it is very important. This paper introduces python's data types, and gives a detailed description of the methods of each data type, which can be used for knowledge review.
I. Integration and Long Integration
python2 in number = 123 print (type(number)) number2 = 2147483647 print (type(number2)) number2 = 2147483648 #We will see more than 2147483647 in this range. py2 Medium shaping will become long shaping. print (type(number2)) #Operation results <type 'int'> <type 'int'> <type 'long'> #python3 in number = 123 print (type(number)) number2 = 2147483648 print (type(number2)) #stay python3 China will not #Operation results <class 'int'> <class 'int'>
The commonly used method s are as follows:
.bit_length()
Take the shortest bit number
def bit_length(self): # real signature unknown; restored from __doc__ """ int.bit_length() -> int Number of bits necessary to represent self in binary. >>> bin(37) '0b100101' >>> (37).bit_length() 6 """ return 0
For instance:
number = 12 #1100 print(number.bit_length()) #Operation results 4
Floating point type
Floating point type can be seen as decimal achievement and float type.
#float number = 1.1 print(type(number)) #Operation results <class 'float'>
The commonly used method s are as follows:
.as_integer_ratio()
Returns tuples (X,Y), number = k, number. as_integer_ratio() ==> (X,Y) x/y=k
def as_integer_ratio(self): # real signature unknown; restored from __doc__ """ float.as_integer_ratio() -> (int, int) Return a pair of integers, whose ratio is exactly equal to the original float and with a positive denominator. Raise OverflowError on infinities and a ValueError on NaNs. >>> (10.0).as_integer_ratio() (10, 1) >>> (0.0).as_integer_ratio() (0, 1) >>> (-.25).as_integer_ratio() (-1, 4) """ pass
For example
number = 0.25 print(number.as_integer_ratio()) #Operation results (1, 4)
.hex()
Floating-point numbers in hexadecimal notation
def hex(self): # real signature unknown; restored from __doc__ """ float.hex() -> string Return a hexadecimal representation of a floating-point number. >>> (-0.1).hex() '-0x1.999999999999ap-4' >>> 3.14159.hex() '0x1.921f9f01b866ep+1' """ return ""
For example
number = 3.1415 print(number.hex()) #Operation results 0x1.921cac083126fp+1
.fromhex()
Enter hexadecimal decimal into string and return decimal decimal decimal
def fromhex(string): # real signature unknown; restored from __doc__ """ float.fromhex(string) -> float Create a floating-point number from a hexadecimal string. >>> float.fromhex('0x1.ffffp10') 2047.984375 >>> float.fromhex('-0x1p-1074') -5e-324 """
For instance
print(float.fromhex('0x1.921cac083126fp+1')) #Operation results 3.1415
.is_integer()
Determine whether a decimal is an integer, such as 3.0 is an integer, and 3.1 is not. Returns a Boolean value?
def is_integer(self, *args, **kwargs): # real signature unknown """ Return True if the float is an integer. """ pass
For instance
number = 3.1415 number2 = 3.0 print(number.is_integer()) print(number2.is_integer()) #Operation results False True
III. Character Types
Strings are characters of columns, enclosed in single or double quotes in Python, and three quotes in multiple lines.
name = 'my name is Frank' name1 = "my name is Frank" name2 = '''my name is Frank I'm 23 years old, ''' print(name) print(name1) print(name2) #Operation results my name is Frank my name is Frank my name is Frank I'm 23 years old
The commonly used method s are as follows:
.capitalize()
Uppercase of the first character of a string
def capitalize(self): # real signature unknown; restored from __doc__ """ S.capitalize() -> str Return a capitalized version of S, i.e. make the first character have upper case and the rest lower case. """ return ""
For instance
name = 'my name is Frank' #Operation results My name is frank
.center()
Character centered, specified width and padding character (default space)
def center(self, width, fillchar=None): # real signature unknown; restored from __doc__ """ S.center(width[, fillchar]) -> str Return S centered in a string of length width. Padding is done using the specified fill character (default is a space) """ return ""
For instance
flag = "Welcome Frank" print(flag.center(50,'*')) #Operation results ******************Welcome Frank*******************
.count()
Calculate the number of characters in a string to specify the index range
def count(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.count(sub[, start[, end]]) -> int Return the number of non-overlapping occurrences of substring sub in string S[start:end]. Optional arguments start and end are interpreted as in slice notation. """ return 0
For instance
flag = 'aaababbcccaddadaddd' print(flag.count('a')) print(flag.count('a',0,3)) #Operation results 7 3
.encode()
Encoding. In Python 3, str defaults to unicode data type, which can be encoded into bytes data
def encode(self, encoding='utf-8', errors='strict'): # real signature unknown; restored from __doc__ """ S.encode(encoding='utf-8', errors='strict') -> bytes Encode S using the codec registered for encoding. Default encoding is 'utf-8'. errors may be given to set a different error handling scheme. Default is 'strict' meaning that encoding errors raise a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and 'xmlcharrefreplace' as well as any other name registered with codecs.register_error that can handle UnicodeEncodeErrors. """ return b""
For instance
flag = 'aaababbcccaddadaddd' print(flag.encode('utf8')) #Operation results b'aaababbcccaddadaddd'
.endswith()
To determine whether the end of a string is a string or a character, you can specify the range by index?
def endswith(self, suffix, start=None, end=None): # real signature unknown; restored from __doc__ """ S.endswith(suffix[, start[, end]]) -> bool Return True if S ends with the specified suffix, False otherwise. With optional start, test S beginning at that position. With optional end, stop comparing S at that position. suffix can also be a tuple of strings to try. """ return False
For instance
flag = 'aaababbcccaddadaddd' print(flag.endswith('aa')) print(flag.endswith('ddd')) print(flag.endswith('dddd')) print(flag.endswith('aaa',0,3)) print(flag.endswith('aaa',0,2)) #Operation results False True False True False
.expandtabs()
Convert tab("\t") to space
def expandtabs(self, tabsize=8): # real signature unknown; restored from __doc__ """ S.expandtabs(tabsize=8) -> str Return a copy of S where all tab characters are expanded using spaces. If tabsize is not given, a tab size of 8 characters is assumed. """ return ""
For instance
flag = "\thello python!" print(flag) print(flag.expandtabs()) #default tabsize=8 print(flag.expandtabs(20)) #Operation results hello python! #One tab,Four spaces in length hello python! #8 A space hello python! #20 A space
.find()
Find characters, return index values, you can search within the specified index range, find no return - 1
def find(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.find(sub[, start[, end]]) -> int Return the lowest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """ return 0
For instance
flag = "hello python!" print(flag.find('e')) print(flag.find('a')) print(flag.find('h',4,-1)) #Operation results 1 -1 9
.format()
Format the output, using the "{}" symbol as the operator.
def format(self, *args, **kwargs): # known special case of str.format """ S.format(*args, **kwargs) -> str Return a formatted version of S, using substitutions from args and kwargs. The substitutions are identified by braces ('{' and '}'). """ pass
For instance
#Location parameters flag = "hello {0} and {1}!" print(flag.format('python','php')) flag = "hello {} and {}!" print(flag.format('python','php')) #Variable parameters flag = "{name} is {age} years old!" print(flag.format(name='Frank',age = 23)) #Combination list infor=["Frank",23] print("{0[0]} is {0[1]} years old".format(infor)) #Operation results hello python and php! hello python and php! Frank is 23 years old! Frank is 23 years old
.format_map()
Format output
def format_map(self, mapping): # real signature unknown; restored from __doc__ """ S.format_map(mapping) -> str Return a formatted version of S, using substitutions from mapping. The substitutions are identified by braces ('{' and '}'). """ return ""
For instance
people={ 'name':['Frank','Caroline'], 'age':['23','22'], } print("My name is {name[0]},i am {age[1]} years old !".format_map(people)) #Operation results My name is Frank,i am 22 years old !
.index()
Find the index value according to the character, you can specify the index range to find, the search can not find the error.
def index(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.index(sub[, start[, end]]) -> int Like S.find() but raise ValueError when the substring is not found. """ return 0
For instance
flag = "hello python!" print(flag.index("e")) print(flag.index("o",6,-1)) #Operation results 1 10
.isalnum()
Determine whether it is a combination of letters or numbers, returning Boolean values?
def isalnum(self): # real signature unknown; restored from __doc__ """ S.isalnum() -> bool Return True if all characters in S are alphanumeric and there is at least one character in S, False otherwise. """ return False
For instance
flag = "hellopython" flag1 = "hellopython22" flag2 = "hellopython!!" flag3 = "!@#!#@!!@" print(flag.isalnum()) print(flag1.isalnum()) print(flag2.isalnum()) print(flag3.isalnum()) #Operation results True True False False
.isalpha()
Determine whether it is a combination of letters and return Boolean values?
def isalpha(self): # real signature unknown; restored from __doc__ """ S.isalpha() -> bool Return True if all characters in S are alphabetic and there is at least one character in S, False otherwise. """ return False
For instance
flag = "hellopython" flag1 = "hellopython22" print(flag.isalpha()) print(flag1.isalpha()) #Operation results True False
.isdecimal()
Determine whether it is a decimal positive integer, returning a Boolean value?
def isdecimal(self): # real signature unknown; restored from __doc__ """ S.isdecimal() -> bool Return True if there are only decimal characters in S, False otherwise. """ return False
For instance
number = "1.2" number1 = "12" number2 = "-12" number3 = "1222" print(number.isdecimal()) print(number1.isdecimal()) print(number2.isdecimal()) print(number3.isdecimal()) #Operation results False True False True
isdigit()
Determine whether it is a positive integer and return a Boolean value, similar to isdecimal above?
def isdigit(self): # real signature unknown; restored from __doc__ """ S.isdigit() -> bool Return True if all characters in S are digits and there is at least one character in S, False otherwise. """ return False
For instance
number = "1.2" number1 = "12" number2 = "-12" number3 = "11" print(number.isdigit()) print(number1.isdigit()) print(number2.isdigit()) print(number3.isdigit()) #Operation results False True False True
.isidentifier()
Determine whether it is an identifier in python
def isidentifier(self): # real signature unknown; restored from __doc__ """ S.isidentifier() -> bool Return True if S is a valid identifier according to the language definition. Use keyword.iskeyword() to test for reserved identifiers such as "def" and "class". """ return False
For instance
flag = "cisco" flag1 = "1cisco" flag2 = "print" print(flag.isidentifier()) print(flag1.isidentifier()) print(flag2.isidentifier()) #Operation results True False True
.islower()
Determine whether the letters in the string are all lowercase and return Boolean values?
def islower(self): # real signature unknown; restored from __doc__ """ S.islower() -> bool Return True if all cased characters in S are lowercase and there is at least one cased character in S, False otherwise. """ return False
For instance
flag = "cisco" flag1 = "cisco222" flag2 = "Cisco" print(flag.islower()) print(flag1.islower()) print(flag2.islower()) #Operation results True True False
.isnumeric()
Judging whether it is a number or not, this is very powerful. Chinese characters and traditional characters can be recognized.
def isnumeric(self): # real signature unknown; restored from __doc__ """ S.isnumeric() -> bool Return True if there are only numeric characters in S, False otherwise. """ return False
For instance
number = "123" number1 = "One" number2 = "One" number3 = "123q" number4 = "1.1" print(number.isnumeric()) print(number1.isnumeric()) print(number2.isnumeric()) print(number3.isnumeric()) print(number4.isnumeric()) #Operation results True True True False False
.isprintable()
Determine whether all quotation marks are printable and return Boolean values
def isprintable(self): # real signature unknown; restored from __doc__ """ S.isprintable() -> bool Return True if all characters in S are considered printable in repr() or S is empty, False otherwise. """ return False
For instance
flag = "\n123" flag1 = "\t" flag2 = "123" flag3 = r"\n123" # r Can be escaped character invalidation print(flag.isprintable()) #\n Non-printable print(flag1.isprintable()) #\t Non-printable print(flag2.isprintable()) print(flag3.isprintable()) #Operation results False False True True
.isspace()
Judging that the string is blank, blank, or tab, returns a Boolean value
def isspace(self): # real signature unknown; restored from __doc__ """ S.isspace() -> bool Return True if all characters in S are whitespace and there is at least one character in S, False otherwise. """ return False
For instance
flag = ' ' #4 A space flag1 = ' '#2 individual tab print(flag.isspace()) print(flag1.isspace()) #Operation results True True
.istitle()
Determine whether the characters in the string are all capitalized and return Boolean values
def isspace(self): # real signature unknown; restored from __doc__ """ S.isspace() -> bool Return True if all characters in S are whitespace and there is at least one character in S, False otherwise. """ return False
For instance
flag = "Welcome Frank" flag1 = "Welcome frank" print(flag.istitle()) print(flag1.istitle()) #Operation results True False
.isupper()
Determine whether all the letters in the string are capitalized
def isupper(self): # real signature unknown; restored from __doc__ """ S.isupper() -> bool Return True if all cased characters in S are uppercase and there is at least one cased character in S, False otherwise. """ return False
For instance
flag = "WELCOME1" flag1 = "Welcome1" print(flag.isupper()) print(flag1.isupper()) #Operation results True False
.join()
Generates a new string by concatenating the string with the specified character
def join(self, iterable): # real signature unknown; restored from __doc__ """ S.join(iterable) -> str Return a string which is the concatenation of the strings in the iterable. The separator between elements is S. """ return ""
For instance
flag = "welcome" print("#".join(flag)) #Operation results w#e#l#c#o#m#e
.ljust()
Left alignment, specifying character width and padding characters
def ljust(self, width, fillchar=None): # real signature unknown; restored from __doc__ """ S.ljust(width[, fillchar]) -> str Return S left-justified in a Unicode string of length width. Padding is done using the specified fill character (default is a space). """ return ""
For instance
flag = "welcome" print(flag.ljust(20,"*")) #Operation results welcome*************
.rjust()
Right alignment, specifying character width and padding characters
def rjust(self, width, fillchar=None): # real signature unknown; restored from __doc__ """ S.rjust(width[, fillchar]) -> str Return S right-justified in a string of length width. Padding is done using the specified fill character (default is a space). """ return ""
For instance
flag = "welcome" print(flag.rjust(20,"*")) #Operation results *************welcome
.lower()
Convert all letters in a string to lowercase
def lower(self): # real signature unknown; restored from __doc__ """ S.lower() -> str Return a copy of the string S converted to lowercase. """ return ""
For instance
flag = "WELcome" #Operation results welcome
.upper()
Capitalize all letters in a string
def upper(self): # real signature unknown; restored from __doc__ """ S.upper() -> str Return a copy of S converted to uppercase. """ return ""
For instance
flag = "WELcome" print(flag.upper()) #Operation results WELCOME
.title()
Capitalization of words in strings
def title(self): # real signature unknown; restored from __doc__ """ S.title() -> str Return a titlecased version of S, i.e. words start with title case characters, all remaining cased characters have lower case. """ return ""
For instance
flag = "welcome frank" print(flag.title()) #Operation results Welcome Frank
.lstrip()
By default, the left blank character is removed, and the removed character can be specified. When the specified character is removed, it will be occupied by the blank space.
def lstrip(self, chars=None): # real signature unknown; restored from __doc__ """ S.lstrip([chars]) -> str Return a copy of the string S with leading whitespace removed. If chars is given and not None, remove characters in chars instead. """ return ""
For instance
flag = " welcome frank" flag1 = "@@@@welcome frank" print(flag.lstrip()) print(flag.lstrip("@")) print(flag.lstrip("@").lstrip()) #Operation results welcome frank welcome frank welcome frank
.rstrip()
By default, the right blank character is removed, and the removed character can be specified. When the specified character is removed, it will be occupied by the blank space.
def rstrip(self, chars=None): # real signature unknown; restored from __doc__ """ S.rstrip([chars]) -> str Return a copy of the string S with trailing whitespace removed. If chars is given and not None, remove characters in chars instead. """ return ""
For instance
flag = "welcome frank " flag1 = "welcome frank@@@@" # print(flag.title()) print(flag.rstrip()) print(flag.rstrip("@")) print(flag.rstrip("@").rstrip()) #Operation results welcome frank welcome frank #There are four spaces on the right. welcome frank
.strip()
The default removal of blank characters on both sides can specify the removal of characters, after removal of the specified characters, will be blank space.
def strip(self, chars=None): # real signature unknown; restored from __doc__ """ S.strip([chars]) -> str Return a copy of the string S with leading and trailing whitespace removed. If chars is given and not None, remove characters in chars instead. """ return ""
For instance
flag = " welcome frank " flag1 = "@@@@welcome frank@@@@" # print(flag.title()) print(flag.strip()) print(flag.strip("@")) print(flag.strip("@").strip()) #Operation results welcome frank welcome frank #There are four spaces on the right. welcome frank
maketrans() and translate()
To create a character mapping conversion table, for the simplest way to accept two parameters, the first parameter is the string, which represents the character to be converted, and the second parameter is also the string which represents the target of conversion. The length of the two strings must be the same, a one-to-one correspondence.
def maketrans(self, *args, **kwargs): # real signature unknown """ Return a translation table usable for str.translate(). If there is only one argument, it must be a dictionary mapping Unicode ordinals (integers) or characters to Unicode ordinals, strings or None. Character keys will be then converted to ordinals. If there are two arguments, they must be strings of equal length, and in the resulting dictionary, each character in x will be mapped to the character at the same position in y. If there is a third argument, it must be a string, whose characters will be mapped to None in the result. """ pass
def translate(self, table): # real signature unknown; restored from __doc__ """ S.translate(table) -> str Return a copy of the string S in which each character has been mapped through the given translation table. The table must implement lookup/indexing via __getitem__, for instance a dictionary or list, mapping Unicode ordinals to Unicode ordinals, strings, or None. If this operation raises LookupError, the character is left untouched. Characters mapped to None are deleted. """ return ""
For instance
intab = "aeiou" outtab = "12345" trantab = str.maketrans(intab, outtab) str = "this is string example....wow!!!" print (str.translate(trantab)) #Operation results th3s 3s str3ng 2x1mpl2....w4w!!!
.partition()
Returns a tuple partitioned by a specified character
def partition(self, sep): # real signature unknown; restored from __doc__ """ S.partition(sep) -> (head, sep, tail) Search for the separator sep in S, and return the part before it, the separator itself, and the part after it. If the separator is not found, return S and two empty strings. """ pass
For instance
flag = "welcome" print(flag.partition("e")) #Operation results ('w', 'e', 'lcome')
.replace()
Replaces the specified character with a new character, specifying the number of replacements
def replace(self, old, new, count=None): # real signature unknown; restored from __doc__ """ S.replace(old, new[, count]) -> str Return a copy of S with all occurrences of substring old replaced by new. If the optional argument count is given, only the first count occurrences are replaced. """ return ""
For instance
flag = "welcome frank ,e.." print(flag.replace("e","z")) print(flag.replace("e","z",1)) #Operation results wzlcomz frank ,z.. wzlcome frank ,e..
.rfind()
Returns the position of the first occurrence of the string, the difference from right to left, the index value, and - 1, if not, according to the index range.
def rfind(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.rfind(sub[, start[, end]]) -> int Return the highest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """ return 0
For instance
flag = "welcome frank ,e.." print(flag.rfind("e")) print(flag.rfind("x")) print(flag.rfind("e",0,3)) #Operation results 15 -1 1
.rindex()
Find the character index value, from right to left, return the index value, similar to rfind, find no error
def rindex(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ """ S.rindex(sub[, start[, end]]) -> int Like S.rfind() but raise ValueError when the substring is not found. """ return 0
For instance
flag = "welcome frank ,e.." print(flag.rindex("e")) print(flag.rindex("e",0,3)) #Operation results 15 1
.rpartition()
Returns a tuple by separating the specified character from right to left only once. If there is no specified character, two empty strings are added before the returned tuple.
def rpartition(self, sep): # real signature unknown; restored from __doc__ """ S.rpartition(sep) -> (head, sep, tail) Search for the separator sep in S, starting at the end of S, and return the part before it, the separator itself, and the part after it. If the separator is not found, return two empty strings and S. """ pass
For instance
flag = "welcome frank ,e.." print(flag.rpartition("e")) print(flag.rpartition("x")) #Operation results ('welcome frank ,', 'e', '..') ('', '', 'welcome frank ,e..')
.split()
Partition, can be divided by the specified character, can specify the number of partitions, the default from left to right partition, different from partition, split partition will delete the specified character, default to space as a partitioner, return tuple.
def split(self, sep=None, maxsplit=-1): # real signature unknown; restored from __doc__ """ S.split(sep=None, maxsplit=-1) -> list of strings Return a list of the words in S, using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done. If sep is not specified or is None, any whitespace string is a separator and empty strings are removed from the result. """ return []
For instance
flag = "welcome frank, e.." print(flag.split()) print(flag.split('e')) print(flag.split('e',1)) #Operation results ['welcome', 'frank,', 'e..'] ['w', 'lcom', ' frank, ', '..'] ['w', 'lcome frank, e..']
.rsplit()
Similar to split, it's just a right-to-left score
def rsplit(self, sep=None, maxsplit=-1): # real signature unknown; restored from __doc__ """ S.rsplit(sep=None, maxsplit=-1) -> list of strings Return a list of the words in S, using sep as the delimiter string, starting at the end of the string and working to the front. If maxsplit is given, at most maxsplit splits are done. If sep is not specified, any whitespace string is a separator. """ return []
For instance
flag = "welcome frank, e.." print(flag.rsplit()) print(flag.rsplit('e')) print(flag.rsplit('e',1)) #Operation results ['welcome', 'frank,', 'e..'] ['w', 'lcom', ' frank, ', '..'] ['welcome frank, ', '..']
.splitlines()
Converting strings to lists
def splitlines(self, keepends=None): # real signature unknown; restored from __doc__ """ S.splitlines([keepends]) -> list of strings Return a list of the lines in S, breaking at line boundaries. Line breaks are not included in the resulting list unless keepends is given and true. """ return []
For instance
info = "hello,my name is Frank" print(info.splitlines()) #Operation results ['hello,my name is Frank']
.startswith()
Determines whether to start with a specified string or character, specifies the index range, and returns a Boolean value
def startswith(self, prefix, start=None, end=None): # real signature unknown; restored from __doc__ """ S.startswith(prefix[, start[, end]]) -> bool Return True if S starts with the specified prefix, False otherwise. With optional start, test S beginning at that position. With optional end, stop comparing S at that position. prefix can also be a tuple of strings to try. """ return False
For instance
info = "hello,my name is Frank" print(info.startswith("he")) print(info.startswith("e")) print(info.startswith("m",6,-1)) #Operation results True False True
.swapcase()
Interchange case and case in strings
def swapcase(self): # real signature unknown; restored from __doc__ """ S.swapcase() -> str Return a copy of S with uppercase characters converted to lowercase and vice versa. """ return ""
For instance
info = "Hello,My name is Frank" print(info.swapcase()) #Operation results hELLO,mY NAME IS fRANK
.zfill()
Specify the width of the string and fill in "0" on the right side of the insufficient string
def zfill(self, width): # real signature unknown; restored from __doc__ """ S.zfill(width) -> str Pad a numeric string S with zeros on the left, to fill a field of the specified width. The string S is never truncated. """ return ""
For instance
info = "Hello,My name is Frank" print(info.zfill(50)) #Operation results 0000000000000000000000000000Hello,My name is Frank
List
A list consists of a series of elements arranged in a specific order. In python, square brackets ([]) are used to represent lists and commas are used to divide the elements. Let's look at a simple list with a type of "list".
name = ['Frank','Caroline','Bob','Saber'] print(name) #Direct printing prints out the middle brackets, quotes, and commas print(name[1]) #Adding an index prints the corresponding value, starting from 0. print(name[-1]) #Print the last element print(name[0:2]) #Slice with colons,Take the right instead of the left print(name[-2:]) #Not writing on the right side of the colon means printing until the last one print(name[:1]) #Not writing on the left side of the colon means printing from "0"
Common methods are as follows:
.index()
Find the index value of the corresponding element, return the index value, you can specify the index range to find, can not find error
def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ """ L.index(value, [start, [stop]]) -> integer -- return first index of value. Raises ValueError if the value is not present. """ return 0
For example
name = ['Frank','Caroline','Bob','Saber'] print(name.index("Frank")) print(name.index("Bob",1,-1)) #Operation results 0 2
.count()
Calculate the number of elements
def count(self, value): # real signature unknown; restored from __doc__ """ L.count(value) -> integer -- return number of occurrences of value """ return 0
For example
name = ['Frank','Caroline','Bob','Saber','Frank'] print(name.count('Frank')) #Operation results 2
.append()
Adding elements to the end of the list
def append(self, p_object): # real signature unknown; restored from __doc__ """ L.append(object) -> None -- append object to end """ pass
For example
name = ['Frank','Caroline','Bob','Saber','Frank'] name.append('Mei') print(name) #Operation results ['Frank', 'Caroline', 'Bob', 'Saber', 'Frank', 'Mei']
.clear()
Clear lists
def clear(self): # real signature unknown; restored from __doc__ """ L.clear() -> None -- remove all items from L """ pass
For example
name = ['Frank','Caroline','Bob','Saber','Frank'] name.clear() print(name) #Operation results []
.copy()
Duplicate lists
def copy(self): # real signature unknown; restored from __doc__ """ L.copy() -> list -- a shallow copy of L """ return []
For example
name = ['Saber','Frank',1,2,[3,4]] name_cp = name.copy() print(name_cp) name[0]='Tom' name[3]='7' name[4][0]='8' print(name) print(name_cp) #Operation results ['Saber', 'Frank', 1, 2, [3, 4]] ['Tom', 'Frank', 1, '7', ['8', 4]] ['Saber', 'Frank', 1, 2, ['8', 4]]
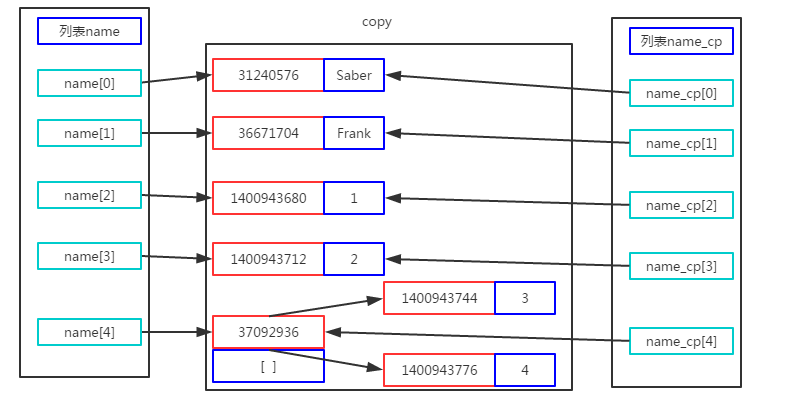
When we replicate, the newly replicated list points to the address space of the replicated list. name[4] and name_cp[4] are also lists themselves, which point to the same list address space. Let's look at the change in address space after reassigning the name list:
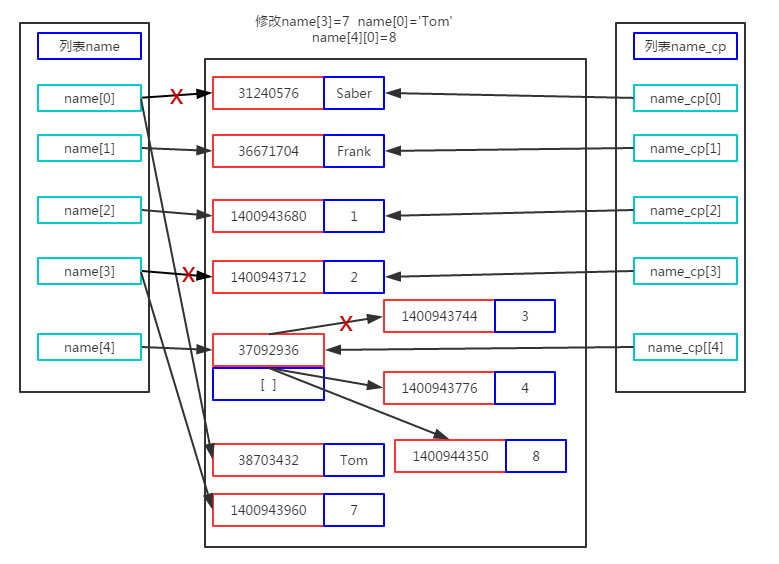
After reassignment, memory opens up a new memory space for name[3], name[0], name[4][0]. name[0] points to memory address 38703432, name[3] points to memory address 1400943960, and name[4] points to 37092936, but memory address 37092936 points to name[4][0] memory address has changed, pointing to 1400944350, so we give it weight in the list. When new assignments are made, the values of replicated lists are also changed, because the lists in their lists all point to the same address space. So what if we want to replicate it completely?
The function deepcopy() can be called.
import copy name = ['Saber','Frank',1,2,[3,4]] name_cp=copy.deepcopy(name) name[4][0]=5 print(name) print(name_cp) #Operation results ['Saber', 'Frank', 1, 2, [5, 4]] ['Saber', 'Frank', 1, 2, [3, 4]]
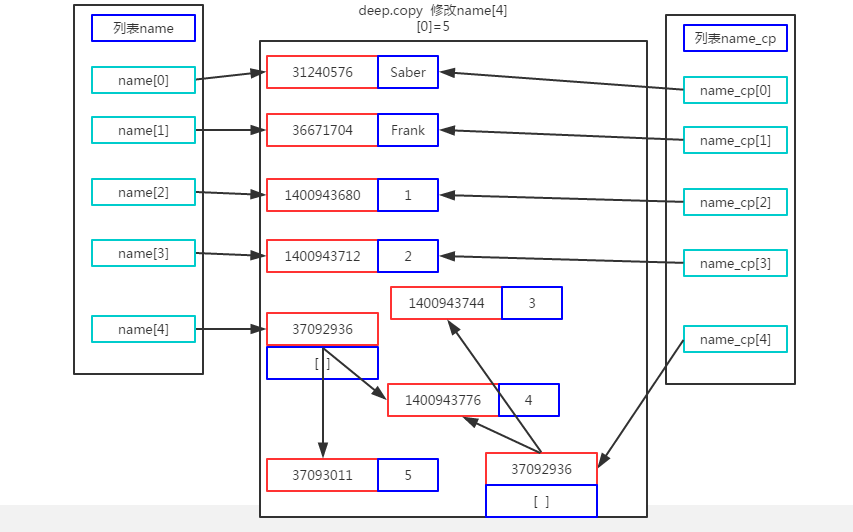
This will re-create an address space for the list in the replicated list and point to the address space of the elements in the list, so how do you change the original list name, name_copy will not change.
.extend()
The function is used to append multiple values in another sequence at the end of the list at once (expanding the original list with a new list).
def extend(self, iterable): # real signature unknown; restored from __doc__ """ L.extend(iterable) -> None -- extend list by appending elements from the iterable """ pass
For example
name = ['Saber','Frank'] nameto = ['Mei','Jack'] name.extend(nameto) print(name) #Operation results ['Saber', 'Frank', 'Mei', 'Jack']
insert()
Insert element, need to specify index value to insert
def insert(self, index, p_object): # real signature unknown; restored from __doc__ """ L.insert(index, object) -- insert object before index """ pass
For example
name = ['Saber','Frank'] name.insert(0,'Jack') print(name) #Operation results ['Jack', 'Saber', 'Frank']
.pop()
Pop-up element, the default pop-up of the last element, can specify the index, pop-up corresponding elements, when the list pops up empty or no specified index value will be wrong, and return the pop-up value.
def pop(self, index=None): # real signature unknown; restored from __doc__ """ L.pop([index]) -> item -- remove and return item at index (default last). Raises IndexError if list is empty or index is out of range. """ pass
For instance
name = ['Saber','Frank','Caroline','Jack'] name.pop() print(name) name = ['Saber','Frank','Caroline','Jack'] name.pop(1) print(name) #Operation results ['Saber', 'Frank', 'Caroline'] ['Saber', 'Caroline', 'Jack']
.remove()
Remove the specified element
def remove(self, value): # real signature unknown; restored from __doc__ """ L.remove(value) -> None -- remove first occurrence of value. Raises ValueError if the value is not present. """ pass
For example
name = ['Saber','Frank','Caroline','Jack'] name.remove('Frank') print(name) #Operation results ['Saber', 'Caroline', 'Jack']
.reverse()
Inversion of List, Permanent Modification
def reverse(self): # real signature unknown; restored from __doc__ """ L.reverse() -- reverse *IN PLACE* """ pass
For example
name = ['Saber','Frank','Caroline','Jack'] name.reverse() print(name) #Operation results ['Jack', 'Caroline', 'Frank', 'Saber']
.sort()
Sort lists, permanently modify them. If there are different types of data in the list at the same time, it can not be sorted, such as containing integers and strings. Passing reverse=True can be sorted backwards.
def sort(self, key=None, reverse=False): # real signature unknown; restored from __doc__ """ L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE* """ pass
For instance
name = ['Saber','Frank','Caroline','Jack','1','abc','xyz'] name.sort() print(name) name.sort(reverse=True) print(name) #Operation results ['1', 'Caroline', 'Frank', 'Jack', 'Saber', 'abc', 'xyz'] ['xyz', 'abc', 'Saber', 'Jack', 'Frank', 'Caroline', '1'] number = [1,2,3,42,12,32,43,543] number.sort() print(number) number.sort(reverse=True) print(number) #Operation results [1, 2, 3, 12, 32, 42, 43, 543] [543, 43, 42, 32, 12, 3, 2, 1]
V. Tuples
Tuples are similar to lists, except that elements of tuples cannot be modified. They are enclosed in parentheses (). They are separated by commas, and their type is tuple.
number = (1,2,2,2,1) print(type(number)) print(number[0]) print(number[-1]) print(number[1:]) #Operation results <class 'tuple'> 1 1 (2, 2, 2, 1)
Common methods are as follows:
.count()
Calculate the number of specified elements
def count(self, value): # real signature unknown; restored from __doc__ """ T.count(value) -> integer -- return number of occurrences of value """ return 0
For instance
number = (1,2,2,2,1) print(number.count(2)) #Operation results 3
.index()
Find the index of the specified element, you can specify the index range to find
def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ """ T.index(value, [start, [stop]]) -> integer -- return first index of value. Raises ValueError if the value is not present. """ return 0
For instance
number = (1,2,2,2,1) print(number.index(2)) print(number.index(2,2,-1)) #Operation results 1 2
VI. Collection
Sets are a series of disordered elements, so you can't use index values. When printing, tuples are naturally sorted, naturally de-duplicated, and their type is set.
number = {1,2,3,4,4,5,6}
number1 = {1,6,2,1,8,9,10}
print(number)
print(number1)
#Operation results
{1, 2, 3, 4, 5, 6}
{1, 2, 6, 8, 9, 10}
Common methods are as follows
.remove()
Remove the specified element
def remove(self, *args, **kwargs): # real signature unknown """ Remove an element from a set; it must be a member. If the element is not a member, raise a KeyError. """ pass
For instance
number = {1,2,3,4,4,5,6}
print(number)
number.remove(1)
print(number)
#Operation results
{1, 2, 3, 4, 5, 6}
{2, 3, 4, 5, 6}
.pop()
The first element after pop-up sorting
def pop(self, *args, **kwargs): # real signature unknown """ Remove and return an arbitrary set element. Raises KeyError if the set is empty. """ pass
For instance
number = {1,2,3,4,4,5,6}
print(number)
number_pop = number.pop()
print(number_pop)
print(number)
#Operation results
{1, 2, 3, 4, 5, 6}
1
{2, 3, 4, 5, 6}
.clear()
Empty list returns set()
def clear(self, *args, **kwargs): # real signature unknown """ Remove all elements from this set. """ pass
For instance
number = {1,2,3,4,4,5,6}
print(number)
number.clear()
print(number)
#Operation results
{1, 2, 3, 4, 5, 6}
set()
.copy()
Replication set
def copy(self, *args, **kwargs): # real signature unknown """ Return a shallow copy of a set. """ pass
For instance
number = {1,2,3,4,4,5,6}
print(number)
number2 = number.copy()
number.pop()
print(number)
print(number2)
#Operation results
{1, 2, 3, 4, 5, 6}
{2, 3, 4, 5, 6}
{1, 2, 3, 4, 5, 6}
.add()
Adding elements
def add(self, *args, **kwargs): # real signature unknown """ Add an element to a set. This has no effect if the element is already present. """ pass
For instance
number = {1,2,3,4,4,5,6}
print(number)
number.add(7)
print(number)
#Operation results
{1, 2, 3, 4, 5, 6}
{1, 2, 3, 4, 5, 6, 7}
.difference()
The difference set can be replaced by "-"
def difference(self, *args, **kwargs): # real signature unknown """ Return the difference of two or more sets as a new set. (i.e. all elements that are in this set but not the others.) """ pass
For instance
number = {1,2,3,4,5,6,8,9}
number1 = {2,3,8,9,11,12,10}
print(number.difference(number1))
print(number1.difference(number))
print(number - number1)
print(number1 - number)
##Operation results
{1, 4, 5, 6}
{10, 11, 12}
{1, 4, 5, 6}
{10, 11, 12}
.union()
The merging set can be replaced by "|"
def union(self, *args, **kwargs): # real signature unknown """ Return the union of sets as a new set. (i.e. all elements that are in either set.) """ pass
For instance
number = {1,2,3,4,5,6,8,9}
number1 = {2,3,8,9,11,12,10}
print(number.union(number1))
print(number | number1)
#Operation results
{1, 2, 3, 4, 5, 6, 8, 9, 10, 11, 12}
{1, 2, 3, 4, 5, 6, 8, 9, 10, 11, 12}
difference_update.()
Differential update, no return value, direct modification of the collection
def difference_update(self, *args, **kwargs): # real signature unknown """ Remove all elements of another set from this set. """ pass
For instance
number = {1,2,3,4,5,6,8,9,13}
number1 = {2,3,8,9,11,12,10}
number.difference_update(number1)
print(number)
#Operation results
{1, 4, 5, 6, 13}
.discard()
Remove the specified element and do nothing if there is no specified element in the collection
def discard(self, *args, **kwargs): # real signature unknown """ Remove an element from a set if it is a member. If the element is not a member, do nothing. """ pass
For instance
number = {1,2,3,4,5,6,8,9,13}
number.discard(1)
print(number)
#Operation results
{2, 3, 4, 5, 6, 8, 9, 13}
.intersection()
Intersection can be replaced by "&"
def intersection(self, *args, **kwargs): # real signature unknown """ Return the intersection of two sets as a new set. (i.e. all elements that are in both sets.) """ pass
For instance
number = {1,2,3,4,5,6,8,9,13}
number1 = {1,2,3,4,5,13,16,17}
print(number.intersection(number1))
print(number & number1)
#Operation results
{1, 2, 3, 4, 5, 13}
{1, 2, 3, 4, 5, 13}
.intersection_update()
Intersection update, no return value, modify the collection directly
def intersection_update(self, *args, **kwargs): # real signature unknown """ Update a set with the intersection of itself and another. """ pass
For instance
number = {1,2,3,4,5,6,8,9,13}
number1 = {1,2,3,4,5,13,16,17}
number.intersection_update(number1)
print(number)
#Operation results
{1, 2, 3, 4, 5, 13}
isdisjoint()
When two sets do not intersect, return True or False
def isdisjoint(self, *args, **kwargs): # real signature unknown """ Return True if two sets have a null intersection. """ pass
For instance
number = {1,2,3,4,5,6,8,9,13}
number1 = {16,17}
print(number.isdisjoint(number1))
#Operation results
True
number = {1,2,3,4,5,6,8,9,13,16}
number1 = {16,17}
#Operation results
False
.issubset()
When there are two sets A and B, A.issubset(B), whether A is included by B, if so, return True, or return False
def issubset(self, *args, **kwargs): # real signature unknown """ Report whether another set contains this set. """ pass
For instance
number = {1,2,3,4,5,6,8,9,13,16,17}
number1 = {16,17}
print(number1.issubset(number))
#Operation results
True
.issuperset()
When there are two sets A and B, A. is superset (B), whether A contains B, if it contains, it returns True, otherwise it returns False.
def issuperset(self, *args, **kwargs): # real signature unknown """ Report whether this set contains another set. """ pass
For instance
number = {1,2,3,4,5,6,8,9,13,16,17}
number1 = {16,17}
print(number.issuperset(number1))
#Operation results
True
.symmetric_difference()
Take the difference set of two sets, that is, the elements that are not in each other's set.
def symmetric_difference(self, *args, **kwargs): # real signature unknown """ Return the symmetric difference of two sets as a new set. (i.e. all elements that are in exactly one of the sets.) """ pass
For instance
number = {1,2,3,4,5,6,8,9,13,16,17}
number1 = {16,17,18,19}
print(number.symmetric_difference(number1))
#Operation results
{1, 2, 3, 4, 5, 6, 8, 9, 13, 18, 19}
.symmetric_difference_update()
Take the difference set of two sets, that is, take the elements that neither of the two sets has, and update them to the set.
def symmetric_difference_update(self, *args, **kwargs): # real signature unknown """ Update a set with the symmetric difference of itself and another. """ pass
For instance
number = {1,2,3,4,5,6,8,9,13,16,17}
number1 = {16,17,18,19}
number.symmetric_difference_update(number1)
print(number)
#Operation results
{1, 2, 3, 4, 5, 6, 8, 9, 13, 18, 19}
.update()
Take the union of two sets and update them to the set
def update(self, *args, **kwargs): # real signature unknown """ Update a set with the union of itself and others. """ pass
For instance
number = {1,2,3,4,5,6,8,9,13,16,17}
number1 = {16,17,18,19}
number.update(number1)
print(number)
#Operation results
{1, 2, 3, 4, 5, 6, 8, 9, 13, 16, 17, 18, 19}
VII. Dictionaries
In python, a dictionary is a series of key-values, each of which corresponds to a value, and keys can be numbers, strings, lists and dictionaries. In fact, any Python object can be used as a dictionary value.
info = { 'name':'Frank', 'age':23, 'hobbby':'reading', 'address':'Shanghai', } print(info) print(info['age']) #Operation results {'name': 'Frank', 'age': 23, 'hobbby': 'reading', 'address': 'Shanghai'} 23
The methods are as follows:
.keys()
Take out the key of the dictionary
def keys(self): # real signature unknown; restored from __doc__ """ D.keys() -> a set-like object providing a view on D's keys """ pass
For instance
info = { 'name':'Frank', 'age':23, 'hobbby':'reading', 'address':'Shanghai', } print(info.keys()) #Operation results dict_keys(['name', 'age', 'hobbby', 'address'])
.values()
Remove the value of the dictionary
def values(self): # real signature unknown; restored from __doc__ """ D.values() -> an object providing a view on D's values """ pass
For instance
info = { 'name':'Frank', 'age':23, 'hobbby':'reading', 'address':'Shanghai', } #Operation results print(info.values())
.pop()
To pop up a key-value pair, the key must be specified
For example
info = { 'name':'Frank', 'age':23, 'hobbby':'reading', 'address':'Shanghai', } info.pop('name') print(info) #Operation results {'age': 23, 'hobbby': 'reading', 'address': 'Shanghai'}
.clear()
Empty the key-value pairs in the dictionary
def clear(self): # real signature unknown; restored from __doc__ """ D.clear() -> None. Remove all items from D. """ pass
For example
info = { 'name':'Frank', 'age':23, 'hobbby':'reading', 'address':'Shanghai', } info.clear() print(info) #Operation results {}
.update()
Update the dictionary. If there are two dictionaries A and B, A. update (B), the same key value of A and B will be updated by B, and the key value pairs that are not in B will be added to A.
def update(self, E=None, **F): # known special case of dict.update """ D.update([E, ]**F) -> None. Update D from dict/iterable E and F. If E is present and has a .keys() method, then does: for k in E: D[k] = E[k] If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v In either case, this is followed by: for k in F: D[k] = F[k] """ pass
For example
info = { 'name':'Frank', 'age':23, 'hobby':'reading', 'address':'Shanghai', } info_new = { 'age':24, 'hobby':'sleeping', 'QQ':'110110', } info.update(info_new) print(info) #Operation results {'name': 'Frank', 'age': 24, 'hobby': 'sleeping', 'address': 'Shanghai', 'QQ': '110110'}
.copy()
Reproduction of dictionaries
info = { 'name':'Frank', 'age':23, 'hobby':['reading','sleep'], 'address':'Shanghai', } info_new = info.copy() info['name']='Jack' info['hobby'][0]='writing' print(info) print(info_new) #Operation results {'name': 'Jack', 'age': 23, 'hobby': ['writing', 'sleep'], 'address': 'Shanghai'} {'name': 'Frank', 'age': 23, 'hobby': ['writing', 'sleep'], 'address': 'Shanghai'}
We will find that, like copy in the list, there are also elements of the list in the dictionary that are modified, and the dictionary that is copied will be automatically modified. This is actually the same reason as the previous one. We can also use deep copy here.
import copy info = { 'name':'Frank', 'age':23, 'hobby':['reading','sleep'], 'address':'Shanghai', } info_new = copy.deepcopy(info) info['name']='Jack' info['hobby'][0]='writing' print(info) print(info_new) #Operation results {'name': 'Jack', 'age': 23, 'hobby': ['writing', 'sleep'], 'address': 'Shanghai'} {'name': 'Frank', 'age': 23, 'hobby': ['reading', 'sleep'], 'address': 'Shanghai'}
Would the dictionary in the dictionary have the same problem?
info = { 'name':'Frank', 'age':23, 'hobby':['reading','sleep'], 'address':'Shanghai', 'language':{1:'Python',2:'Go'}, } info_new = info.copy() info['name']='Jack' info['hobby'][0]='writing' info['language'][2]='Java' print(info) print(info_new) #Operation results {'name': 'Jack', 'age': 23, 'hobby': ['writing', 'sleep'], 'address': 'Shanghai', 'language': {1: 'Python', 2: 'Java'}} {'name': 'Frank', 'age': 23, 'hobby': ['writing', 'sleep'], 'address': 'Shanghai', 'language': {1: 'Python', 2: 'Java'}}
The answer is, yes, when we want to modify the original dictionary, the copied dictionary remains unchanged, or we can use deep.copy to solve this problem.
import copy info = { 'name':'Frank', 'age':23, 'hobby':['reading','sleep'], 'address':'Shanghai', 'language':{1:'Python',2:'Go'}, } info_new = copy.deepcopy(info) info['name']='Jack' info['hobby'][0]='writing' info['language'][2]='Java' print(info) print(info_new) #Operation results {'name': 'Jack', 'age': 23, 'hobby': ['writing', 'sleep'], 'address': 'Shanghai', 'language': {1: 'Python', 2: 'Java'}} {'name': 'Frank', 'age': 23, 'hobby': ['reading', 'sleep'], 'address': 'Shanghai', 'language': {1: 'Python', 2: 'Go'}}
This is what we often say about shallow copy!
.fromkeys()
To create a new dictionary
def fromkeys(*args, **kwargs): # real signature unknown """ Returns a new dict with keys from iterable and values equal to value. """ pass
For example
key = (1,2,3,4,5) value = 'Python' print(dict.fromkeys(key,value)) #Operation results {1: 'Python', 2: 'Python', 3: 'Python', 4: 'Python', 5: 'Python'}
.get()
Return None if there is no key based on the key return value
info = { 'name':'Frank', 'age':23, 'hobby':['reading','sleep'], 'address':'Shanghai', } print(info.get('hobby')) #Operation results ['reading', 'sleep']
.items()
Return dict_items(), which is generally used in conjunction with for loops
info = { 'name':'Frank', 'age':23, 'hobby':['reading','sleep'], 'address':'Shanghai', } print(info.items()) #Operation results dict_items([('name', 'Frank'), ('age', 23), ('hobby', ['reading', 'sleep']), ('address', 'Shanghai')])
info = { 'name':'Frank', 'age':23, 'hobby':['reading','sleep'], 'address':'Shanghai', } for k,v in info.items(): print(k,"---",v) #Operation results name --- Frank age --- 23 hobby --- ['reading', 'sleep'] address --- Shanghai
.popitem()
When the last key is popped up, a tuple is returned. When the empty dictionary is popped up, an error will be reported.
def popitem(self): # real signature unknown; restored from __doc__ """ D.popitem() -> (k, v), remove and return some (key, value) pair as a 2-tuple; but raise KeyError if D is empty. """ pass
For example
info = { 'name':'Frank', 'age':23, 'hobby':['reading','sleep'], 'address':'Shanghai', } print(info.popitem()) info.popitem() print(info) #For instance ('address', 'Shanghai') {'name': 'Frank', 'age': 23}
.setdefault(key,value)
If the key is in the dictionary, the value of the key is returned. If it is not in the dictionary, the key is inserted into the dictionary and the value is returned. The default value bit is None.
For instance
info = { 'name':'Frank', 'age':23, 'hobby':['reading','sleep'], } print(info.setdefault('name')) #Existence bond name,Return value print(info) print(info.setdefault('address','shanghai')) #No key exists address,Return'shanghai',Adding key-value pairs print(info) print(info.setdefault('QQ')) #No key exists QQ,Add keys QQ,Return None print(info) #Operation results Frank {'name': 'Frank', 'age': 23, 'hobby': ['reading', 'sleep']} shanghai {'name': 'Frank', 'age': 23, 'hobby': ['reading', 'sleep'], 'address': 'shanghai'} None {'name': 'Frank', 'age': 23, 'hobby': ['reading', 'sleep'], 'address': 'shanghai', 'QQ': None}
That's all for today. Welcome to point out the mistakes and shortcomings. Thank you!