Tip: after the article is written, the directory can be generated automatically. Please refer to the help document on the right for how to generate it
Chapter VIII file operation (IO Technology)
Both the program and the stored data are complete; The program data we wrote earlier is not actually stored, so the data disappears after the python interpreter executes. In actual development, we often need to read data from external storage media (hard disk, optical disc, U SB flash disk, etc.), or store the data generated by the program into files to realize "persistent" storage.
Basic students know that many software systems store data in the database; In fact, the database is also stored in the form of files. In this chapter, we will learn the relevant operations of files.
Text and binary files
According to the data organization form in the file, we divide the file into two categories: text file and binary file.
-
text file
The text file stores ordinary "character" text. python defaults to unicode character set (two bytes represent one character, up to 65536), which can be opened by Notepad program. However, documents edited by word software are not text files. -
Binary file
Binary files store data contents in "bytes" and cannot be opened with Notepad. Special software must be used for decoding. Common are: MP4 video files, MP3 audio files, JPG pictures, doc documents and so on.
Overview of modules related to file operation
In the Python standard library, the following are the modules related to file operation, which we will introduce to you one after another.

Create file object (open)
The open() function is used to create file objects. The basic syntax format is as follows:
open(file name[,Open mode])
If it is just a file name, it represents the file in the current directory. The file name can be entered in the full path, for example: D:\a\b.txt. To reduce the input of "\", you can use the original string: r "d:\b.txt". Examples are as follows:
f = open(r"d:\b.txt","w")
The opening methods are as follows:
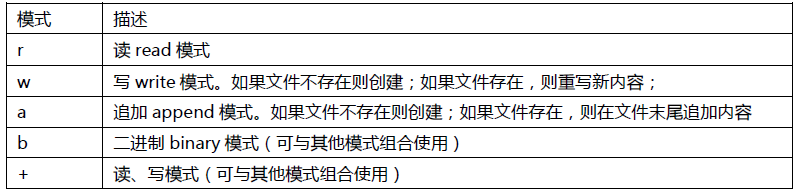
Creation of text file objects and binary file objects:
If we do not add the mode "b", we will create a text file object by default, and the basic unit of processing is "character". In case of binary mode "b", the binary file object is created, and the basic unit of processing is "byte".
Writing of text file
Basic file write operation
Writing text files is generally three steps:
- Create file object
- Write data
- Close file object
Let's first create a small program to experience the writing operation of text files.
[operation] simple test of text writing operation
f=open(r"b.txt","a") s="itbaizhan\nsxt\n" f.write(s) f.close()
Operation results:
itbaizhan
sxt
Introduction to common codes
When operating text files, we often operate Chinese. At this time, we often encounter the problem of garbled code. In order to enable you to solve the problem of Chinese garbled code, here is a brief introduction to the relationship between various codes.
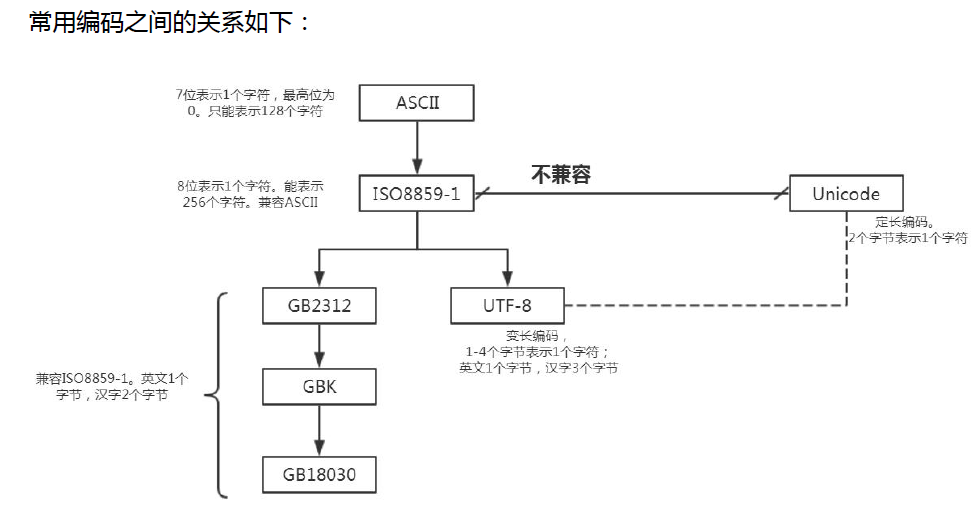
ASCII
Its full name is American Standard Code for Information Interchange
Information exchange standard code, which is the earliest and most common single byte coding system in the world. It is mainly used to display modern English and other Western European languages.
It can only be represented by 128 ASCII characters. Only 27 = 128 characters are defined, using
7 bits can be fully encoded, and the capacity of 8 bits per byte is 256, so the encoding of one byte ASCII is the most convenient
The high order is always 0.
ISO8859-1
ISO-8859-1, also known as Latin-1, is an 8-bit single byte character set, which puts the highest value of ASCII
Bit is also used and compatible with ASCII. The new space is 128, but it is not completely used up.
Western European languages, Greek, Thai, Arabic and Hebrew are added to the ASCII code
The corresponding text symbol, which is downward compatible with ASCII encoding
GB2312,GBK,GB18030
·GB2312
The full name of GB2312 is the Chinese character coded character set for information exchange. It was released in 1980 in China and is mainly used for information exchange
It is used for Chinese character processing in computer system. GB2312 mainly contains 6763 Chinese characters and 682 symbols.
GB2312 covers most of the usage of Chinese characters, but it can't deal with special rare words such as ancient Chinese, so codes such as GBK and GB18030 appeared later.
GB2312 is fully compatible with ISO8859-1.
·GBK
The full name is Chinese Internal Code Specification, that is, the internal code extension specification of Chinese characters, which was formulated in 1995. It mainly expands GB2312 and adds more Chinese characters on its basis. It contains a total of 21003 Chinese characters
·GB18030
The latest internal code word set was released in 2000 and enforced in 2001. It contains the language characters of most ethnic minorities in China and contains more than 70000 Chinese characters.
It mainly adopts single byte, double byte and four byte character coding. It is downward compatible with GB2312 and GBK. Although it is a compulsory standard in China, it is rarely used in actual production, and GBK and GB2312 are used most
Unicode
Unicode encoding is designed to fix two bytes, and all characters use 16 bits (2 ^ 16 = 65536)
Said, including the English characters that only occupied 8 bits before, so it will cause a waste of space. UNICODE has not been popularized and applied for a long time.
Unicode is completely redesigned and is not compatible with iso8859-1 or any other encoding.
UTF-8
For English letters, unicode also needs two bytes to represent. So unicode is inconvenient
For transmission and storage. Therefore, UTF coding is generated. The full name of UTF-8 is (8-bit Unicode)
Transformation Format).
UTF coding is compatible with iso8859-1 coding, and can also be used to represent characters in all languages,
However, UTF coding is variable length coding, and the length of each character ranges from 1-4 bytes. Among them, English letters are represented by one byte, while Chinese characters use three bytes.
[old bird's suggestion] UTF-8 will be used in general projects. In unicode, although Chinese characters are two bytes,
Chinese characters in UTF-8 are 3 bytes. However, a web page in the Internet also contains a large number of English letters. These English letters only occupy one byte and occupy space as a whole. UTF-8 is still better than Unicode.
Chinese garbled code problem
The default code of windows operating system is GBK, and the default code of Linux operating system is UTF-8. When we use open(), we call the file opened by the operating system, and the default code is GBK.
[example] solve the problem of Chinese garbled code by specifying the file code
f=open(r"c.txt","w",encoding="utf-8") s="Baizhan programmer\n Shang Xuetang\n" f.write(s) f.close()
Operation results:
Baizhan programmer
Shang Xuetang
write()/writelines() write data
write(a): writes the string a to a file
writelines(b): write the string list to the file without adding line breaks
close() closes the file stream
Since the underlying file is controlled by the operating system, the file object we open must explicitly call the close() method to close the file object. When the close() method is called, the buffer data will be written to the file first (or the flush() method can be called directly), and then the file will be closed to release the file object.
In order to ensure that the open file object can be closed normally, it is generally implemented in combination with the finally or with keyword of the exception mechanism to close the open file object in any case.
Schematic diagram of program call file:

[operation] combined with the exception mechanism, finally ensure that the file object is closed
# Use the exception mechanism to manage the closing operation of file objects
try:
f=open(r"c.txt","a")
strs=["zhangsan\n","lisi\n","wangwu\n"]
f.writelines(strs)
except BaseException as e:
print(e)
finally:
f.close()
Operation results:
Baizhan programmer
Shang Xuetang
zhangsan
zhangsan
lisi
wangwu
with statement (context manager)
The with keyword (context manager) can automatically manage context resources. No matter what reason jumps out of the with block, it can ensure that the file is closed correctly, and can automatically restore the scene when entering the code block after the code block is executed.
[operation] use with to manage file writing
# Test with statement
s=["zhangsan\n","lisi\n","wangwu\n"]
with open(r"d.txt","w") as f:
f.writelines(s)
Operation results:
zhangsan
lisi
wangwu
Reading of text file
The following three methods are generally used to read files:
- read([size])
Read size characters from the file and return them as results. If there is no size parameter, the entire file is read.
Reading to the end of the file returns an empty string. - readline()
Read a line and return it as a result. Reading to the end of the file returns an empty string. - readlines()
In the text file, each line is stored in the list as a string, and the list is returned
[operation] the file is small, and the contents of the file are read into the program at one time
# Test file reading
with open(r"e.txt","r",encoding="utf-8") as f:
str=f.read()
print(str)
Operation results:
high love u Shang Xuetang 12345 Process finished with exit code 0
[operation] use the iterator (return one line at a time) to read the text file
with open(r"e.txt","r",encoding="utf-8") as f:
for a in f:
print(a,end="")
Operation results:
high love u Shang Xuetang 12345 Process finished with exit code 0
[operation] add the line number at the end of each line of the text file
#a = ["Gao love u\n", "Shang school \ n","12345\n"]
#b=enumerate(a)
#print(a)
#print(list(b))
with open(r"e.txt","r",encoding="utf-8") as f:
lines=f.readlines()
lines=[line.rstrip()+" #"+str(index+1)+"\n" for index,line in enumerate(lines)]
with open(r"e.txt","w",encoding="utf-8") as f:
f.writelines(lines)
Operation results:
high love u #1 Shang Xuetang #2 12345 #3 SXTSXT #4
Reading and writing of binary files
The processing flow of binary file is consistent with that of text file. First, we need to create the file object, but we need to specify the binary mode to create the binary file object. For example:
f = open(r"d:\a.txt",'wb ') # writable, rewritable binary file object
f = open(r"d:\a.txt",'ab ') # writable, append mode binary object
f = open(r"d:\a.txt",'rb ') # readable binary object
After creating binary file objects, you can still use write() and read() to read and write files.
[operation] read the picture file and copy the file
with open(r"aa.gif","rb") as f:
with open(r"aa_copy.gif","wb") as w:
for line in f.readlines():
w.write(line)
print("Picture copy complete!!!")
Common properties and methods of file objects
File objects encapsulate file related operations. Earlier, we learned to read and write files through file objects. In this section, we list and explain the common attributes and methods of file objects in detail.
Properties of the file object
| attribute | explain |
|---|---|
| name | The name of the returned file |
| mode | Returns the open mode of the file |
| closed | Returns True if the file is closed |
Open mode of file object
| pattern | explain |
|---|---|
| r | Read mode |
| w | Write mode |
| a | append mode |
| b | Binary mode (can be combined with other modes) |
| + | Read write mode (can be combined with other modes) |
Common methods of file objects
| Method name | explain |
|---|---|
| read([size]) | Read the contents of size bytes or characters from the file and return. If [size] is omitted, it will be read to the end of the file, that is, all contents of the file will be read at one time |
| readline() | Read a line from a text file |
| readlines() | Take each line in the text file as an independent string object, and put these objects into the list to return |
| write(str) | Write string str contents to file |
| writelines(s) | Writes the string list s to the file without adding line breaks |
| seek(offset [,whence]) | Move the file pointer to the new position, and offset represents the offset of how many bytes relative to where; Offset: off is positive to the end and negative to the start. Different values represent different meanings: 0: calculated from the file header (default) 1: calculated from the current position 2: calculated from the end of the file |
| tell() | Returns the current position of the file pointer |
| truncate([size]) | No matter where the pointer is, only the first size byte of the pointer is left, and the rest are deleted; If no size is passed in, all contents will be deleted when the current position of the pointer reaches the end of the file |
| flush() | Writes the contents of the buffer to the file without closing the file |
| close() | Write the contents of the buffer into the file, close the file at the same time, and release the resources related to the file object |
[example] example of seek() moving file pointer
with open(r"e.txt","r",encoding="utf-8") as f:
print("The file name is:{0}".format(f.name))
print(f.tell())
print("Read content:{0}".format(str(f.readline())))
print(f.tell())
f.seek(3)
print(f.tell())
print("Read content:{0}".format(str(f.readline())))
print(f.tell())
Operation results:
The file name is: e.txt 0 Read content: high love u #1 14 3 Read content: love u #1 14 Process finished with exit code 0
Using pickle serialization
In Python, everything is an object, which is essentially a "memory block for storing data". Sometimes, we need to save the "data of memory block" to the hard disk or transmit it to other computers through the network. At this time, you need to "serialize and deserialize objects". Object serialization mechanism is widely used in distributed and parallel systems.
Serialization refers to the conversion of objects into "serialized" data form, which is stored on the hard disk or transmitted to other places through the network. The process of "deserializing" an object into data is the opposite of "deserializing" it.
We can use the functions in pickle module to realize serialization and deserialization.
Serialization we use:
pickle.dump(obj, file) obj Is the object to be serialized, file Refers to stored files pickle.load(file) from file Read the data and deserialize it into an object
[operation] serialize the object into a file
import pickle
a1="Gao Qi"
a2=234
a3=[10,20,30,40]
with open(r"data.dat","wb") as f:
pickle.dump(a1,f)
pickle.dump(a2, f)
pickle.dump(a3, f)
with open(r"data.dat","rb") as w:
b1 = pickle.load(w)
b2 = pickle.load(w)
b3 = pickle.load(w)
print(b1);print(b2);print(b3)
Operation results:
Gao Qi 234 [10, 20, 30, 40] Process finished with exit code 0
Operation of CSV file
csv(Comma Separated Values) is a comma separated text format, which is commonly used for data exchange, import and export of Excel files and database data
The module csv of Python standard library provides objects for reading and writing csv format files.
csv.reader object and CSV file reading
[operation] csv The reader object is used to read data from csv files
with open("dd.csv","r") as f:
a_csv=csv.reader(f)
#print(list(a_csv))
for row in a_csv:
print(row)
Operation results:
['ID', 'full name', 'Age', 'salary'] ['1001', 'Gao Qi', '18', '50000'] ['1002', 'Gao Ba', '19', '30000'] ['1003', 'Senior nine', '20', '20000']
csv.writer object and CSV file writing
[operation] csv The writer object writes a csv file
import csv
with open("ee.csv","w") as w:
b_csv=csv.writer(w)
b_csv.writerow(["ID","full name","Age"])
b_csv.writerow(["1001", "Gao Qi", "18"])
c=[["1002","Zhang San","20"],["1003","Li Si","23"]]
b_csv.writerows(c)
Operation results:
ID,full name,Age 1001,Gao Qi,18 1002,Zhang San,20 1003,Li Si,23
os and os Path module
os module can help us operate the operating system directly. We can directly call the executable files and commands of the operating system, and directly operate files, directories, etc. In the core foundation of system operation and maintenance.
os module - call operating system commands
·os.system can help us call system commands directly
·os.startfile: directly call the executable file
import os
#os.system("notepad.exe")
#os.system("regedit")
#os.system("ping www.baidu.com")
#os.system("cmd")
#Direct call to executable file
os.startfile(r"C:\Users\Lenovo\AppData\Roaming\baidu\BaiduNetdisk\BaiduNetdisk.exe")
os module - file and directory operations
We can read and write the file content through the file object mentioned above. If you need to do other operations on files and directories, you can use os and os Path module.
Methods of common operation files under os module
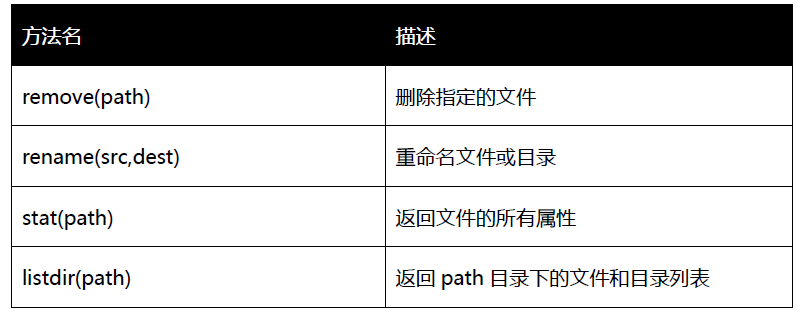
The relevant methods of directory operation under os module are summarized as follows:

#coding=utf-8
import os
##############Get information about files and folders######################
print(os.name) #Windows - > NT Linux and UNIX - > POSIX
print(os.sep) #Windows - > \ Linux and UNIX - >/
print(repr(os.linesep)) #windows->\r\n linux-->\n\
print(os.stat("my02.py"))
###############Operation of working directory#######################
#print(os.getcwd())
#os.chdir("c:") #Change the current working directory to: c: root directory
#os.mkdir("book")
################Create directory, create multi-level directory, delete#############
#os.rmdir("book") #Relative paths are relative to the current working directory
#os.makedirs("movie / RTHK / Stephen Chow")
#os.rmdir("film/Hong Kong and Taiwan/Zhou Xingchi") #Only empty directories can be deleted
#os.makedirs("music / Hong Kong / Stephen Chow")
#os.rename("Movie", "Movie")
dirs=os.listdir("movie")
print(dirs)
Operation results:
nt \ '\r\n' os.stat_result(st_mode=33206, st_ino=11540474045147788, st_dev=4204661902, st_nlink=1, st_uid=0, st_gid=0, st_size=823, st_atime=1644859569, st_mtime=1644858124, st_ctime=1644853267) ['Hong Kong and Taiwan'] Process finished with exit code 0
os.path module
os. The path module provides directory related operations (path judgment, path segmentation, path connection, folder traversal)
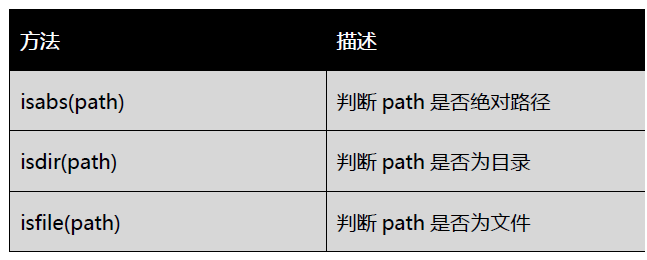

#Test OS Common methods of path
import os
import os.path
#################Obtain basic information of directories and files
print(os.path.isabs("c:/a.txt")) #Absolute path
print(os.path.isdir("c:/a.txt")) #Directory
print(os.path.isfile("c:/a.txt")) #File
print(os.path.exists("a.txt")) #Does the file exist
print(os.path.getsize("c:/a.txt")) #file size
print(os.path.abspath("a.txt")) #Output absolute path
print(os.path.dirname("c:/a.txt")) #Output directory
########Obtain the creation time, access time and last modification time##########
print(os.path.getctime("a.txt")) #Return creation time
print(os.path.getatime("a.txt")) #Return last access time
print(os.path.getmtime("a.txt")) #Return the last modification time
################Divide and connect paths####################
path = os.path.abspath("a.txt") #Return absolute path
print(os.path.split(path)) #Return tuple: directory, file
print(os.path.splitext(path)) #Return tuple: path, extension
print(os.path.join("aa","bb","cc")) #Return path: aa/bb/cc
Operation results:
True
False
True
True
378
C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\a.txt
c:/
1644858775.5383203
1644858794.551535
1644858793.554584
('C:\\Users\\Lenovo\\PycharmProjects\\mypro_io\\test_os', 'a.txt')
('C:\\Users\\Lenovo\\PycharmProjects\\mypro_io\\test_os\\a', '.txt')
aa\bb\cc
Process finished with exit code 0
[example] list all in the specified directory py file and output the file name
#coding=utf-8
#List all under the specified directory py file and output the file name
import os
import os.path
path=os.getcwd()
file_list=os.listdir(path)
for filename in file_list:
pos=filename.rfind(".")
if filename[pos+1:]=="py":
print(filename,end="\t")
print("\n##################")
file_list2=[filename for filename in os.listdir(path) if filename.endswith("py")]
for filename in file_list2:
print(filename,end="\t")
Operation results:
my01.py my02.py my03.py my04.py ################## my01.py my02.py my03.py my04.py Process finished with exit code 0
walk() recursively traverses all files and directories
os.walk() method:
Returns a tuple of 3 elements (dirpath, dirnames, filenames),
dirpath: To list the path of the specified directory dirnames: All folders under directory filenames: All files in the directory
[example] use walk() to recursively traverse all files and directories
#walk() recursively traverses all files and directories
import os
all_files=[]
path=os.getcwd()
list_files=os.walk(path)
for dirpath,dirnames,filenames in list_files:
for dir in dirnames:
all_files.append(os.path.join(dirpath,dir))
for name in filenames:
all_files.append(os.path.join(dirpath,name))
for file in all_files:
print(file)
#print(path)
#print(list(list_files))
Operation results:
C:\ANACONDA\python.exe C:/Users/Lenovo/PycharmProjects/mypro_io/test_os/my05.py C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\Movie C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\a.txt C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\my01.py C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\my02.py C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\my03.py C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\my04.py C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\my05.py C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\Movie\mainland C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\Movie\Japan C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\Movie\Hong Kong and Taiwan C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\Movie\Hong Kong and Taiwan\Zhou Xingchi C:\Users\Lenovo\PycharmProjects\mypro_io\test_os\Movie\Hong Kong and Taiwan\Zhou Xingchi\gongdu.mp4 Process finished with exit code 0
shutil module (copy and compression)
The shutil module is provided in the python standard library. It is mainly used to copy, move and delete files and folders; You can also compress and decompress files and folders.
The os module provides general operations on directories or files. As a supplement, the shutil module provides operations such as moving, copying, compressing and decompressing, which are not provided by these os modules.
[example] copy files
[example] copy folder contents recursively (using shutil module)
#Test the usage of shutil module: copy, compress
# Copy
import shutil
import zipfile
shutil.copyfile("1.txt","1_copy.txt") #Will 1 Txt copy to 1_copy.txt
shutil.copytree("movie/Hong Kong and Taiwan","film") #take"movie/Hong Kong and Taiwan"Copy next file to"film"Lower;#The movie directory can be copied normally only when it does not exist
shutil.copytree("movie/Hong Kong and Taiwan","film",ignore=shutil.ignore_patterns("*.txt","*.html")) #Filter out files with txt and html suffixes
[example] compress all contents of the folder (using the shutil module)
[example] decompress the compressed package to the specified folder (using the shutil module)
#Compress, decompress
shutil.make_archive("film/gg","zip","Movie/Hong Kong and Taiwan") #Compress the contents of the files in the Movie / Hong Kong TV folder to the "Movie" folder for production GG Zip file
#z1=zipfile.ZipFile("abc.zip","w")
#z1.write("1.txt")
#z1.write("1_copy.txt")
#z1.close()
#z2=zipfile.ZipFile("abc.zip","r")
#z2.extractall("film") #Set the address of decompression
#z2.close()
recursive algorithm
Recursion is a common way to solve problems, that is, to gradually simplify the problem. The basic idea of recursion is "call yourself". A method using recursion technology will call itself directly or indirectly.
Using recursion, we can solve some complex problems with simple programs. For example, the calculation of nuohan tower, Fibonacci, etc.
The recursive structure consists of two parts:
define recursive headers. Answer: when not to call its own method. If there is no head, it will fall into an endless loop, that is, the end condition of recursion.
recursive body. Answer: when do I need to call my own method.
[example 3-22] use recursion to find n!
#Use recursion to calculate the factorial of n (5! = 5 * 4 * 3 * 2 * 1)
def factorial(n):
if n==1:
return n
else:
return n*factorial(n-1)
print(factorial(5))
Operation results:
120

Recursive defect
A simple program is one of the advantages of recursion. Recursion takes up more memory than recursion.
[example] use recursive algorithm to traverse all files in the directory
#Recursively print all directories and files
import os
all_file=[]
def getALLFiles(path,level):
childFiles=os.listdir(path)
for file in childFiles:
filepath=os.path.join(path,file)
if os.path.isdir(filepath):
getALLFiles(filepath,level+1)
all_file.append("\t"*level+filepath)
getALLFiles("test_os",0)
for f in reversed(all_file):
print(f)
Operation results:
C:\ANACONDA\python.exe C:/Users/Lenovo/PycharmProjects/mypro_io/file14.py test_os\my05.py test_os\my04.py test_os\my03.py test_os\my02.py test_os\my01.py test_os\Movie test_os\Movie\Hong Kong and Taiwan test_os\Movie\Hong Kong and Taiwan\Zhou Xingchi test_os\Movie\Hong Kong and Taiwan\Zhou Xingchi\gongdu.mp4 test_os\Movie\Japan test_os\Movie\mainland test_os\a.txt Process finished with exit code 0
