I What are requests
Requests is written in python language based on urlib and uses the HTTP Library of Apache 2 licensed open source protocol. If you read the previous article about the use of urlib library, you will find that urlib is still very inconvenient, and requests is more convenient than urlib and can save us a lot of work. In a word, requests is the simplest and easy-to-use HTTP library implemented in python. It is recommended that crawlers use the requests library. After python is installed by default, the requests module is not installed and needs to be installed separately through pip.
II Installation of requests
The installation method is very simple. You can directly use the command to install, as follows:
pip install requests
III Detailed use of requests
Public method
response.json() # The response content is returned in the form of json, and the object format is dict response.content # The response content is returned in binary form, and the object format is bytes response.text # Return the response content in the form of string, and the object format is str response.url # Returns the url of the request response.status_code # Return the status code of this request response.reason # Return the reason corresponding to the status code response.headers # Return response header response.cookies # Return cookie information response.raw # Returns the original response body response.encoding # Return encoding format
Instance introduction
import requests #Guide Package
# Initiate a request to build an object for a get request
response = requests.get('https://www.baidu.com/')
print(response)
print("+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-Separator+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+")
# View the content of the response body
print(response.text)
# View response data types
print(type(response.text))
print("+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-Separator+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+")
# View status code
print(response.status_code)
The operation results are as follows:
<Response [200]>
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-Separator+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é"</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ–°é—»</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视é¢'</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产å"</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å
³äºŽç™¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç"¨ç™¾åº¦å‰å¿
读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æ„è§å馈</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
<class 'str'>
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-Separator+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
200
3.1 get based request
3.1.1 basic writing method
# Test website: http://httpbin.org/get
import requests
# Initiate a request to build an object for a get request
res = requests.get('http://httpbin.org/get')
# View response status
print(res.status_code)
# Print decoded return data
print(res.text)
The operation results are as follows:
200
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.24.0",
"X-Amzn-Trace-Id": "Root=1-60d2e34d-672cc3a72400338d60c8f83a"
},
"origin": "183.198.250.28",
"url": "http://httpbin.org/get"
}
3.1.2 get request with parameters
# Test website: http://httpbin.org/get
import requests
# Initiate a request to build an object for a get request
res = requests.get('http://httpbin. org/get? Name = Lisi & age = 18 & sex = man ') # pass? Splice in url
# View response status
print(res.status_code)
# Print decoded return data
print(res.text)
The operation results are as follows:
200
{
"args": {
"age": "18",
"name": "lisi",
"sex": "man"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.24.0",
"X-Amzn-Trace-Id": "Root=1-60d2e339-4078e867367372de6e4bf6d3"
},
"origin": "183.198.250.28",
"url": "http://httpbin.org/get?name=lisi&age=18&sex=man"
}
The above is the most direct way to write. The required parameters are spliced directly after the url. However, generally, in order to facilitate viewing and modification, we can also write the parameters into the user-defined dictionary. The parameters will be passed into params, as shown in the following example:
# Test website: http://httpbin.org/get
import requests
# Parameter dictionary
data = {
'name':'lisi',
'age':22,
'sex':'nan'
}
# Initiate a request to build an object for a get request
res = requests.get('http://httpbin.org/get',params = data) # pass the data parameter dictionary into the formal parameter params
# View response status
print(res.status_code)
# Print decoded return data
print(res.text)
The operation result is:
200
{
"args": {
"age": "22",
"name": "lisi",
"sex": "nan"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.24.0",
"X-Amzn-Trace-Id": "Root=1-60d2e5bc-3a364122315c713c245f05b7"
},
"origin": "183.198.250.28",
"url": "http://httpbin.org/get?name=lisi&age=22&sex=nan"
}
3.1.3 json parsing
import requests
import json
res = requests.get('http://httpbin.org/get')
# print(res.status_code)
print(res.text) #jason data looks like string data in a dictionary
print(type(res.text))
# . loads() string to dictionary type
print(json.loads(res.text))
print(type(json.loads(res.text))) #json is a dictionary type
a = json.loads(res.text)
print(a['url'])
# . json() get JSON data
print(res.json())
print(type(res.json()))
The operation results are as follows:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.24.0",
"X-Amzn-Trace-Id": "Root=1-60d2e740-59fd21b347e38265759e821f"
},
"origin": "183.198.250.28",
"url": "http://httpbin.org/get"
}
<class 'str'>
{'args': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.24.0', 'X-Amzn-Trace-Id': 'Root=1-60d2e740-59fd21b347e38265759e821f'}, 'origin': '183.198.250.28', 'url': 'http://httpbin.org/get'}
<class 'dict'>
http://httpbin.org/get
{'args': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.24.0', 'X-Amzn-Trace-Id': 'Root=1-60d2e740-59fd21b347e38265759e821f'}, 'origin': '183.198.250.28', 'url': 'http://httpbin.org/get'}
<class 'dict'>
3.1.4 obtaining binary data
# Target site - Baidu logo picture: https://www.baidu.com/img/baidu_jgylogo3.gif
import requests
url = 'https://www.baidu.com/img/baidu_jgylogo3.gif'
res = requests.get(url)
print(res.text)
# . content() get binary data
print(res.content) # 010101 bytes
print(type(res.content))
with open('baidu_logo.gif','wb') as f:
f.write(res.content)
f.close()
The operation results are as follows:
(�ɨ����t{���,w�|��vt)2�����!�,u&�x���0� J0ɻ�`�UV!L���l��P���V
�B�Z�aK�7|M�Ph
�%����n8FN&:@F��|V1~w�y��r� �9�khlO�j�!�s�\�m�&�\���AZ�PQ�~��yX��Rż�����WEz85�'���
������.�D�a����������,��L
vٱ#�U�a��mf=��*L���<03��]��x���\y��2���)�J�h��iHt��HK&���D�K��;��.��ғ��eK��܊�����n��BC[�Р `�.�����_�:&`S�� ����͚/m��Y��Ȗ� �a���~ִ��븱�0�����p�i��6��f��y\<�{�f�[t�ȨO'�S�A� �\L����`���m�T52D]P��U�a�}��H�=��~�Uxm�d���e�Z$�#r0!~*�W+�
b'GIF89au\x00&\x00\xa2\x00\x00\xe62/\xea\xd4\xe2Y`\xe8\x99\x9d\xf1\xefvt)2\xe1\xe1\x06\x02\xff\xff\xff!\xf9\x04\x00\x00\x00\x00\x00,\x00\x00\x00\x00u\x00&\x00\x00\x03\xffx\xba\xdc\xfe0\xb6 J\x190\x04\xc9\xbb\xff`\xc8UV!L\xa4\xb0\x89l\xeb\xbe\xcbP\x96\xeb\x11\xccV\r\xef|\x7f\xe0\x96\x93\x824\xc3\xf8\x8eH\xd0\r(\x94\x01\x0b\xc9\xa8\xf4\xb1\x04\x0e\x9f\x05\xddt{\xac\xe2\x14\xd8,w\x8c|\n\xb1B\xb2Z\xa4a\x10K\xc67|M\xf7Ph\n\xaf%\xf6\xd4\xd6\xffn8FN&:@F\x80\x89|V1~w\x85y\x03\x92\x8a\x7fr\x16\x88 \x849\x94khlO\x9cj\x9e!\x9as\xa1\\\xa3\x0c\x1am\x0e\x96&\xa7\\\xae\x98\x8fAZ\xaePQ\x04\xba~\x7f\xa5\x9byX\x98\xb7R\x06\xc5\xbc\xc5\xc8\xc9\x06\x00\x00\x04\xbc\x1f\x00\xc8WE\x0bz85\xae\'\xca\xdb\xdc\x06\n\xd1\xdd\xe1\xe0\xe1\xc8\x04.\xe3\x0bD\xc2a\xbf\xd9\x07\xe4\xe1\xdf\xf0\xdc\xe3\xf3\xe6,\xe8\x12\xbeL\n\xfb\x18\xcc\x00\x01&\x0b\x08P\x9e\xb7<\xacT\xb1\x1aH\xb0\x9e\x81g\x12t\xe9\xd2gj\x94\x9c4\x0e\x02 \x83\x08.\xffO1\x00\x13>*HF%\xd9\xbd$\x9a\x8c\x84i2@\x80\x00L\r\xc7\xc5\\\x00N\xe3\xbc\x8f$\x1f\x10(\x97\'&3g\x0c\xf29(\xa5r\xa5\x84\x9b9\x0f\xd4D\xba,i\x83q+l\x86;)4\x90 0\xec06`Z\x8cfW\x1b"U\x85M\xb6\xaa\xecNi\x1e\xe1\xad\xa8jC\x9d\x83\x0bX\xe1\xfex\xf5\x00m\x04\xbb\x1d\xc1.\x0b\xb9\xf7\x1d\xd2\x93\x11\xce\xf6eK\x84\x97\xdc\x8a\xb5\x1c\xd8\x85\x80\xf7\xab\xd4n\xf7\xfeBC[\x95\xd0\xa0 `\x8a\x1e.\xa1\xd5\xef\xc1\xbb_\x95:&\x07`\x05S\xc0\x11\xf2\t\xf5\xb2\xa1\xca\x19\xcd\x9a/m\xfd\xe8\x93Y\xe3\xcf\x1f\xc8\x96\xd5 \xf8a\xb5\xde\xdc\x0c~\xd6\xb4\x81\xd0\xeb\xb8\xb1\xf70\xe0\xfa\xb9\xa3\xc3p\x8f!\x08\x06i\xe3\xf96\xe1\xe9f\xb4\xe6\x9c\x19y\\<\x0b\x98{\xf5f\x9d[t\x9d\xc8\xa8O\'\x98S\xe8\x9bA\x15\x8e\x1f \x91\\L\xf8\xd0\x10\xf2\x8a\xf6\x16`\x1c\xd0\x00\x86\xd3m\xe0T52\x19D]P\x94\xd9U\x8aa\x9d}\xf7\xcbH\xf8=\xa0\x9f~\xbdUx\x1fm\xec\x99d\xa0\x16\xaa\xd9e\xcd\x00Z$\xd6\x00#\x17r0!~\x00*\x83\x1aW+\x00\xd7\rv\xd9\xb1#\xe3U\xcba\xe8\xd3mf=\xe7\xcc*L\xd5\xd0\xdf<0\x023\xe3\x90\xf6]\x88\xd4x\x8f\x95\xf3\\y\xe9\xed2\x81\x8b\xca\x04)\xe4J\xb7h\xa7\xd8iH\x0et\x12\x01\xf5\x1c\x98HK&\xbc\x04\xa2\x16\x01\xb4D\xc4K\x10\xad\x91\x00\x00;'
<class 'bytes'>
3.1.5 adding headers
# Target site - know: https://www.zhihu.com/explore
url = 'https://www.zhihu.com/explore'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'
}
# UA: identification of browser user identity, through headers
res = requests.get(url,headers = headers)
print(res.text)
The operation results are as follows:
<!doctype html> <html lang="zh" data-hairline="true" data-theme="light"><head><meta charSet="utf-8"/><title data-react-helmet="true">find - Know</title><meta name="viewport" content="width=device-width,initial-scale=1,maximum-scale=1"/><meta name="renderer" content="webkit"/><meta name="force-rendering" content="webkit"/><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"/><meta name="google-site-verification" content="FTeR0c8arOPKh8c5DYh_9uu98_zJbaWw53J-Sch9MTg"/><meta name="description" property="og:description" content="Zhihu, a high-quality Q & a community of Chinese Internet and an original content platform gathered by creators, was officially launched in January 2011 to「Let people better share knowledge, experience and opinions and find their own solutions」For the brand mission. With a serious, professional and friendly community atmosphere, unique product mechanism and structured and easily accessible high-quality content, Zhihu has gathered the most creative people in the fields of Chinese Internet technology, commerce, film and television, fashion and culture, and has become a comprehensive and comprehensive category The knowledge sharing community with key influence in many fields and the original content platform gathered by creators have established a community driven content realization business model."/><link data-react-helmet="true" rel="apple-touch-icon" href="https://static. zhihu. com/heifetz/assets/apple-touch-icon-152. a53ae37b. png"/><link data-react-helmet="true" rel="apple-touch-icon" href=" https://static.zhihu.com/heifetz/assets/apple-touch-icon-152.a53ae37b.png " sizes="152x152"/><link data-react-helmet="true" rel="apple-touch-icon" href=" https://static.zhihu.com/heifetz/assets/apple-touch-icon-120.bbce8f18.png " sizes="120x120"/><link data-react-helmet="true" rel="apple-touch-icon" href=" https://static.zhihu.com/heifetz/assets/apple-touch-icon-76.cbade8f9.png " sizes="76x76"/><link data-react-helmet="true" rel="apple-touch-icon" href=" https://static.zhihu.com/heifetz/assets/apple-touch-icon-60.8f6c52aa.png " sizes="60x60"/><link crossorigin="" rel="shortcut icon" type="image/x-icon" href=" https://static.zhihu.com/heifetz/favicon.ico "/><link crossorigin="" rel="search" type="application/opensearchdescription+xml" href=" https://static.zhihu.com/heifetz/search.xml "Title =" Zhihu "/ > < link rel =" DNS prefetch "href =" / / static zhimg. com"/><link rel="dns-prefetch" href="//pic1. zhimg. com"/><link rel="dns-prefetch" href="//pic2. zhimg. com"/><link rel="dns-prefetch" href="//pic3. zhimg. com"/><link rel="dns-prefetch" href="//pic4. zhimg. com"/><style> ...
3.2 post based request
# Test website: https://httpbin.org/post
import requests
url = 'https://httpbin.org/post'
data = {
'name':'lisi'
}
res = requests.post(url,data=data) # Most parameters are passed through data, and a few are json
print(res.text)
The operation results are as follows:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "lisi"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "9",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.24.0",
"X-Amzn-Trace-Id": "Root=1-60d2fbfb-7d98938c2ec01e2830ddf3fc"
},
"json": null,
"origin": "183.198.250.28",
"url": "https://httpbin.org/post"
}
IV Response response
4.1 response attribute
# Target website - short book: http://www.jianshu.com
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'
}
url = 'http://www.jianshu.com'
res = requests.get(url,headers=headers)
print(res.status_code)
if res.status_code == 200:
print("Request succeeded")
else:
print("request was aborted")
# print(res.text)
# View response header information
print(res.headers)
# Get server name by key name
print(res.headers['Server'])
print(res.url)
# Check whether the web page has been redirected
print(res.history) #a jump b
The operation results are as follows:
200
Request succeeded
{'Server': 'Tengine', 'Date': 'Thu, 24 Jun 2021 05:13:23 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Vary': 'Accept-Encoding', 'X-Frame-Options': 'SAMEORIGIN', 'X-XSS-Protection': '1; mode=block', 'X-Content-Type-Options': 'nosniff', 'ETag': 'W/"e77a5901d75feed6c49e2940cf452958"', 'Cache-Control': 'max-age=0, private, must-revalidate', 'Set-Cookie': 'locale=zh-CN; path=/', 'X-Request-Id': '57070148-e17b-4ba5-b91e-f30453a986de', 'X-Runtime': '0.004672', 'Strict-Transport-Security': 'max-age=31536000; includeSubDomains; preload', 'Content-Encoding': 'gzip'}
Tengine
https://www.jianshu.com/
[<Response [301]>]
4.2 status code judgment (understand)
The status code beginning with 2 (request successful) indicates that the request was successfully processed.
The 200 (successful) server has successfully processed the request. Typically, this means that the server has provided the requested web page.
201 (created) the request succeeded and the server created a new resource.
202 (accepted) the server has accepted the request but has not yet processed it.
203 (unauthorized information) the server has successfully processed the request, but the information returned may come from another source.
204 (no content) the server successfully processed the request, but did not return any content.
205 (reset content) the server successfully processed the request, but did not return any content.
206 (partial content) the server successfully processed some GET requests.
The beginning of 3 (the request is redirected) indicates that further operations are required to complete the request. Typically, these status codes are used for redirection.
300 (multiple choices) the server can perform a variety of operations for requests. The server can select an operation according to the user agent or provide a list of operations for the requester to select.
301 (permanent move) the requested web page has been permanently moved to a new location. When the server returns this response (a response to a GET or HEAD request), it automatically moves the requester to a new location.
302 (Temporary Mobile) server currently responds to requests from web pages in different locations, but the requester should continue to use the original location for future requests.
303 (view other locations) the server returns this code when the requester should use a separate GET request for different locations to retrieve the response.
304 (unmodified) the requested web page has not been modified since the last request. When the server returns this response, the web page content will not be returned.
305 (use proxy) the requester can only use the proxy to access the requested web page. If the server returns this response, it also indicates that the requester should use a proxy.
307 (temporary redirection) the server currently responds to requests from web pages in different locations, but the requester should continue to use the original location for future requests.
4 (request error) these status codes indicate that the request may be wrong and hinder the processing of the server.
400 (bad request) the server does not understand the syntax of the request.
401 (unauthorized) request requires authentication. The server may return this response for web pages that require login.
403 (Forbidden) the server refused the request.
404 (not found) the server could not find the requested page.
405 (method disable) disables the method specified in the request.
406 (not accepted) unable to respond to the requested web page with the requested content feature.
407 (proxy authorization required) this status code is similar to 401 (unauthorized), but the designated requester should authorize the use of the proxy.
408 (request timeout) a timeout occurred while the server was waiting for a request.
409 (conflict) the server encountered a conflict while completing the request. The server must include information about the conflict in the response.
410 (deleted) if the requested resource has been permanently deleted, the server will return this response.
411 (valid length required) the server does not accept requests without a valid content length header field.
412 (preconditions not met) the server does not meet one of the preconditions set by the requester in the request.
413 (request entity is too large) the server cannot process the request because the request entity is too large to handle the server.
414 (the requested URI is too long) the requested URI (usually the web address) is too long for the server to process.
415 (unsupported media type) the requested format is not supported by the requested page.
416 (the requested range does not meet the requirements) if the page cannot provide the requested range, the server will return this status code.
417 (expectation not met) the server did not meet the requirements of the "expectation" request header field.
5 (server error) these status codes indicate that the server encountered an internal error while trying to process the request. These errors may be the server itself, not the request.
500 (server internal error) the server encountered an error and was unable to complete the request.
501 (not yet implemented) the server does not have the function to complete the request. For example, this code may be returned when the server does not recognize the requested method.
502 (error gateway) the server, as a gateway or proxy, received an invalid response from the upstream server.
503 (service unavailable) the server is currently unavailable (due to overload or shutdown maintenance). Usually, this is only temporary.
504 (Gateway timeout) the server acts as a gateway or proxy, but does not receive a request from the upstream server in time.
505 (HTTP version not supported) the server does not support the HTTP protocol version used in the request.
V Advanced operations
5.1 file upload
# Test website: https://httpbin.org/post
import requests
url = 'https://httpbin.org/post'
# Application scenario: you need to upload files to access the data of subsequent pages
data={'files':open('baidu_logo.gif','rb')} # Construct file data
res = requests.post(url,files=data) # Most parameters are passed through data, and a few are json
print(res.text)
The operation results are as follows:
{
"args": {},
"data": "",
"files": {
"files": "data:application/octet-stream;base64,R0lGODlhdQAmAKIAAOYyL+rU4llg6Jmd8e92dCky4eEGAv///yH5BAAAAAAALAAAAAB1ACYAAAP/eLrc/jC2IEoZMATJu/9gyFVWIUyksIls677LUJbrEcxWDe98f+CWk4I0w/iOSNANKJQBC8mo9LEEDp8F3XR7rOIU2Cx3jHwKsUKyWqRhEEvGN3xN91BoCq8l9tTW/244Rk4mOkBGgIl8VjF+d4V5A5KKf3IWiCCEOZRraGxPnGqeIZpzoVyjDBptDpYmp1yumI9BWq5QUQS6fn+lm3lYmLdSBsW8xcjJBgAABLwfAMhXRQt6ODWuJ8rb3AYK0d3h4OHIBC7jC0TCYb/ZB+Th3/Dc4/PmLOgSvkwK+xjMAAEmCwhQnrc8rFSxGkiwnoFnEnTp0mdqlJw0DgIggwgu/08xABM+KkhGJdm9JJqMhGkyQIAATA3HxVwATuO8jyQfECiXJyYzZwzyOSilcqWEmzkP1ES6LGmDcStshjspNJAgMOwwNmBajGZXGyJVhU22quxOaR7hrahqQ52DC1jh/nj1AG0Eux3BLgu59x3SkxHO9mVLhJfcirUc2IWA96vUbvf+QkNbldCgIGCKHi6h1e/Bu1+VOiYHYAVTwBHyCfWyocoZzZovbf3ok1njzx/IltUg+GG13twMfta0gdDruLH3MOD6uaPDcI8hCAZp4/k24elmtOacGXlcPAuYe/VmnVt0ncioTyeYU+ibQRWOHyCRXEz40BDyivYWYBzQAIbTbeBUNTIZRF1QlNlVimGdfffLSPg9oJ9+vVV4H23smWSgFqrZZc0AWiTWACMXcjAhfgAqgxpXKwDXDXbZsSPjVcth6NNtZj3nzCpM1dDfPDACM+OQ9l2I1HiPlfNceentMoGLygQp5Eq3aKfYaUgOdBIB9RyYSEsmvASiFgG0RMRLEK2RAAA7"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "856",
"Content-Type": "multipart/form-data; boundary=0897caac667c3ccdc85cda38e69475c4",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.24.0",
"X-Amzn-Trace-Id": "Root=1-60d307c2-7ebdd32b1f9d050b5e0f3d0f"
},
"json": null,
"origin": "183.198.250.28",
"url": "https://httpbin.org/post"
}
5.2 obtaining cookies
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'
}
url = 'http://www.jianshu.com'
res = requests.get(url,headers=headers)
print(res.cookies) # Cookie object
# items() gets the key and value in the cookie object
for key,value in res.cookies.items():
print(key,value)
print(key+'='+value)
The operation results are as follows:
<RequestsCookieJar[<Cookie locale=zh-CN for www.jianshu.com/>]> locale zh-CN locale=zh-CN
5.3 session maintenance
# Stateless protocol has no memory function for the processing of things
# Establishing a session object allows you to maintain certain parameters across requests
import requests
# The first is to maintain the session through cookie s
headers = {
'Cookie': 'BIDUPSID=8E1608C3F35CB14077C7A5DC04472502; PSTM=1610880123; BD_UPN=12314753; BAIDUID=E164473C4067938C0BCAE150D5EE8742:FG=1; BDUSS=TB0dWpBaXMteFF5S0ExaW9OQ2Y3VkpheVFmbUx2LTlDN3V4SXFvaVFtWFMyNEJnRVFBQUFBJCQAAAAAAAAAAAEAAACoM47OYXNkNDQ2MDE5MDcyAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANJOWWDSTllgd; BDUSS_BFESS=TB0dWpBaXMteFF5S0ExaW9OQ2Y3VkpheVFmbUx2LTlDN3V4SXFvaVFtWFMyNEJnRVFBQUFBJCQAAAAAAAAAAAEAAACoM47OYXNkNDQ2MDE5MDcyAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANJOWWDSTllgd; __yjs_duid=1_4a1719cc524d052c435a309b1d6cd64a1619166605122; BAIDUID_BFESS=E164473C4067938C0BCAE150D5EE8742:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; COOKIE_SESSION=654_0_7_5_16_10_1_1_4_3_0_5_653_0_1_0_1624352530_0_1624352531%7C9%23249629_57_1617417915%7C9; BD_HOME=1; delPer=0; BD_CK_SAM=1; PSINO=1; H_PS_PSSID=33801_33968_31253_33848_34112_33607_34107_34135_26350'
}
res = requests.get('https://www.baidu.com/')
print(res.text)
The operation results are as follows:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é"</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ–°é—»</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视é¢'</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产å"</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å
³äºŽç™¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç"¨ç™¾åº¦å‰å¿
读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æ„è§å馈</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
# Session maintain session
# The server does not know that the two requests received are from the same user. Session maintenance is to let the server know
import requests
# Create a session object
s = requests.session()
res=s.get('https://www.baidu.com/')
print(res.text)
The operation results are as follows:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é"</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ–°é—»</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视é¢'</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产å"</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å
³äºŽç™¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç"¨ç™¾åº¦å‰å¿
读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æ„è§å馈</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
5.4 certificate verification
# Target site: https://www.12306.cn
import requests
from requests.packages import urllib3
urllib3.disable_warnings() # Eliminate warning messages
res = requests.get('https://www.12306.cn',verify=False)
print(res.status_code)
The operation results are as follows:
200
5.5 proxy settings
5.5.1 why use agents
Make the server think that the same client is not requesting
Prevent our real address from being leaked and investigated
5.5.2 understand the process of using agents
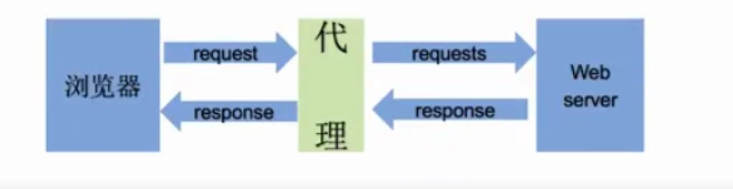
1. The browser sends a request to the agent > > > > 2 The agent receives the request and forwards the request > > > > 3 The server receives the request and returns a response to the agent > > > > 4 When the agent forwards the response to the browser, the agent acts as an intermediary
5.5.3 understand the difference between forward proxy and reverse proxy
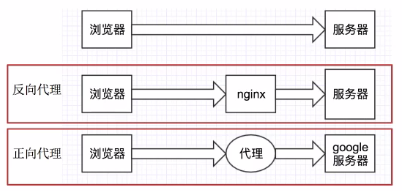
As can be seen from the above figure:
Forward proxy: the browser knows the real address of the server, such as VPN (virtual private network)
Reverse proxy: the browser does not know the real address of the server, such as nginx (a high-performance HTTP and reverse proxy web server)
- In terms of purpose
- Forward proxy - for LAN clients to access Internet services externally, you can use the buffering feature to reduce network utilization.
- Reverse proxy - provides Internet services for LAN servers. It can use load balancing to improve customer access. It can also control the service quality based on advanced URL policy and management technology.
- In terms of security
- Forward proxy - security measures must be taken to ensure that intranet clients access external websites through it and hide the identity of clients.
- Reverse proxy - providing external services is transparent. The client does not know that he is accessing a proxy and hides the identity of the server.
5.5.4 use of agents
import requests
# Select different agents according to the protocol type
proxies = {
"http": "http://12.34.56.79:9527",
"https": "http://12.34.56.79:9527",
}
response = requests.get("http://www.baidu.com", proxies = proxies)
print response.text
5.5.5 proxy IP Classification
According to the configuration of the proxy server, when sending a request to the target address, remote_ ADDR,HTTP_ VIA,HTTP_ X_ FORWARDED_ The three variables of for are different and can be divided into the following four categories:
Transparent proxy:
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Your IP
Although the transparent proxy can directly hide your IP address, it can still be accessed from HTTP_X_FORWARDED_FOR to find out who you are
Anonymous proxy:
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Proxy IP
Anonymous proxy is a little better than transparent proxy. Others can only know you used the proxy, but can't know who you are
Confusion agent:
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Random IP address
As mentioned above, it is the same as anonymous proxy. If a confused proxy is used, others can still know that you are using the proxy, but you will get a fake IP address, which is more realistic
High potential agent:
REMOTE_ADDR = Proxy IP HTTP_VIA = not determined HTTP_X_FORWARDED_FOR = not determined
It can be seen that the high hidden agent makes it impossible for others to find that you are using the agent, so it is a better choice
From the protocol used: the proxy can be divided into http proxy, https proxy, socket proxy, etc. it needs to be selected according to the protocol of the website
5.5.6 precautions for using proxy IP
Reverse climbing:
Using proxy IP is a necessary anti crawling method, but even if proxy IP is used, the other server still has many ways to detect whether we are a crawler
Update of proxy IP pool:
Many times, 90% of the free proxy IP on the network may not be able to be used normally. At this time, we need to detect what can be used and what can not be used through the program. One is to buy the proxy
Build your own IP proxy server
Assemble your own proxy IP pool
5.6 timeout setting
# Target site: http://www.baidu.com
import requests
res = requests.get('https://www.taobao.com',timeout=0.01) # in seconds
print(res.status_code)
5.7 exception handling
# Target site: http://www.baidu.com
import requests
try: # Handling exceptions
res = requests.get('https://www.taobao.com',timeout=0.0001) # in seconds
print(res.status_code)
except: #Code to handle exception execution
print("overtime")
The operation results are as follows:
overtime
5.8 certification settings
# https://static3.scrape.cuiqingcai.com
imports requests
from requests.auth import HTTPBasicAuth
res = requests.get('https://static3.scrape.cuiqingcai.com',auth=HTTPBasicAuth('user','123456'))
print(res.status_codetus_code)
# The second way to write
res = requests.get('https://static3.scrape.cuiqingcai.com',auth=('user','123456'))
print(res.status_codetus_code)