1, Foreword
The CET-4 and CET-6 exam, which is held twice a year, has come to an end. This exam has a strong sense of experience, and the backhand is a "five-star praise"

Starlight is not bad for passers-by, and time is not bad for those who want to pass CET-4 or CET-6 easily. Also have to be down-to-earth, step by step, and make sufficient preparation for review. I wish everyone, whether in the final exam or CET-4 or CET-6, can achieve ideal results, and then go home for a good year~~
This paper uses Python's fuzzy matching method to brush CET6 paragraph matching, which takes only 3 seconds! Python's FuzzyWuzzy library is an easy-to-use and powerful fuzzy string matching toolkit. It calculates the difference between two sequences according to Levenshtein Distance Algorithm. Levenshtein Distance Algorithm, also known as Edit Distance algorithm, refers to the minimum number of editing operations required to convert one string to another between two strings. Permitted editing operations include replacing one character with another, inserting a character, and deleting a character. Generally speaking, the smaller the editing distance, the greater the similarity between the two strings.
Github portal: https://github.com/seatgeek/fuzzywuzzy
The following programming is in the Jupiter notebook. Install the FuzzyWuzzy library as follows:
pip install fuzzywuzzy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
Original link: https://yetingyun.blog.csdn.net/article/details/122022033
Reprint is prohibited without the permission of the author, let alone for other purposes. Violators will be prosecuted.
2, Fuzzy module
Import method: if you directly import this module, the system will prompt UserWarning, which does not mean an error. The program can still run (the default algorithm is used, and the execution speed is slow). You can install the python Levenshtein library for assistance according to the system prompt, which is conducive to improving the calculation speed.
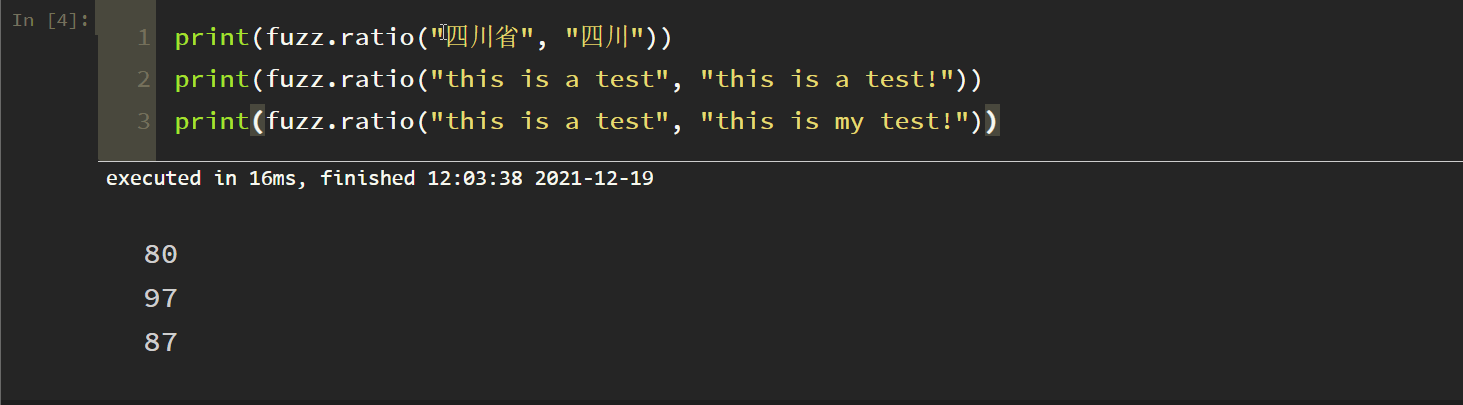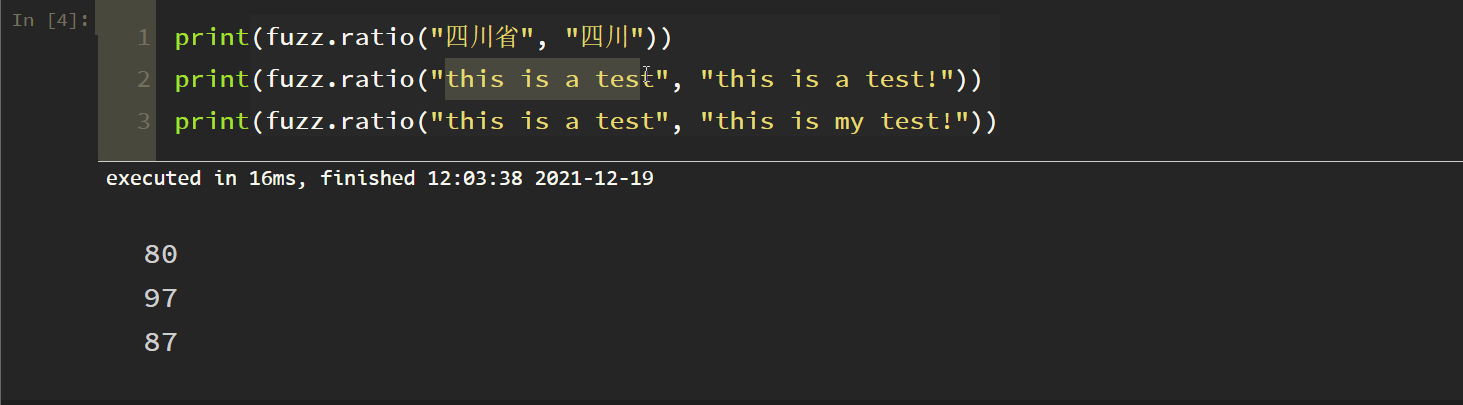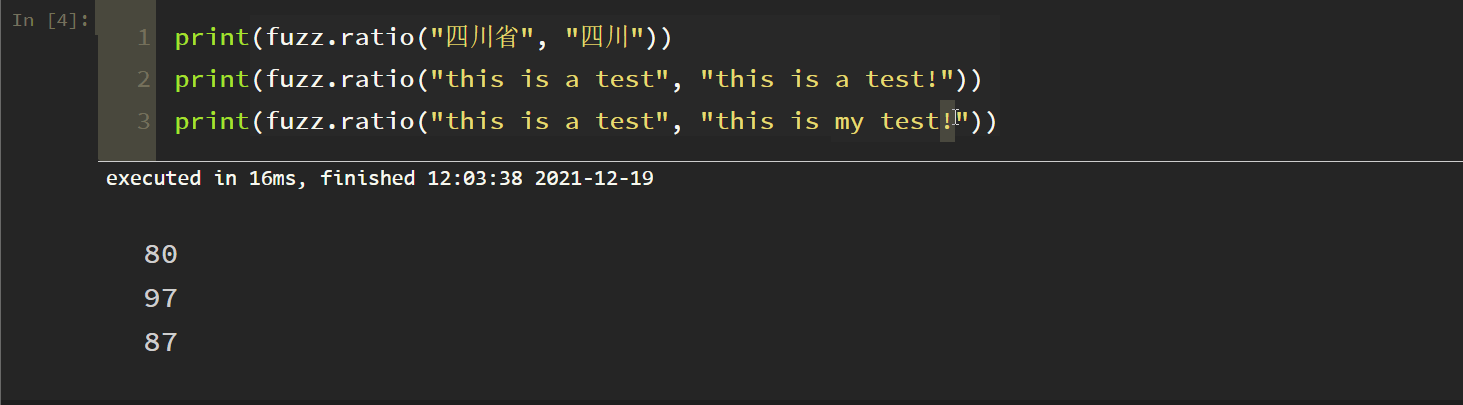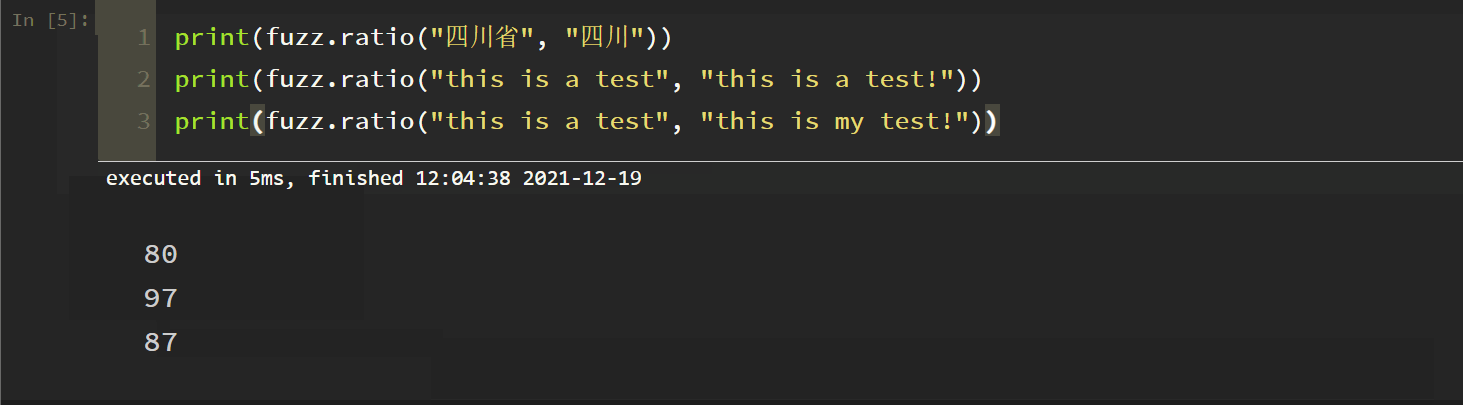
1. Simple matching
In fact, this is not very accurate and not commonly used. The tests are as follows:
2. Partial Ratio
Try to use partial matching with high accuracy! The tests are as follows:
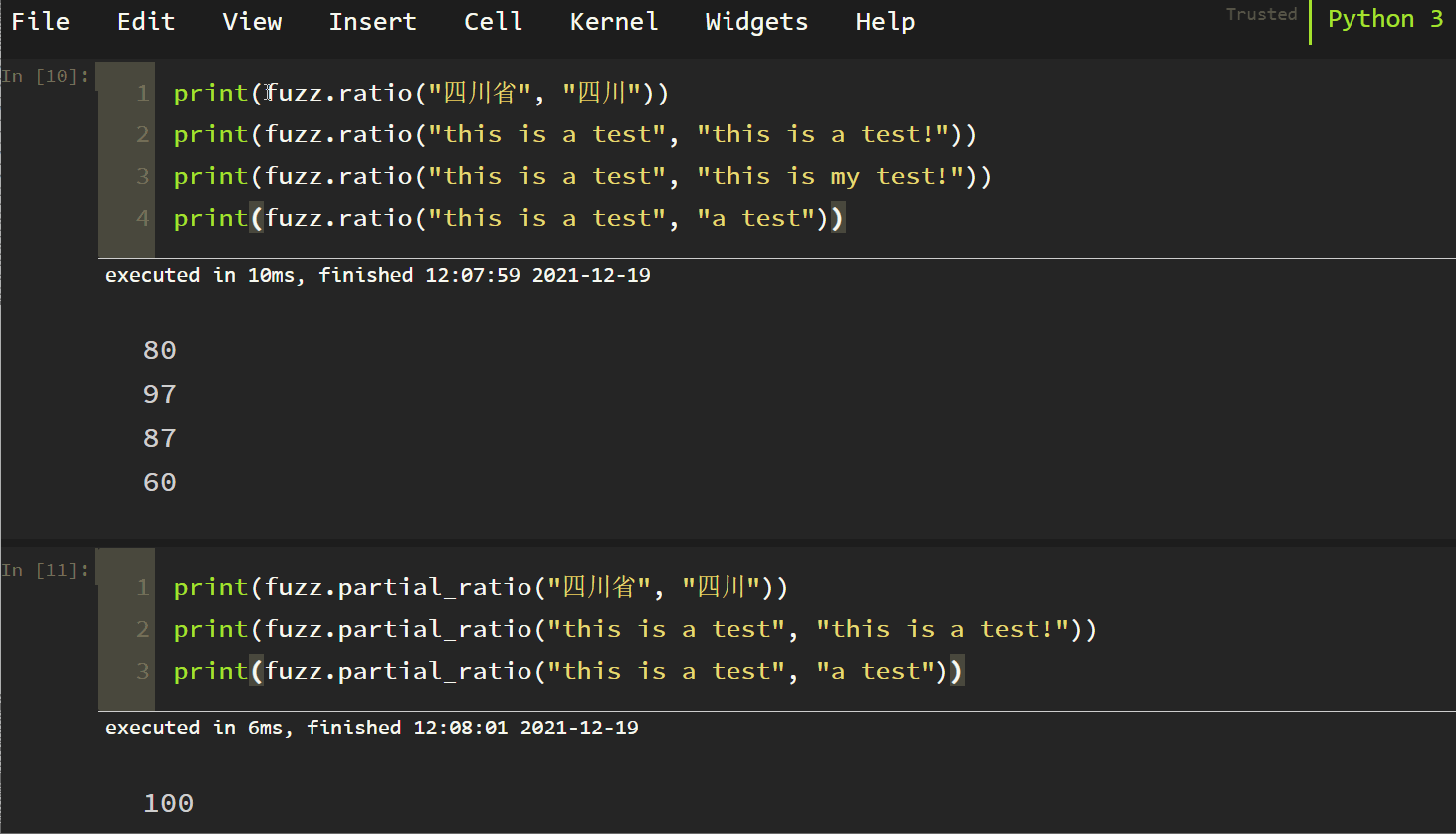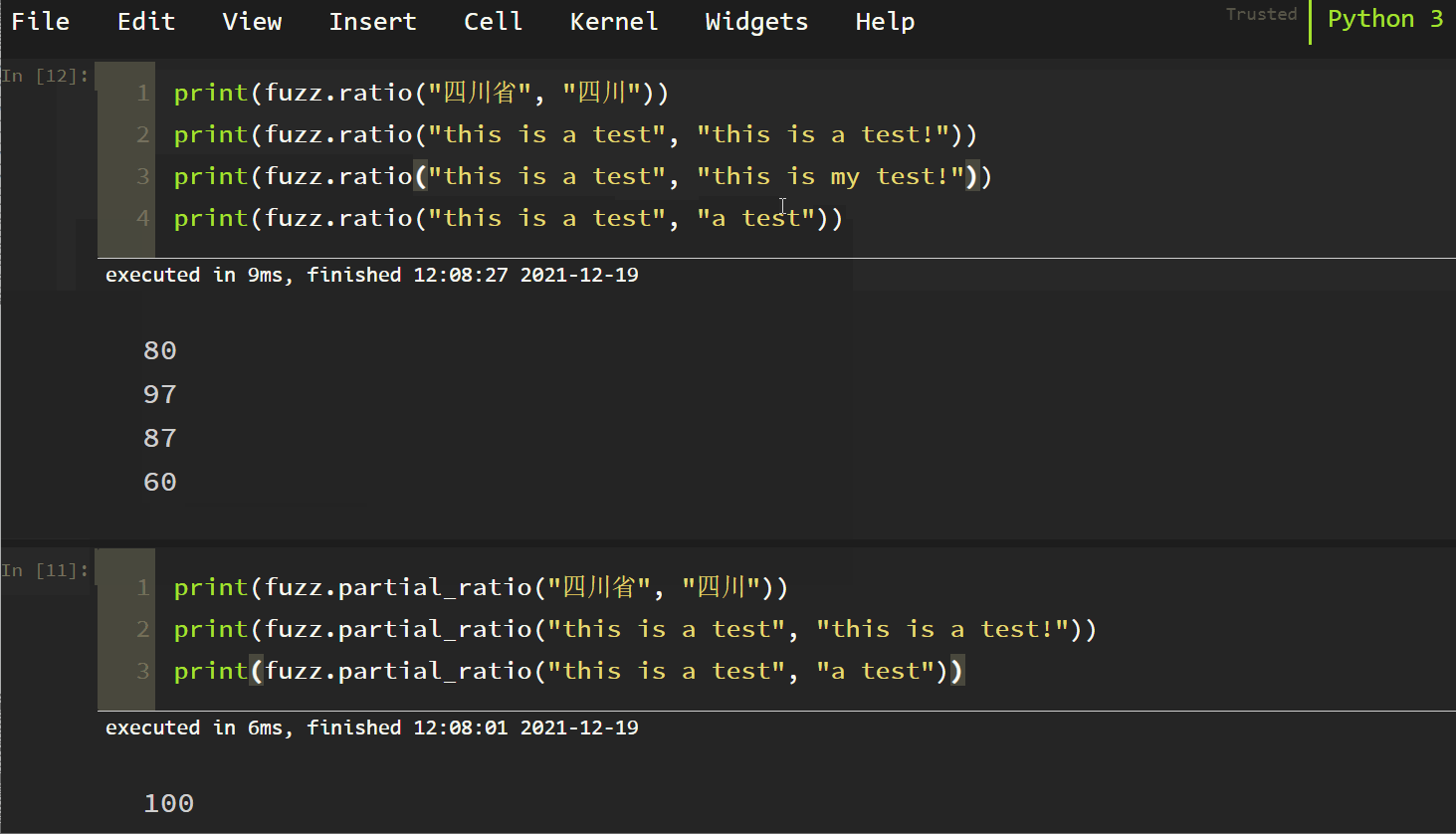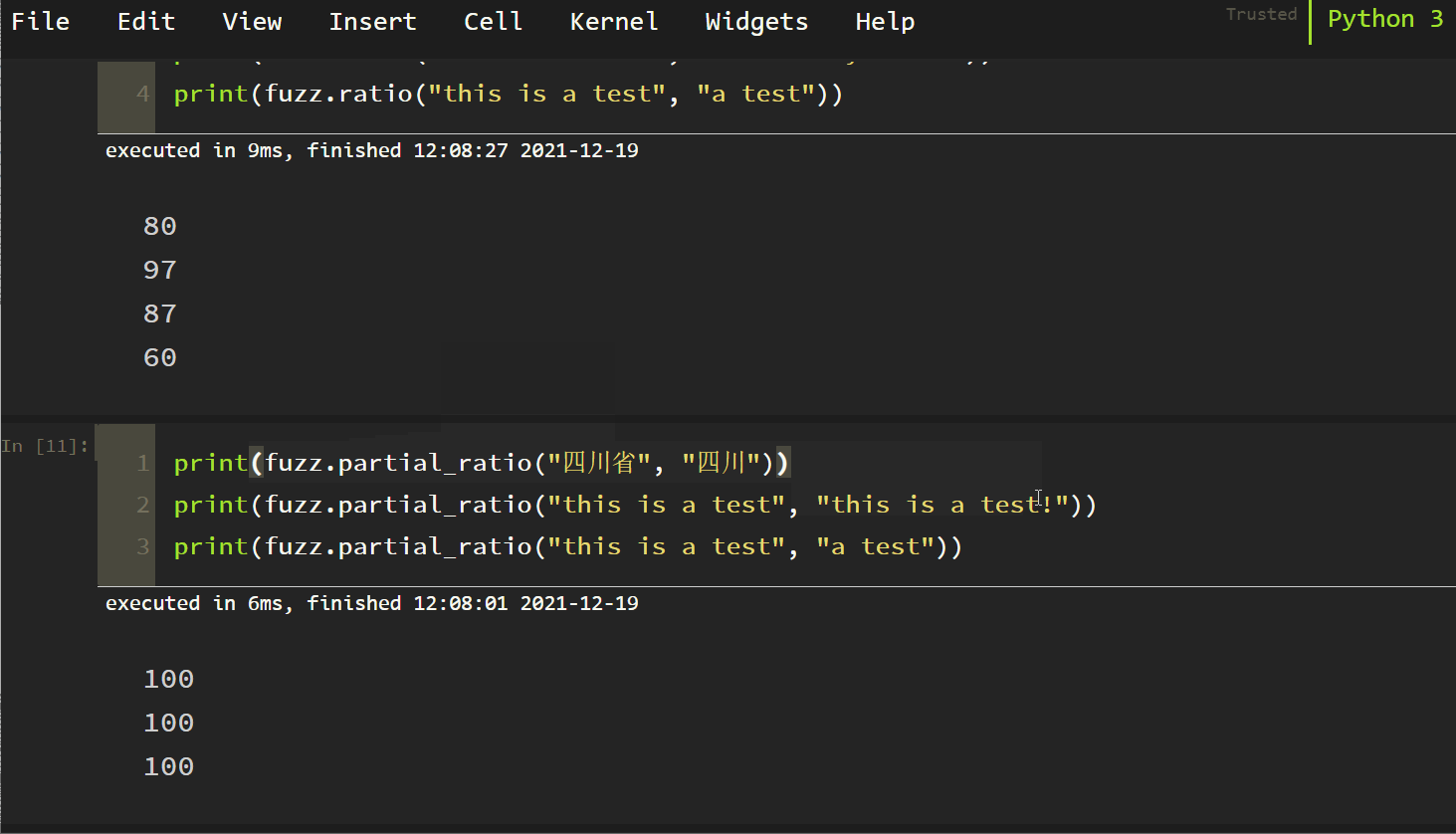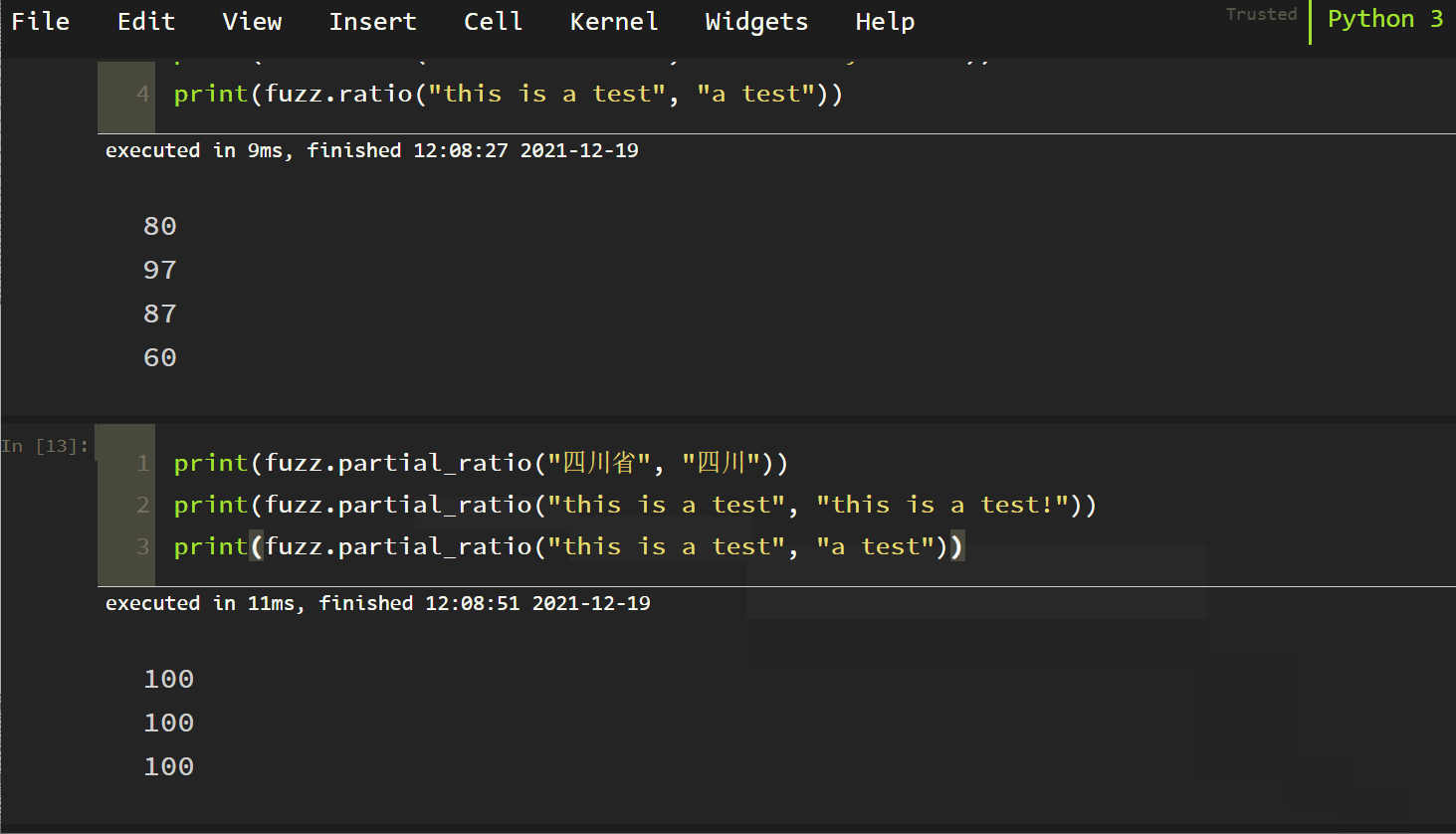
It can be found that fuzzy partial_ Ratio (S1, S2) partially matches. If S2 is a substring of S1, it still returns 100
3. Ignore the Token Sort Ratio
Principle: take the space as the separator, lowercase all letters, and ignore other punctuation marks in the space. The test is as follows:
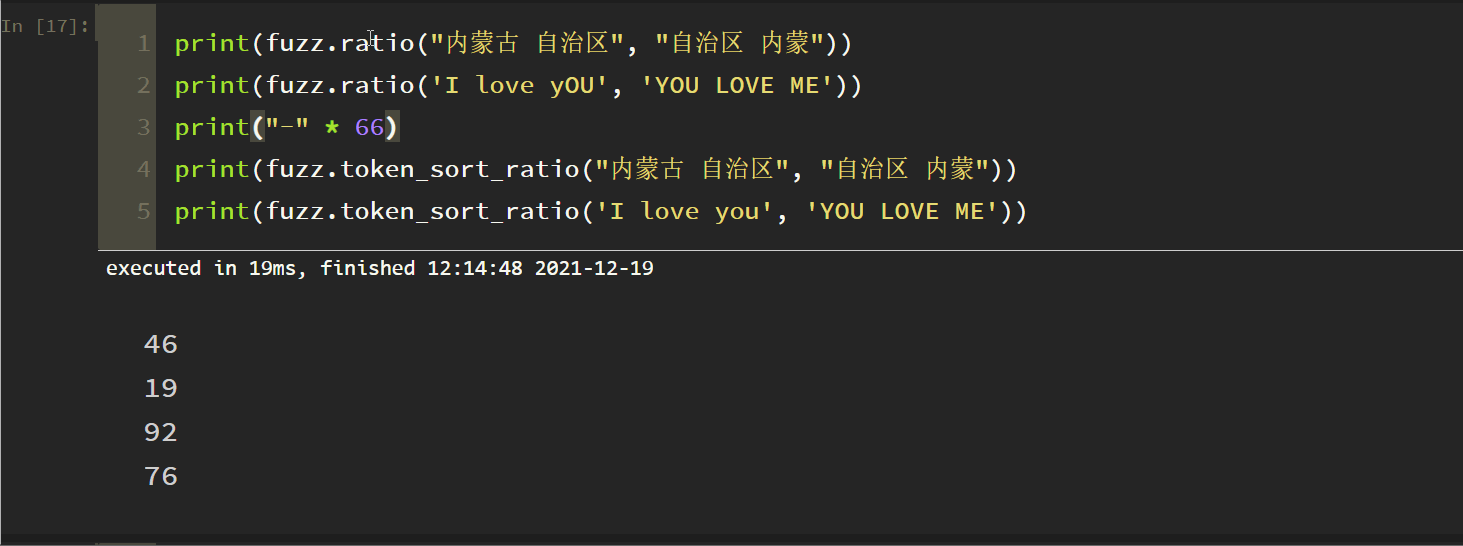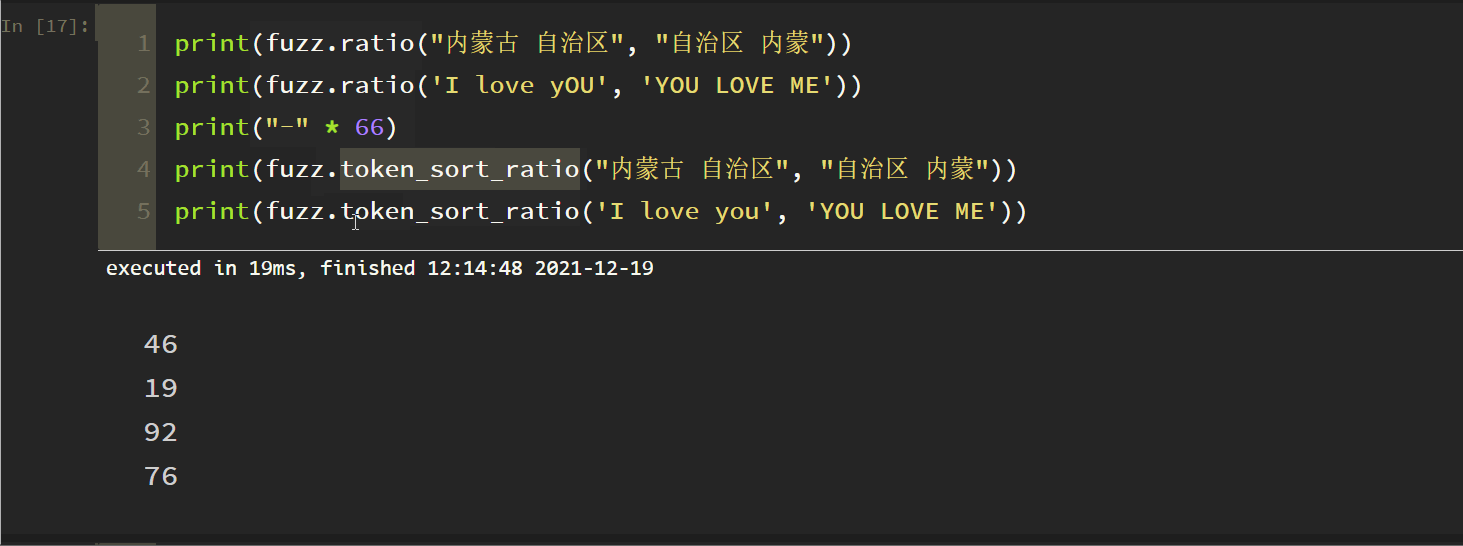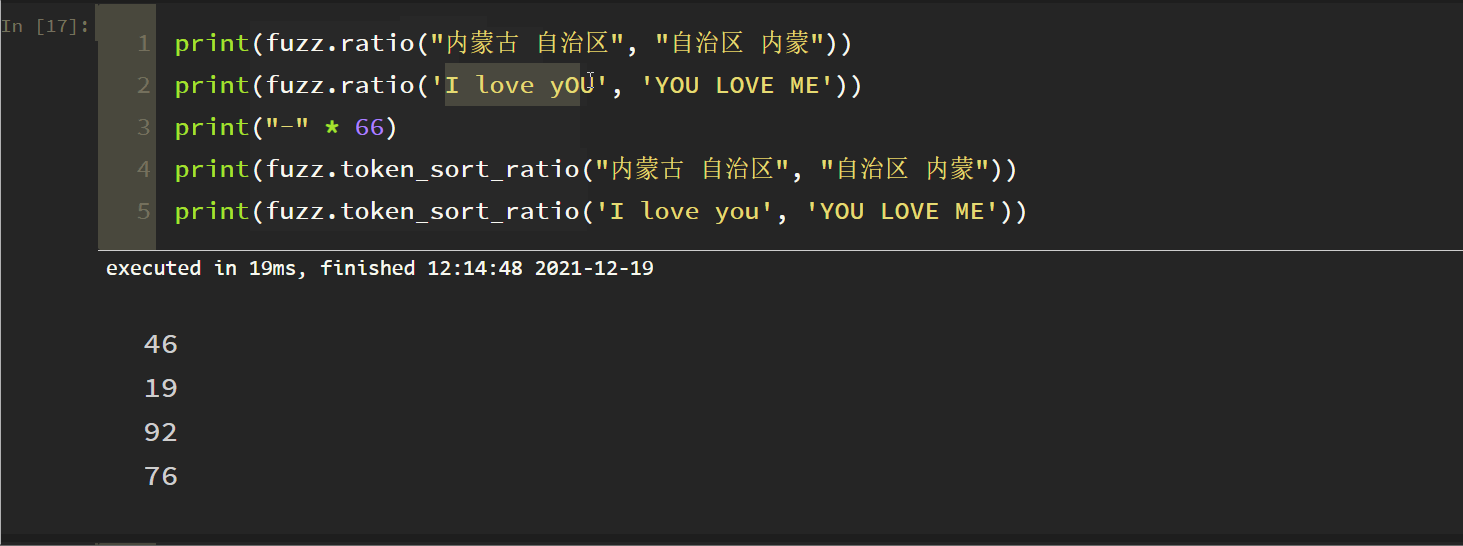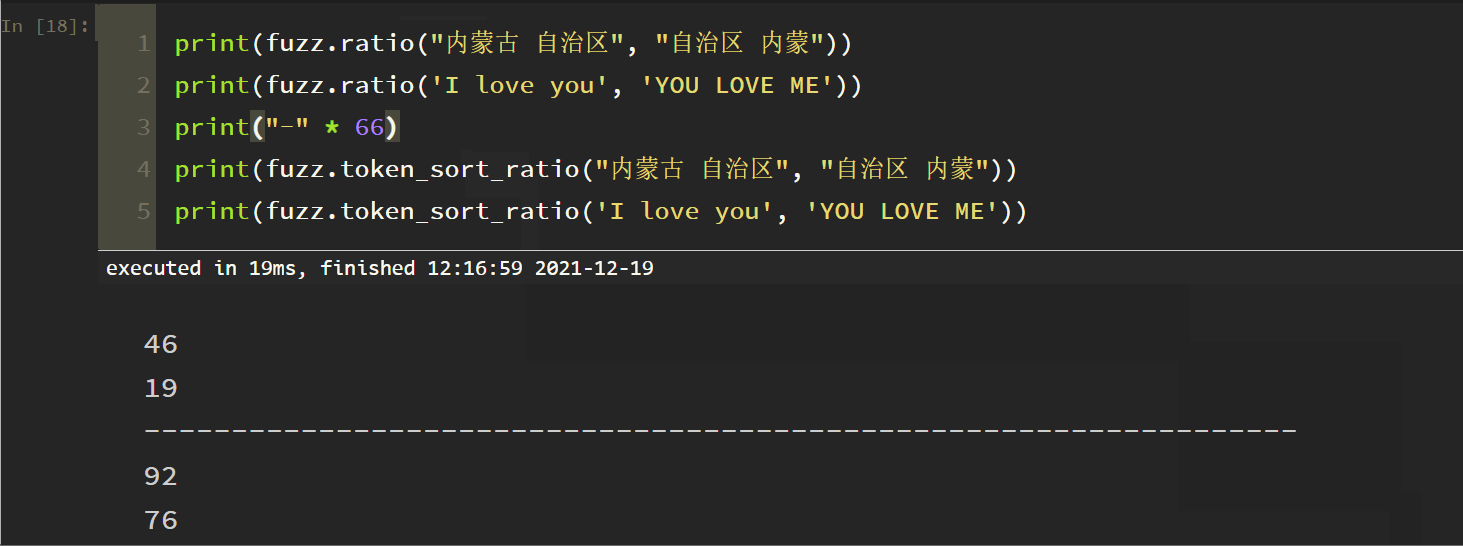
fuzz.token_sort_ratio (S1, S2) compares whether S1 and S2 words are the same, regardless of the order between words.
4. Token Set Ratio
This is equivalent to a set de duplication process before comparison. Note the last two. It can be understood that this method is in token_ sort_ The set de duplication function is added based on the ratio method. The following three matches are in reverse order.
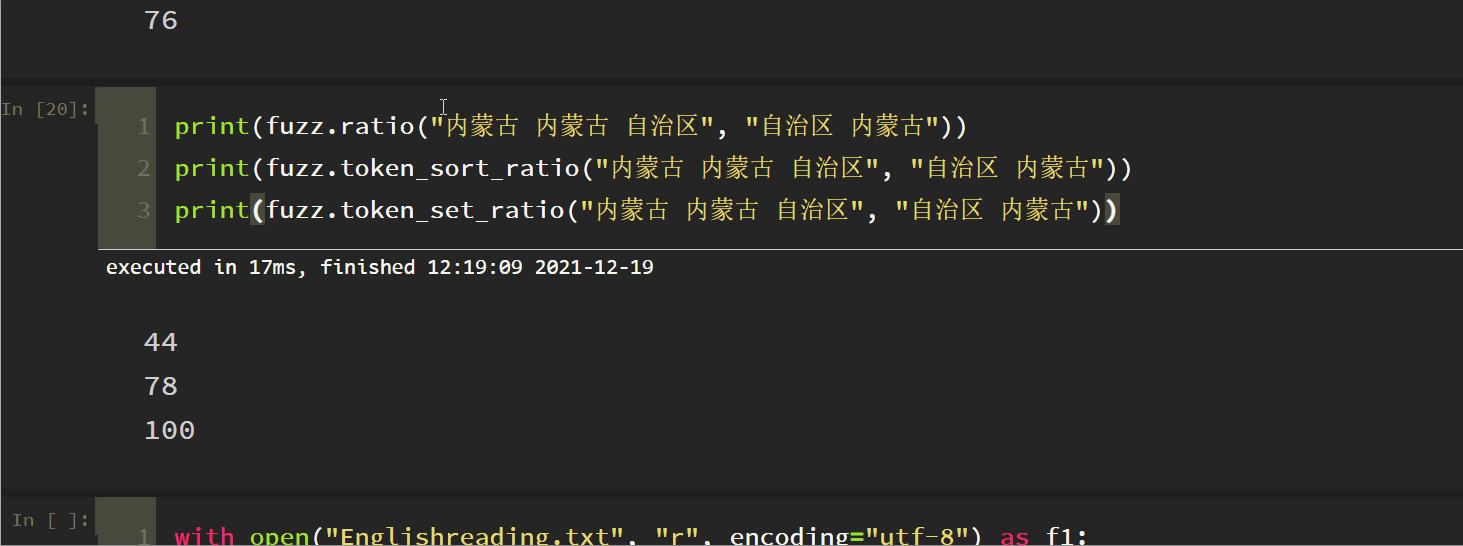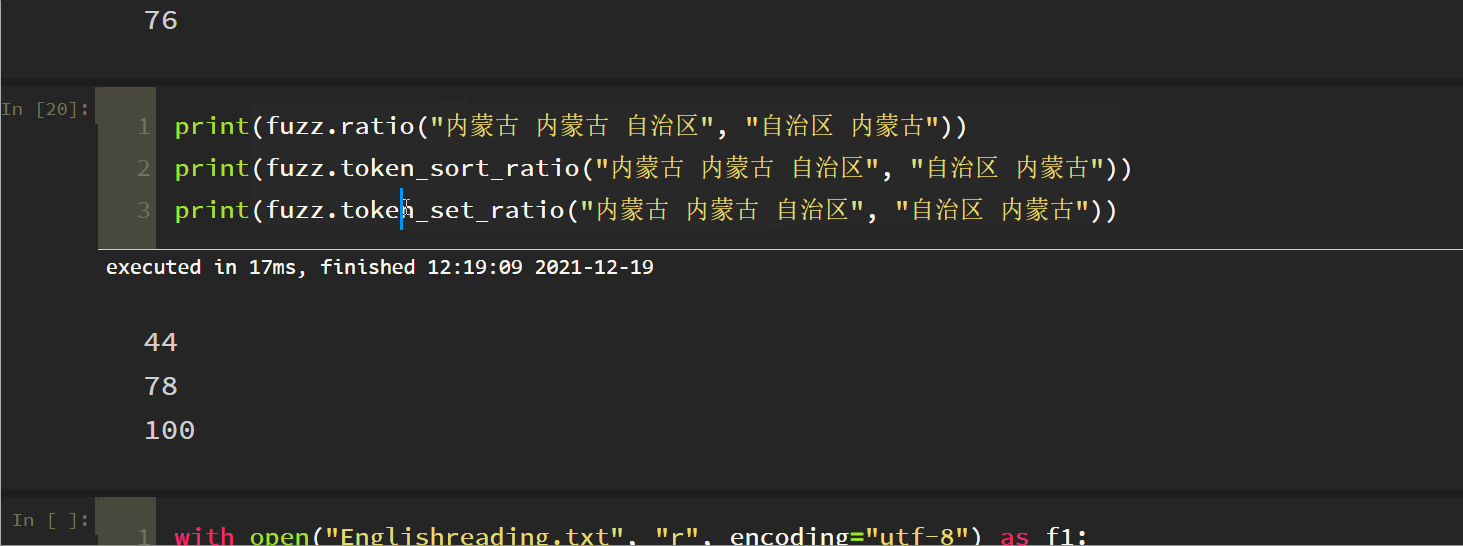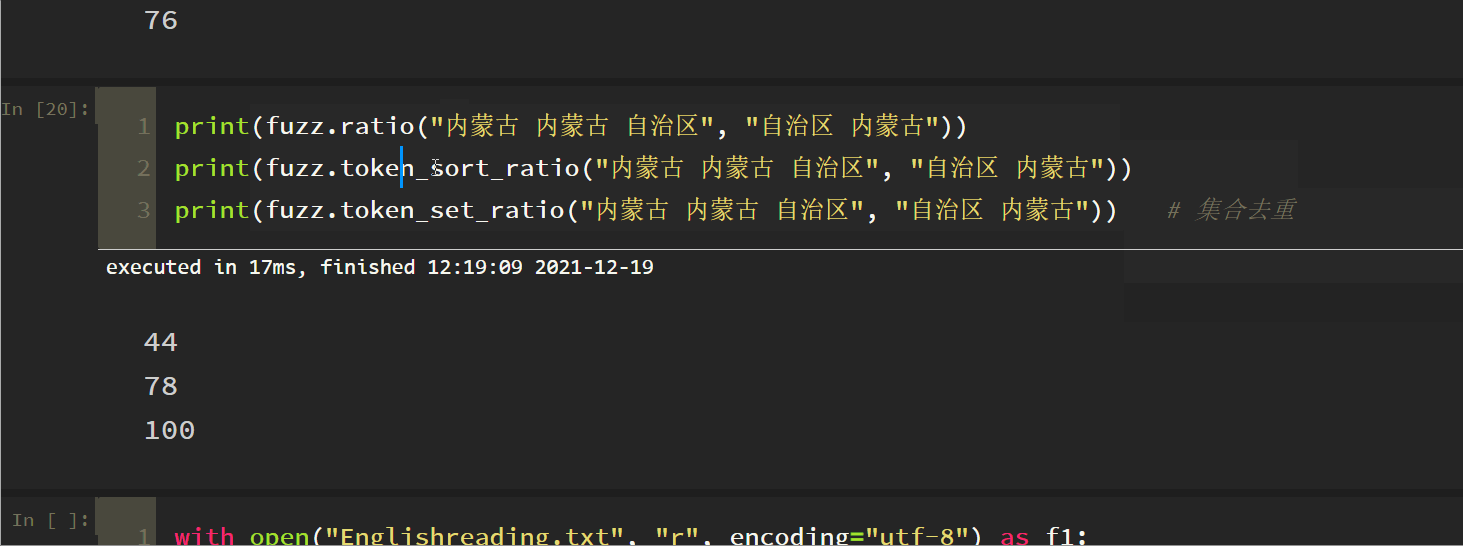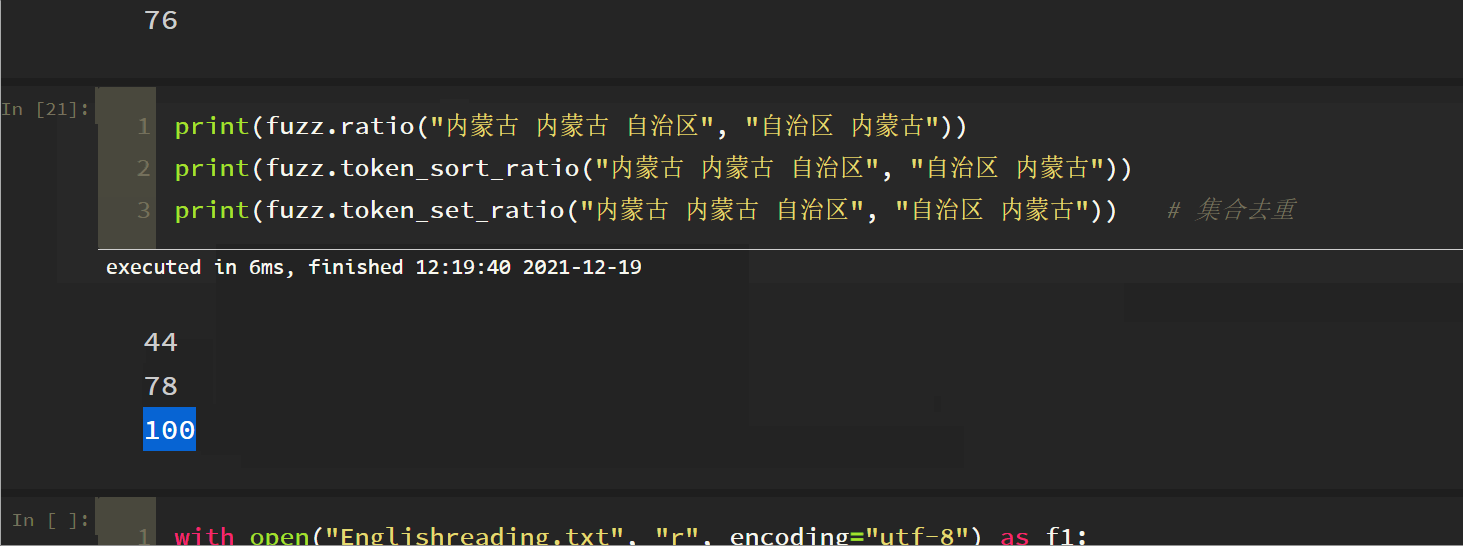
The final results of these ratio functions of fuzz y are matching values. If you need to obtain the string results with the highest matching degree, you still need to select different functions according to your own data type, and then extract the results. If you look at the matching degree of text data, it can be quantified in this way, However, it is not very convenient for us to extract the matching results, so there is a process module.
3, process module
It is used to deal with the case of limited alternative answers and return the fuzzy matching string and similarity. The tests are as follows:

4, Practice
Practice, of course, is to use the fuzz y module to brush CET-6 paragraph matching and see how the result is!!
You can find a website to download the PDF of level 6 real questions: https://pan.uvooc.com/Learn/CET/
Its PDF can't be edited directly. It seems to be scanned. Here, we use Adobe Acrobat Pro DC to identify, copy and paste the reading materials and the options to be matched directly into txt.
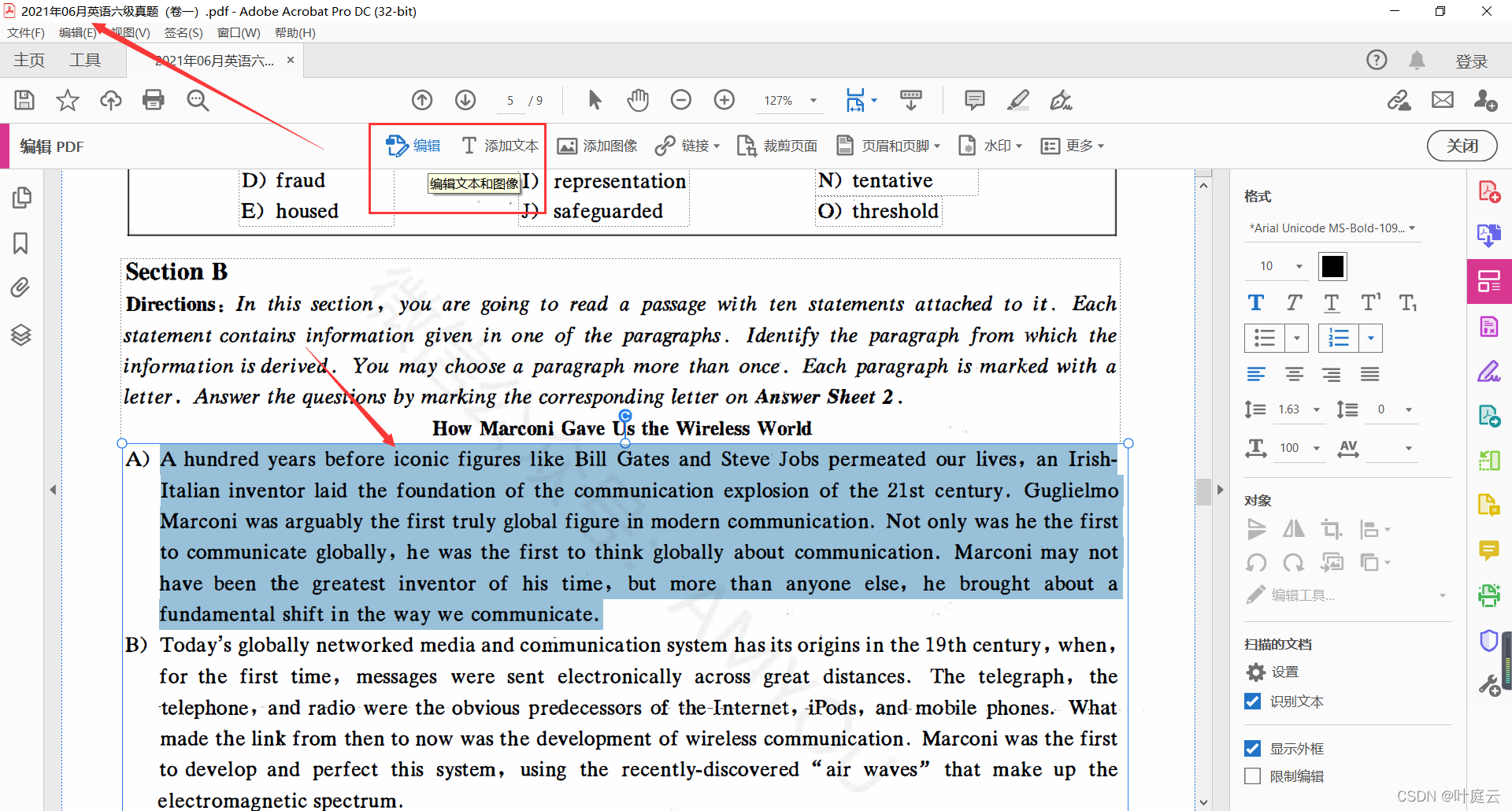

By the way: use Adobe Acrobat Pro DC to cut the page, extract the vector image in PDF and save it. The image will not be distorted when enlarged. If you take a screenshot directly, it will be distorted when enlarged.
Read txt data:
with open("Englishreading.txt", "r", encoding="utf-8") as f1:
con1 = f1.read().split("\n")
dic1 = {}
for i in con1:
data = i.split(":")
dic1[data[0]] = data[1]
print(dic1)with open("match.txt", "r") as f2:
con2 = f2.read().split("\n")
dic2 = {}
for i in con2:
data = i.split(":")
dic2[data[0]] = data[1]
print(dic2)First, simply test one. For example, one is matching F, as shown below:

test_str = "Marconi was central to our present-day understanding of communication."
# test_str = "As an adult, Marconi had an intuition that he had to be loyal to politicians in order to be influential."
big_lst = []
for k, v in dic1.items():
sentence = [x.strip(" ") for x in v.split(".")]
scores = []
for a in sentence:
score = fuzz.partial_ratio(a, test_str)
scores.append(score)
# print(scores, sum(scores), round(sum(scores) / len(scores), 2))
k_score = sum(scores) * 0.2 + sum(scores) / len(scores)
big_lst.append((k, scores, round(k_score, 2)))
results = sorted(big_lst, key=lambda x: x[2], reverse=True)
print(results)
print(results[0][0])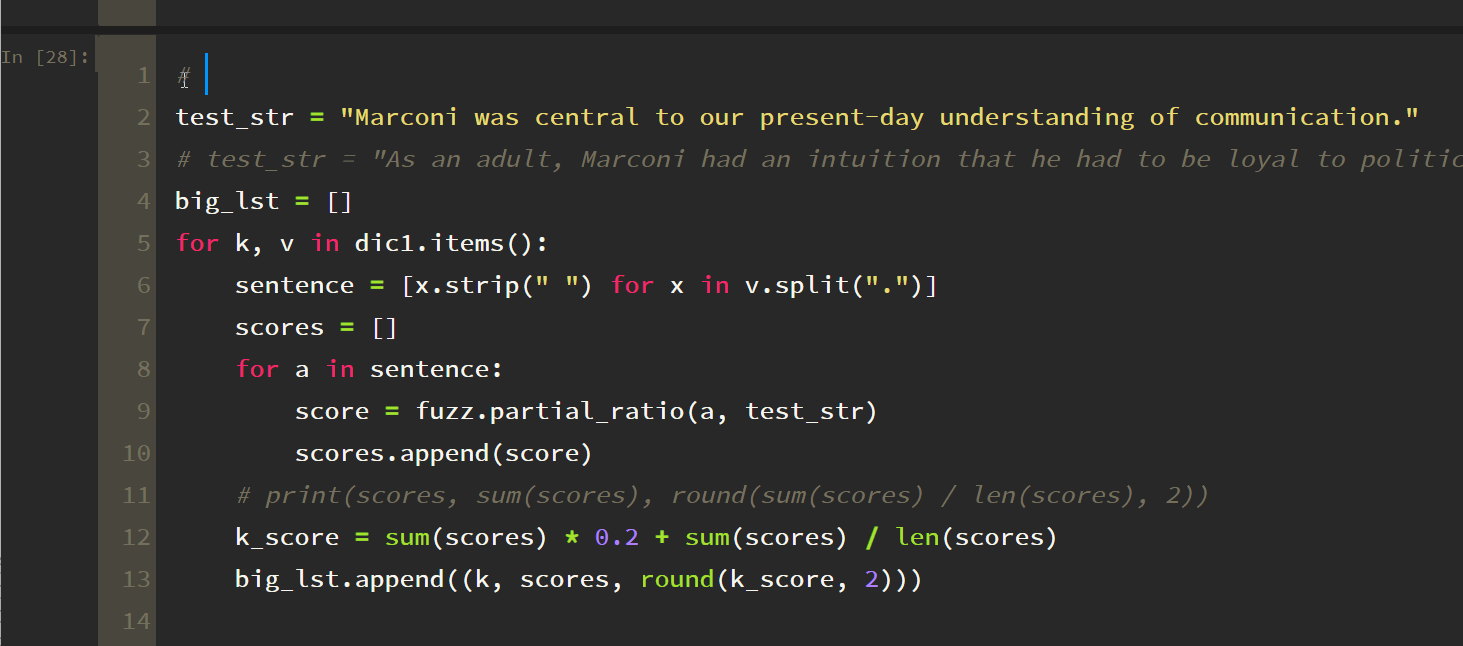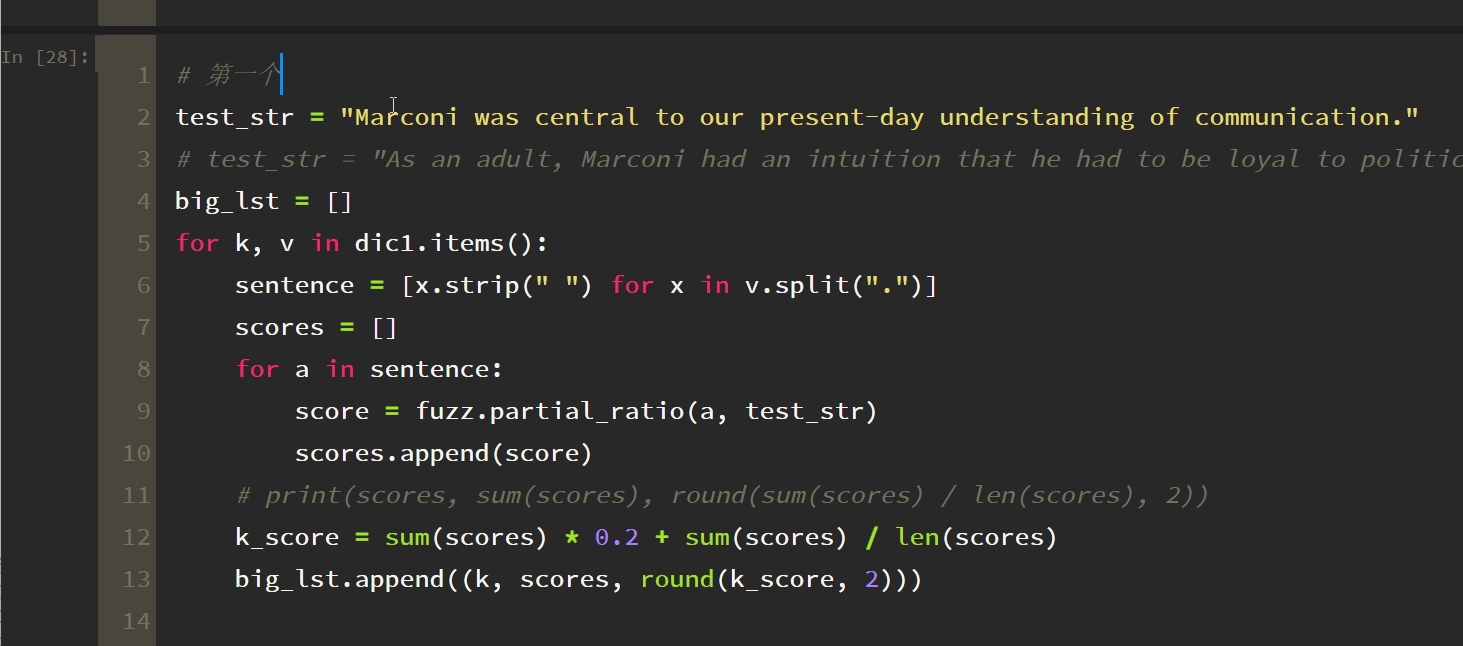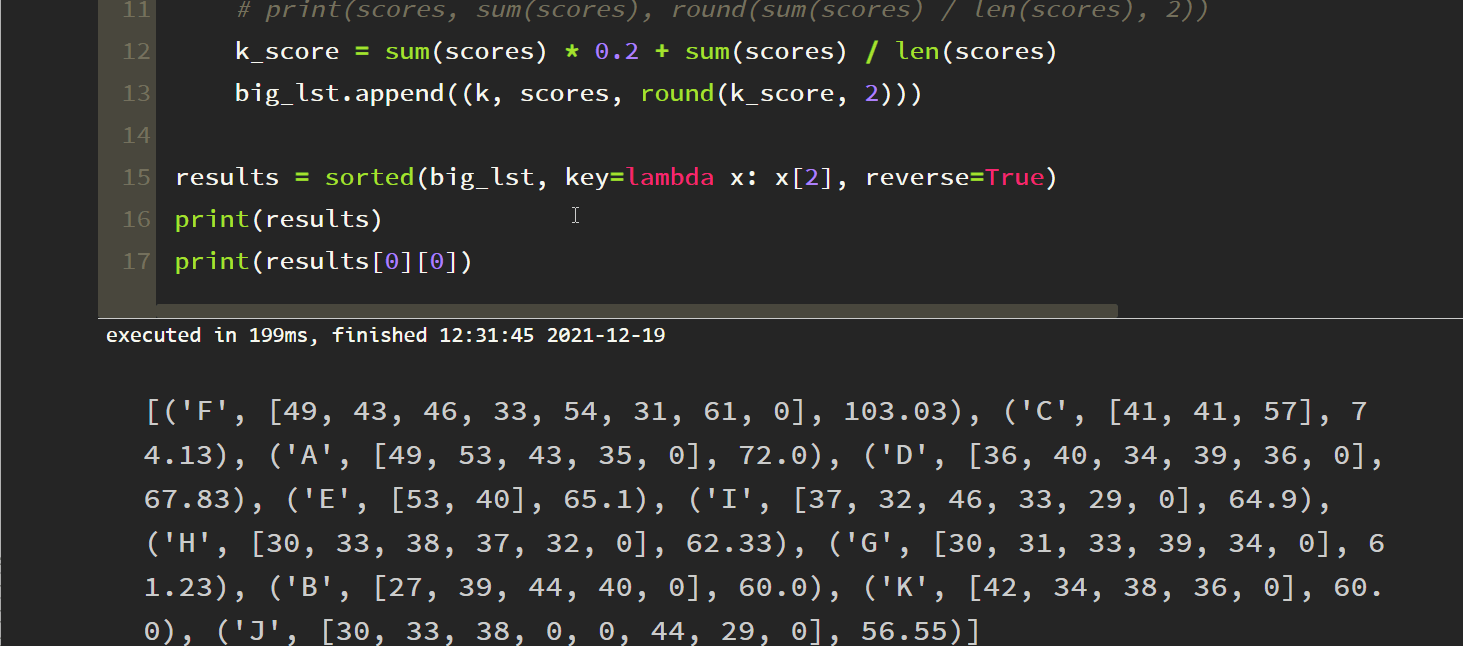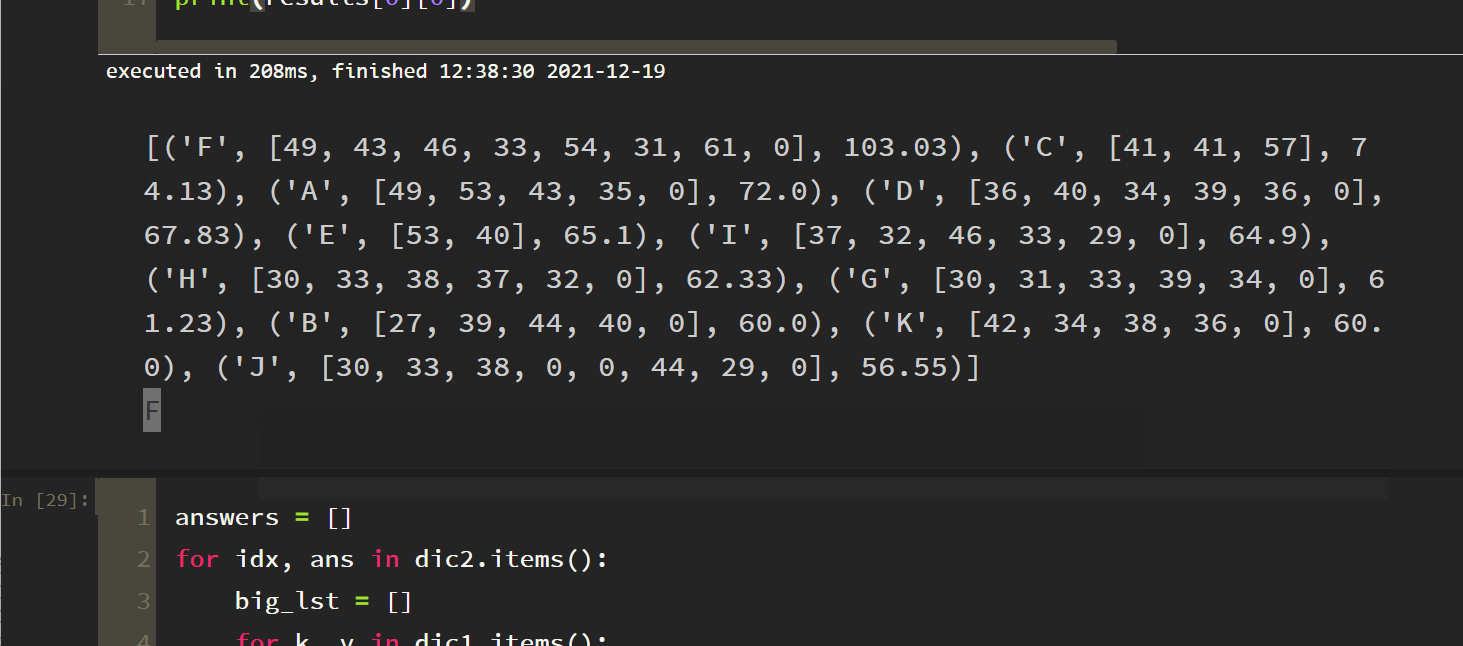
The answer is also F. our algorithm is right! Finally, brush CET-6 paragraph matching (10 questions), and the results are as follows:
# -*- coding: UTF-8 -*-
"""
@Author : Ye Tingyun
@CSDN : https://yetingyun.blog.csdn.net/
"""
answers = []
for idx, ans in dic2.items():
big_lst = []
for k, v in dic1.items():
sentence = [x.strip(" ") for x in v.split(".")]
scores = []
for a in sentence:
# score = fuzz.token_sort_ratio(a, ans)
score = fuzz.partial_ratio(a, ans)
if score > 30:
scores.append(score)
scores.sort()
if len(scores) >= 2:
max_ = max(scores) + scores[-2]
else:
max_ = max(scores)
big_lst.append((k, max_, scores))
results = sorted(big_lst, key=lambda x: x[1], reverse=True)
print(results)
print("-" * 66)
answers.append(results[0][0])
print("answer: ", answers)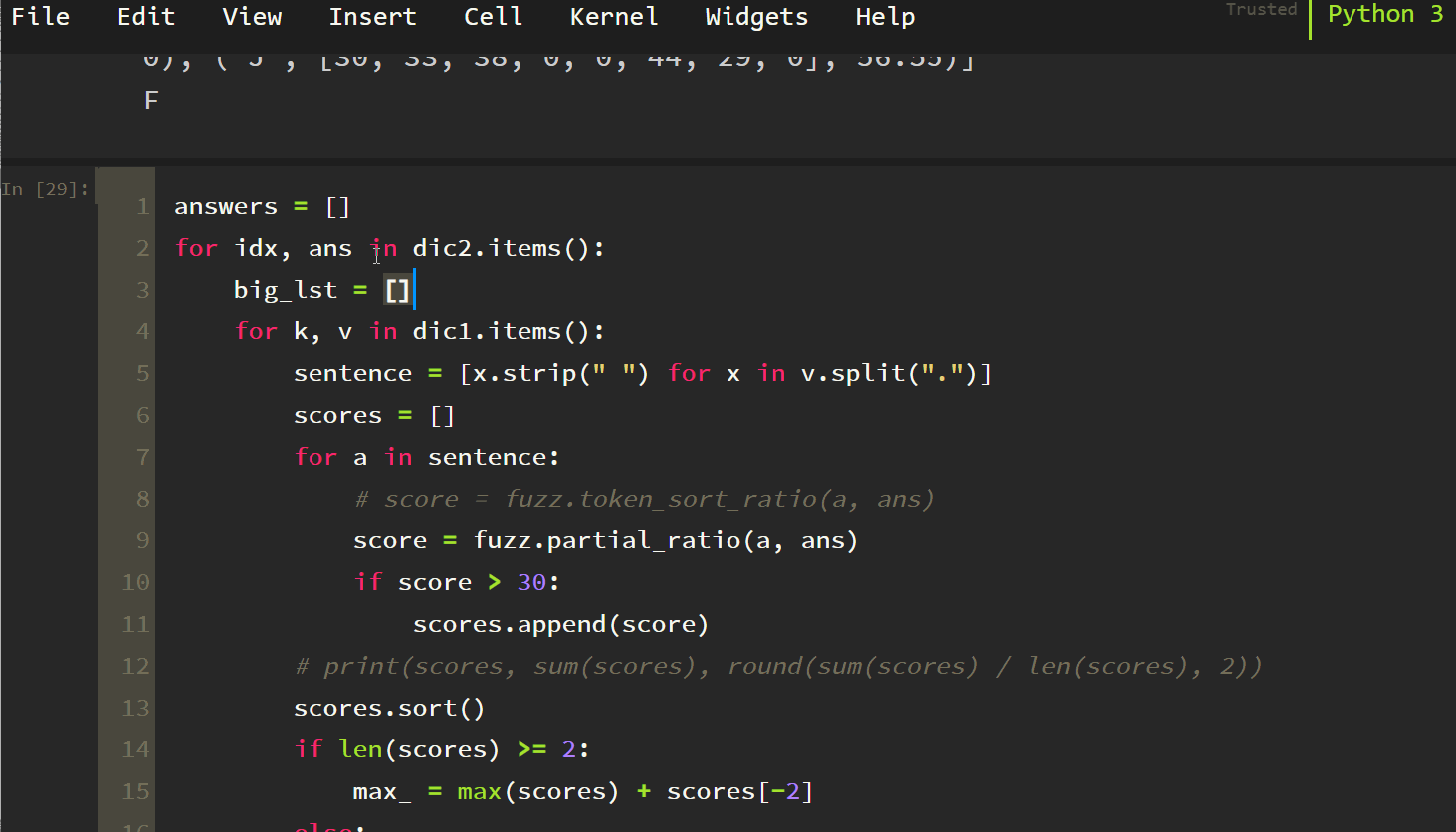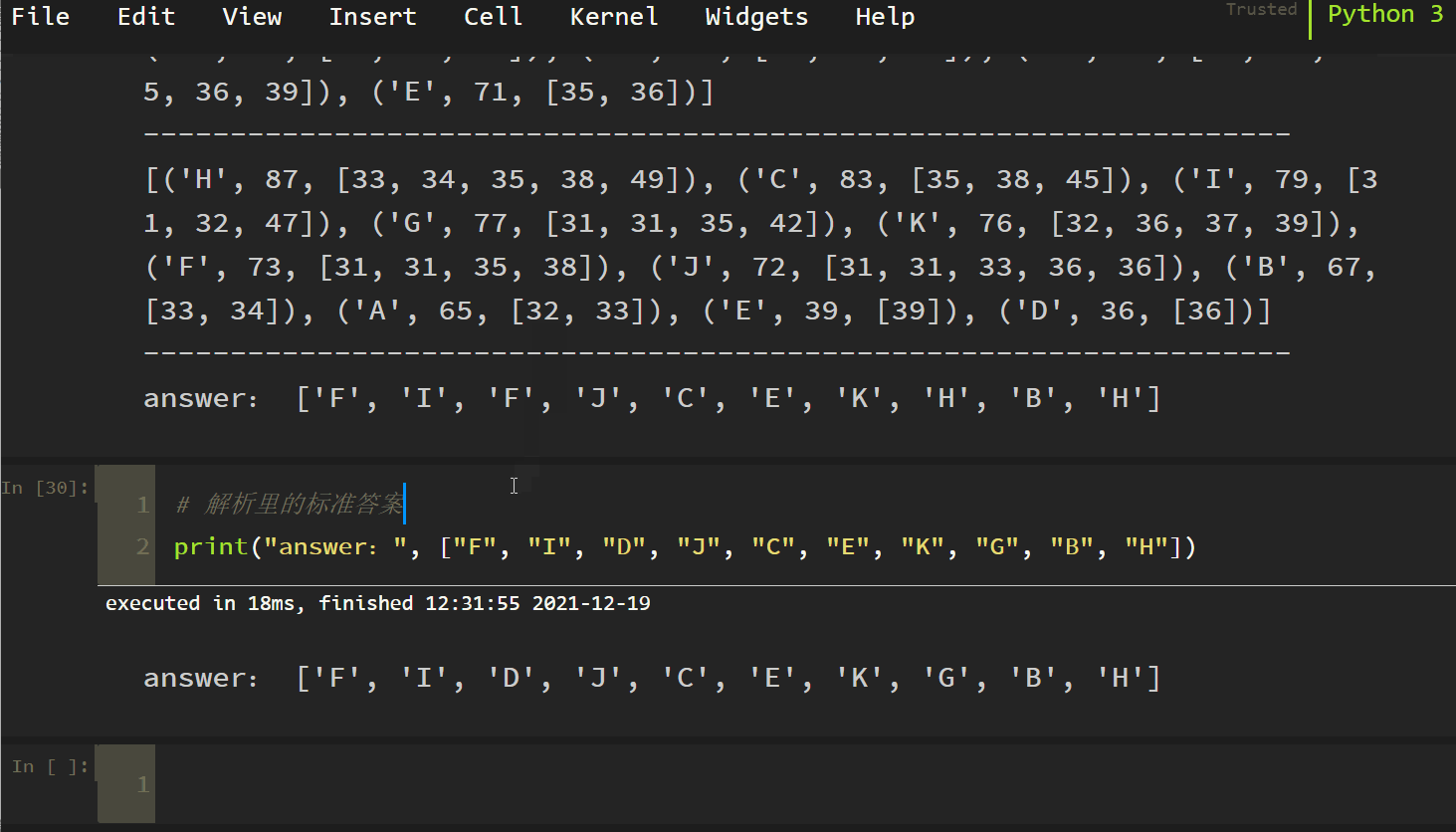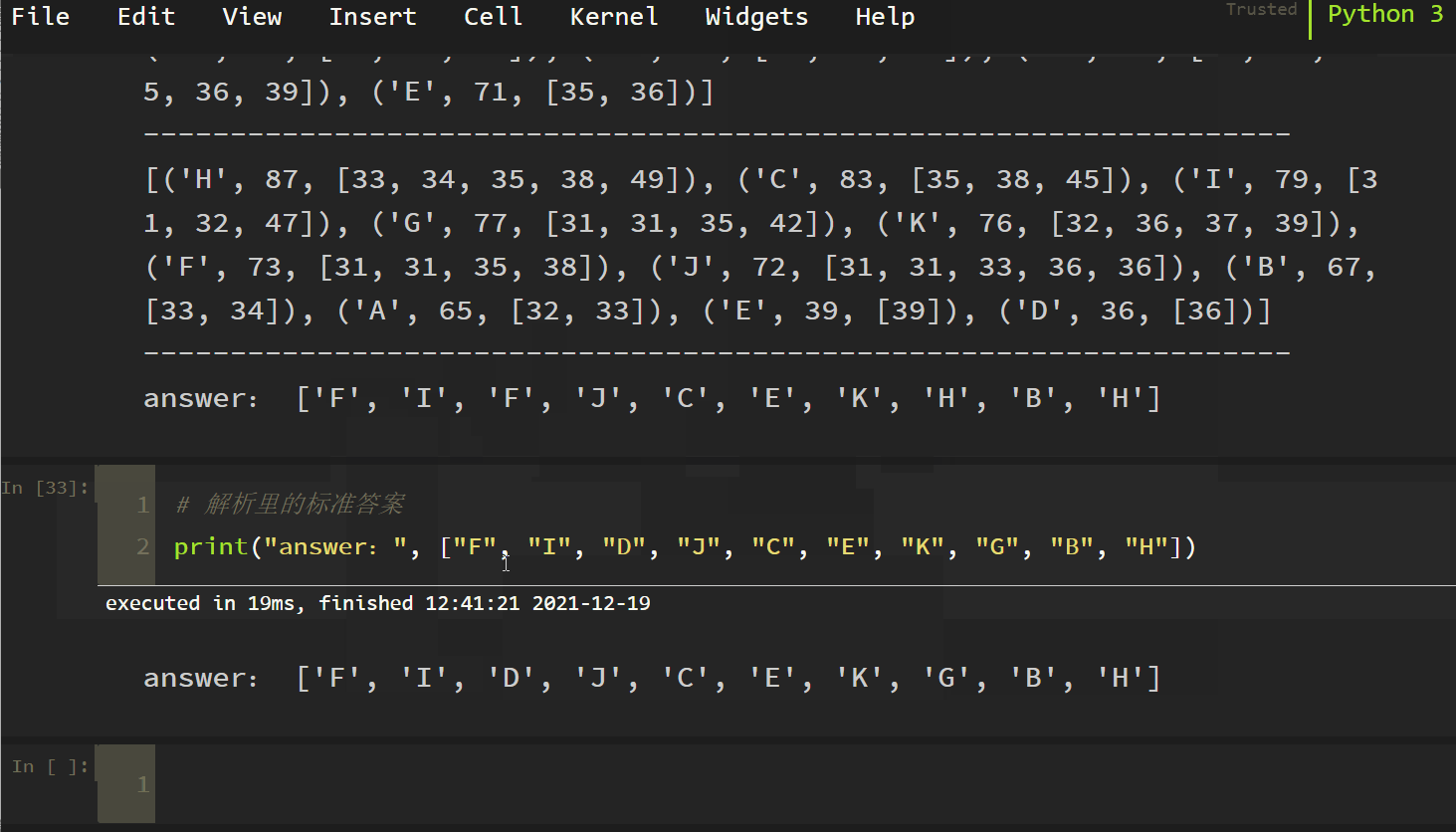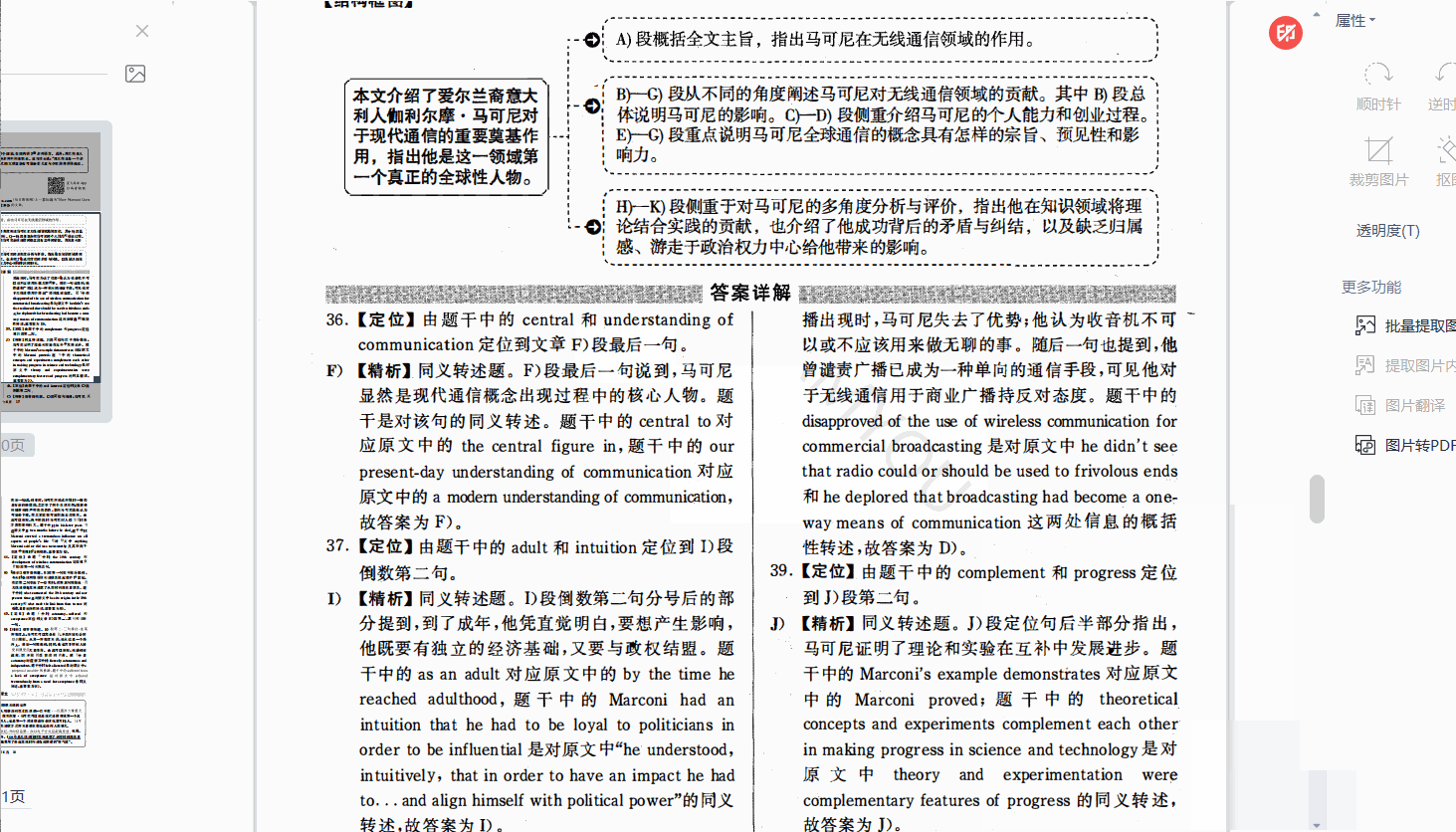

This paper uses Python's fuzzy matching method to brush CET6 paragraph matching, which takes only 3 seconds! (when the intermediate results are printed), the real CET-6 questions (Volume 1) in June 2021 are selected for the test. For CET-6 just tested yesterday, no usable PDF of the real questions has been found on the Internet. Interested readers can practice by themselves and see how many can be right. No, no, no, no one will make more than two mistakes in CET-6 🚀🚀