1, openpyxl of excel for python operation
Preface
According to the official documents, openpyxl is a third-party library that can handle Excel files in xlsx/xlsm format (A Python library to read/write Excel 2010 xlsx/xlsm files).
There are three main concepts in openpyxl: Workbook, sheet and cell.
Main operations in openpyxl: open Workbook, locate Sheet, and operate Cell.
(1) Support excel format
- xlsx
- xlsm
- xltx
- xltm
(2) Basic usage
First of all, it introduces some basic concepts of Excel. Workbook is equivalent to a file. WorkSheet is every specific table in the file. For example, 'Sheet1' in a new EXCEL file, and one or more worksheets in a workbook
- Workbook: a workbook. An excel file contains multiple sheet s.
- worksheet: there are multiple worksheets in a workbook, with table name identification, such as "sheet1", "sheet2", etc.
- Cell: cell, storing data objects
1. Install openpyxl
pip install openpyxl
2. Parameter introduction
(1) Common situations
As far as I am concerned, the common situations may be as follows:
- Read the data of the whole excel sheet page.
- Read data of specified row and column
- Write data to a blank excel document
- Append data to an excel document that already has data
Here are some examples.
(2) Description of modules and functions involved
As far as I know, there are three modules that can operate excel documents, and three modules can be installed directly through pip.
- xlrd: read data
- xlwt: write data
- openpyxl: can read or write data
This is just openpyxl, because this module can meet the above needs.
openpyxl function
| function | Explain |
|---|---|
| load_workbook(filename) | Open excel and return all sheet pages to access the specified sheet page: * ා open the excel document WB = openpyxl.load ᦇ Workbook (file ᦇ) ා access the sheet Page * sheet = wb ['sheet page name'] ා close the excel document wb.close() |
| Workbook() | Create the excel document wb = openpyxl.Workbook(). Save the excel document wb.save ('filename. xlsx ') |
| The following functions are used to access the specified cells for sheet = wb ['sheet page name'], sheet['B1 '] | |
| min_row | Returns the minimum row index containing the data, starting with 1. For example: sheet.min row |
| max_row | Returns the maximum row index containing data, starting at 1 |
| min_column | Returns the minimum column index containing data, starting at 1 |
| max_column | Returns the maximum column index containing data, starting at 1 |
| values | Get all the data of excel document and return a generator object |
| iter_rows(min_row=None, max_row=None, min_col=None, max_col=None) | Min row: minimum row index Max row: maximum row index min col: minimum column index Max col |
| title | The name of the WorkSheet |
Now I have such an excel. Let's use this Excel to explain.

3. Read file properties
import openpyxl
# Open an EXcel document
wb = openpyxl.load_workbook('test.xlsx')
sheet2 = wb['Sheet2']
print('The table name is:',sheet2.title)
print('Rows and columns of data:',sheet2.dimensions)
print('The minimum number of rows is:',sheet2.max_row)
print('The maximum number of rows is:',sheet2.min_row)
print('The maximum number of columns is:',sheet2.max_column)
print('The minimum number of columns is:',sheet2.min_column)
# Get the specified cell
print('Cell A1: ',sheet2['A1'])
print('Cell B1: ',sheet2.cell(row=1, column=2))
# Get row
print('That's ok:',sheet2.rows)
# Get column
print('Column:',sheet2.columns)
# Get all the data
print('All data:',sheet2.values)
# View Excel document properties
print('Read only:',wb.read_only)
print('Document properties:',wb.properties)
#Character set format of document
print('Character set format:',wb.encoding)
# Get active worksheet
print('Active worksheet:',wb.active)
# Get all worksheets
print('All worksheets:',wb.worksheets)
# Get the names of all worksheets
print('Output file all sheet names:', wb.sheetnames)
# Get the worksheet object according to the table name, case sensitive
print('Table name:',wb['Sheet2'])The output result is:
Table name: Sheet2 Number of rows and columns of data: A1:C8 The minimum number of rows is: 8 The maximum number of rows is: 1 Maximum number of columns: 3 The minimum number of columns is: 1 Cell A1: & lt; cell 'SHEET2'. A1 & gt; Cell B1: & lt; cell 'SHEET2'. B1 & gt; Line: & lt; generator object worksheet.] cells by row at 0x000002612197f2e0 & gt; Column: & lt; generator object worksheet. \; All data: & lt; generator object worksheet.values at 0x000002612197f2e0 & gt; Read only: False Document properties: & lt; openpyxl.packaging.core.documentproperties object & gt; Parameters: creator = 'small steel gun', title = none, description = none, subject = none, identifier = none, language = none, created = datetime.datetime (2015, 6, 5, 18, 17, 20), modified = datetime.datetime (2020, 5, 7, 4, 9, 19), LastModified by =, category = none, contentstatus = none, version = none, revision = none, keywords = none, lastprinted = none Character set format: utf-8 Active worksheet: & lt; worksheet "score sheet" & gt; All worksheets: [& lt; worksheet "SHEET2" & gt;, & lt; worksheet "sheet3" & gt;, & lt; worksheet "gradesheet" & gt;] Output file all sheet names: ['sheet2 ',' sheet3 ',' grade sheet '] Table name: & lt; worksheet "SHEET2" & gt;
4. Read file contents
import openpyxl
wb = openpyxl.load_workbook('test.xlsx')
sheet2 = wb['Sheet2']
# Get cell contents
# Mode 1
print('Method 1')
for row in sheet2.values:
print(*row)
print('=========================')
# Mode 2
print('Method 2')
for row in sheet2.rows:
print(*[cell.value for cell in row])
print('=========================')
# Mode 3
print('Method 3')
for row in sheet2.iter_rows():
print(*[cell.value for cell in row])
print('=========================')
# Mode 4 (most complex and original)
print('Method 4')
for i in range(sheet2.min_row, sheet2.max_row + 1):
for j in range(sheet2.min_column, sheet2.max_column + 1):
print(sheet2.cell(row=i,column=j).value,end=' ')
print()The output result is:
Method 1 No. Name Age 1 what happened 25 2 floating vision 26 3 okay 27 4 Reply 28 5 good words 29 6 sets of nets 30 7 too gentle 31 ========================= Method 2 No. Name Age 1 what happened 25 2 floating vision 26 3 okay 27 4 Reply 28 5 good words 29 6 sets of nets 30 7 too gentle 31 ========================= Method 3 No. Name Age 1 what happened 25 2 floating vision 26 3 okay 27 4 Reply 28 5 good words 29 6 sets of nets 30 7 too gentle 31 ========================= Method 4 No. Name Age 1 what happened 25 2 floating vision 26 3 okay 27 4 Reply 28 5 good words 29 6 sets of nets 30 7 too gentle 31
5. Delete and create tables
import openpyxl
# Open an EXcel document
wb = openpyxl.load_workbook('test.xlsx')
sheet2 = wb['Sheet2']
# Delete table
sheet1 = wb.get_sheet_by_name('Sheet1')
wb.remove_sheet(sheet1)
# Save changes to workbook
wb.save('test.xlsx')
# Create a new worksheet
wb.create_sheet('Score sheet')
# Save changes to workbook
wb.save('test.xlsx')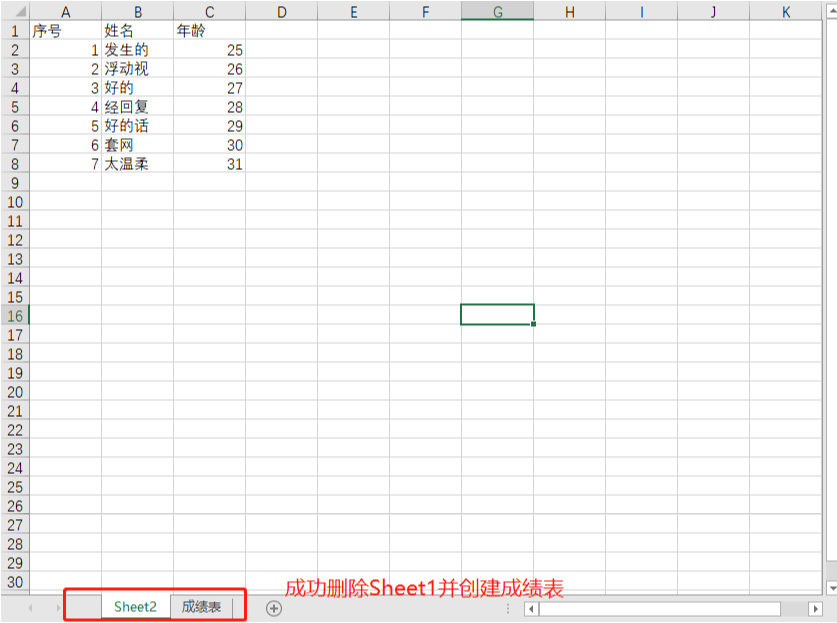
6. Store student grades in Excel
import openpyxl
# Open workbook
wb = openpyxl.load_workbook("Score sheet.xlsx")
# #Create a score sheet
# WB. Create "sheet
#
# # Delete table
# wb.remove_sheet(wb['Sheet1'])
# Get "student transcript"
score = wb["Student transcript"]
# title = ['serial number', 'name', 'language', 'Mathematics']
# no = range(6)
# names = ['Zhang San', 'Li Si', 'Wang Wu', 'Zhao Liu', 'Tian Qi']
# wen = [80,88,85,81,89]
# First row of data
score['A1'].value = 'Serial number'
score['B1'].value = 'Full name'
score['C1'].value = 'Chinese'
score['D1'].value = 'Mathematics'
# Second row of data
score['A2'].value = int('1')
score['B2'].value = 'Zhang San'
score['C2'].value = int('52')
score['D2'].value = int('64')
# Third row of data
score['A3'].value = int('2')
score['B3'].value = 'Li Si'
score['C3'].value = int('28')
score['D3'].value = int('95')
# Save workbook
wb.save('Score sheet.xlsx')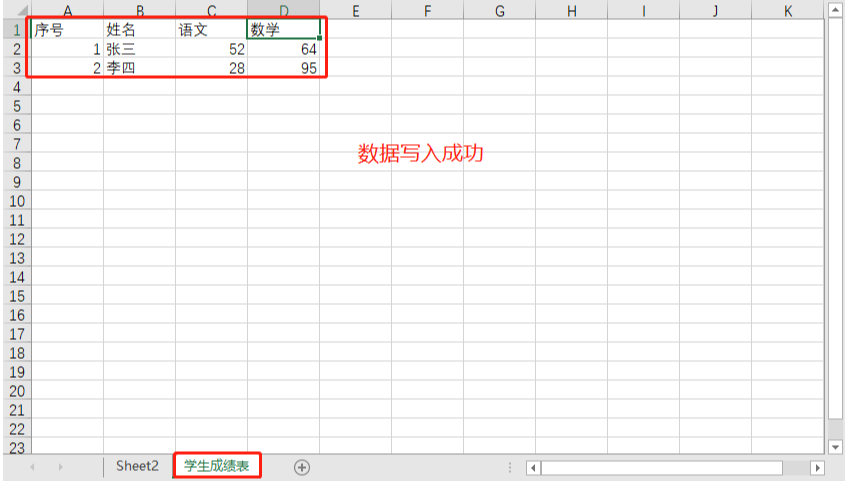
7. Insert sheet contents
#coding=utf-8
import openpyxl
def process_worksheet(sheet):
# Column with total score
sum_column = sheet.max_column + 2
# Column with average score
avg_column = sheet.max_column + 1
# Save total and average scores to the last two columns
for row in sheet.iter_rows(min_row=2, min_col=3):
# Cell
score = [cell.value for cell in row]
# Total score
sum_score = sum(score)
# average
avg_score = sum_score / len(score)
# Save total and average scores to the last two columns
sheet.cell(row=row[0].row, column=avg_column).value = avg_score
sheet.cell(row=row[0].row, column=sum_column).value = sum_score
# Set the title of the average score and total score
sheet.cell(row=1, column=avg_column).value = "average"
sheet.cell(row=1, column=sum_column).value = "Total score"
def main():
# Open Excel document
wb = openpyxl.load_workbook("achievement.xlsx")
# Get a worksheet
sheet = wb["Score sheet"]
# Insert the sheet in the external excel file (score table) into the current Excel
process_worksheet(sheet)
# Save exercise.xlsx
wb.save("Practice-copy.xlsx")
if __name__ == '__main__':
main()View data for exercise - copy.xlsx

2, Python reading and writing Excel files (three modules and three ways
There are many ways for python to read and write excel. Different modules have slightly different ways of speaking in reading and writing:
- Using xlrd and xlwt to read and write excel;
- Using openpyxl to read and write excel;
- Using pandas to read and write excel;
pandas introduction
- Pandas is a data analysis package of Python, which is created to solve data analysis tasks.
- Pandas integrates a large number of libraries and standard data models to provide the tools needed to operate data sets efficiently.
- Pandas provides a large number of functions and methods that enable us to process data quickly and easily.
- Pandas is a dictionary form, which is created based on NumPy, making NumPy centric applications easier.
1. xlrd module
Xlrd is used to read and write data from excel, but I usually only use it to read and write data. There are some problems in writing data. It is convenient to read with xlrd. The process is the same as usual manual operation of Excel. Open workbook, select sheets, and then operate cells. For example, to open an excel file named "data.xlsx" in the current directory, select the first worksheet, read all the contents of the first row and print it out.
#Open excel file
data=xlrd.open_workbook('data.xlsx')
#Get the first sheet (by index)
table=data.sheets()[0]
#Data list is used to store data
data_list=[]
#Read and add the data in the first row of the table to the data menu list
data_list.extend(table.row_values(0))
#Print out all data of the first line
for item in data_list:
print itemIn the above code, table.row'u values (number) is used to read a row, and table.column'u values (number) is used to read a column. Number is the row index. In xlrd, both rows and columns are indexed from 0. Therefore, cell A1 in the top left corner of Excel is row 0 and column 0.
In xlrd, you can use table.cell(row,col) to read a cell, where row and col are the corresponding rows and columns of the cell.
Here is a brief summary of the use of xlrd
(1) Install xlrd module
Download the http://pypi.python.org/cmdpypi/xlrd module on the python official website for installation, provided that the python environment has been installed.
pip install xlrd
(2) Tips
- sheet.name: the name of sheet
- sheet.nrows: number of sheet rows
- sheet.ncols: number of sheet columns
- Sheet. Get rows(): returns an iterator, traverses all rows, and gives a list of values for each row
- Sheet. Row? Values (index): returns a list of values for a row
- sheet.row(index): returns a row object. You can get the cell object in this row through row[index]
- sheet.col_values(index): returns a list of values in a column
- sheet.cell(row,col): get a cell object (row and col start from 0
table = data.sheets()[0] #Get by index order table = data.sheet_by_index(0) #Get by index order table = data.sheet_by_name(u'Sheet1')#Get by name # Get values (arrays) for entire rows and columns table.row_values(i) table.col_values(i) # Get the number of rows and columns nrows = table.nrows ncols = table.ncols # Circular row list data for i in range(nrows): print table.row_values(i) # Cell cell_A1 = table.cell(0,0).value cell_C4 = table.cell(2,3).value # Use row and column index cell_A1 = table.row(0)[0].value cell_A2 = table.col(1)[0].value # Simple write row = 0 col = 0 # Type 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error ctype = 1 value = 'Cell value' xf = 0 # Extended formatting table.put_cell(row, col, ctype, value, xf) table.cell(0,0) #Cell value ' table.cell(0,0).value #Cell value '
(3) View file data
import xlrd
book = xlrd.open_workbook('Practice-copy.xlsx')
sheet1 = book.sheets()[0]
nrows = sheet1.nrows
print('Total number of table lines:', nrows)
ncols = sheet1.ncols
print('Total columns:', ncols)
row3_values = sheet1.row_values(2)
print('Value in line 3:', row3_values)
col3_values = sheet1.col_values(2)
print('Values in column 3:', col3_values)
cell_2_2 = sheet1.cell(2,2).value
print('3 Value of row 3 column',cell_2_2)The output is as follows
Total number of table lines: 8 Total number of columns in the table: 3 Value in line 3: [2.0, 'floating view', 26.0] Values in column 3: ['age ', 25.0, 26.0, 27.0, 28.0, 29.0, 30.0, 31.0] Value of 3 rows and 3 columns 26.0
2. xlwt module
pip install xlwt
If xlrd is not a simple Reader (if the last two characters in xlrd are regarded as readers, then the last two characters in xlwt are similar to writers), then xlwt is a pure Writer, because it can only write to Excel. Xlwt and xlrd are not only names, but also many functions and operation formats. Here is a brief summary of common operations
(1) xlwt common operations
Create a new Excel file (can only be written by creating a new one)
data=xlwt.Workbook()
Create a new sheet
table=data.add_sheet('name')Write data to cell A1
table.write(0,0,u'Ha-ha')
Note: if you repeat the operation on the same cell, an overwrite Exception will be raised. To cancel this function, you need to specify it as overwritable when adding a worksheet, as follows
table=data.add_sheet('name',cell_overwrite_ok=True)Save file
data.save('test.xls')Only the extension xls can be saved here. The format of xlsx is not supported
xlwt supports certain styles. The operations are as follows
#Initialize style style=xlwt.XFStyle() #Create fonts for styles font=xlwt.Font() #Specify font name font.name='Times New Roman' #Bold font font.bold=True #Set the font to style font style.font=font #Use this style when writing to a file sheet.write(0,1,'just for test',style)
(2) Examples
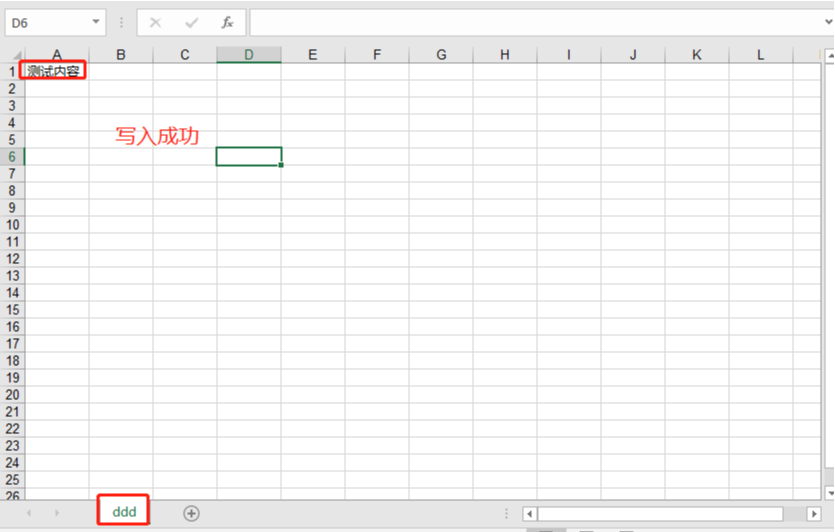
import xlwt # It seems that Excel 2007's xlsx format is not supported
wb = xlwt.Workbook()
wb_sheet = wb.add_sheet('ddd')
wb_sheet.write(0,0,'Test content')
wb.save('d.xls')View d.xls file
3. openpyxl module
pip install openpyxl
This module supports the latest version of Excel file format, and has read and write operations that respond to Excel files. There are two special classes for this, Reader and Writer, which are convenient for the operation of Excel files. However, I usually use the default workbook to operate. Common operations are summarized as follows:
(1) openpyxl common operations
Read Excel file
from openpyxl.reader.excel import load_workbook wb=load_workbook(filename)
Show the index range of the sheet
wb.get_named_ranges()
Show all sheet names
wb.get_sheet_names()
Get the first sheet
sheetnames = wb.get_sheet_names() ws = wb.get_sheet_by_name(sheetnames[0])
Get table name
ws.title
Get the number of rows in the table
ws.get_highest_row()
Get the number of columns in the table
ws.get_highest_column()
Cell reading is very similar to that of xlrd, which is read through the indexes of rows and columns
#Read from cell B1 ws.cell(0,1).value
Of course, it also supports reading data through Excel coordinates. The code is as follows
#Read from cell B1
ws.cell("B1").value(2) Examples
import pandas as pd
from pandas import DataFrame
# df = pd.read_excel(r 'exercise - copy.xlsx',sheet_name = 'student transcript')
# print(df.head())
data = {
'name':['Zhang San','Li Si','Wang Wu'],
'age':[11,12,13],
'sex':['male','female','Unknown'],
}
df = DataFrame(data)
df.to_excel('new.xlsx')View the new.xlsx file

4. Cases

Extract two tables from the original Excel document provided into another new Excel document, and arrange them horizontally
The code is as follows:
import openpyxl
import pandas
from pandas import DataFrame
wb = openpyxl.load_workbook('Live Database and table structure.xlsx')
sheet = wb['Sheet1']
aa = []
for row1 in sheet.iter_rows(min_row=3,max_row=6):
score1 = [cell.value for cell in row1]
aa.append(score1)
df = DataFrame(aa)
df.to_excel('xgp.xlsx')
bb = []
for row2 in sheet.iter_rows(min_row=8,max_row=14):
score2 = [cell.value for cell in row2]
bb.append(score2)
df = pandas.DataFrame(bb)
book = openpyxl.load_workbook('xgp.xlsx')
with pandas.ExcelWriter('xgp.xlsx')as E:
E.book = book
E.sheets = dict((ws.title, ws) for ws in book.worksheets)
df.to_excel(E,sheet_name='Sheet1',index=False,startcol=12)View the xgp.xlsx file

5. Summary
When reading Excel, there is little difference between openpyxl and xlrd, which can meet the requirements
When writing a small amount of data and saving it as xls format file, it is more convenient to use xlwt
When you write a large amount of data (exceeding the xls format limit) or you have to save it as an xlsx format file, you need to use openpyxl.