Python implementation of k-nearest neighbor algorithm
1, Overview
K-nearest neighbor algorithm, also known as KNN algorithm, is the simplest algorithm in data mining technology. Working principle of KNN: given a training dataset with known label category, after inputting new data without label, find K instances closest to the new data in the training dataset. If most of these K instances belong to a category, the new data belongs to this category. It can be simply understood as: the k points closest to X vote to decide which category X belongs to.

In Figure 1, there are two categories: red triangle and blue square. Now we need to judge which category the green dot belongs to
When k=3, the green dot belongs to the category of red triangle;
When k=5, the green dot belongs to the category of blue square.
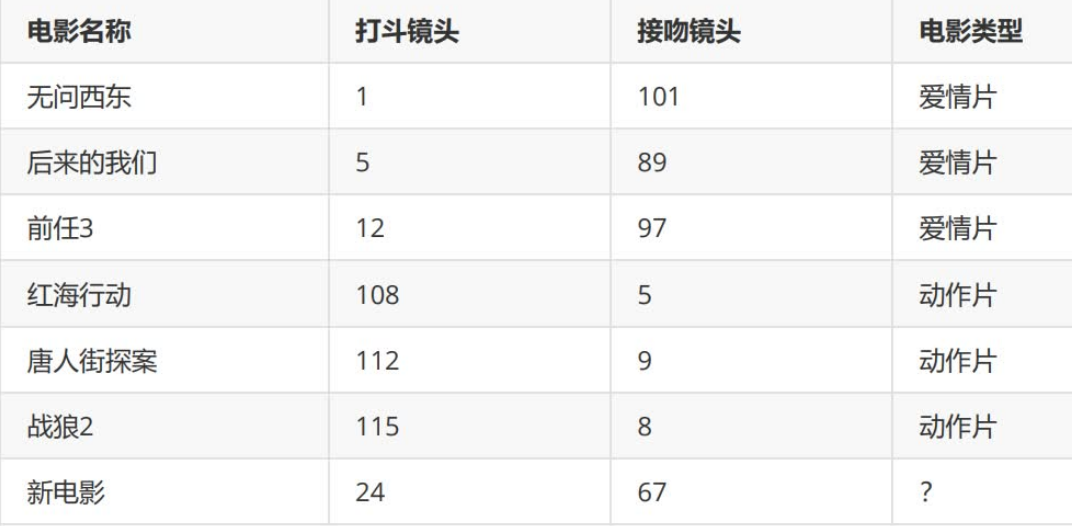
For a simple example, k-nearest neighbor algorithm can be used to classify whether a movie is a love movie or an action movie. (the number of fighting scenes and kissing scenes is fictional)
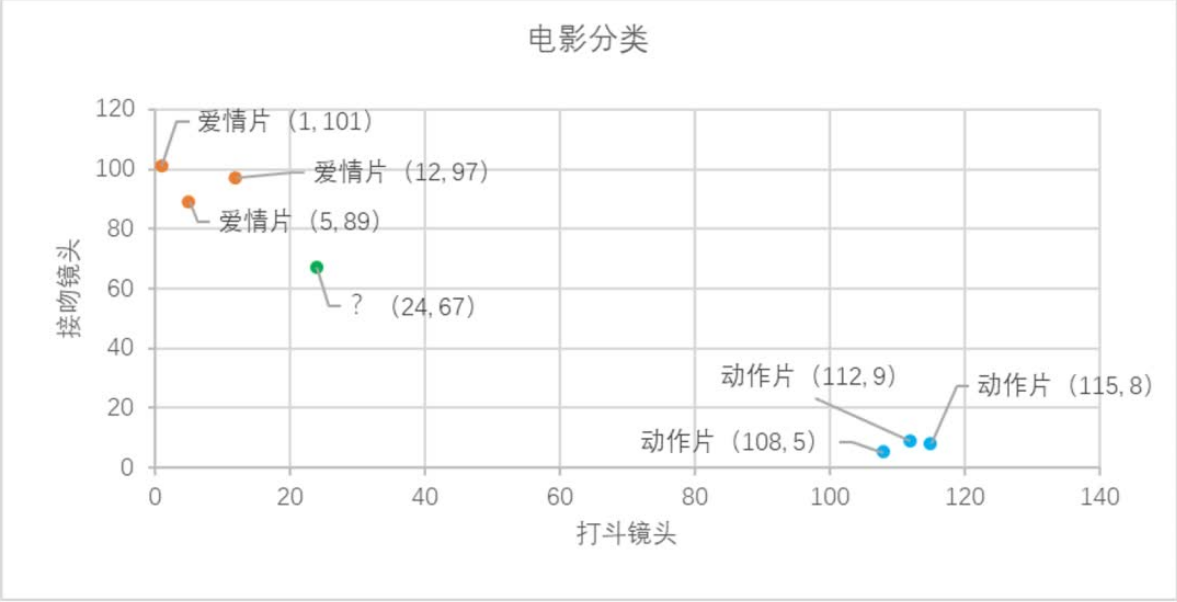
We can roughly infer from the scatter diagram that this unknown film may be a romantic film, because it looks closer to the three known romantic films. What method does k-nearest neighbor algorithm use to judge? Yes, it's distance measurement. We can calculate the distance between two points in the two-dimensional classification formula in high school, that is:
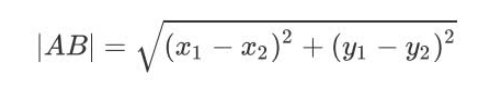
How to calculate if multiple features are extended to N-dimensional space? Yes, we can use Euclidean distance (also known as Euclidean measure), as shown below
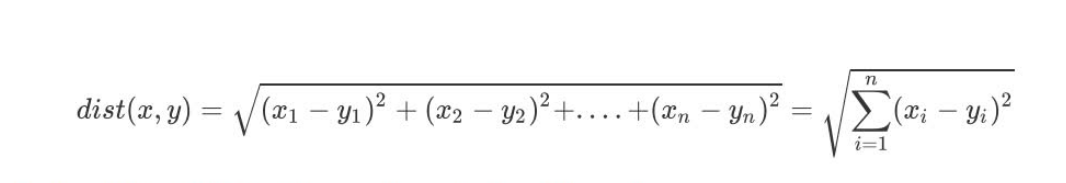
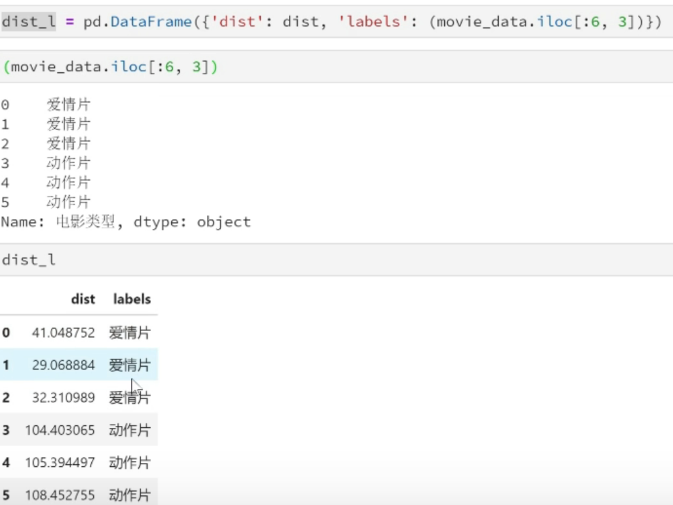
The distance between all movies in the training set and unknown movies can be obtained through calculation, as shown in Table 2

Through the calculation results in Table 2, we can know that the film marked with green dot is the closest to the romantic film "later us", which is 29.1. If only based on this result, the category of green dot film is determined as love film, this algorithm is called nearest neighbor algorithm, not k-nearest neighbor algorithm. The steps of k-nearest neighbor algorithm are as follows:
(1) Calculate the distance between the point in the known category dataset and the current point;
(2) Sort according to the order of increasing distance;
(3) Select the k points with the smallest distance from the current point;
(4) Determine the occurrence frequency of the category where the first k points are located;
(5) Return the category with the highest frequency of the first k points as the prediction category of the current point.
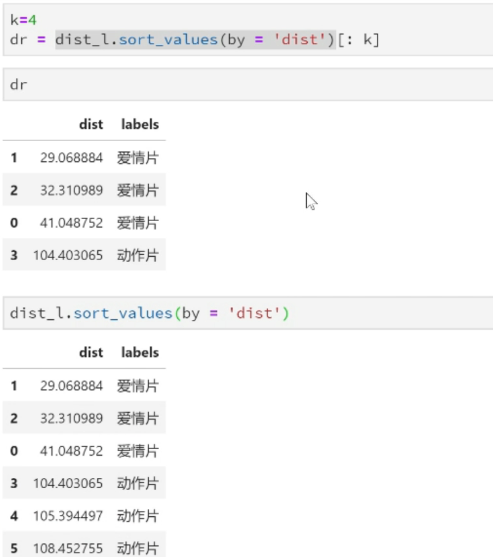
For example, now k = 4, in this movie example, the distance is arranged in ascending order. The first four movies closest to the green dot film are "later us", "former 3", "Wu Wen Xi Dong" and "operation Red Sea". The categories of these four films are love films: action films = 3:1, and the category with the highest frequency is love films, so when k = 4, The category of green dot films is romance. This discrimination process is k-nearest neighbor algorithm.
2, Python implementation of k-nearest neighbor algorithm
After understanding the principle and implementation steps of k-nearest neighbor algorithm, we implement these processes in python.
1.1 build the original data set that has been classified. In order to facilitate verification, we use python dictionary dict to build the data set, and then convert it into DataFrame format.
import pandas as pd
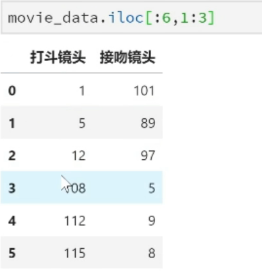
rowdata = {'Movie title': ['Ask nothing', 'Later we', 'Predecessor 3', 'Operation Red Sea', 'Chinatown detective', 'War wolf'],
'Fighting lens': [1, 5, 12, 108, 112, 115],
'Kissing lens': [101, 89, 97, 5, 9, 8],
'Film type': ['affectional film', 'affectional film', 'affectional film', 'action movie', 'action movie', 'action movie']}
movie_data = pd.DataFrame(rowdata)
print(movie_data)
'''
Film name fighting lens kissing lens film type
0 Ask nothing 1 101 romance
1 Later we 5 89 romance
2 Predecessor 3 12 97 romance
3 Operation Red Sea 108 5 action film
4 Chinatown detective 112 9 action film
5 Warwolf 115 8 action film
'''
"" "create dictionary using {}" ""
scores = {'Zhang San': 100}
print(scores) # {'Zhang San': 100}
2. Calculate the distance between the point in the known category dataset and the current point
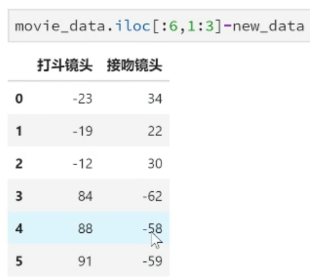
new_data = [24, 67] dist = list((((movie_data.iloc[:6, 1:3] - new_data) ** 2).sum(1)) ** 0.5) print(dist)
'''The second way to create a list,Use built-in functions list()''' lst2 = list(['hello', 'world', 98]) print(lst2) # ['hello', 'world', 98]
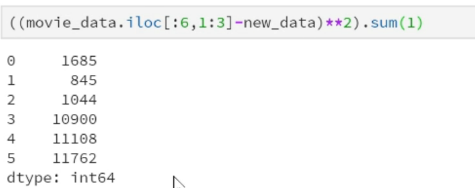
sum of columns (1)
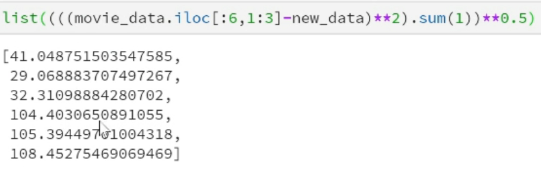
3. Arrange the distance in ascending order, and then select the k points with the smallest distance
dist_l = pd.DataFrame({'dist': dist, 'labels': (movie_data.iloc[:6, 3])})
print(dist_l)
k = 4;
dr = dist_l.sort_values(by='dist')[:4]
print(dr)
4. Determine the occurrence frequency of the category where the first k points are located
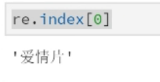
re = dr.loc[:, 'labels'].value_counts() print(re);

5. Select the category with the highest frequency as the prediction category of the current point
result = [] result.append(re.index[0]) print(result)#[romance]