Python implementation of regular update of ChromeDriver
Selenium, as a UI automation testing framework based on web pages, is deeply loved by developers and occupies a place in the field of automation; Selenium framework, together with its configured tool ChromeDriver, is used to help developers complete all kinds of work. At the same time, the page saves most human and material resources and greatly improves efficiency.
However, those who use Selenium framework know that chrome driver needs to be updated synchronously with the update of Google browser. Only the matching version of chrome driver can start the browser and complete the program we want to run. Now, the update frequency of Google browser will be updated once every two weeks. Therefore, it is very important for the whole automation to update the chrome driver tool regularly.
When you search for chrome driver updates, you can also get all kinds of results on the website. The methods used by various gods are also different. However, the latest update led to the shutdown of my automatic program for a day, so I had to put down my work and take a look at the specific problem
After debugging the whole code, it is found that the problem appears on the software image source. Previously, we used the Taobao image warehouse of ChromeDriver at the address:
CNPM Binaries Mirror(http://npm.taobao.org/mirrors/chromedriver/)
However, after you open the link again this time, you will find that the address automatically jumps to a new image address with SSL encryption, which leads to the failure of basically all automatic update codes on the Internet. The new address is
CNPM Binaries Mirror(https://registry.npmmirror.com/binary.html?path=chromedriver/)
We get the corresponding version through the image source. The basic idea of its implementation is to get the latest version of the browser, and then find the corresponding version of chrome driver. The automatic logic is to get the version numbers of both sides and make a comparison. However, if you directly request to crawl the content of the new address above, you will find that, There is no version number list you want in his web page source code, as shown in the following code:
<!DOCTYPE html>
<html>
<head>
<title>CNPM Binaries Mirror</title>
</head>
<body>
<script>
// Forked from https://chromedriver.storage.googleapis.com/index.html
// Split a string in 2 parts. The first is the leading number, if any,
// the second is the string following the numbers.
function splitNum(s) {
var results = new Array();
results[0] = 'None';
for (var i = 0; i < s.length; i++) {
var substr = s.substr(0, i+1)
if (isNaN(substr)) {
// Not a number anymore.
results[1] = s.substr(i)
break;
} else {
// This is a number. update the results.
results[0] = parseFloat(substr);
}
}
return results;
}
// Compare 2 strings using a custom alphanumerical algorithm.
// This is similar to a normal string sort, except that we sort
// first by leading digits, if any.
// For example:
// 100hello > 2goodbye
// Numbers anywhere else in the string are compared using the normal
// sort algorithm.
function alphanumCompare(a, b) {
var parsedA = splitNum(a);
var parsedB = splitNum(b);
var numA = parsedA[0];
var numB = parsedB[0];
var strA = parsedA[1];
var strB = parsedB[1];
if (isNaN(numA) == false && isNaN(numB) == false) {
// They both start with numbers.
if (numA < numB) return -1;
if (numA > numB) return 1;
// Identical. Fallback to string.
return (strA < strB) ? -1 : (strA > strB ? 1 : 0)
}
// If only one starts with a number, we start with that one as
// the lowest.
if (isNaN(numA) == false) return -1
if (isNaN(numB) == false) return 1
// They are both strings.
return (a < b) ? -1 : (a > b ? 1 : 0)
}
// Helper function to retrieve the value of a GET query parameter.
// Greatly inspired from http://alturl.com/8rj7a
function getParameter(parameterName) {
// Add '=' to the parameter name (i.e. parameterName=value)
var parameterName = parameterName + '=';
var queryString = window.location.search.substring(1);
if (queryString.length <= 0) {
return '';
}
// Find the beginning of the string
begin = queryString.indexOf(parameterName);
// If the parameter name is not found, skip it, otherwise return the
// value.
if (begin == -1) {
return '';
}
// Add the length (integer) to the beginning.
begin += parameterName.length;
// Multiple parameters are separated by the '&' sign.
end = queryString.indexOf ('&', begin);
if (end == -1) {
end = queryString.length;
}
// Return the string.
return escape(unescape(queryString.substring(begin, end)));
}
// Displays the directory listing given the XML and path.
function displayList(items, root, path) {
// Display the header
document.write('<h1>Index of /' + path + '</h1>');
// Start the table for the results.
document.write('<table style="border-spacing:15px 0px;">');
var sortOrder = getParameter('sort');
var sortLink = location.pathname + '?path=' + path;
if (sortOrder != 'desc') {
sortLink += '&sort=desc';
}
// Display the table header.
document.write('<tr><th><img src="https://gw.alipayobjects.com/mdn/rms_fa382b/afts/img/A*v6fRRLopV_0AAAAAAAAAAAAAARQnAQ" alt="[ICO]"></th>');
document.write('<th><a href="' + sortLink + '">Name</a></th>');
document.write('<th>Last modified</th>');
document.write('<th>Size</th>');
document.write('<tr><th colspan="5"><hr></th></tr>');
// Display the 'go back' button.
if (path != '') {
var backpath = location.pathname;
// If there is more than one section delimited by '/' in the current
// path we truncate the last section and append the rest to backpath.
var delimiter = path.lastIndexOf('/');
if (delimiter >= 0) {
delimiter = path.substr(0, delimiter).lastIndexOf('/');
if (delimiter >= 0) {
backpath += '?path=';
backpath += path.substr(0, delimiter+1);
}
}
document.write('<tr><td valign="top"><img src="https://gw.alipayobjects.com/mdn/rms_fa382b/afts/img/A*3QmJSqp2zpUAAAAAAAAAAAAAARQnAQ" alt="[DIR]"></td>');
document.write('<td><a href="');
document.write(backpath);
document.write('">Parent Directory</a></td>');
document.write('<td> </td>');
document.write('<td align="right"> - </td></tr>');
}
// Set up the variables.
var directories = new Array();
var files = new Array();
for (var i = 0; i < items.length; i++) {
var item = items[i];
if (item.type === 'file') {
files.push(item);
} else {
directories.push(item);
}
}
files.sort(alphanumCompare);
directories.sort(alphanumCompare);
// Reverse the list for a descending sort.
if (sortOrder == 'desc') {
files.reverse();
directories.reverse();
}
// Display the directories.
for (var i = 0; i < directories.length; i++) {
var lnk = location.pathname.substr(0, location.pathname.indexOf('?'));
var item = directories[i];
lnk += '?path=' + path + item.name;
document.write('<tr>');
document.write('<td valign="top"><img src="https://gw.alipayobjects.com/mdn/rms_fa382b/afts/img/A*ct35SJLile8AAAAAAAAAAAAAARQnAQ" alt="[DIR]"></td>');
document.write('<td><a href="' + lnk + '">' +
item.name + '</a></td>');
document.write('<td align="right">' + (item.date || '-') + '</td>');
document.write('<td align="right">-</td>');
document.write('</tr>');
}
// Display the files.
for (var i = 0; i < files.length; i++) {
var item = files[i];
var link = item.url;
var filename = item.name;
var sizeUnit = '';
var size = item.size;
if (size > 1024) {
sizeUnit = 'KB';
size = size / 1024;
if (size > 1024) {
sizeUnit = 'MB';
size = size / 1024;
}
}
if (sizeUnit !== '') {
size = size.toFixed(2) + sizeUnit;
}
var lastModified = item.date;
// Remove the entries we don't want to show.
if (filename == '') {
continue;
}
if (filename.indexOf('$folder$') >= 0) {
continue;
}
// Display the row.
document.write('<tr>');
document.write('<td valign="top"><img src="https://gw.alipayobjects.com/mdn/rms_fa382b/afts/img/A*FKvWRo-vns4AAAAAAAAAAAAAARQnAQ" alt="[DIR]"></td>');
document.write('<td><a href="' + link + '">' + filename +
'</a></td>');
document.write('<td align="right">' + lastModified + '</td>');
document.write('<td align="right">' + size + '</td>');
document.write('</tr>');
}
// Close the table.
document.write('<tr><th colspan="5"><hr></th></tr>');
document.write('</table>');
document.title = 'CNPM Binaries Mirror';
}
function fetchAndDisplay() {
var path = getParameter('path');
var lastSlash = location.pathname.lastIndexOf("/");
var filename = location.pathname.substring(lastSlash + 1);
var root = 'https://registry.npmmirror.com/-/binary/';
var http = new XMLHttpRequest();
http.open('GET', root + path, true);
http.onreadystatechange = useHttpResponse;
http.send(null);
function useHttpResponse() {
if (http.readyState == 4) {
var items = [];
try {
items = JSON.parse(http.responseText);
} catch (err) {
console.error(err, http.responseText);
}
displayList(items, root, path);
}
}
}
fetchAndDisplay();
</script>
</body>
</html>
Through the packet capturing analysis, it is found that the real request path is not the address itself seen above the website, but another request specially loading these version information, as shown in the figure below
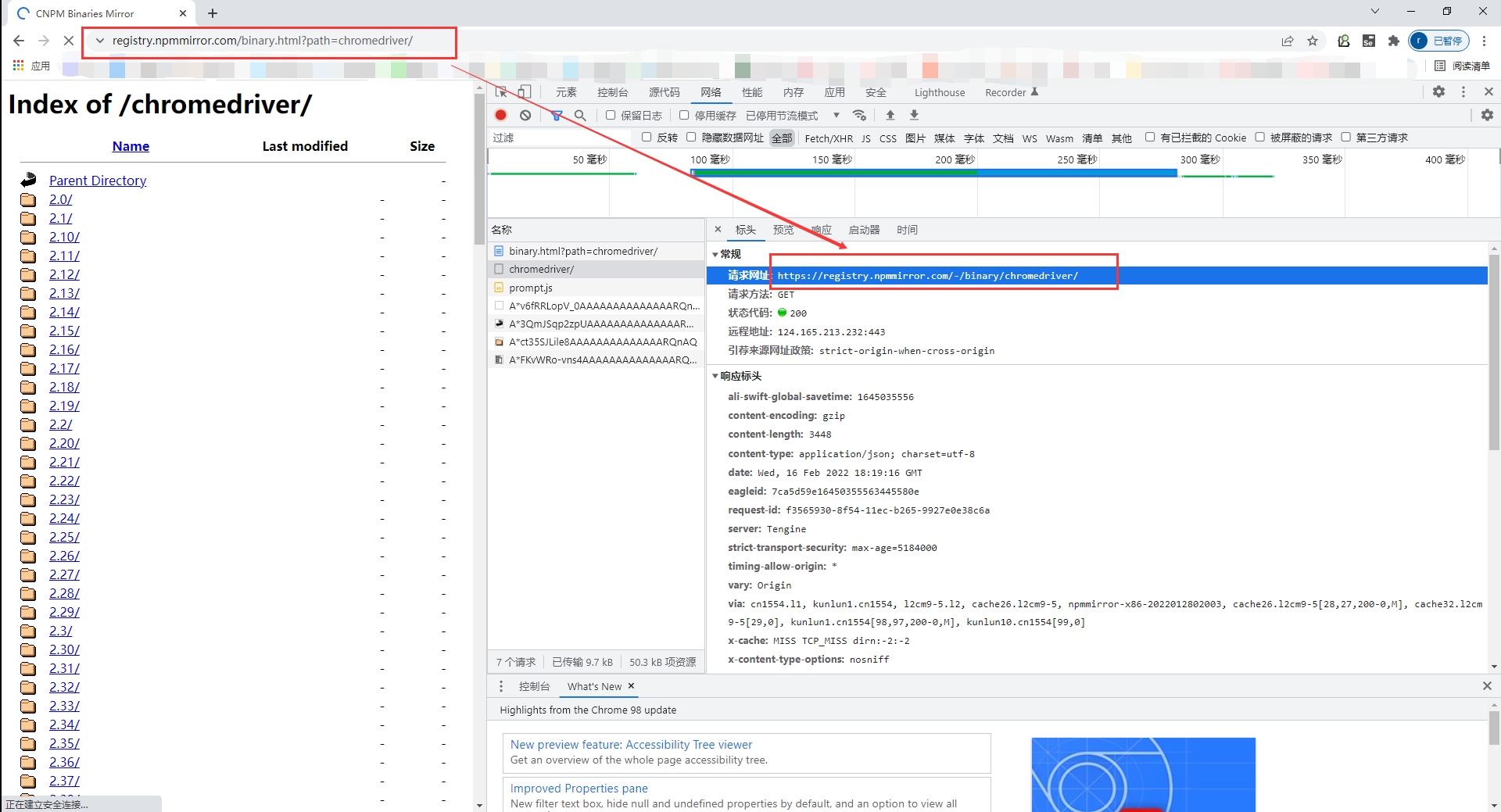
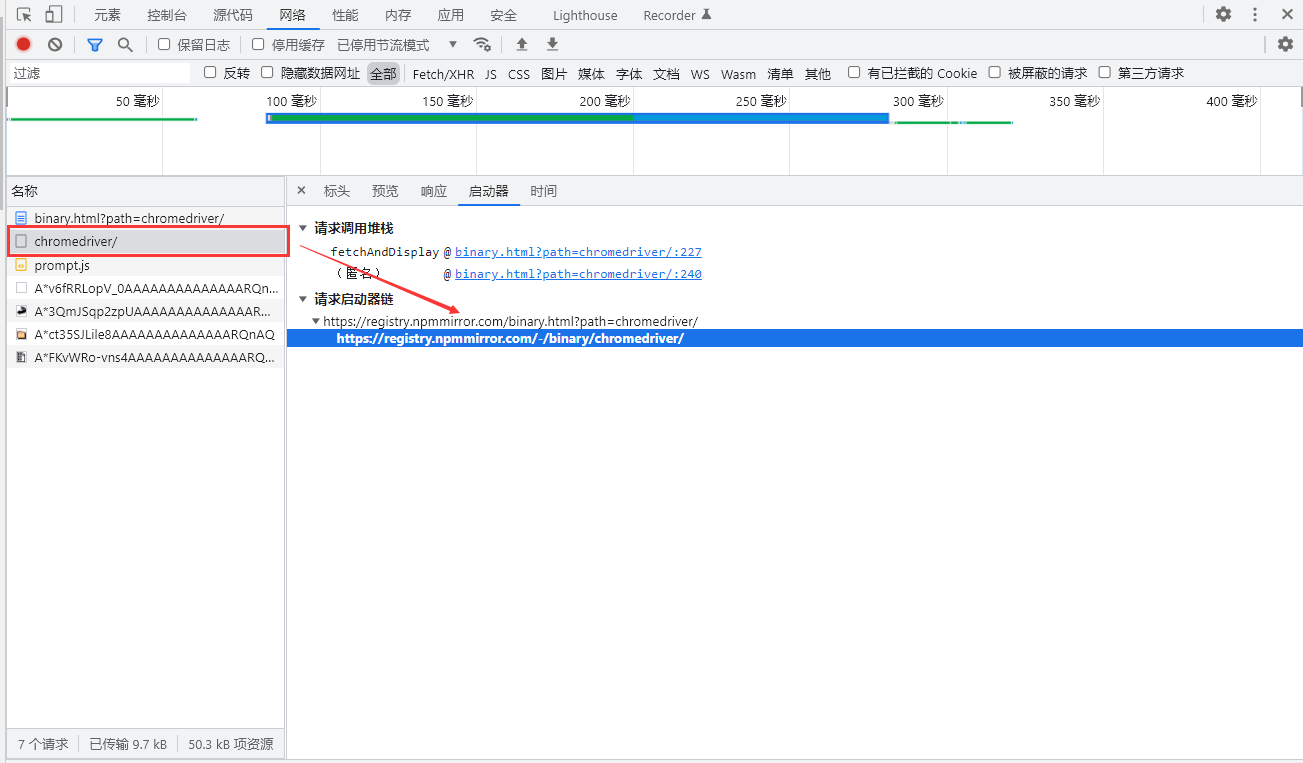
From the above two figures, we can clearly see that the specific request for the version information in the website on the left is as follows: (here you can click the website pasted below me, and you will find that here is a Json format data about the version on the website you want to obtain)
https://registry.npmmirror.com/-/binary/chromedriver/
With these clear, we can build a script to automatically update chrome driver regularly
First, let's clarify the logic of the whole requirement, as shown in the following flow chart:
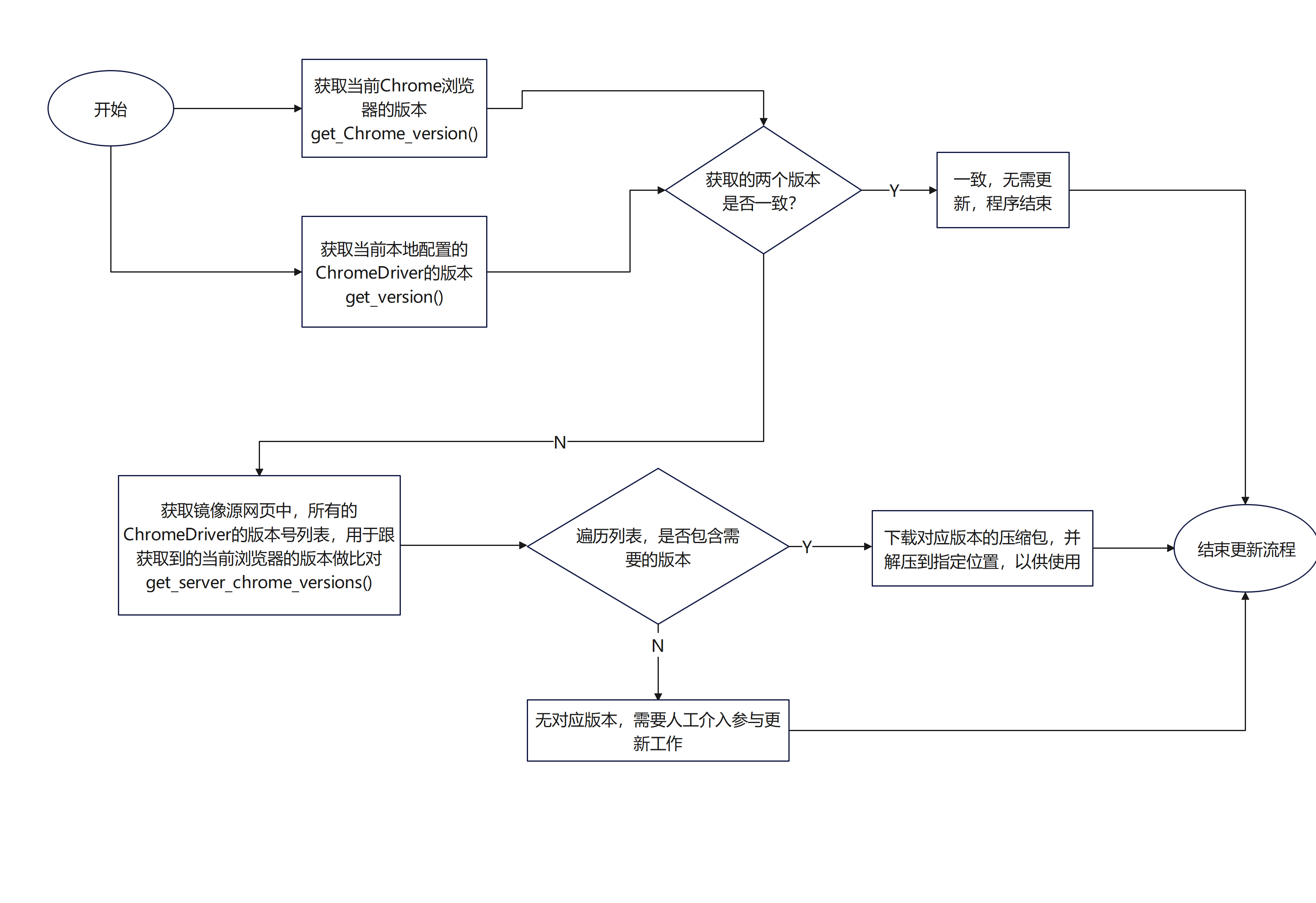
The specific implementation code is as follows, in which several points need to be paid attention to:
- The new image source website protocol is Https. When crawling with requests, pay attention to ignoring the judgment of SSL certificate protocol
- The full version number of Chrome will be inconsistent with the full version number of Chrome driver on the mirror source website. Therefore, when making comparison, we only need to compare the first group of numbers to keep the large version consistent
- The method of obtaining the local path in the code can be used until chrome driver is used. Fill the corresponding path through the method instead of writing an absolute path
# -*- coding:utf-8 -*-
import json
import os
import time
import ssl
import requests
import winreg
import zipfile
from requests.packages.urllib3.exceptions import InsecureRequestWarning
"""ignore SSL Certificate warning"""
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
ssl._create_default_https_context = ssl._create_unverified_context
"""ChromeDriver Warehouse Taobao image address"""
# ChromeDriver_depot_url = r'http://npm.taobao.org/mirrors/chromedriver/'
ChromeDriver_depot_url = r'https://registry.npmmirror.com/binary.html?path=chromedriver/'
ChromeDriver_base_url = r'https://registry.npmmirror.com/-/binary/chromedriver/'
def get_Chrome_version():
"""
Get through the registry Google Chrome Version of
:return: Local machine Chrome Version number of (e.g. 96).0.4664)
"""
key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, r'Software\Google\Chrome\BLBeacon')
version, types = winreg.QueryValueEx(key, 'version')
print("Current of this machine Chrome Version is:", version)
return version
def get_version():
"""
Query the information in the system Chromedriver edition
:return: Local machine ChromeDriver Version of (e.g. 92).0.4515)
"""
ChromeDriverVersion = os.popen('chromedriver --version').read()
print("Current of this machine Chrome Version is:", ChromeDriverVersion.split(' ')[1])
return ChromeDriverVersion.split(' ')[1]
def get_server_chrome_versions(url):
"""
obtain ChromeDriver All versions in the version warehouse and write to the list
:param: Taobao ChromeDriver Warehouse address
:return: versionList Version list
"""
versionList = []
rep = requests.get(url, verify=False).text
rep_list = json.loads(rep)
for i in range(len(rep_list)):
version = rep_list[i]['name'] # Extract version number
versionList.append(version[:-1]) # Save all versions to the list
return versionList
def download_driver(download_url):
"""
Download File
:param download_url: ChromeDriver Corresponding version download address
"""
file = requests.get(download_url, verify=False)
with open("chromedriver.zip", 'wb') as zip_file: # Save the file to the directory where the script is located
zip_file.write(file.content)
print('Download succeeded')
def unzip_driver(path):
"""
decompression Chromedriver Compress the package to the specified directory
:param path: Specify the extraction directory
"""
f = zipfile.ZipFile("chromedriver.zip", 'r')
for file in f.namelist():
f.extract(file, path)
def get_path():
"""
Get current ChromeDriver Storage path of
:return: ChromeDriver current path
"""
ChromeDriverLocating = os.popen('where chromedriver').read()
ChromeSavePath, ChromeName = os.path.split(ChromeDriverLocating)
return ChromeSavePath
def check_update_chromedriver():
chromeVersion = get_Chrome_version()
chrome_main_version = int(chromeVersion.split(".")[0]) # chrome major version number
driverVersion = get_version()
driver_main_version = int(driverVersion.split(".")[0]) # chromedriver major version number
download_url = ""
if driver_main_version != chrome_main_version:
print("chromedriver Version and chrome Browser incompatible, updating>>>")
versionList = get_server_chrome_versions(ChromeDriver_base_url)
if chromeVersion in versionList:
download_url = f"{ChromeDriver_base_url}{chromeVersion}/chromedriver_win32.zip"
else:
for version in versionList:
if version.startswith(str(chrome_main_version)):
download_url = f"{ChromeDriver_base_url}{version}/chromedriver_win32.zip"
break
if download_url == "":
print(r"Unable to find the connection with chrome Compatible chromedriver Version, please http://npm.taobao.org/mirrors/chromedriver /. ")
download_driver(download_url=download_url)
Chrome_Location_path = get_path()
print("The decompression address is:", Chrome_Location_path)
unzip_driver(Chrome_Location_path)
os.remove("chromedriver.zip")
print('Updated Chromedriver Version:', get_version())
else:
print(r"chromedriver Version and chrome Browser compatible, no update required chromedriver edition!")
if __name__ == "__main__":
check_update_chromedriver()
time.sleep(10)
As for the scheduled task, you only need to set a scheduled task on windows. Please Baidu yourself in this step
This article has come to an end. I wish you no ERROR on the code and no BUG on the keyboard!!