Python implementation of stock query
Requirements:
- According to the entered name, the stock is queried fuzzy
- Filter out qualified stocks according to the entered formula. The filter items include: current price, rise and fall range and turnover rate! For example, enter the current price > 30
- Be able to repeatedly query, count and print qualified stocks!
Data source: stock_data.txt
Stock code,Stock name,Current price,Rise and fall,Fluctuation range,Year to date,Turnover,Turnover,turnover rate,P / E ratio(TTM),Dividend yield,market value SH601778,N Crystal family,6.29,+1.92,+43.94%,+43.94%,259.66 ten thousand,1625.52 ten thousand,0.44%,22.32,-,173.95 Hundred million SH688566,Lu Feixue City,52.66,+6.96,+15.23%,+122.29%,1626.58 ten thousand,8.09 Hundred million,42.29%,89.34,-,98.44 Hundred million SH688268,Walter gas,88.80,+11.72,+15.20%,+102.51%,622.60 ten thousand,5.13 Hundred million,22.87%,150.47,-,106.56 Hundred million SH600734,SP Setia ,2.60,+0.24,+10.17%,-61.71%,1340.27 ten thousand,3391.14 ten thousand,2.58%,loss,0.00%,16.18 Hundred million SH900957,Ling Yun B thigh,0.36,+0.033,+10.09%,-35.25%,119.15 ten thousand,42.10 ten thousand,0.65%,44.65,0.00%,1.26 Hundred million SZ000584,Current price intelligence,6.01,+0.55,+9.07%,-4.15%,2610.86 ten thousand,1.53 Hundred million,4.36%,199.33,0.26%,36.86 Hundred million SH600599,Panda financial holding,6.78,+0.62,+10.06%,-35.55%,599.64 ten thousand,3900.23 ten thousand,3.61%,loss,0.00%,11.25 Hundred million SH600524,Wenyi Technology,8.21,+0.75,+8.05%,-24.05%,552.34 ten thousand,4464.69 ten thousand,3.49%,loss,0.00%,13.01 Hundred million SH600520,Huate Technology,6.21,+0.75,+10.05%,-2.05%,552.34 ten thousand,4464.69 ten thousand,3.49%,loss,0.00%,13.01 Hundred million
thinking
-
First, read the txt document data into memory
- It involves multiple queries, so saving it in a dictionary makes the query speed faster
- The first row is obviously different from other rows. It is a header and stored separately in a list. You can use this list to obtain the index value of the entered query item
- There is a space at the end of each line. Use the strip() function to format, and use split('') to cut each line into list format
- Because the ID is unique, the ID is generally used as the key of the dictionary. Here is the "stock code"“
-
If the query can be repeated, use the while loop
- The variable count is introduced to count the query results, and each cycle starts to be cleared
- The input() function accepts input instructions
-
Using regular expressions to judge the validity of formulas
- Use < > to cut the input command
- If the cutting length is 1, the formula format is illegal.
- Fuzzy query of stock name, print results and end the cycle
- Count print the header before the first count to facilitate reading the query results
- If the cutting length is 2, the formula format is legal
- Determine whether the column name is legal if the formula format is legal
- If the column name is legal, judge whether the value is legal
-
The formula is legal, the stock is screened and the results are printed
- Judge whether the input command is < or >, and query in the dictionary according to the judgment resu lt s
- Some values have a percent sign and are formatted with strip('%'),
- The entered value and the value in the dictionary are of character type and need to be converted to float type
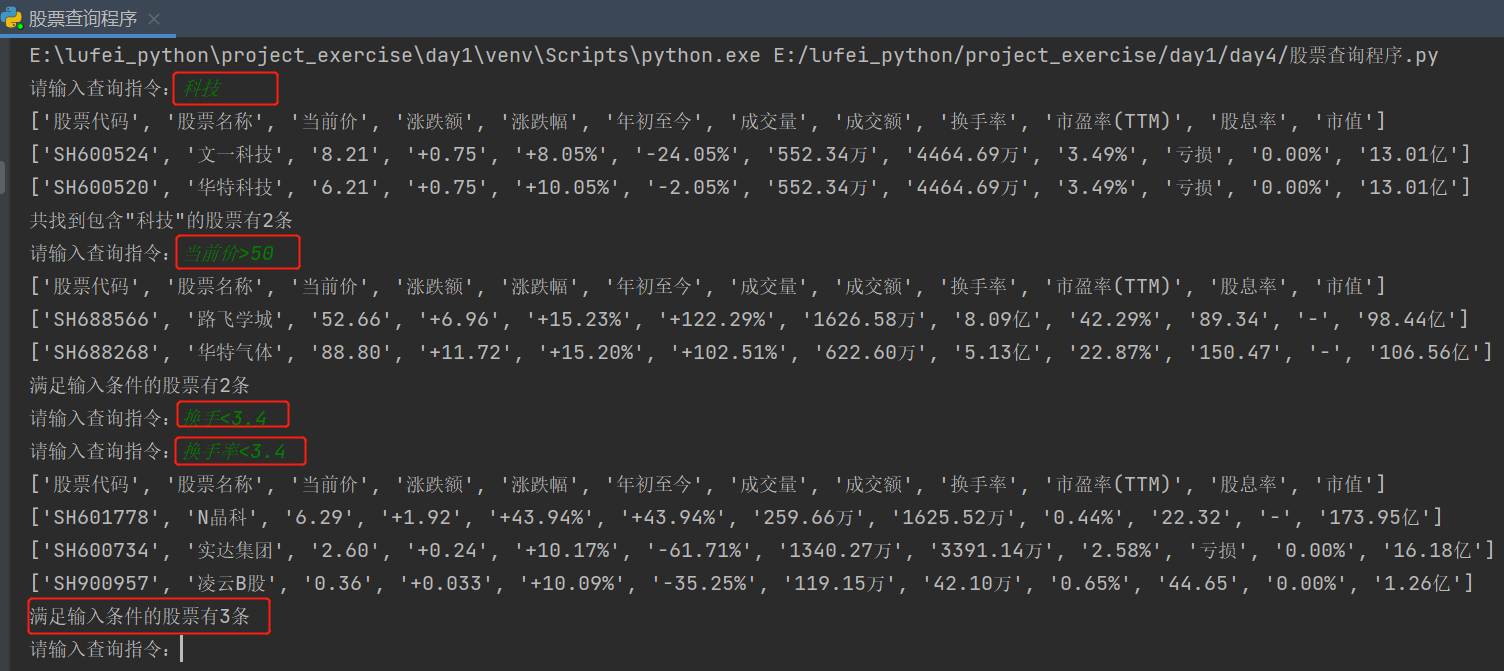
Implementation result example
- Enter * * * "technology" * * * to query the stocks with these two words
- Enter * * * current price > 50 * * * and find 2 records
- Input * * * change hands < 3.4 * * *, because the input column name is less than one word, which is illegal, so it is required to re-enter
- Input * * * turnover rate < 3.4 * * * and filter out 3 records
Complete code implementation
import re #Import the re module and use regular expressions
# ------------Open the file and read the data into the dictionary--------------
s_dict = {} # Store read data, dictionary structure
f = open('stock_data', 'r', encoding='utf-8') #
header = f.readline().strip().split(',') # Read out the header of the first row and store it separately in a list
for line in f:
line = line.strip().split(',')
s_dict[line[0]] = line
f.close()
# for key, value in s_dict.items():
# print(key, value)
# Repeated query must be an endless loop. Use while, user input, and accept an instruction
while True:
count = 0
cmd = input("Please enter the query instruction:")
# ------------Judge the legitimacy of the formula--------------
cmd_parser = re.split("[<>]", cmd) # re module is imported and regular expression is used for cutting
if len(cmd_parser) != 2: # Judge the legitimacy of the formula,
# ------------Fuzzy query stock--------------
for i in s_dict: # Illegal formula, fuzzy stock query
if cmd in s_dict[i][1]:
if count == 0: # Display the header once to facilitate reading the search results, the same below
print(header)
count += 1
print(s_dict[i])
print(f'''Total found contains"{cmd}"What are your stocks{count}strip''')
continue # The formula is illegal. The re-entry instruction is returned after fuzzy query of stocks
if cmd_parser[0] not in ['Current price', 'Fluctuation range', 'turnover rate']: # Judge the legitimacy of the list
continue
try: # Judge the validity of the value. For example, entering the current price > A, a is illegal. If there is no judgment here, Chengxun will report ValueError error
cmd_parser[1] = float(cmd_parser[1])
except ValueError:
continue
# ------------Filter stocks by formula--------------
s_index = header.index(cmd_parser[0]) # Gets the index of the column name from the header
for s_id, s_value in s_dict.items():
if '>' in cmd:
if float(s_value[s_index].strip('%')) > float(cmd_parser[1]):
if count == 0:
print(header)
print(s_value)
count += 1
else:
if float(s_value[s_index].strip('%')) < float(cmd_parser[1]):
if count == 0:
print(header)
print(s_value)
count += 1
print(f"The stocks that meet the input conditions are{count}strip")