Preface
It is a common practice to write a web crawler in Python. The principle is to download the web page, clean the data with regular expressions, and obtain the target resources. It can be text, picture, or other URL. Then it is stored in different categories. This paper is only for simple text extraction.
text
The code is written in Python version 2.7 and can pass the test. The results of the operation are shown below.
# -*- coding: UTF-8 -*-
import urllib2
import re
def ppkao_getanwser(questionURL) :
questionPage = urllib2.urlopen(questionURL).read()
# Analytic topic
questionTypeURL = re.search('The following questions are from:(.*?)<a target="_blank" href="(.*?)" >(.*?)</a>', questionPage, re.S).group(2)
questionType = re.search('The following questions are from:(.*?)<a target="_blank" href="(.*?)" >(.*?)</a>', questionPage, re.S).group(3)
questionTypeID = re.search('ViewAnswers\(\'//(.*?)\',\'(\d+)\'', questionPage, re.S).group(2)
questionModel = re.search('<i class="tx">(.*?)</i>', questionPage, re.S).group(1)
questionName = re.search('<strong class="(.*?)">(.*?)</strong>', questionPage, re.S).group(2)
if questionModel == 'Short answer' :
questionItems = []
else :
questionItems = re.search('</strong>(.*?)</p>', questionPage, re.S).group(1).replace('<p>', '').replace('\t', '').replace('\r\n', '').replace(',<br />', '<br />').split('<br />')
#questionItems = re.search('</strong>(.*?)</p>', questionPage, re.S).group(1).replace('<p>', '').replace('\t', '').replace('\r\n', '').strip().replace(',<br />', '<br />').split('<br />')
# Get answers
anwserURL = re.search('ViewAnswers\(\'//(.*?)\',', questionPage, re.S).group(1)
anwserPage = urllib2.urlopen('https://' + anwserURL).read()
if questionModel == 'Short answer' :
questionAnwser = re.search('<i class="target">Question answer</i>(.*?)<span>(.*?)<p>(.*?)</p>', anwserPage, re.S).group(3).strip()
else :
questionAnwser = re.search('<em class="ture-answer">(.*?)</em>', anwserPage, re.S).group(1).strip()
# Exhibition
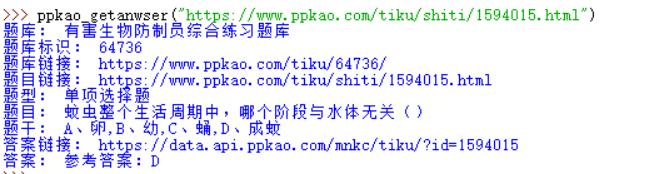
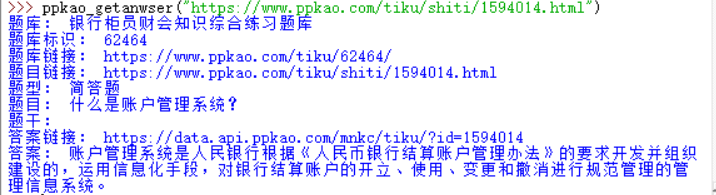
print 'Question bank:', questionType
print 'Item bank identification:', questionTypeID
print 'Question bank link:', questionTypeURL
print 'Title Link:', questionURL
print 'Question type:', questionModel
print 'Title:', questionName
print 'Topic:', ','.join(questionItems)
print 'Answer link:', 'https://' + anwserURL
print 'Answer:', questionAnwsertest result
ppkao_getanwser("https://www.ppkao.com/tiku/shiti/1594015.html")
ppkao_getanwser("https://www.ppkao.com/tiku/shiti/1594014.html")