☘ preface ☘
What can you learn after reading this blog?
- Reading and writing methods of excel
- How to get the interface
- Multithreading improves crawler efficiency
- Cloud server deployment web service real-time update

In this blog, based on the previous article, I will further explore the website interface api to improve the access speed, further explore the faster speed of multithreading, and finally deploy it to the web server to update the ranking list in real time.
Students who have not read the previous article and have no foundation can read the previous article first [python life from scratch ①] user's question brushing data of hand tearing reptiles and raking force buttons
Approximate reading time of the full text: 20min
🧑🏻 About the author: a young man who changed from industrial design to embedded
✨ Contact: 2201891280(QQ)
1, Reasons for improvement
Code improvement of the previous article (mainly using headless mode without displaying the screen to improve the speed):
ch_options = webdriver.ChromeOptions()
# Configure headless mode for Chrome
ch_options.add_argument("--headless")
ch_options.add_argument('--no-sandbox')
ch_options.add_argument('--disable-gpu')
ch_options.add_argument('--disable-dev-shm-usage')
ch_options.add_argument('log-level=3')
ch_options.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
ch_options.add_experimental_option('useAutomationExtension', False)
ch_options.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=ch_options)
driver.implicitly_wait(10)
🚨 1. Time efficiency
The following is a screenshot of my running time on raspberry pie 4B. 900s, which is not acceptable on the server
 >## 🎶 2. Resource occupation >
>## 🎶 2. Resource occupation >
This is the resource occupation of my computer when it is running. If the server is running, it will burst directly... It may cause my own web service to stop responding.
2, Acquisition of interface
1. Find query information
First visit your home page and press f12 to enter the developer tool
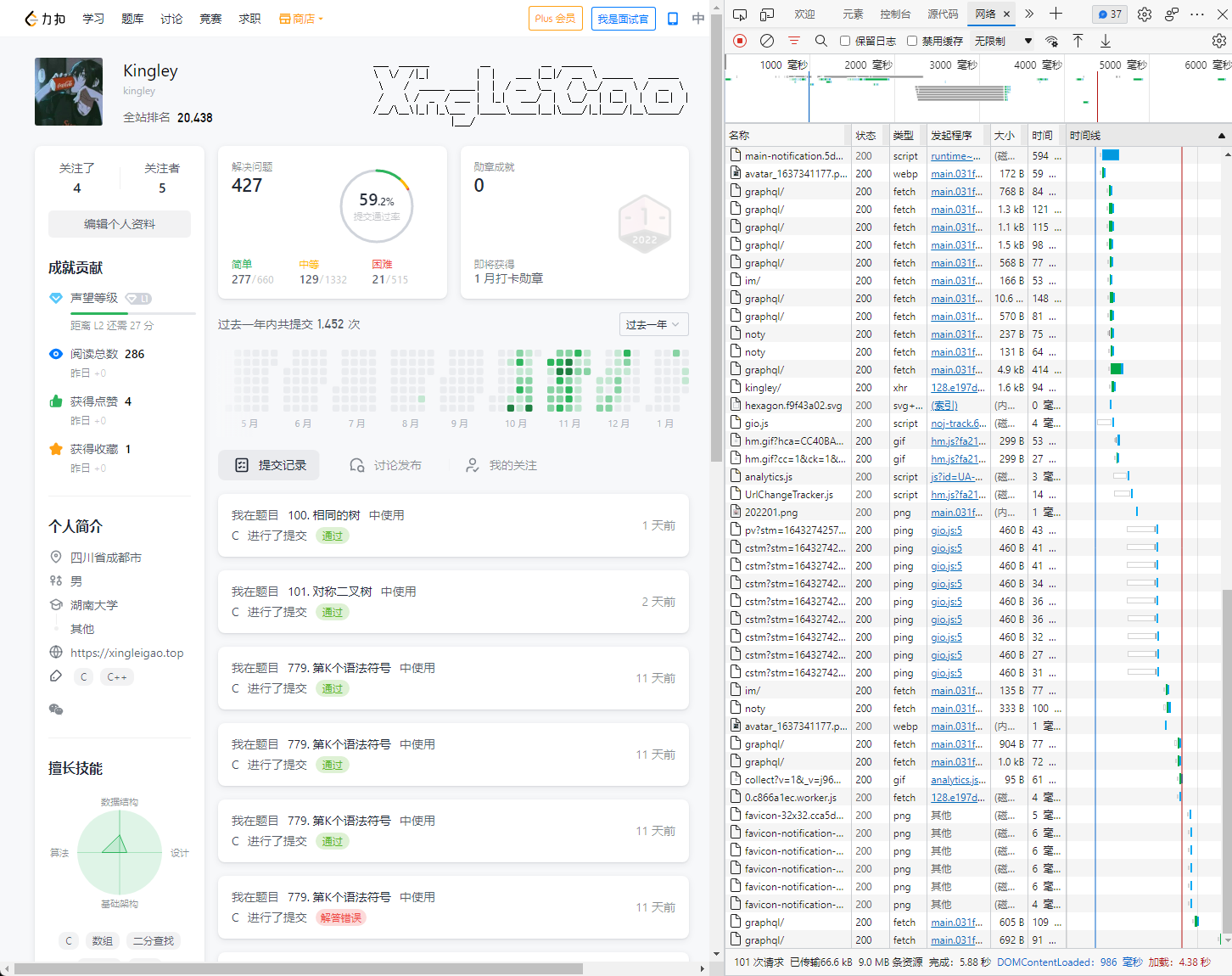
Press ctrl+f to find the number of questions you brush
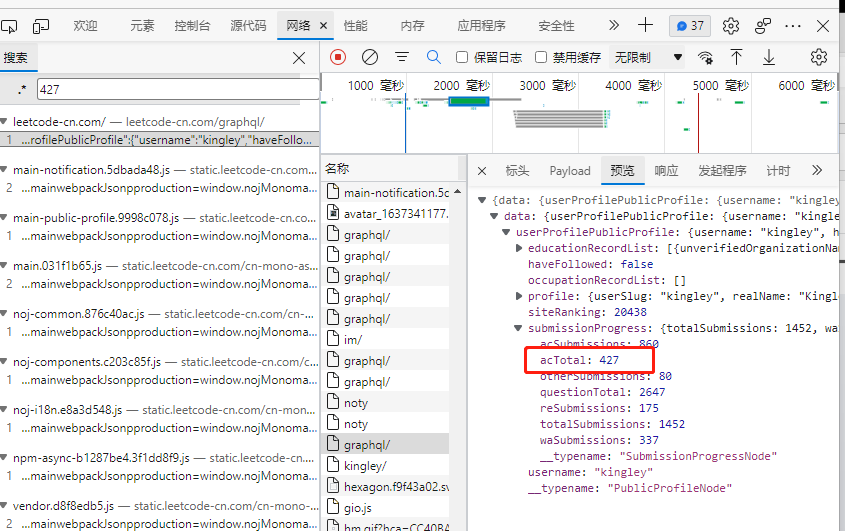
You can successfully find that the corresponding keyword is acTotal, and the corresponding request is to look at the header.
2. Determine the incoming parameters
2.1 determining header information

The address where the header can be found is https://leetcode-cn.com/graphql/ , let's post directly to see the feedback.
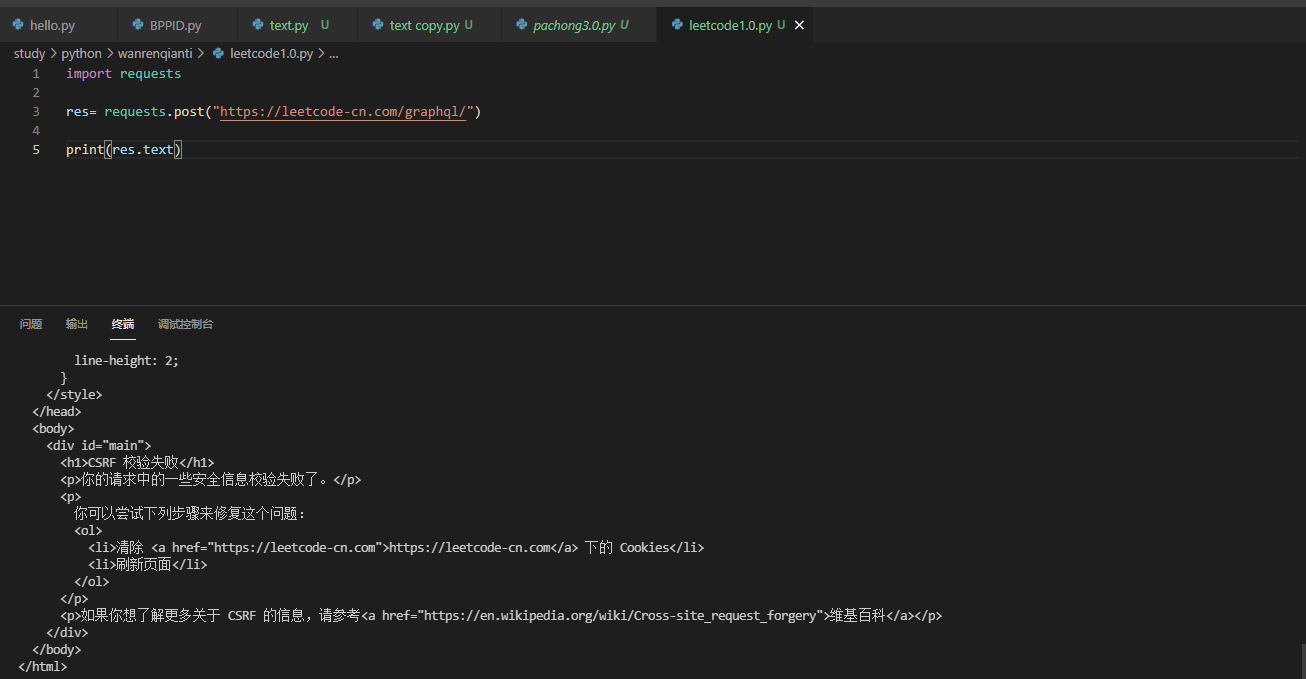
The picture above tells us that I didn't give him CSRF verification.
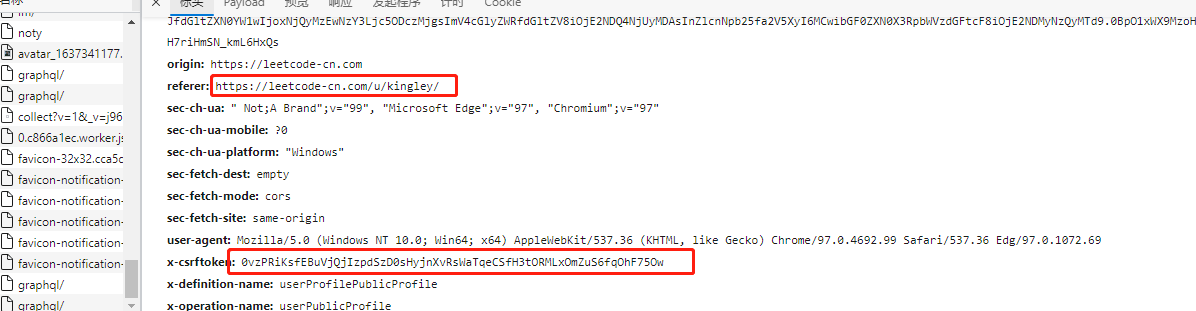
Our normal request parameters are here, actually in the header. Generally, this kind of website also needs to apply for website information, so we can send the corresponding header information to it.
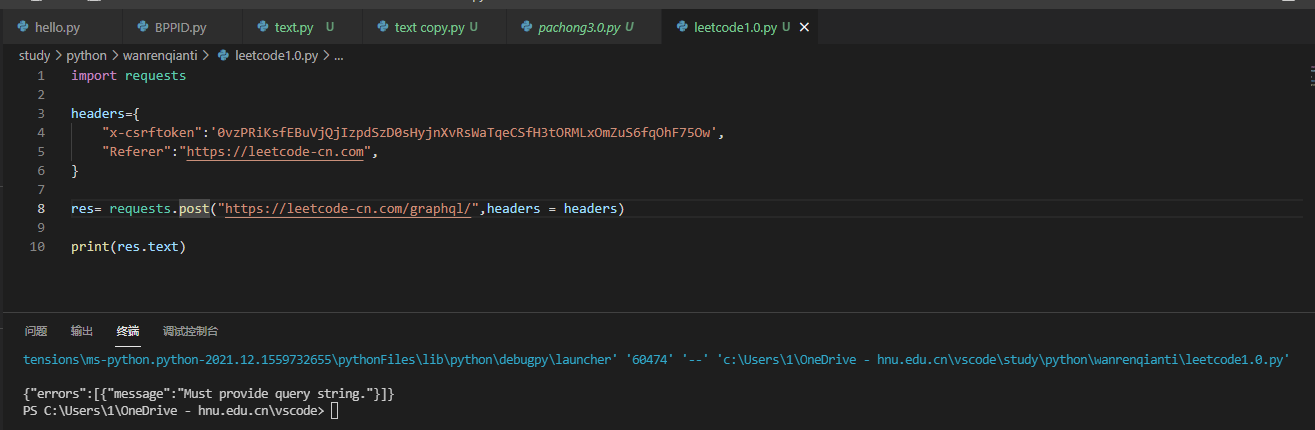
Now we have successfully given the header, prompting us to pass the parameter error. We didn't pass the parameter at all, 233
2.2 determining transmission parameters
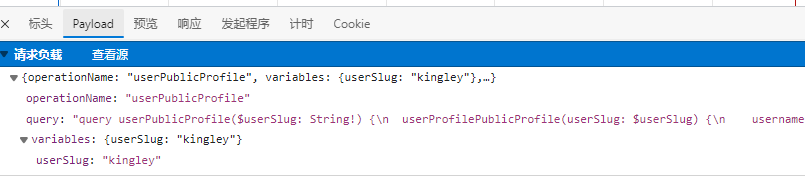
Check the payload to find the main transmission data. We copy it and send it to the corresponding website as data:
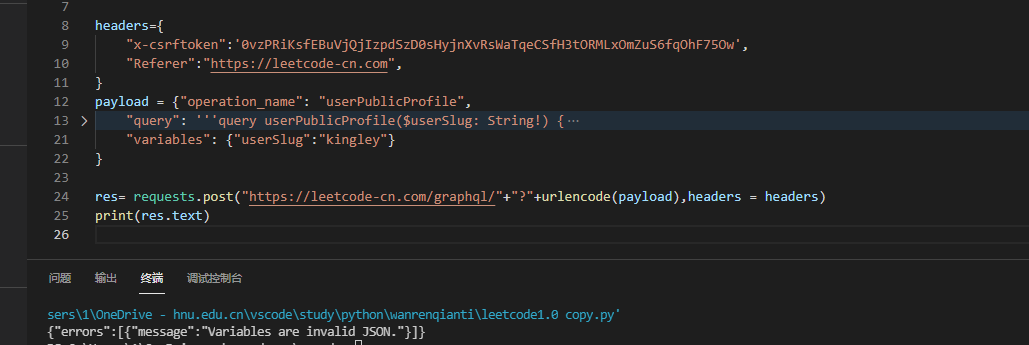
The error message tells me that variables do not meet the requirements, ah, this??? In fact, you need to change the value of variables into a string:
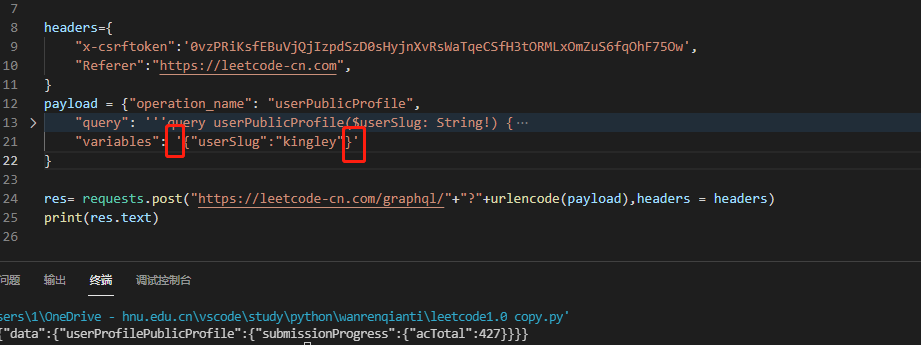
Well, we've got the data we need, but it's too complicated. You can find that the query results all depend on the query field. Let's simplify it:
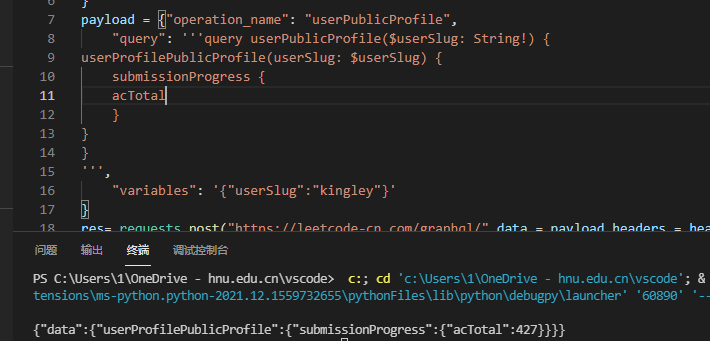
Without destroying the hierarchy, it is streamlined to the extreme, and the returned information is only the data we want
Let's modify the value of the returned data again, and it's perfect.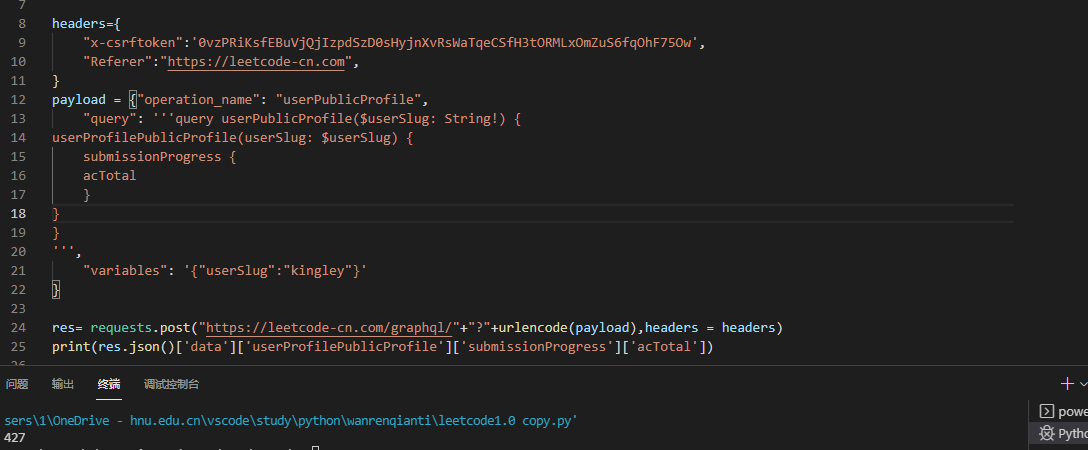
For convenience, we encapsulate the query information according to the name into a function and verify it
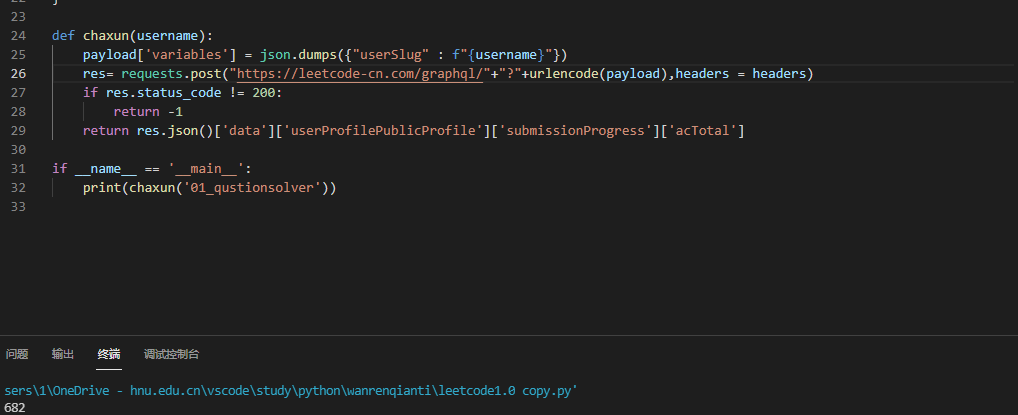
3, Data read in and query write back
1. Data reading and query
In fact, we finished reading the relevant data last time, but this time we only need the user's name. So we have a little change. We read in the data and directly output 0 if it does not meet the requirements
If it meets the requirements, we need to find the user name from it and analyze the link to find / u / {user name} /, so we can extract the corresponding user name with regular expression

At this time, the corresponding data can be output
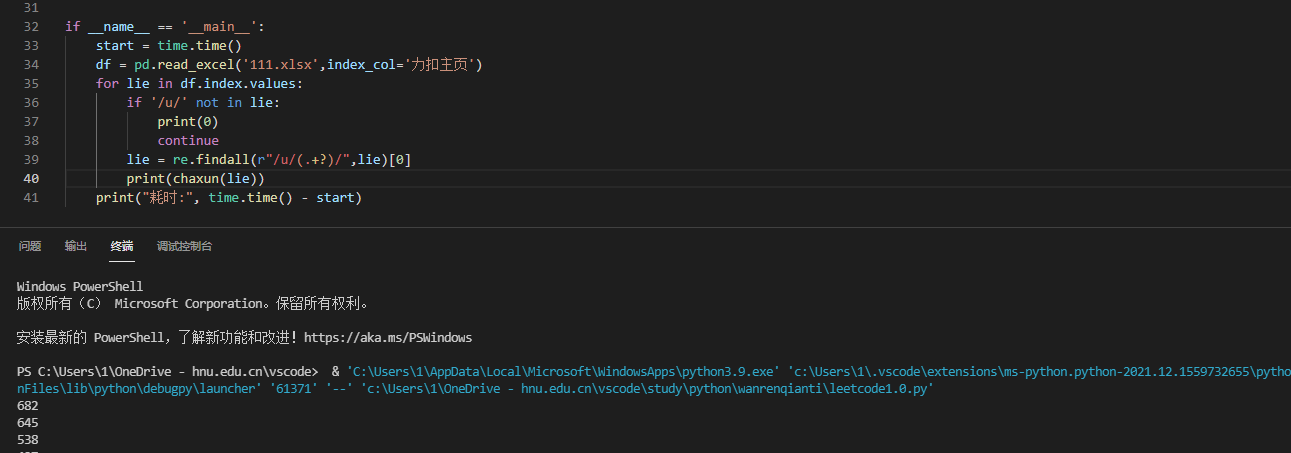
2. Write back of data
At first, in order to copy back Tencent documents, I directly used txt as output, which is very simple:
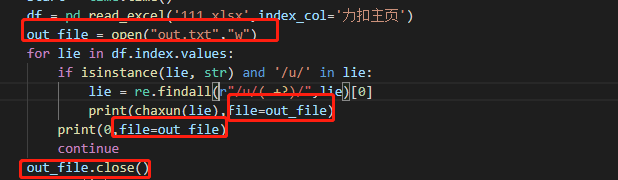

It can be found that in this case, the cpu load is very low and the speed has been greatly improved, but we know that requests are to access network resources, and the main problem of limiting time is network waiting, so we prefer to use multi-threaded concurrent requests to meet the requirements of improving program speed.
4, Multithreaded request information
Thanks to Minglao's guidance here, which saves a lot of trouble @Xiaoming - code entity
First, introduce the ThreadPoolExecutor Thread Library:
Import:
from concurrent.futures import ThreadPoolExecutor
Create thread library:
with ThreadPoolExecutor(max_workers=10) as executor:
Return the results in order and receive:
nums = executor.map(chaxun, df.Force buckle home page.str.extract(
r"leetcode-cn.com/u/([^/]+)(?:/|$)", expand=False))
The second parameter is the passed in parameter list, and map can be output in the order of input.
As long as we convert the returned nums into a list, we can get the results in the previous order.
Overall function:
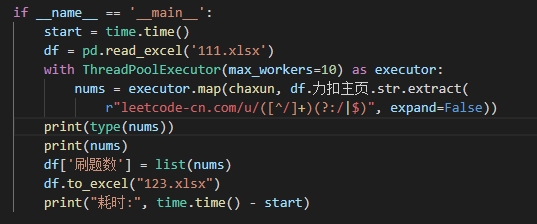
Time consuming: >Results obtained
>Results obtained
5, Writing of web front end
Thanks for the hard work of Minglao: @Xiaoming - code entity
pandas can generate html files directly by default. We need to modify it a little
1. Default generation result:
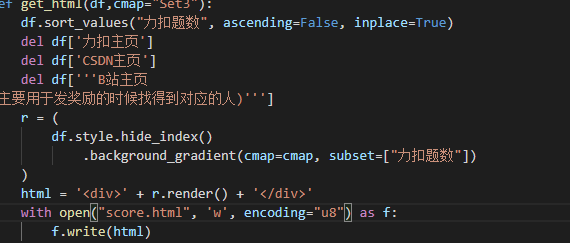

2. Change to the color display of the whole line
To view the generated stylesheet, we need to change the corresponding value #T_18e34_row0_col3 becomes row0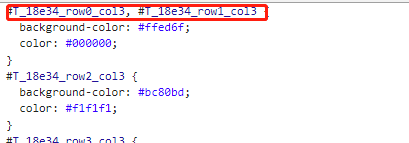
Use regular expressions to replace (I really don't understand it here. It's still Minglao who asks for help, Minglao yyds!!!)
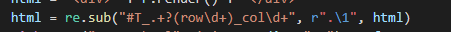
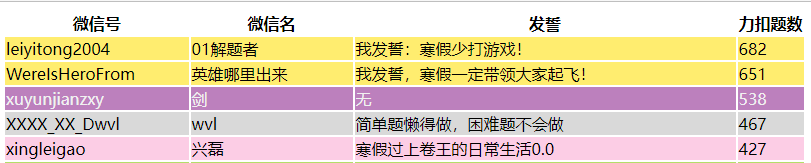
3. Improve the style sheet
Finally, add the display mode you want to customize, and then return the corresponding html information.
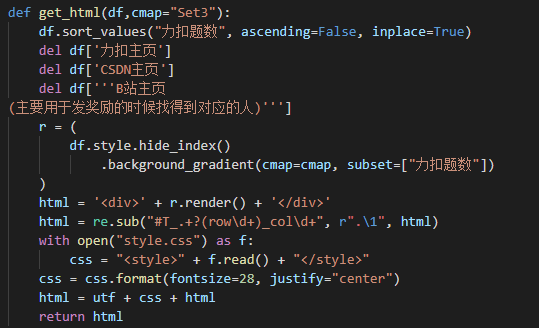
6, Other supplements
1. Acquisition of CSRF
requests can directly obtain a cookie, which we can extract from cookies
def int_csrf():
global headers
sess= requests.session()
sess.head("https://leetcode-cn.com/graphql/")
headers['x-csrftoken'] = sess.cookies["csrftoken"]
2. The web server writes the static page address directly

It can be directly written to the root directory of the corresponding web page and accessed directly. The effect can be seen Mobile version of ten thousand questions list
3. Presentation page on computer side
The resolution of the computer and mobile phone is different, so the display effect is different. So we made some PC side pages separately and used the embedded method to browse the data. In fact, ifame is used for nesting and scaling.
<style>
.iframe-body-sty{position: relative;overflow: hidden;height:700px;width: 500px;background-color:#FFF;}
.iframe-body-sty>#iframe-shrink{position: absolute;transform:scale(0.43);left: -620px;top: -550px;height:1900px;max-width:1600px;width: 1600px;}
</style>
<div class="iframe-body-sty">
<iframe id="iframe-shrink" src="https://www.xingleigao.top/score.html"></iframe>
</div>
The final effect can be seen as follows: List of thousands of questions for 10000 people on PC
4. Regular update of data
Use sh to perform corresponding operations
cd /home/leetcode date >> log.txt python3 leetcode.py >> log.txt 2>&1
Using cron for scheduled tasks
crontab -e

7, Write at the end
The whole optimization process is relatively smooth this time, and I have learned a lot from a little white who doesn't understand anything. If you have any questions, please criticize and correct them. Here is the complete code:
"""
Xinglei's code
CSDN Home page: https://blog.csdn.net/qq_17593855
"""
__author__ = 'Xing Lei'
__time__ = '2022/1/27'
import pandas as pd
import re
import time
from urllib.parse import urlencode
import requests
import json
from concurrent.futures import ThreadPoolExecutor
headers={
"x-csrftoken":'',
"Referer":"https://leetcode-cn.com",
}
utf = '''
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<script>
var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?f114c8d036eda9fc450e6cbc06a31ebc";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
</script>
'''
payload = {"operation_name": "userPublicProfile",
"query": '''query userPublicProfile($userSlug: String!) {
userProfilePublicProfile(userSlug: $userSlug) {
submissionProgress {
acTotal
}
}
}
''',
"variables": '{"userSlug":"kingley"}'
}
def int_csrf():
global headers
sess= requests.session()
sess.head("https://leetcode-cn.com/graphql/")
headers['x-csrftoken'] = sess.cookies["csrftoken"]
def chaxun(username):
payload['variables'] = json.dumps({"userSlug" : f"{username}"})
res= requests.post("https://leetcode-cn.com/graphql/"+"?"+urlencode(payload),headers = headers)
if res.status_code != 200:
return -1
return res.json()['data']['userProfilePublicProfile']['submissionProgress']['acTotal']
def get_html(df,cmap="Set3"):
df.sort_values("Number of force deduction questions", ascending=False, inplace=True)
del df['Force buckle home page']
del df['CSDN homepage']
del df['''B Station home page
(It is mainly used to find the corresponding person when giving rewards)''']
r = (
df.style.hide_index()
.background_gradient(cmap=cmap, subset=["Number of force deduction questions"])
)
#print(r.render())
html = '<div>' + r.render() + '</div>'
html = re.sub("#T_.+?(row\d+)_col\d+", r".\1", html)
with open("style.css") as f:
css = "<style>" + f.read() + "</style>"
css = css.format(fontsize=28, justify="center")
html = utf + css + html
return html
if __name__ == '__main__':
int_csrf()
df = pd.read_excel('111.xlsx')
#Read an entire column of data
start = time.time()
with ThreadPoolExecutor(max_workers=10) as executor:
nums = executor.map(chaxun, df.Force buckle home page.str.extract(
r"leetcode-cn.com/u/([^/]+)(?:/|$)", expand=False))
df['Number of force deduction questions']=list(nums)
with open("/www/xxxx/score.html", 'w', encoding="u8") as f:
f.write(get_html(df))
print("time consuming:", time.time() - start)
Finally, thank you very much!! yyds