preface
Crawler is a good thing. I want to use it recently, so I'll send out the previous little things and write a few blogs~
Synergetic process
First of all, it is clear that the thread is not multi-threaded, and the thread is still a single thread in essence. However, the characteristic of this thread is that when the current thread enters the IO state, the CPU will automatically switch tasks, so as to improve the overall operation efficiency of the system. Yes, this cooperation process is actually the same as the multi-channel processing mechanism of the operating system. The implementation effect is a bit similar to using multithreading or thread pool, but the coroutine is more lightweight. In essence, it is a single thread switching back and forth.
Xiecheng gets started quickly
Then let's first experience the efficacy of this collaborative process.
To use CO process in python, that is, asynchronous, we need to master two keywords, await and async. Of course, there is also a library that supports collaborative processes, asyncio.
Let's look at the code first.
import asyncio
import time
# Co process function
async def do_some_work(x):
print('doing: ', x)
await asyncio.sleep(2)
return 'done {}'.format(x)
# Co process object
xs = [1,2,3]
# Turn the collaborative process into task and form a list
tasks = []
start = time.time()
for x in xs:
c = do_some_work(x)
tasks.append(asyncio.ensure_future(c))
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time()-start
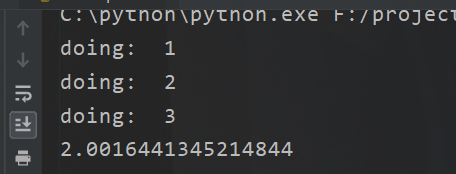
At first glance, it seems that we have implemented multithreading. Well, I'll change the code.
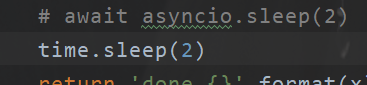
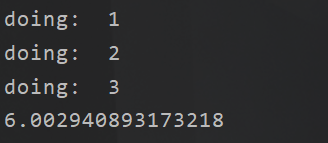
See, it's 6 seconds. How can this happen? If it's multithreaded, it must be 2 seconds. So a coroutine is not multithreaded. This is the first point
Well, since it's not multithreaded, why is it just two seconds.
Concurrent asynchronous operation
This is actually very simple. Before that, we have to talk about a method
asyncio.sleep(2)
What's special about this? Yes, the special point is that this sleep is equivalent to io operation, so do you understand what I mean
This sleep is the IO operation
We have three asynchronies here, and all the IO S are handed over to the system for execution, so we only spent 2 seconds in the end.
Workflow
Well, now that we have experienced this result, it's time for us to talk about why.
First, the first keyword async is to declare this method. The code block is an asynchronous thing, which is equivalent to declaration
What does await mean? This is why we are the "secret" of two seconds. This gadget, when it is found that the thing decorated by it is a time-consuming IO operation, it will tell the operating system to perform IO operation and let the CPU switch other tasks. There can be multiple tasks in a single threaded program.
task management
We talked about the two keywords, so the question is, who will tell the operating system and who will work for me. asyncio is needed at this time.
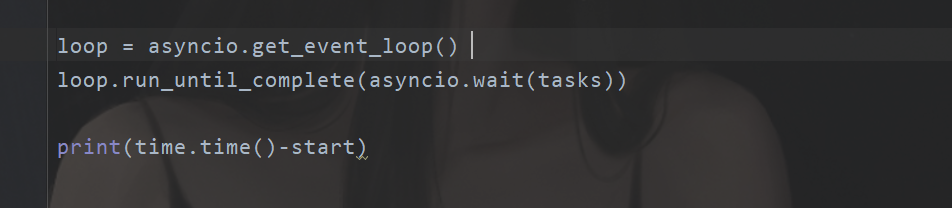
Yes, that's the code.
Of course, there are many ways to create a collaborative process, but this one is used more in crawlers, so I only write this one here. In fact, there are three. (this is similar to the furtertask in java)
aiohttp
Now it's time for our asynchronous crawling. Request one, what are the crawling resources? This is actually an IO operation. So we can use asynchrony, but at this time, we can't use requests anymore.
You have to use this. Download it first
pip install aiohttp
import asyncio
import time
import aiohttp
#Just visit the bing homepage three times
urls = ["https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1"]
async def get_page(url):
print("Start crawling website", url)
#Asynchronous blocks can only be switched when await is added when executing asynchronous methods, otherwise it is serial
async with aiohttp.ClientSession() as session:
async with await session.get(url) as resp:
page = await resp.text()
print("Crawling completed->",url)
return page
tasks = []
start = time.time()
for url in urls:
c = get_page(url)
tasks.append(asyncio.ensure_future(c))
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time()-start)
Well, the aiohttp thing, how to say, there are many methods similar to requests. For example, the method just mentioned is similar to requests Session () is the same (highly similar)
Asynchronous save
I've said this. Of course, there are aiofiles
import asyncio
import time
import aiohttp
import aiofiles
#Just visit the bing homepage three times
urls = ["https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1"]
async def get_page(url):
print("Start crawling website", url)
#Asynchronous blocks can only be switched when await is added when executing asynchronous methods, otherwise it is serial
async with aiohttp.ClientSession() as session:
async with await session.get(url) as resp:
page = await resp.text()
print("Crawling completed->",url)
# async with aiofiles.open("a.html",'w',encoding='utf-8') as f:
# await f.write(page)
# await f.flush()
# await f.close()
with open("a.html",'w',encoding='utf-8') as f:
f.write(page)
f.flush()
f.close()
return page
tasks = []
start = time.time()
for url in urls:
c = get_page(url)
tasks.append(asyncio.ensure_future(c))
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time()-start)
First of all, this is not necessarily better than directly writing file blocks, and some third-party libraries do not support it!
Asynchronous callback
Now we save the file asynchronously. The problem comes. I want to get the result directly and analyze it. So we need an asynchronous callback.
import asyncio
import time
import aiohttp
import aiofiles
#Just visit the bing homepage three times
urls = ["https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1",
"https://cn.bing.com/?FORM=Z9FD1"]
async def get_page(url):
print("Start crawling website", url)
#Asynchronous blocks can only be switched when await is added when executing asynchronous methods, otherwise it is serial
async with aiohttp.ClientSession() as session:
async with await session.get(url) as resp:
page = await resp.text()
print("Crawling completed->",url)
return page
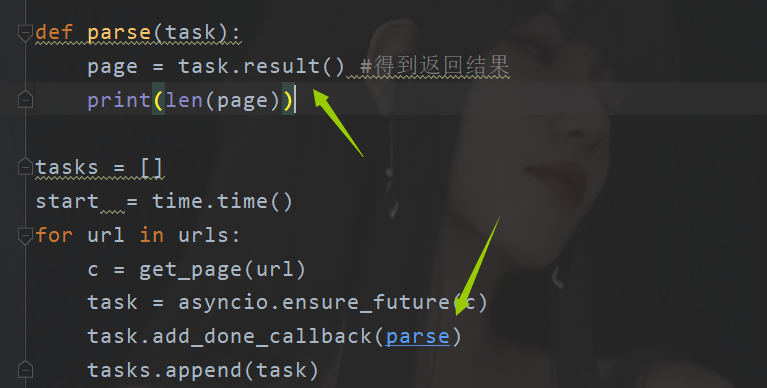
def parse(task):
page = task.result() #Get return results
print(len(page))
tasks = []
start = time.time()
for url in urls:
c = get_page(url)
task = asyncio.ensure_future(c)
task.add_done_callback(parse)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
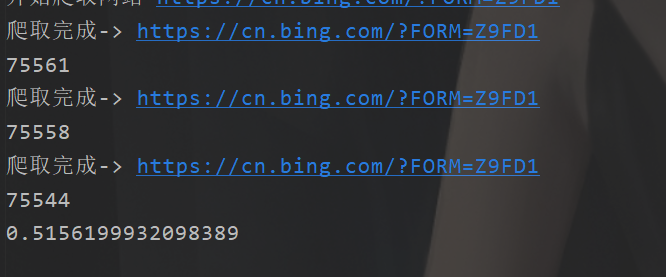
print(time.time()-start)
Well, this is the asynchronous thing. Here's why I use the future task, because I can get the parameters. In java, it's the calllabel.
Next, there is a divine tool, scapy, which will be updated later (it depends, it's Friday!)