preface
I found a video of Python multiprocess, multithreading and multiprocessing in station B (see reference 2). It didn't take long, but I felt it was pretty good. This article is just a simple note.
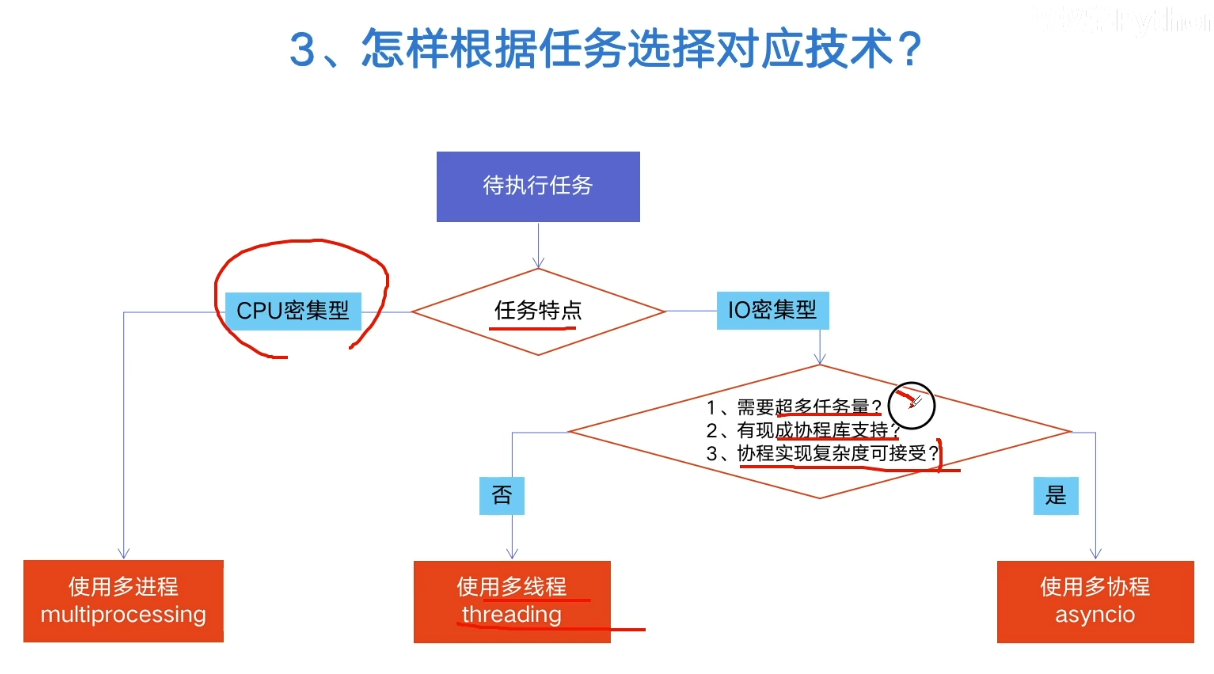
How to select multi process, multi thread and multi co process
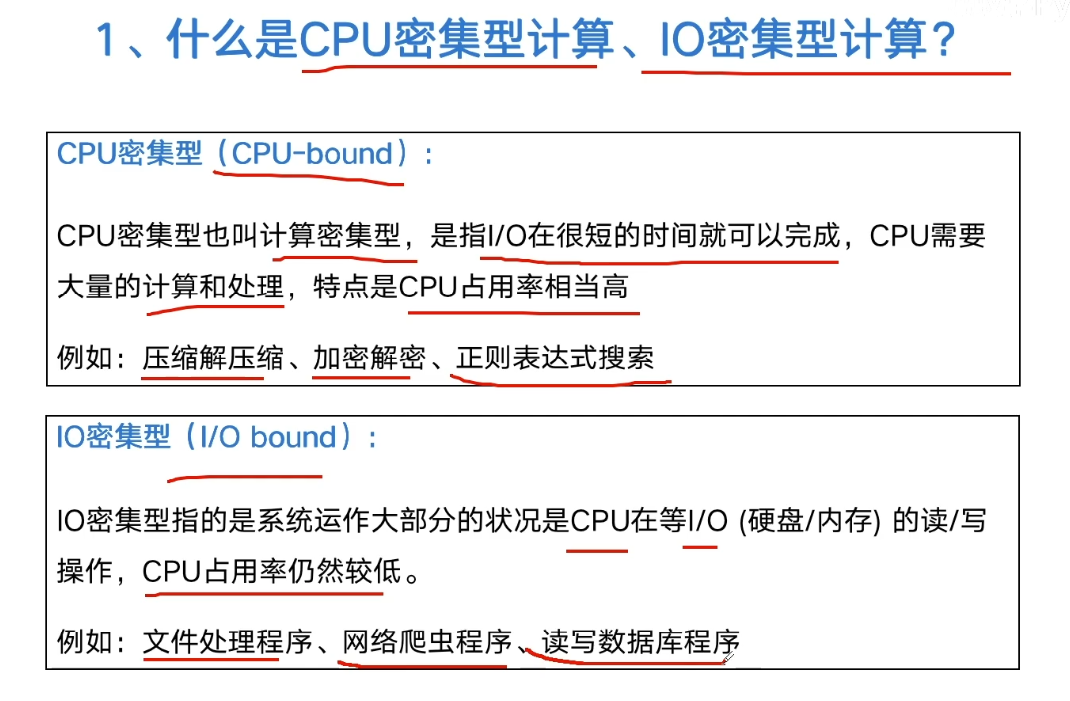
CPU intensive, IO intensive computing
Comparison of multiprocess, multithread and multiprocess
- multiprocessing
- Multithreading (threading)
- Multi process Coroutin (asyncio)

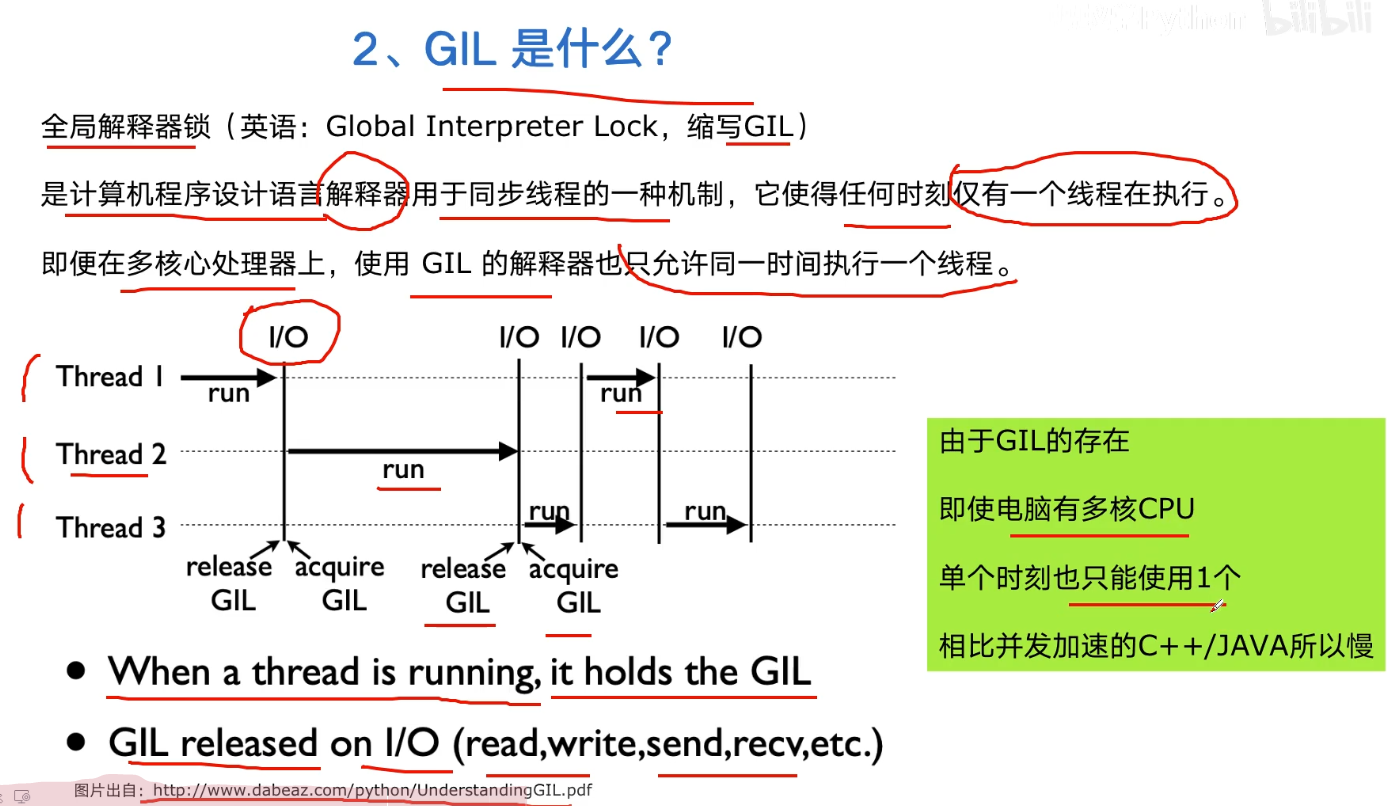
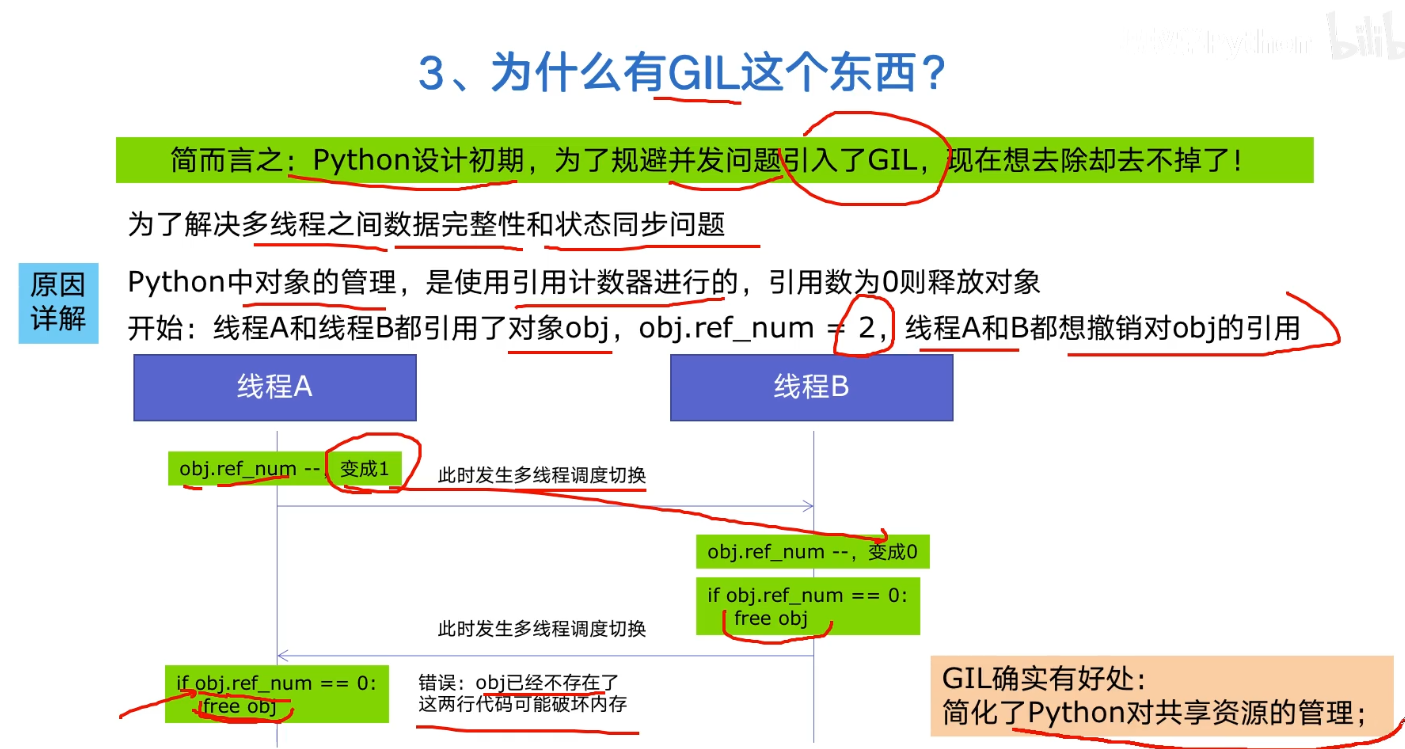
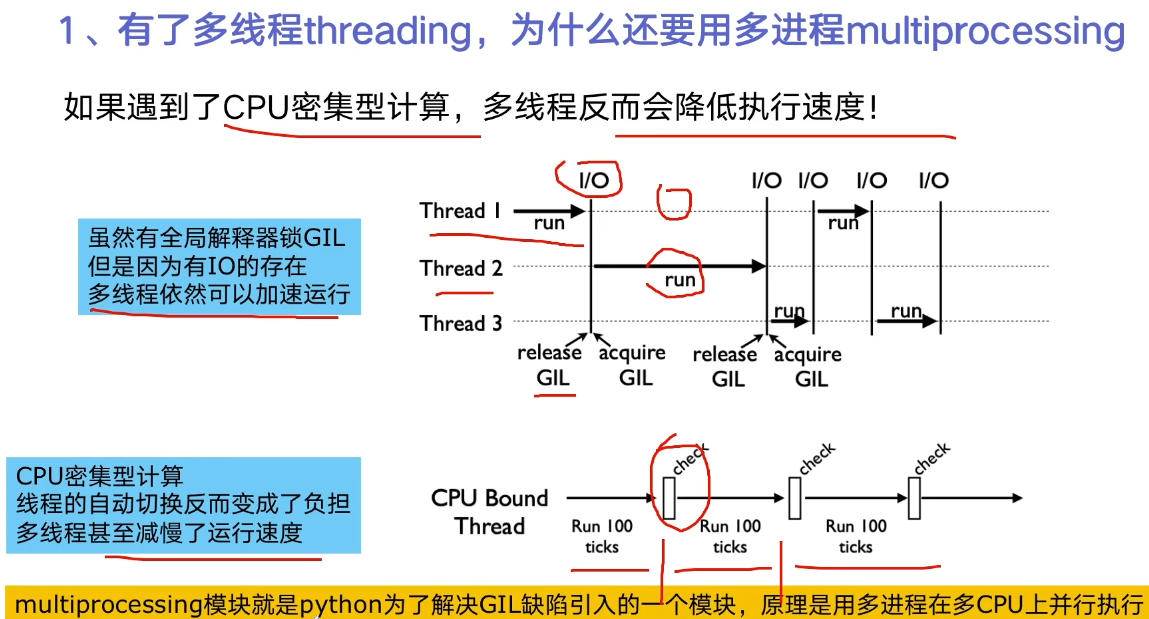
Python global interpreter lock GIL
Python is slow for two reasons:
- Dynamically typed language (interpretive language)
- The existence of GIL makes Python unable to execute concurrently with multi-core CPU

Accelerating crawlers with multithreading
target passes in the name of the function, and the parameters passed later are tuples

import requests
urls = [
f"https://www.cnblogs.com/#p{page}"
for page in range(1, 50+1)
]
# print(urls)
def craw(url):
r = requests.get(url)
print(url, len(r.text))
craw(urls[0])
# multi_thread.py
import blog_spider
import threading
import time
def single_thread():
print("single_thread begin")
for url in blog_spider.urls:
blog_spider.craw(url)
print("single_thread end")
def multi_thread():
print("multi_thread begin")
threads = []
for url in blog_spider.urls:
threads.append(
threading.Thread(target=blog_spider.craw, args=(url, ))
)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print("multi_thread begin")
if __name__ == "__main__":
start = time.time()
single_thread()
end = time.time()
print("single thread cost:", end-start, "seconds")
start = time.time()
multi_thread()
end = time.time()
print("multi thread cost:", end - start, "seconds")
Python implements producer consumer crawler
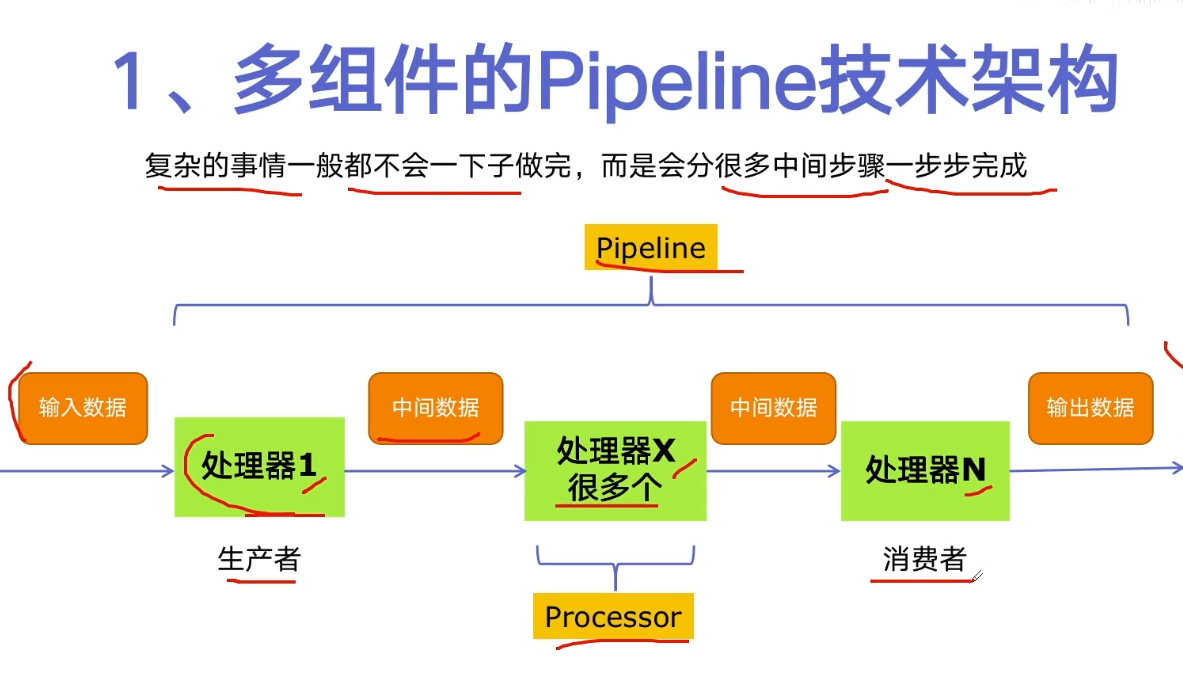
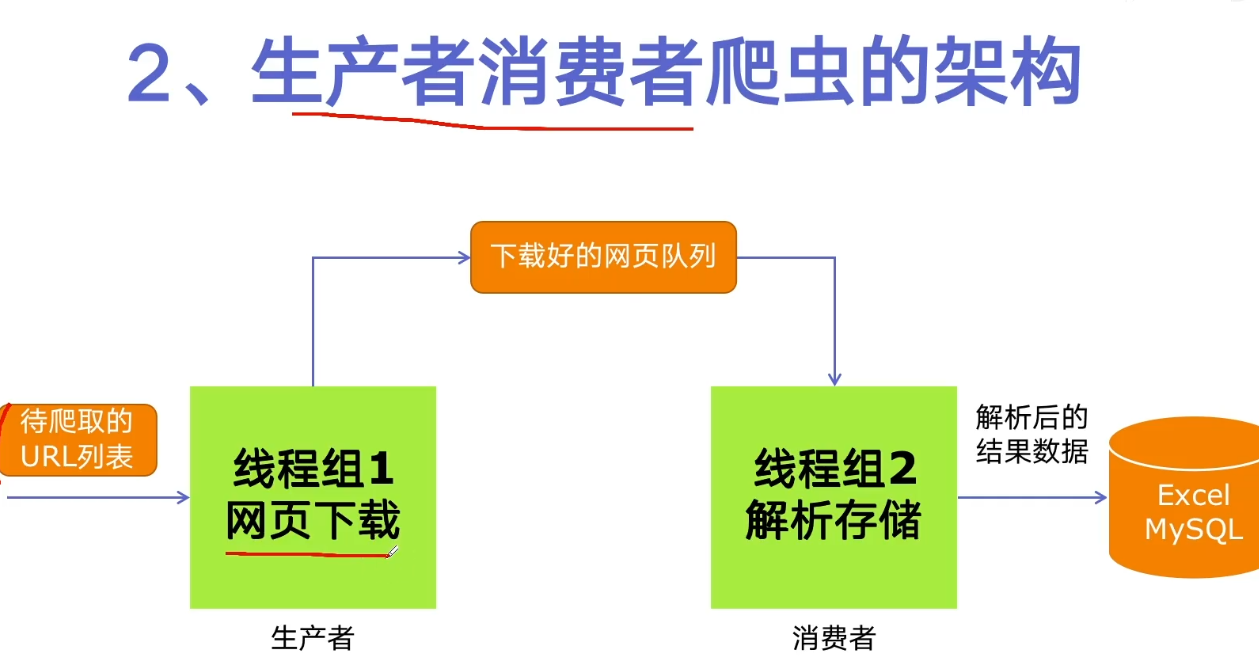

Locate the class where the title is located

Complete code
# _*_ coding=utf-8 _*_
import queue
import blog_spider
import time
import random
import threading
def do_craw(url_queue:queue.Queue, html_queue:queue.Queue):
while True:
url = url_queue.get()
html = blog_spider.craw(url)
html_queue.put(html)
print(threading.current_thread().name, f"craw {url}",
"url_queue.size=", url_queue.qsize())
time.sleep(random.randint(1, 2))
def do_parse(html_queue:queue.Queue, fout):
while True:
html = html_queue.get()
results = blog_spider.parse(html)
for result in results:
fout.write(str(result) + "\n")
print(threading.current_thread().name, f"result.size", len(results),
"html_queue.size=", html_queue.qsize())
time.sleep(random.randint(1, 2))
if __name__ == "__main__":
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in blog_spider.urls:
url_queue.put(url)
for idx in range(3):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f"craw{idx}")
t.start()
fout = open("producer_consumer_data.txt", 'w')
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f"parse{idx}")
t.start()
Thread safety problems and Solutions
Thread safety problem, example: bank withdrawal
You can use Lock to solve thread safety problems

Code before locking
# _*_ coding=utf-8 _*_
import threading
import time
class Account:
def __init__(self, balance):
self.balance = balance
def craw(account, amount):
if account.balance >= amount:
time.sleep(0.1) # Thread problems can be seen more clearly
print(threading.current_thread().name, "Successful withdrawal")
account.balance -= amount
print(threading.current_thread().name, "The balance is", account.balance)
else:
print(threading.current_thread().name, "Insufficient balance, withdrawal failed")
if __name__ == "__main__":
account = Account(1000)
ta = threading.Thread(name='ta', target=craw, args=(account, 800))
tb = threading.Thread(name='tb', target=craw, args=(account, 800))
ta.start()
tb.start()
This output is too messy...

After the lock is added (two lines of code are added)
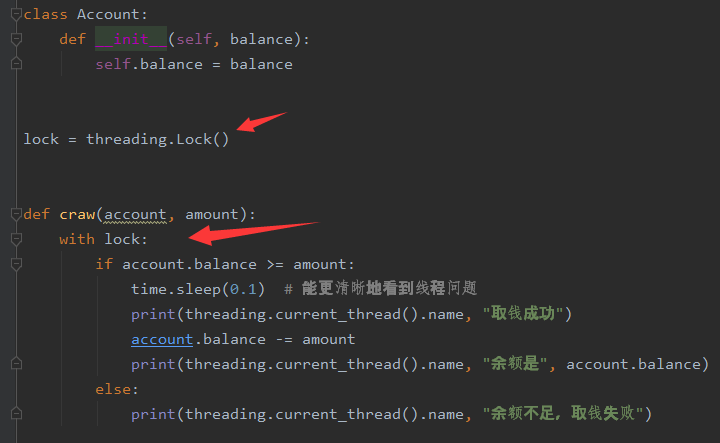
The output is also normal

Easy to use thread pool ThreadPoolExecutor
- New: completely immobile state
- Ready: system scheduling is required
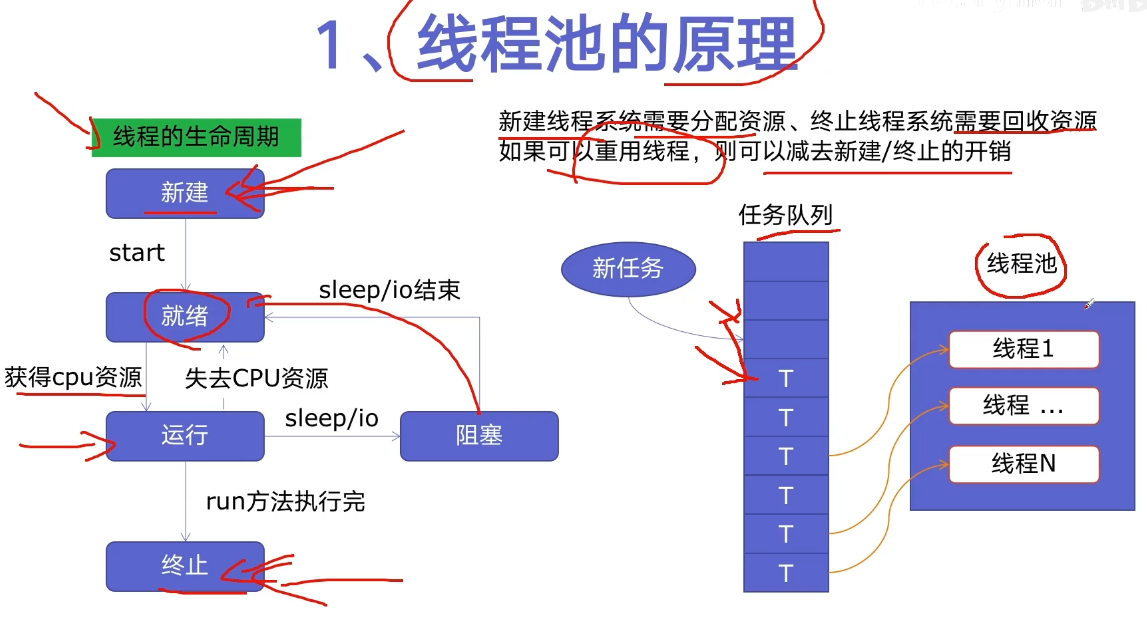


as_ The completed () method is a generator. When no task is completed, it will block. When a task is completed, it will yield the task, so that the following statements of the for loop can be executed, and then continue to block until all tasks are completed. It can also be seen from the results that the main thread will be notified of the tasks completed first.
Code of this section:
# _*_ coding=utf-8 _*_
import concurrent.futures
import blog_spider
# craw
with concurrent.futures.ThreadPoolExecutor() as pool:
htmls = pool.map(blog_spider.craw, blog_spider.urls)
htmls = list(zip(blog_spider.urls, htmls))
for url, html in htmls:
print(url, len(html))
print("craw over")
# parse
with concurrent.futures.ThreadPoolExecutor() as pool:
futures = {}
for url, html in htmls:
future = pool.submit(blog_spider.parse, html)
futures[future] = url
# First kind
# for future, url in futures.items():
# print(url, future.result())
# The second one is not in order, but in the order of thread completion
for future in concurrent.futures.as_completed(futures):
url = futures[future]
print(url, future.result())
Accelerating Web services with thread pool
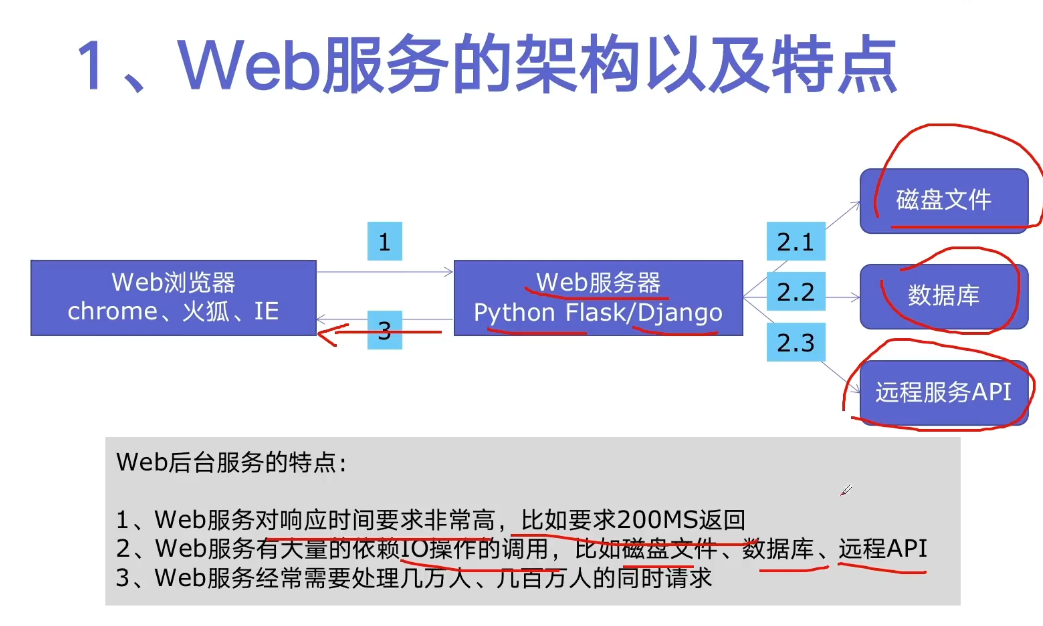

Simulate several operations of web server with time (read file, read database, read api)
# _*_ coding=utf-8 _*_
import json
import flask
import time
app = flask.Flask(__name__)
def read_file():
time.sleep(0.1)
return "file result"
def read_db():
time.sleep(0.2)
return "db result"
def read_api():
time.sleep(0.3)
return "api result"
@app.route('/')
def index():
result_file = read_file()
result_db = read_db()
result_api = read_api()
return json.dumps({
"result_file": result_file,
"result_db": result_db,
"result_api": result_api
})
if __name__ == "__main__":
app.run()
Use thread pool acceleration. The corresponding service is run with the thread pool, and the result method of the thread pool is also used to return the result. At this time, because it is executed concurrently, the running time is related to the longest of the three services (that is, it takes more than 300 ms)
# _*_ coding=utf-8 _*_
import json
import flask
import time
from concurrent.futures import ThreadPoolExecutor
app = flask.Flask(__name__)
pool = ThreadPoolExecutor()
def read_file():
time.sleep(0.1)
return "file result"
def read_db():
time.sleep(0.2)
return "db result"
def read_api():
time.sleep(0.3)
return "api result"
@app.route('/')
def index():
result_file = pool.submit(read_file)
result_db = pool.submit(read_db)
result_api = pool.submit(read_api)
return json.dumps({
"result_file": result_file.result(),
"result_db": result_db.result(),
"result_api": result_api.result()
})
if __name__ == "__main__":
app.run()
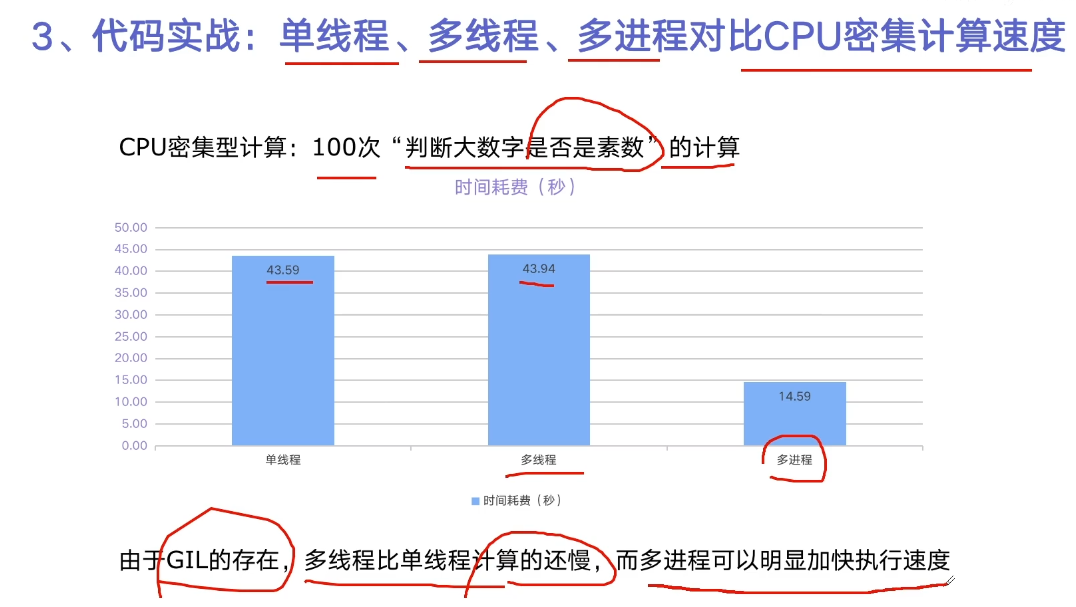
Use multiprocessing to speed up the running of programs
The grammar is almost the same

# _*_ coding=utf-8 _*_
import math
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from Crypto.Util import number
PRIMES = []
for i in range(100):
PRIMES.append(number.getPrime(40))
# print(PRIMES)
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def single_thread():
for number in PRIMES:
is_prime(number)
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
def multi_process():
with ProcessPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
if __name__ == "__main__":
start = time.time()
single_thread()
end = time.time()
print('single_thread, cost:', end - start, 'seconds')
start = time.time()
multi_thread()
end = time.time()
print('multi_thread, cost:', end - start, 'seconds')
start = time.time()
multi_process()
end = time.time()
print('multi_process, cost:', end - start, 'seconds')
Multiple processes are faster, and sometimes multiple threads are slower than a single thread

Using process pool acceleration in Flask service
That is, in the flash environment, in the face of CPU intensive operation, multi process method is used to accelerate.
The code is actually similar to using thread pool acceleration, but the video says that since the process pool does not share memory space, it is necessary to put the declaration of the process pool after all function declarations and in the main function to ensure the normal use of the process pool.
PS: but after the experiment, it seems that it is possible to call like a thread pool. Maybe where has the library been updated? (not studied in depth)
# _*_ coding=utf-8 _*_
import math
import flask
import json
from concurrent.futures import ProcessPoolExecutor
app = flask.Flask(__name__)
process_pool = ProcessPoolExecutor() # The video said that putting it here would report an error, but the experiment seems to have no problem. Has it been changed
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
@app.route('/is_prime/<numbers>')
def api_is_prime(numbers):
number_list = [int(x) for x in numbers.split(',')]
results = process_pool.map(is_prime, number_list)
return json.dumps(dict(zip(number_list, results)))
if __name__ == "__main__":
# It needs to be placed in the main function and accessed after all other functions are declared http://127.0.0.1:5000/is_prime/1,2,3
# process_pool = ProcessPoolExecutor()
app.run()
Asynchronous IO implementation concurrent crawler
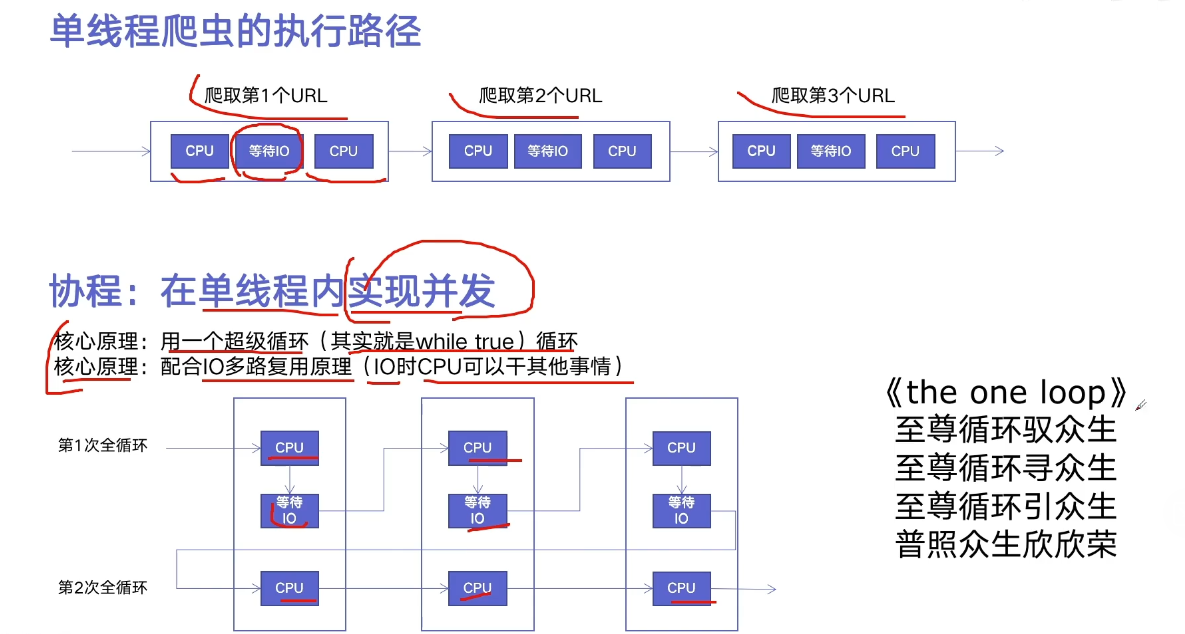

# _*_ coding=utf-8 _*_
import time
import aiohttp
import asyncio
import blog_spider
async def async_craw(url):
print('craw url:', url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f'craw url: {url}, {len(result)}')
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(async_craw(url))
for url in blog_spider.urls
]
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print('use time seconds:', end-start)
reference resources:
- https://www.jianshu.com/p/b9b3d66aa0be
- https://www.bilibili.com/video/BV1bK411A7tV?from=search&seid=10357238605445227627&spm_id_from=333.337.0.0