[python + Neo4j] simple use of knowledge map tool
Write at the front: because the graduation project needs to use the knowledge map tool to visually display the csv form, after learning Zhihu, blog, etc., we decided to use neo4j for preliminary implementation. This article records the whole process of Xiaobai's entry, for novices' reference!
1, neo4j installation and environment configuration
This part is implemented with reference to the blogs of predecessors. A blog with a very detailed introduction is put below. I followed this one and it is available for personal testing.
Neo4j Article 1: installing neo4j in Windows Environment - happy time blog Park (cnblogs.com)
PS: I didn't operate the third part of network connection configuration, because I didn't have this requirement, and my computer network is very poor, so I can't understand it.
2, python operation neo4j
Here we need to use a library: py2neo, which can be installed directly from pip.
2.1 introduction
For the simplest introduction, I refer to the following blog. Please pay attention to adjusting the user name and password in the code.
However, for students without database foundation, it is necessary to know the difference between Node name and Node label; And what the parameters of Node and Relationship functions mean. Refer to the link below
2.2 importing CSV into neo4j
The pandas library and py2neo implementation are combined here. In addition, for the vacancy values in the table, py2neo will directly report an error instead of automatically skipping, so we need to add judgment in the code. The details are as follows:
def CSV4neo4j(filepath, graph):
# Read CSV file
data = pd.read_csv(filepath, error_bad_lines=False, encoding='GBK')
for i in range(len(data)):
"""Skip first row header"""
if str(data.iloc[i, 0]) == 'original text':
continue
"""Establish nodes and relationships line by line( if (used to judge whether the event attribute value exists)"""
text = Node('text', name=data.iloc[i, 0])
graph.create(text)
"""Attribute 1"""
if str(data.iloc[i, 1]) != 'nan':
prim = Node('prim', name=data.iloc[i, 1])
graph.create(prim)
# Build relationships
text2prim = Relationship(text, 'Attribute 1', prim)
graph.create(text2prim)
"""Attribute 2"""
if str(data.iloc[i, 2]) != 'nan':
size = Node('size', name=data.iloc[i, 2])
graph.create(size)
# Build relationships
prim2size = Relationship(text, 'Attribute 2', size)
graph.create(prim2size)
"""Attribute 3"""
if str(data.iloc[i, 3]) != 'nan':
trans = Node('trans', name=data.iloc[i, 3])
graph.create(trans)
# Build relationships
text2trans = Relationship(text, 'Attribute 3', trans)
graph.create(text2trans)
2.3 merging the same nodes (de duplication)
If the same nodes are not merged, the relationship between nodes will not be clear, and the significance of knowledge map will be small, so this part is also a very important step.
In the process of implementation, I found that many other blogs are implemented in Cypher language of Neo4j, but it is too difficult for me, who has a poor database foundation and has not operated the database with mySQL instructions... So I found another way, that is to search whether the same node already exists in the current figure. I mainly refer to the following two blogs. The first introduces the overall idea and the second focuses on the code implementation. I won't introduce it in detail here. Please move to the great God blog hee hee!
Therefore, the above CSV4neo4j function is improved as follows:
def CSV4neo4j(filepath, graph):
# Import CSV file
data = pd.read_csv(filepath, error_bad_lines=False, encoding='GBK')
for i in range(len(data)):
"""Skip first row header"""
if str(data.iloc[i, 0]) == 'original text':
continue
"""Establish nodes and relationships line by line( if (used to judge whether the event attribute value exists)"""
text = Node('text', name=data.iloc[i, 0])
graph.create(text)
"""Attribute 1"""
if str(data.iloc[i, 1]) != 'nan':
prim = Node('prim', name=data.iloc[i, 1])
matcher = NodeMatcher(graph)
matchlist = list(matcher.match('prim', name=data.iloc[i, 1]))
if len(matchlist) > 0: # Node already exists, no need to create
prim = matchlist[0]
# Direct relationship building
text2prim = Relationship(text, 'Attribute 1', prim)
graph.create(text2prim)
else: # Node to be created
graph.create(prim)
# Build relationships
text2prim = Relationship(text, 'Attribute 1', prim)
graph.create(text2prim)
"""Attribute 2"""
if str(data.iloc[i, 2]) != 'nan':
size = Node('size', name=data.iloc[i, 2])
matcher = NodeMatcher(graph)
matchlist_size = list(matcher.match('size', name=data.iloc[i, 2]))
if len(matchlist_size) > 0:
size = matchlist_size[0]
# Build relationships
prim2size = Relationship(text, 'Attribute 2', size)
graph.create(prim2size)
else:
graph.create(size)
# Build relationships
prim2size = Relationship(text, 'Attribute 2', size)
graph.create(prim2size)
"""Attribute 3"""
if str(data.iloc[i, 3]) != 'nan':
trans = Node('trans', name=data.iloc[i, 3])
matcher = NodeMatcher(graph)
matchlist_trans = list(matcher.match('trans', name=data.iloc[i, 3]))
if len(matchlist_trans) > 0:
trans = matchlist_trans[0]
# Build relationships
text2trans = Relationship(text, 'Attribute 3', trans)
graph.create(text2trans)
else:
graph.create(trans)
# Build relationships
text2trans = Relationship(text, 'Attribute 3', trans)
graph.create(text2trans)
Finally, call as needed
from py2neo import Graph, Node, Relationship, NodeMatcher
import pandas as pd
# Connect neo4j database and enter address, user name and password
graph = Graph('http://localhost:7474', username='neo4j', password='')
graph.delete_all()
myfilepath = 'D:/Bi Sheh/code/data/test.CSV'
CSV4neo4j(myfilepath, graph)
give the result as follows
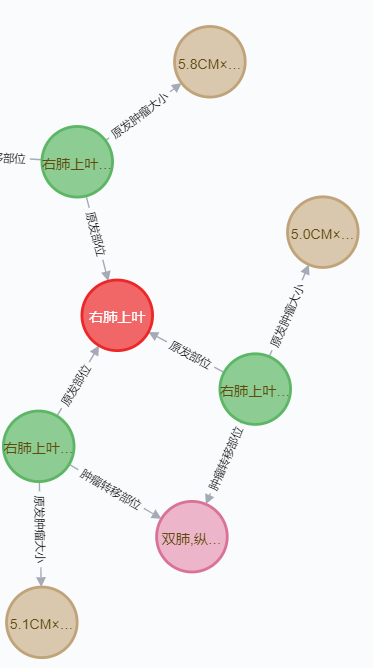
Welcome to communicate!